Flink 双流 Join 的3种操作示例
Posted Flink 中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 双流 Join 的3种操作示例相关的知识,希望对你有一定的参考价值。
-
join() -
coGroup() -
intervalJoin()
准备数据
DataStream<String> clickSourceStream = env.addSource(new FlinkKafkaConsumer011<>("ods_analytics_access_log",new SimpleStringSchema(),kafkaProps).setStartFromLatest());DataStream<String> orderSourceStream = env.addSource(new FlinkKafkaConsumer011<>("ods_ms_order_done",new SimpleStringSchema(),kafkaProps).setStartFromLatest());DataStream<AnalyticsAccessLogRecord> clickRecordStream = clickSourceStream.map(message -> JSON.parseObject(message, AnalyticsAccessLogRecord.class));DataStream<OrderDoneLogRecord> orderRecordStream = orderSourceStream.map(message -> JSON.parseObject(message, OrderDoneLogRecord.class));
join()
clickRecordStream.join(orderRecordStream).where(record -> record.getMerchandiseId()).equalTo(record -> record.getMerchandiseId()).window(TumblingProcessingTimeWindows.of(Time.seconds(10))).apply(new JoinFunction<AnalyticsAccessLogRecord, OrderDoneLogRecord, String>() {@Overridepublic String join(AnalyticsAccessLogRecord accessRecord, OrderDoneLogRecord orderRecord) throws Exception {return StringUtils.join(Arrays.asList(accessRecord.getMerchandiseId(),orderRecord.getPrice(),orderRecord.getCouponMoney(),orderRecord.getRebateAmount()), ' ');}}).print().setParallelism(1);
coGroup()
clickRecordStream.coGroup(orderRecordStream).where(record -> record.getMerchandiseId()).equalTo(record -> record.getMerchandiseId()).window(TumblingProcessingTimeWindows.of(Time.seconds(10))).apply(new CoGroupFunction<AnalyticsAccessLogRecord, OrderDoneLogRecord, Tuple2<String, Long>>() {public void coGroup(Iterable<AnalyticsAccessLogRecord> accessRecords, Iterable<OrderDoneLogRecord> orderRecords, Collector<Tuple2<String, Long>> collector) throws Exception {for (AnalyticsAccessLogRecord accessRecord : accessRecords) {boolean isMatched = false;for (OrderDoneLogRecord orderRecord : orderRecords) {// 右流中有对应的记录collector.collect(new Tuple2<>(accessRecord.getMerchandiseName(), orderRecord.getPrice()));isMatched = true;}if (!isMatched) {// 右流中没有对应的记录collector.collect(new Tuple2<>(accessRecord.getMerchandiseName(), null));}}}}).print().setParallelism(1);
intervalJoin()
right.timestamp ∈ [left.timestamp + lowerBound; left.timestamp + upperBound]
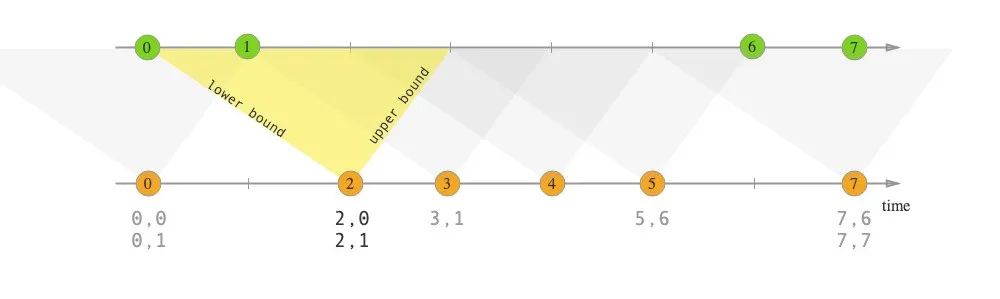
clickRecordStream.keyBy(record -> record.getMerchandiseId()).intervalJoin(orderRecordStream.keyBy(record -> record.getMerchandiseId())).between(Time.seconds(-30), Time.seconds(30)).process(new ProcessJoinFunction<AnalyticsAccessLogRecord, OrderDoneLogRecord, String>() {public void processElement(AnalyticsAccessLogRecord accessRecord, OrderDoneLogRecord orderRecord, Context context, Collector<String> collector) throws Exception {collector.collect(StringUtils.join(Arrays.asList(accessRecord.getMerchandiseId(),orderRecord.getPrice(),orderRecord.getCouponMoney(),orderRecord.getRebateAmount()), ' '));}}).print().setParallelism(1);
interval join 的实现原理
public <OUT> SingleOutputStreamOperator<OUT> process(ProcessJoinFunction<IN1, IN2, OUT> processJoinFunction,TypeInformation<OUT> outputType) {Preconditions.checkNotNull(processJoinFunction);Preconditions.checkNotNull(outputType);final ProcessJoinFunction<IN1, IN2, OUT> cleanedUdf = left.getExecutionEnvironment().clean(processJoinFunction);final IntervalJoinOperator<KEY, IN1, IN2, OUT> operator =new IntervalJoinOperator<>(lowerBound,upperBound,lowerBoundInclusive,upperBoundInclusive,left.getType().createSerializer(left.getExecutionConfig()),right.getType().createSerializer(right.getExecutionConfig()),cleanedUdf);return left.connect(right).keyBy(keySelector1, keySelector2).transform("Interval Join", outputType, operator);}
private transient MapState<Long, List<BufferEntry<T1>>> leftBuffer;private transient MapState<Long, List<BufferEntry<T2>>> rightBuffer;public void initializeState(StateInitializationContext context) throws Exception {super.initializeState(context);this.leftBuffer = context.getKeyedStateStore().getMapState(new MapStateDescriptor<>(LEFT_BUFFER,LongSerializer.INSTANCE,new ListSerializer<>(new BufferEntrySerializer<>(leftTypeSerializer))));this.rightBuffer = context.getKeyedStateStore().getMapState(new MapStateDescriptor<>(RIGHT_BUFFER,LongSerializer.INSTANCE,new ListSerializer<>(new BufferEntrySerializer<>(rightTypeSerializer))));}
public void processElement1(StreamRecord<T1> record) throws Exception {processElement(record, leftBuffer, rightBuffer, lowerBound, upperBound, true);}public void processElement2(StreamRecord<T2> record) throws Exception {processElement(record, rightBuffer, leftBuffer, -upperBound, -lowerBound, false);}("unchecked")private <THIS, OTHER> void processElement(final StreamRecord<THIS> record,final MapState<Long, List<IntervalJoinOperator.BufferEntry<THIS>>> ourBuffer,final MapState<Long, List<IntervalJoinOperator.BufferEntry<OTHER>>> otherBuffer,final long relativeLowerBound,final long relativeUpperBound,final boolean isLeft) throws Exception {final THIS ourValue = record.getValue();final long ourTimestamp = record.getTimestamp();if (ourTimestamp == Long.MIN_VALUE) {throw new FlinkException("Long.MIN_VALUE timestamp: Elements used in " +"interval stream joins need to have timestamps meaningful timestamps.");}if (isLate(ourTimestamp)) {return;}addToBuffer(ourBuffer, ourValue, ourTimestamp);for (Map.Entry<Long, List<BufferEntry<OTHER>>> bucket: otherBuffer.entries()) {final long timestamp = bucket.getKey();if (timestamp < ourTimestamp + relativeLowerBound ||timestamp > ourTimestamp + relativeUpperBound) {continue;}for (BufferEntry<OTHER> entry: bucket.getValue()) {if (isLeft) {collect((T1) ourValue, (T2) entry.element, ourTimestamp, timestamp);} else {collect((T1) entry.element, (T2) ourValue, timestamp, ourTimestamp);}}}long cleanupTime = (relativeUpperBound > 0L) ? ourTimestamp + relativeUpperBound : ourTimestamp;if (isLeft) {internalTimerService.registerEventTimeTimer(CLEANUP_NAMESPACE_LEFT, cleanupTime);} else {internalTimerService.registerEventTimeTimer(CLEANUP_NAMESPACE_RIGHT, cleanupTime);}}
-
取得当前流 StreamRecord 的时间戳,调用 isLate() 方法判断它是否是迟到数据(即时间戳小于当前水印值),如是则丢弃。 -
调用 addToBuffer() 方法,将时间戳和数据一起插入当前流对应的 MapState。 -
遍历另外一个流的 MapState,如果数据满足前述的时间区间条件,则调用 collect() 方法将该条数据投递给用户定义的 ProcessJoinFunction 进行处理。collect() 方法的代码如下,注意结果对应的时间戳是左右流时间戳里较大的那个。
private void collect(T1 left, T2 right, long leftTimestamp, long rightTimestamp) throws Exception {final long resultTimestamp = Math.max(leftTimestamp, rightTimestamp);collector.setAbsoluteTimestamp(resultTimestamp);context.updateTimestamps(leftTimestamp, rightTimestamp, resultTimestamp);userFunction.processElement(left, right, context, collector);}
-
调用 TimerService.registerEventTimeTimer() 注册时间戳为 timestamp + relativeUpperBound 的定时器,该定时器负责在水印超过区间的上界时执行状态的清理逻辑,防止数据堆积。注意左右流的定时器所属的 namespace 是不同的,具体逻辑则位于 onEventTime() 方法中。
@Overridepublic void onEventTime(InternalTimer<K, String> timer) throws Exception {long timerTimestamp = timer.getTimestamp();String namespace = timer.getNamespace();logger.trace("onEventTime @ {}", timerTimestamp);switch (namespace) {case CLEANUP_NAMESPACE_LEFT: {long timestamp = (upperBound <= 0L) ? timerTimestamp : timerTimestamp - upperBound;logger.trace("Removing from left buffer @ {}", timestamp);leftBuffer.remove(timestamp);break;}case CLEANUP_NAMESPACE_RIGHT: {long timestamp = (lowerBound <= 0L) ? timerTimestamp + lowerBound : timerTimestamp;logger.trace("Removing from right buffer @ {}", timestamp);rightBuffer.remove(timestamp);break;}default:throw new RuntimeException("Invalid namespace " + namespace);}}
本文转载自简书,作者:LittleMagic
原文链接:https://www.jianshu.com/p/45ec888332df
 Flink Forward Asia 2020
Flink Forward Asia 2020
以上是关于Flink 双流 Join 的3种操作示例的主要内容,如果未能解决你的问题,请参考以下文章
20.Flink高级特性--新特性--双流Joinjoin的分类API代码演示-WindowJoin代码演示-IntervalJoin
20.Flink高级特性--新特性--双流Joinjoin的分类API代码演示-WindowJoin代码演示-IntervalJoin