《MySQL实战45讲》读后笔记
Posted jazon@
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《MySQL实战45讲》读后笔记相关的知识,希望对你有一定的参考价值。
《mysql实战45讲》读后笔记
MySQL 里经常说到的 WAL 技术,WAL 的全称是 Write-Ahead Logging,它的关键点就是先写日志,再写磁盘。
bin log
MySQL的Server层的日志,binlog只能用于归档,不能用于crash-safe,所以MyISAM不具备crash-safe能力。
redolog和binlog比较:
1.redolog是物理日志,记录的是某一页做了什么修改。binlog是逻辑日志,记录了sql。
2.redoglog会循环覆盖,binlog是一直追加
3.redolog是innodb独有,binlog是MySQL的Server层实现的。
回滚日志read-view:
read-view可用于回滚,因为他记录了旧值。但没有事务需要用到readview时,就会删除它,如果长事务,会导致大量的read-view链无法删除,因为长事务与current read-view之间的都要在长事务结束才可能删除。这就是为什么不使用长事务的原因。此外,长事务还会占用锁资源。
查询长事务命令
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60
一周一备和一天一备的对比
最坏情况所需要的的binlog不一样,一天一备最坏所需binlog也只是一天,而一周一备最坏所需的binlog需要一周。对应的指标是RT0,即恢复目标所需时间。
什么情况下业务字段也适合做主键?
对于个人信息这种,身份证号码不适合做主键,因为个人信息表通常有其他索引,二级索引包含主键,占用空间大。当整张表只有一个索引时,才考虑用业务字段作为主键,一般情况下我们都用自增主键。
索引顺序考虑
1.这里我们的评估标准是,索引的复用能力。因为可以支持最左前缀,所以当已经有了 (a,b) 这个联合索引后,一般就不需要单独在 a 上建立索引了。因此,第一原则是,如果通过调整顺序,可以少维护一个索引,那么这个顺序往往就是需要优先考虑采用的。2.我们要考虑的原则就是空间了。比如上面这个市民表的情况,name 字段是比 age 字段大的 ,那我就建议你创建一个(name,age) 的联合索引和一个 (age) 的单字段索引。
重建索引使得索引页更紧凑
对于二级索引使用alter table T drop index k;alter table T add index k没问题,但是对于主键索引,这样的语句会重建整张表。可以用这个语句代替 :alter table T engine=InnoDB
如何避免长事务
首先,从应用开发端来看:
- 确认是否使用了 set autocommit=0。这个确认工作可以在测试环境中开展,把 MySQL 的 general_log(所有到达MySQL的语句都将记录) 开起来,然后随便跑一个业务逻辑,通过 general_log 的日志来确认。一般框架如果会设置这个值,也就会提供参数来控制行为,你的目标就是把它改成 1。
- 确认是否有不必要的只读事务。有些框架会习惯不管什么语句先用 begin/commit 框起来。我见过有些是业务并没有这个需要,但是也把好几个 select 语句放到了事务中。这种只读事务可以去掉。(spring的read的时候不要乱加事务)
- 业务连接数据库的时候,根据业务本身的预估,通过 SET MAX_EXECUTION_TIME 命令,来控制每个语句执行的最长时间,避免单个语句意外执行太长时间。(为什么会意外?在后续的文章中会提到这类案例)
其次,从数据库端来看: - 监控 information_schema.Innodb_trx 表,设置长事务阈值,超过就报警 / 或者 kill;
- Percona 的 pt-kill 这个工具不错,推荐使用;
- 在业务功能测试阶段要求输出所有的 general_log,分析日志行为提前发现问题;
- 如果使用的是 MySQL 5.6 或者更新版本,把 innodb_undo_tablespaces 设置成 2(或更大的值)。如果真的出现大事务导致回滚段过大,这样设置后清理起来更方便。
全局锁
Flush tables with read lock (FTWRL),显示加全局锁,不允许修改语句执行。应用场景是全局逻辑备份。针对INNODB,其实有MVVC机制,mysqldump则可以利用这种机制,加上-- single-transaction,mysqldump期间不能使用ddl语句。而MyISAM没有事务,没有MVVC机制,且readonly字段通常会被系统用于其他作用,比如标记为从主库,FTWRL在客户端异常断开之后就会使数据库恢复为可写,设置readonly则一直不能恢复。
表级锁
locak table t1 read, t2 write。MDL锁,即表元数据(表结构数据)锁,访问表的时候便会隐式地加上。
给一张表加个字段,导致整个库挂了
长事务霸占了MDL读锁,当加个字段时,会尝试加MDL写锁,因为互斥,所以阻塞了。此后的事务,都会因为MDL写锁在排队,而阻塞。所以,在加字段的时候,要确保没长事务在执行,可以通过select * from innodb_trx查询,如果有可以尝试kill掉。如果是查询很频率的场景,可以使用alter table table_name WAIT add column,在 N时间内如果获取不到MDL锁就结束掉,避免阻塞,这是MariaDb才有的。
行锁
行锁是引擎层实现的,MyISAM不支持行锁,InnoDB支持。
两阶段加锁带来的启发
如果你的事务中需要锁多个行,要把最可能造成锁冲突、最可能影响并发度的锁尽量往后放。
MySQL死锁,CPU很高
两阶段加锁时,相互等待。解决方法:1.innodb_lock_wait_timeout设置短一些,但是这会引起不是死锁情况的失败返回。2.开启死锁检测,但是带来的消耗很大,因为每个事务执行都需要判断自己的加入会不会引起死锁,那么就是O(n)的时间复杂度。假如1000个并发,那么就是100W次检查,效率很低。如果开了死锁检测,就要控制并发度,确保同时修改一行数据的并发度低。
主从架构下,mysqldump --singe-transaction可能的问题
用从库在备份,主库修改了表结构,此时会怎么样?
当前读避免丢失更新
update table set k=k+1 where id = 1 //会在更新前进行 当前读
如果要在select触发当前读,需要加上lock in share mode或for update
再看另一种情况

事务C在执行update时就会加锁,两阶段加解锁,所以事务B要等到事务C结束才能拿到锁。所以也不会出现丢失更新。
一致性读,当前读,两阶段加减锁保证了可重复读。
• 为何表结构不支持可重复读
1.因为他们有行记录,即没有trx_id。
• 唯一索引和普通索引的区别
1.普通索引找到等值查询的值之后,还会找下一个看看是否满足条件,直到不满足条件才返回。唯一索引,找到就返回了。几乎没差别。
2.change buufer,对于唯一索引无法使用change buffer,对于普通索引,可以使用change buffer。
change buffer处于buffer pool区域,记录更新操作,避免每次更改时数据不在buffer情况下,都需要从磁盘读数据。应用change buffer的过程叫做merge。redo log会记录buffer pool的状态(包括了change buffer),所以掉电也不慌。
推荐使用普通索引。
• change buffer使用场景
适用于写多读少的场景,读多的话,change buffer没有什么增益。
• change buffer和redo log的优化分别是什么
changebuffer是减少随机读,redo log是减少随机写
• mysql判断扫描行数有误
行数判断有误,引起优化器选择了错的执行方式,analyze table t,分析表的统计数据,可用于纠正mysql判断扫描行数有误的情况。
• 错误选择索引的例子
select * from user where (a between 5000 and 6000) and (b between 50000 and 10000) order by b limit 1优化器选择使用了b索引,因为优化器认为不需要进行文件排序可提高效率。我们可以将order by b改为order by b,a使得优化器选择a。
• 如何给字符串加索引
完整索引;使用前缀索引,减少字段占用,但是覆盖索引将不能使用,权衡;倒序之后再创建前缀索引;hash。从:cpu,占用空间,查询效率分析。
• 刷脏页的IO速度控制
给MySQL设置IOPS值(系统IO能力),MySQL根据脏页比例计算出F1(M)和刷入检查点计算出F2(M),取最大值,然后乘以IOPS,得到要使用多少IO能力去刷新。
• 查询脏页比例
mysql> select VARIABLE_VALUE into @a from global_status where VARIABLE_NAME = ‘Innodb_buffer_pool_pages_dirty’;
select VARIABLE_VALUE into @b from global_status where VARIABLE_NAME = ‘Innodb_buffer_pool_pages_total’;
select @a/@b;
• 删数据并没有减少表的大小问题
innodb_file_per_table,设置为ON,表数据将存在.ibd文件中。删除行,插入行(页分裂)都可能带来空洞(占用磁盘空间,但是没有数据,后续可以使用这部分空间去写)。重建表可以减少空洞:
alter table A engine=InnoDB,MySQL5.6之后才支持 ONLINE DDL,而且是默认。
• count()
MyISAM直接保存了值,而Innodb基于MVVC,不适合直接保存值。Innodb基于count()的优化就是,在不影响结果的前提下,选择小的B+树。可以考虑用单独的表字段维护count,而不依赖于count函数。
• 不同count的区别
原则:1.Server需要什么,引擎就会返回什么。2.引擎只返回必要的值。3.针对count()做了优化,不取行,其他优化没有做。count(1),引擎不取值,Server会遍历所有行,填充1,累加。count(字段),遍历所有行,返回字段,Server层会判读值,判断是不是NULL,累加。count()会遍历,但是不需要取值,它肯定不为NULL。count(id)引擎层会返回id给Server,Server判断不为NULL则累加。
按照效率排序的话,count(字段)<count(主键 id)<count(1)≈count(),所以我建议你,尽量使用 count()。
• order by的sort_buffer
order by时当sort_buffer不足则会使用tmp_file进行排序,归并排序。sort_buffer是考虑了查询的所有字段的,所以查询字段越多,越有可能容量不够。SET max_length_for_sort_data = 16;设置排序时全量载字段载入buffer pool的字段大小,超过这个设置大小,将使用row_id方式,即只载入id到sort_buffer或临时文件中,排序完再回表查询。
/* 打开 optimizer_trace,只对本线程有效 /
SET optimizer_trace=‘enabled=on’;
/ @a 保存 Innodb_rows_read 的初始值 /
select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = ‘Innodb_rows_read’;
/ 执行语句 /
select city, name,age from t where city=‘杭州’ order by name limit 1000;
/ 查看 OPTIMIZER_TRACE 输出 /
SELECT * FROM information_schema.OPTIMIZER_TRACE\\G
/ @b 保存 Innodb_rows_read 的当前值 /
select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = ‘Innodb_rows_read’;
/ 计算 Innodb_rows_read 差值 */
select @b-@a;
查看是否使用临时文件排序。
• 正确显示随机记录
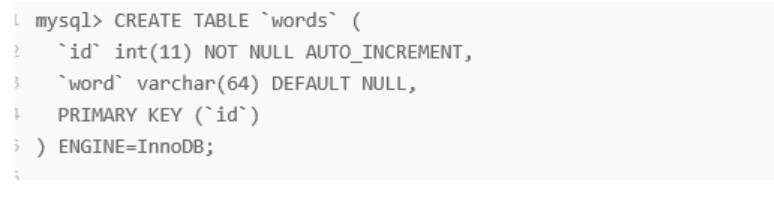
select word from words order by rand() limit 3
假设表里有1W数据。
这条语句会使用内存临时表进行排序(是不是用内存临时表取决于临时表大小),首先扫描words表,将它们加载到内存临时表(W,R),R是rand()随机生成的,这里扫描1W行数据。之后将临时表的R字段和POS字段(其实就是ROW_ID字段)加载到sort buffer中,这里又扫描1W行。排完序之后,取出三条,回到临时内存表查找数据,所以总共扫描的是2W3行。为什么会产生临时表呢?个人猜测是rand()函数引起的。order by rand() 使用了内存临时表,内存临时表排序的时候使用了 rowid 排序方法。因为内存临时表即使采用rowid,也不会产生磁盘IO。
当超过tmp_file_size时,会使用磁盘临时表。我们将tmp_file_size设置为1024,sort_buffer_size设置为32768,max_length_for_sort_data设置为16。
max_length_for_sort_data设置为16,小于W的长度定义,所以它会走rowid排序。但是记过简单计算,我们发现加载入sortbuffer的应该是1W行 * (W字段大小 + R字段大小) = 14000字节,超过了sortbuffer,所以按理有tmp_file才是。但是上面的number_of_tmp_files却为0。原因是MySQL5.6之后引入了优先队列排序算法,对于sql中的情况,因为排序后其实也只是取前三条,所以不需要全部排序,只需要维护找出前三的即可。想要随机三条,可以在总行数里随机三个数,然后limit 1。
• 明明只有一行,为什么执行很慢
select * from t where id = 1;
这条命令卡住,可能的原因是什么。
1.show processlist;
查看线程状态,发现正在等待MDL锁,MDL锁是表级锁。

当performance_schema开启后,可以通过sys.schema_table_lock_waits这张表,直接找出阻塞的process_id,把这个连接用kill命令杀掉。
select blocking_pid from sys.schema_table_lock_waits;
2.undo log太长引起慢
select * from t where id = 1
由于在此事务期间,可能有大量的修改,导致undo log过长。如果不要求一致性,可以使用
select * from t where id = 1 in share mode
因为id有索引,所以也只是加这一行。
• 当前读时,引入间隙锁
可重复提交隔离级别下,会默认开启间隙锁,因为可重复提交隔离级别下,插入新纪录前,该记录不可能被锁住,比如表(a,v,c) 。在一个提前开始的事务将所有c为5的v值改为100,在此事务期间,插入c为5,v为8的记录。当事务提交后,数据库的记录为(a,8,5),但是binlog日志回放后是(a,100,5),所以需要引入间隙锁。间隙锁就是锁住记录之间的间隙部分。
• 加锁规则
1.加锁的单位为next-key-lock。2查找过程中,访问到的对象才会加锁,比如你使用了覆盖索引,不需要回表,那么就只加覆盖索引。3.索引上的等值查询,给唯一索引加锁时,next-key lock退化为行锁。4.索引上的等值查询,向右遍历时,最后一个值不满足等值条件时,next-key lock退化为间隙锁。5.一个bug:唯一索引上的范围查询会访问到不满足条件的第一个数据为止,本来唯一索引就是唯一的了,按理不需要访问到访问到不满足条件的数据为止。
• 双1机制保证MySQL数据不丢失
innodb_flush_log_at_trx_commit设置为1,意味着每次提交事务redolog都会刷盘。
sync_binlog设置为1,意味着每次提交事务binlog都会刷盘。
• MySQL主备如何保证数据一致性
binlog有statement和row格式,statement记录的是原SQL,row记录的是能定位到某条记录的。比如delete from t where a<5 and b<9 limit 1,在主从库中如果使用statement可能删除的不一样,因为主从库选用的索引可能不一样。如果使用row格式,则能定位到某个主键中。mixed格式是mysql智能地选用row或statement。row耗空间及易读性差。现在通常用的row了,因为它会记录修改前的状态,可以避免误操作引起的问题。
• 双M架构如何避免的循环复制
binlog有个serverId,备库拿到binlog之后,回放,生成的serverId和旧的binlog的serverId一样。当主库再次拿到binlog,发现和自己的serverid一样,丢弃。
• MRR算法优化
如果回表查询是无序的,那么就会引起磁盘随机读写,如果能在会表前将主键id排序,则可以变为顺序IO,这就是MRR的原理,通过二级索引得到主键id,将id放入read_rnd_buffer中排序,再回表。
• NLJ,BKA算法优化
BKA算法依赖于MRR算法,它将驱动表的关联键存入join buffer中,相当于一次关联多行,比起未优化时的一行一行,性能更好。
• BNL给系统带来的影响
1.多次扫描被驱动表,占用磁盘IO资源;
2.判断join条件需要执行MN次比价,耗费CPU;
3.使得buffer pool冷热数据异常,缓存命中率降低;
• BNL转BKA
select * from t1 join t2 on (t1.b = t2.b) where t2.b >= 1 and t2.b<=2000;如果使用BNL算法来join,这个语句执行流程是这样的: 把表t1的所有字段取出来,存入join_buffer中,这个表只有1000行,join_buffer_size默认值是256k,可以完全存入,扫描t2,取出每一行跟join_buffer中的数据进行对比,如果不满足t1.b=t2.b,则跳过;满足判断其他条件,明显这样子等值条件判断是MN,工作量很大。不想创建索引时,我们可以使用临时表
create temporary table temp_t(id int primary key, a int, b int index(b)) engine=innodb;
insert into temp_t select * from t2 where b>=1 and b<= 2000;
select * from t1 join temp_t on (t1.b=temp_t.b)
使用临时表并给临时表创建索引,将扫描行数和比较次数都降低了。总而言之: 思路就是让join语句能够用上被驱动表的索引,触发BKA算法,提升查询性能。
• 扩展-hash join
join被人所诟病的一点是它不支持hash join,意思是mysql没加载把记录加载进join buffer维护成一个字典,如果使用hash,那么就是1N了,利用这个思路,可以自己在业务端实现。
• 临时表的特性
临时表只能被它的session访问,对其他线程不可见,临时表可以与普通表同名,session内有同名的临时表和普通表时,show create语句,以及增删改查语句的是临时表,show tables 命令不显示临时表,当session结束后,临时表就会被自动删除。
• 临时表适合于BNL的join的原因
不同session的临时表可以重名,如果有多个session同时执行join优化,不需要担心表名重复导致建表失败的问题。
不需要担心数据删除问题,如果使用普通表,在流程执行过程中客户端发生了异常断开,或者数据库发生异常重启,还需要专门来清理中间过程中生成的数据表,而临时表会自动回收。
• 临时表在分库分表的应用
将来自不同库的数据查询回来,插入到一个MySQL实例中临时表,在从一个库的临时表中查询。
• 临时表可以重名
临时表的表结构定义文件名是"#sql{进程id}_{线程id}_序列号",表中的数据5.7之后的版本,MySQL引入了一个临时文件表空间,专门用来存放临时文件的数据。在内存中,MySQL同样也需要一套机制区分不同的表,每个表都对应一个table_def_key,普通表由库名+表名组成,临时表是在此基础上加上server_id+thread_id。
• draop temporary table + "表名"为什么要写到binlog
如果binlog_format=row,那么跟临时表有关的语句就不会记录到binlog里,也就是说,只在binlog_format=statment/mixed的时候,binlog中才会记录临时表操作。主库在写临时表的binlog时,会将库名+表明+serverId+threadId记录到binlog中。
• union 和 union all对临时表使用的区别
union有去重的作用,所以它需要使用到内部临时表,如果union all则直接将结果集发给客户端。
• group by对临时表的使用
group by对无序数据需要创建临时表,扫描数据载入临时表,对于聚合键存在的则统计,对于聚合键不存在的则插入。简单来说,就是group by构造了一个带唯一索引的表。
• group by 优化方法–索引
如果group by的列是有序的,那么将不需要使用临时表,这就是group by的优化方式之一。
• group by 优化方法 – 直接排序
如果group by字段不能使用索引,那该如何优化?mysql使用磁盘临时表是在内存临时表不够用的时候才选择,那么我们可以直接让mysql走磁盘临时表,使用SQL_BIG_RESULT告诉Mysql。
select SQL_BIG_RESULT id%100 as m, count() as c from t1 group by m;
MySQL知道这个结果将会很大时,会创建sort buffer,将 id % 100放入其中排序,得到了一个有序数组,则结果就像使用了索引一样了。explain的结果,将会显示 using index;using file sort; 前面的using index是扫描索引,得到id。
• MySQL什么时候会使用内部临时表
1.如果语句执行过程中可以一边读数据,一边直接得到结果,是不需要额外内存的,否则就需要额外的内存,来保存中间结果;2.join_buffer是无序数组,sort_buffer是有序数组,临时表二维表结构;3.如果执行逻辑需要用到二维表特性,就会优先考虑使用临时表。比如union需要用唯一索引约束,group by还需要用到另外一个字段来存累积计数。
• group by使用指导原则
1.如果对group by 语句的结果没有排序要求,要在语句后面加order by null;尽量让group by过程用上表的索引,确认方法是explain 结果里没有Using temporary和Using filesort;3.如果group by需要统计的数量不大,尽量只使用内存临时表,也可以适当调大tmp_table_size参数,避免用到磁盘临时表;
• Memory引擎的主键索引方式
主键id是hash索引,索引上的key并不是有序的,内存表的数据部分以数组的方式单独存放,内存表的数据就是按照写入顺序存放的。Memory所有索引都是地位相同。内存表可以支持自己创建b+索引。
• 内存表的锁
内存表不支持行锁,只支持表锁,一张表有更新,就会堵住其他所有在这个表上的读写操作。

sessionB会阻塞住。
• 内存表数据持久性问题
双M架构下,由于内存表在MySQL重启后会清空数据,所以备库重启了,主库发了一条update语句,会出现找不到数据行更新。而且,重启后会发一条delete table t1到另一个M,导致使用着,数据没了。
• 到底内存表能用吗?
建议普通内存表都用InnoDB表来代替,因为内存表并发度低,而且InnoDB也有buffer Pool。但是临时表可以使用Memory引擎,因为临时表只能被本线程访问,没有并发性问题,临时表重启后也需要被删除,数据持久性问题不存在,备库临时表也不会影响主库的用户线程。
• MySQL自增值的存储
MyISAM存储引擎,自增值是被写在数据文件上的,而在InnoDB中,自增值是被记录在内存的。8.0之后,InnoDB自增值加上了持久化的能力,确保重启前后一个表的自增值不变。重启后,InnoDB会以当前数据库里最大值加上1作为新的自增值。8.0之后,记录在redolog中。
• MySQL的自增主键连续吗
MySQL的自增主键不保证连续,因为表的AUTO_INCREMENT是先赋值给行,然后加一写AUTO_INCREMENT变量中,而在插入的时候,行记录可能有唯一索引冲突,插入失败,但是AUTO_INCREMENT此时已经加1了,导致了不连续。另一种情况是事务回滚,当事务回滚,也是没插入,但是AUTO_INCREMENT已经增加了。在申请id的时候,那种批量插入语句,会多次申请Id,第一次申请时有一个,第二次申请时就会有两个,第三次申请就会有四个,可能申请多了,这是id不连续的第三个原因。
• 为什么自增ID有上面那个问题,而MySQL不解决?
因为解决需要大范围加锁,使得性能下降。
• 自增Id锁的优化历史
在MySQL5.0版本时,自增Id锁的范围还是整个语句,到了MySQL5.1.22引入了innodb_autoinc_lock_mode,默认值是1,1意味着普通insert语句,自增锁在申请之后马上就释放;类似于insert…select这样的批量插入,需要等到语句结束后才被释放,这是为了数据一致性。
• 几种特殊情况下的insert语句
insert …select 在可重复读隔离级别下,这个语句会给select的表里扫描到的记录和间隙加读锁,目的是为了避免数据和日志可能的不一致情况。insert…select的对象是同一个表,则有可能造成循环写入,这种情况,我们需要引入用户临时表来做优化,否则mysql会将select记录全部加载入临时表。insert语句如果出现唯一键冲突,会在冲突的唯一值上加共享的next-key-lock,因此,碰到由于唯一约束报错后,尽快提交或回滚事务,避免加锁时间过长。
• 复制一张表的方法
insert…select,弊端是会对源表加锁;mysqldump;到处csv再load csv,csv在主备是会将csv文件内容写入binlog,备库load的时候是读取binlog里收到的csv文件内容;物理拷贝:直接将.frm和.idb文件拷贝是不行的,因为mysql还有个数据字典记录.frm和.idb和表空间id三者的关系,正确的方式如下:通过导出加导入表空间的方式实现物理拷贝,创建一个表r和被复制表t一样的结构;将表的表空间删除,即运行alter table r discard tablespace,r.idb文件会被删掉;flush table t for export这时候db1目录会生成一个t.cfg文件,将t.cfg和t.idb文件重命名为r.cfg和r.idb;执行unlock tables,将t.cfg文件删除;重新导入表空间,alter table import tablespace,将r.idb就导入了,其中的数据和t.idb相同。
详解一下上面几步:
1.flush table t for export是为了让t表处于只读状态,直到执行unlock tables命令才释放读锁;这时候生成t.cfg改名为r.cfg,估计能让r表也起到同样效果(不管同不同样效果,应该不影响结果)
2.import tablespace,为了让r.ibd的文件里的表空间id和数据字典中的一致,会修改r.idb的表空间id,而这个表空间id存在于每一个数据页中,因此如果一个很大的r.idb文件,则每一页都需要修改,则耗时稍长一些。
• 分区表能用吗
锁方面:InnoDB下,gap锁在使用分区表之后将被截断,gap锁表现不一致,而MyISAM下,表锁将锁住某个分区,因为MyISAM只支持表锁;分区策略方面:MyISAM使用的是通用分区策略,一下子打开所有分区,容易引起open limit file溢出导致打开表失败,MyISAM在8.0之后不允许MyISAM创建分区表了;InooDB使用的是本地分区策略,由InnoDB内部管理自己打开的分区表;分区表的server层行为:一条语句将会拥有整个表的MDL锁,比起创建多个表的方式,分区表影响更大。
• MySQL的crash-safe
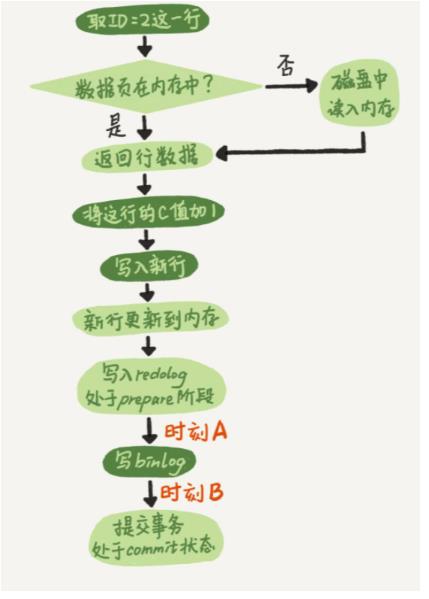
时刻A如果发生故障,redo log处于prepare阶段,写binlog之前发生了故障,由于binlog还没写入,redolog也没提交,所以崩溃就事务回滚;时刻B,如果redo log里面的事务是完整的,也就是已经有了commit标识,则直接提交;如果redo log里面的事务只有完整的prepare,则判断事务bin log是否存在并完整,如果是,则提交事务,否则回滚事务。
• MySQL怎么知道bin log是完整的?
staement 格式的 binlog,最后会有COMMIT;row格式的bin log,最后会有一个XID event。
• redo log 和 bin log是怎么关联起来的
它们都有共同的一个字段叫XID,崩溃恢复时会顺序扫描redo log,如果即有prepare和commit的redo log就直接提交,如果只有prepare而没有commit的 redo log,就拿着XID去binlog找对应的事务。
• 只用big log不可以吗
big log不支持崩溃恢复,主要是在于它不能恢复数据页,redo log才是记录数据页的。
• 只要redo log 不要bin log可以吗
从崩溃恢复的脚本来说可以的,但是bin log在正式生产库上一般都是开着的,用于复制,数据分析之类的。
• redo log 设置多大合适?
redo log太小,导致很快写满,不得不刷redo log, 这样WAL 机制的能力就发挥不出来,将 redo log设置为4个文件,一个文件1G吧
• 业务设计实战
互相关注,则成为好友的表设计。并发互相关注时,则有概率不能生成好友关系。解决方案就是引入relation_ship字段,使得唯一索引生效。(具体看MySQL45讲之15讲)
• 不等号条件里的等值查询
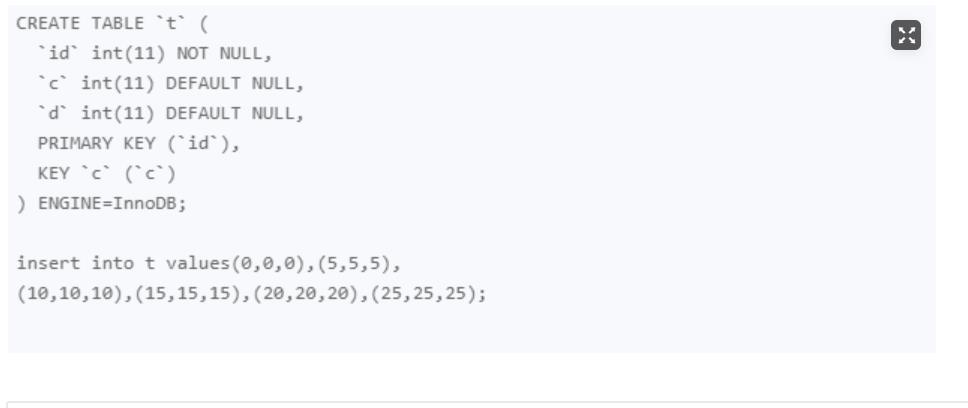
select * from t where id>9 and id<12 order by id desc for update
这条语句首先要找到id=12的行,根据优化2规则,向右遍历且最后一个条件不满足等值条件时,next-key-lock退化为间隙锁(10, 15),之后是范围查找,向左边找i>9的,向左找到id=5的那行才能结束查找则加上了(0,5],最后总的加锁就成了
(0,5],(5,10]和(10,15)。
• 等值查询的过程
select id from t where c in(5,20,10) lock in share mode;
先找到c=5,由于c不是唯一索引,所以还得向右遍历,找到c=10才能确定没有数据了,根据优化2,这里退化为间隙锁(5,10),所以c=5时,加锁范围为(0,5],(5,10),其他条件,同样方式得到c=10加锁范围为(5,10],(10,15),c=20的加锁范围为(15,20],(20,25)。这条语句是在执行过程中一个一个加上去的锁,每个条件加上每个条件的锁。 5,10,20是记录锁。
• 怎么看死锁
show engine innodb status,查看LATESTDETECTED DEADLOCK那一节的信息,就是记录最后一次死锁信息。这个结果分成三部分:
1.TRANSACTION,是第一个事务的信息;
2.TRANSACTION,是第二个事务的信息;
3.WE ROLL BACK TRANSACTION(X),是最终的处理结果,表示回滚了第X个事务。结论: 由于锁是一个个加的,要避免死锁,对同一组资源,要按照尽量相同的顺序访问;在发生死锁的时刻,for update 这条语句占有的资源更多,回滚成本更大,所以InnoDB选择了回滚成本更小的lock in share mode语句,来回滚。
• 一个锁等待的例子
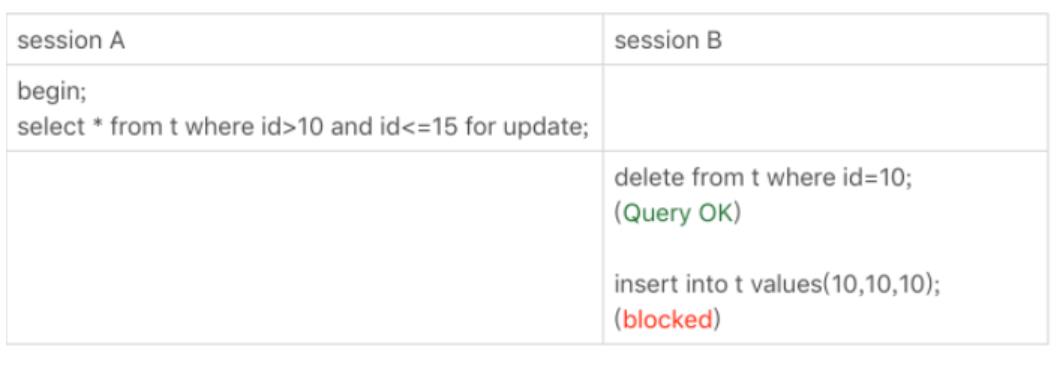
先看看sessionA会怎么加锁,先找id=15的,因为这里有一个明显的等值查询,于是(10,15],此时退化成了行锁,之后往左边查找,找到10前面,于是锁成了(10,15],由于sessionB把10这行删掉了,锁范围成了(5,15],于是插入10的就被阻塞了。tip:往左边查找时,是找到第一条符合记录的行就停下来了。
• update的例子
找到第一条满足记录是c=10,所以不会加(0,5]这个next-key lock,所以加锁范围成了(5,10],(10,15],(15,20]
当sessionB把c=5那行改为c=1时,相当于间隙的墙没了,所以,锁的范围就扩大了变为了(1,10],所以当第二个update语句想要把c从1改为5时,就阻塞了。tip:>号是找第一条满足记录的,<号是找第一条不满足记录的。
以上是关于《MySQL实战45讲》读后笔记的主要内容,如果未能解决你的问题,请参考以下文章