flaskcelery+redis 实现定时任务和异步——
Posted 胖虎是只mao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flaskcelery+redis 实现定时任务和异步——相关的知识,希望对你有一定的参考价值。
1. Celery简介
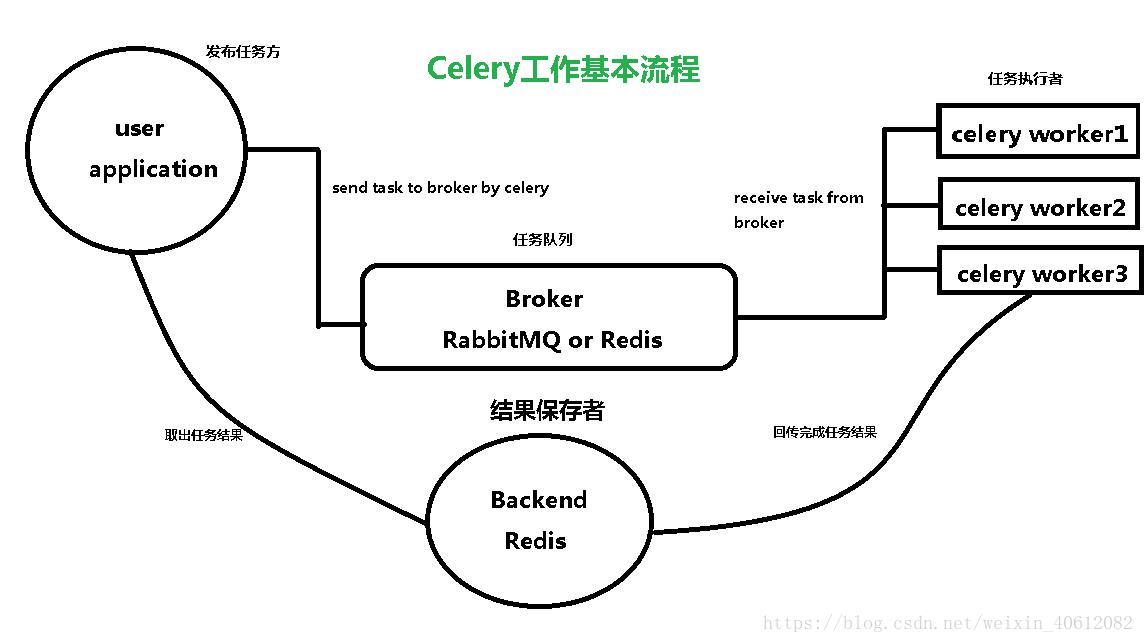
Celery是一个异步任务的调度工具。 Celery 是 Distributed Task Queue,分布式任务队列,分布式决定了可以有多个 worker 的存在,队列表示其是异步操作,即存在一个产生任务提出需求的工头,和一群等着被分配工作的码农。
Broker
在 Python 中定义 Celery 的时候,我们要引入 Broker(消息中间件),中文翻译过来就是“中间人”的意思,在这里 Broker 起到一个中间人的角色。在工头提出任务的时候,把所有的任务放到 Broker 里面,在 Broker 的另外一头,一群码农等着取出一个个任务准备着手做。
Backend
这种模式注定了整个系统会是个开环系统,工头对于码农们把任务做的怎样是不知情的。所以我们要引入 Backend 来保存每次任务的结果。这个 Backend 有点像我们的 Broker,也是存储任务的信息用的,只不过这里存的是那些任务的返回结果。我们可以选择只让错误执行的任务返回结果到 Backend,这样我们取回结果,便可以知道有多少任务执行失败了。
Celery应用场景
1.异步:你想对100台机器执行一条批量命令,可能会花很长时间 ,但你不想让你的程序等着结果返回,而是给你返回 一个任务ID,你过一段时间只需要拿着这个任务id就可以拿到任务执行结果, 在任务执行ing进行时,你可以继续做其它的事情。
2.定时任务:你想做一个定时任务,比如每天检测一下你们所有客户的资料,如果发现今天 是客户的生日,就给他发个短信祝福
Celery的特点:
1.简单:一单熟悉了celery的工作流程后,配置和使用还是比较简单的
2.高可用:当任务执行失败或执行过程中发生连接中断,celery 会自动尝试重新执行任务
3.快速:一个单进程的celery每分钟可处理上百万个任务
3.灵活: 几乎celery的各个组件都可以被扩展及自定制
Celery工作基本流程
我们的项目
项目目录:
from __future__ import absolute_import, unicode_literals
from celery import Celery
app = Celery('proj',
broker = 'amqp://',
backend = 'amqp://',
include = ['proj.tasks'])
app.conf.update(
result_expires = 3600
)
if __name__ == '__main__':
app.start()
在这个模块中创建了Celery实例(通常称为app)
要在项目中使用Celery只需要通过import导入该实例就行了
-
broker参数指定要使用的中间件的URL
-
backend参数指定使用的result backend
用来跟踪任务状态和结果,虽然默认状态下结果不可用。以上例子中使用RPC result backend。当然,不同的result backend都有自己的好处和坏处,根据自己实际情况进行选择,如果不需要最好禁用。通过设置@task(ignore_result=True)选项来禁用耽搁任务) -
include参数是当worker启动时导入的模块列表需要在这里添加自己的任务模块这样worker就可以找到任务
proj/tasks.py
from __future__ import absolute_import, unicode_literals
from .celery import app
@app.task
def add(x, y):
return x + y
@app.task
def mul(x, y):
return x * y
@app.task
def xsum(numbers):
return sum(numbers)
启动worker
Celery程序可以用来启动worker:
celery -A proj worker -l info
-------------- celery@centos6 v4.1.0 (latentcall)
---- **** -----
--- * *** * -- Linux-2.6.32-696.el6.x86_64-x86_64-with-centos-6.9-Final 2018-03-26 12:27:49
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: task:0x7fe5cfbd20d0
- ** ---------- .> transport: amqp://guest:**@localhost:5672//
- ** ---------- .> results: amqp://
- *** --- * --- .> concurrency: 4 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celery
[tasks]
[2018-03-26 12:27:49,921: INFO/MainProcess] Connected to amqp://guest:**@localhost:5672//
[2018-03-26 12:27:49,926: INFO/MainProcess] mingle: searching for neighbors
[2018-03-26 12:27:49,499: INFO/MainProcess] mingle: sync with 1 nodes
[2018-03-26 12:27:50,950: INFO/MainProcess] mingle: sync complete
[2018-03-26 12:27:50,957: INFO/MainProcess] celery@centos6 ready
- broker是在celery模块中指定的中间件参数的url,也可以在命令行中通过
-b选项指定不同的中间件 - Concurrent是用于并行处理的任务的预创建worker进程数量,当所有的任务都在忙于工作时,新的任务必须等待之前的执行完成才能处理
**默认的并发数是机器上CPU的数量,**可以通过celery worker -c选项指定自定义数量。没有推荐值,最佳数量取决于很多因素,但是如果你的任务主要是I/O相关的,就可以增加这个数量。实验表明,增加超过两倍CPU数量效果很差,而且可能会降低性能
除了prefork pool,Celery还支持Eventlet、Gevent并且还能在单线程上运行
- Event是一个可选项,当启用的时候,Celery会发送监控(消息)来反映worker的操作,也可以被用来监视像celery、events和Flower(实时Celery监控)这样的程序。
- Queues是worker将使用的任务的队列的集合,worker可以一次接受几个队列,它用来将消息路由到特定的工作者以作为服务质量、关注点分离、和优化的一种方式
可以通过命令行获取完整的列表————celery worker --help
停止worker
ctrl-c
后台
生产环境中一般将worker放到后台,后台脚本使用celery multi命令后台启动一个或多个worker
celery multi start w1 -A proj -l info
控制台打印
celery multi v4.1.0 (latentcall)
> Starting nodes...
> w1@centos6: OK
Stale pidfile exists - Removing it.
也可以重启:
celery multi restart w1 -A proj -l info
celery multi v4.1.0 (latentcall)
> Stopping nodes...
> w1@centos6: TERM -> 23620
> Waiting for 1 node -> 23620.....
> w1@centos6: OK
> Restarting node w1@centos6: OK
> Waiting for 1 node -> None...
停止:
celery multi stop w1 -A proj -l info
stop命令是异步的所以它不会等待worker关闭,可以使用stopwait命令来确保当前执行都任务在退出前都已执行完毕
celery multi stopwait w1 -A proj -l info
celery multi不会存储关于worker的信息,所以重启的时候需要使用同样的命令行参数。在停止时,必须使用相同的pidfile和logfile参数
默认情况下,程序将在当期目录创建pid和log文件,为了防止多个worker运行出错,推荐将这些文件放在专门的目录:
mkdir -p /var/run/celery
mkdir -p /var/log/celery
celery multi start w1 -A proj -l info --pidfile=/var/run/celery/%n.pid --logfile=/var/log/celery/%n%I.log
使用multi指令可以启动多个worker,并且有一个强大的命令行语法来为不同的worker指定参数:
celery multi start 10 -A proj -l info -Q:1-3 images, video -Q:4, 5 data -Q default -L:4,5 debug
–app参数
–app参数指定使用的Celery应用实例,必须以module.path:attribute的形式出现
但也支持快捷方式,只要包名指定了,就会尝试在应用实例中搜索
使用–app=proj:
- 名为proj.app的属性
- 名为proj.app的属性
- 模块proj中的任何属性都是一个Celery应用程序,如果都没有发现,它就会尝试一个名为proj.celery的子模块
- 名为proj.celery.app的属性
- 名为proj.celery.celery的属性
- 模块proj.celery中的任何属性都是一个Celery应用程序
任务调用
可以通过使用delay()方法来调用一个任务
add.delay(3, 3)
这个方法实际上是另一种叫做apply_async()方法的快捷方式
add.applay_async((3, 3))
后者(applay_async())能够指定执行选项,比如运行时间(倒计时)、应该发送的队列等等:
add.apply_async((2, 2), queue='lopri', countdown=10)
上述案例中,任务会被发送给一个名为lopri的队列,该任务会在信息发送后十秒执行
直接应用该任务会在当前进程中执行任务,不会发送消息
add(3, 3)
====================
result:6
三种方法delay()、apply_async()和应用__call__,代表了Celery调用API,也同样用于签名
-
每一个任务调用都有一个唯一的标识符(UUID),这个就是任务的id
-
delay()和apply_async方法会返回一个AsyncResult实例,可以被用来跟踪任务执行状态,但是需要开启result backend这样状态才能被存储在某处 -
Results默认是禁用的,因为实际上没有一个result backend适用于每个应用程序,所以要考虑到每个独立backend的缺点来选择一个使用。对于许多保持返回值的任务来说都不是很有用,所以这个默认的禁用是很明智的。还需要注意的是,result backend并不用来监控任务和worker,对于Celery有专门的事件消息
如果配置了result backend就可以接收到任务的返回值
result = add.delay(2, 2)
res.get(timeout=1)
retult:4
-
可以通过查看id属性找到任务的id
result:073c568d-ca88-4198-b735-0f98f861218b -
如果任务抛出异常也可以检查到异常,默认result.get()可以传播任何错误
-
如果不希望错误传播,可以通过propagete属性禁用
res.get(propagate=False)
在这种情况下,它会返回所提出的异常实例,以便检查任务是否成功或失败,您将不得不在结果实例上使用相应的方法
res.failed()
res.successful()
也可以通过state找到任务的状态:
res.state
result:FAILUTE
- 一个任务只能有一个状态,但是可以在几个状态中发展,典型任务阶段可能是这样
PENDING -> STARTED -> SUCCESS
STARTED状态是一个特殊的状态,只有在task_track_started设置启用或者@task(track_started=True)选项设置的时候才会被记录下来
PENDING状态实际上不是记录状态,而是未知任务id的默认状态
from proj.celery import app
res = app.AsyncResult('this-id-does-not-exist')
res.state
result:PENDING
- 如果重新尝试这个任务可能会变得更复杂,对于一个尝试过两遍的任务来说阶段可能是这样:
PENDING -> STARTED -> RETRY -> STARTED -> RETRY -> STARTED -> SUCCESS
Canvas:设计任务流
前面学习了通过delay方法调用任务,通常这样就够了,但是有时可能需要将任务调用的签名传递给另一个进程或者另一个函数的参数,对Celery来说叫做signatures
签名以某种方式包装了单一任务调用的参数和执行选项,以便将其传递给函数,甚至序列化后发送。
可以使用参数(2, 2)和十秒的计时器来为add任务创建一个签名
add.signature((2, 2), countdown=10)
也可以简写:
add.s(2, 2)
调用API
签名的实例也支持调用API,意味着也可以有delay和apply_async方法
但是有一个区别,那就是签名可能已经指定了一个参数签名,add任务接受两个参数,所以一个指定了两个参数的签名将会形成一个完整的签名
s1 = add.s(2, 2)
res = s1.delay()
res.get()
也可以使用不完整的签名,叫做partials:
s2 = add.s(2)
s2现在是部分签名,需要另一个参数才完整,则可以在调用signature的时候处理
# resolves the partial: add(8, 2)
res = s2.delay(8)
res.get()
在这里,添加了参数8,对已存在的参数2组成了一个完整的签名add(8, 2)
关键字参数也可以延迟添加,会和已存在的关键字参数合并,新参数优先(新参数覆盖旧参数)
s3 = add.s(2, 2, debug=True)
s3.delay(debug=False)
已声明的签名支持调用API:
- sig.apply_async(arg=(), kwargs={}, **options
使用可选部分参数和部分关键字参数调用签名,也支持部分可执行选项 - sig.delay(*args, **kwargs)
apply_async的星参版本,任何参数都会被预先记录在签名的参数你,关键字参数会和现有的keys合并
基本体
- group
- chain
- chord
- map
- starmap
- chunks
这些基本体本身就是签名对象,因此,它们可以以任何多种方式组合起来组成复杂的工作流
Group
一个group同时调用任务列表,返回一个特殊结果实例,这样可以以组的形式检查结果,并按顺序检索返回值
from celery import group
from proj.tasks import add
group(add.s(i, i) for in in range(10))().get()
result:[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
- Partial group
g = group(add.s(i, i) for i in range(10))
g(10).get()
result:[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
Chains
任务可以被相互连接起来,这样在一个任务返回后另一个任务被调用
from celery import chain
form proj.tasks import add, mul
// 用法1
chian(add.s(4, 4) | mul.s(8))().get()
// 用法2
g = chain(add.s(4) | mul.s(8))
g(4).get()
// 用法3
(add.s(4, 4) | mul.s(8))().get()
Chords
chord是一个有返回值的group
from celery import chord
from proj.tasks import add, xsum
// 用法1
(group(add.s(i, i) for i in range(10)) | xsum.s())().get()
// 用法2
upload_document.s(file) | group(apply_filter.s() for filter in filters)
路由
Celery支持AMQP提供的所有路由设施,但是它也支持简单路由,将消息发送到指定的队列
task_routes设置可以是用户按名称对任务进行路由,并将一切集中在一个位置
app.conf.update{
task_routes = {
'proj.tasks.add': {'queue': 'hipri'},
}
}
可以在运行时通过queue参数指定队列到apply_async:
from proj.tasks import add
add.apply_async((2,2), queue='hipri')
然后可以通过指定celery worker -Q选项使worker从队列中消费
celery -A proj worker -Q hipri
也可以通过使用逗号分隔符(,)来指定多个队列
celery -A proj worker -Q hipri, celery
默认队列因为历史原因命名为:celery
队列的顺序无关紧要,因为worker会给队列相同的权重
远程控制
如果使用RabbitMQ(AMQP)、Redis或者Qpid作为中间件就可以在运行时监视worker。也就是broker 消息中间件
- 查看worker当前执行的任务
celery -A proj inspect active
这是通过使用广播消息实现的,因此,集群中的每一个工作人员都能接收到所有远程控制命令
- 也可以指令一个或多个worker使用
--destination选项请求行动,这是一个逗号分隔的worker主机名列表
celery -A proj inspect active --destination=celery@example.com
如果没有提供目标,那么每个worker都会对请求做出反应并回复
Celery inspect命令包含的命令不会改变worker的任何东西,它只会回复关于worker内部发生的事情的信息和统计信息,可以执行命令检查列表:
celery -A proj inspect --help
celery control命令,包含在运行时实际改变worker操作的命令
celery -A proj control --help
- 强制worker启用事件消息(用于监视任务和工作人员)
celery -A proj control enable_events
当事件激活,可以启动event dumper查看worker正在做什么
celery -A proj events --dump
或者
celery -A proj events
当完成监控可以再次禁用events
celery -A proj control disable_events
- celery status命令还能使用远程控制命令,并显示集群中的在线worker列表
celery -A proj status
时区
所有的时间和日期、内部和消息多使用UTC时间区域
当worker收到消息,例如使用倒计时设置,它将UTC时间转换为本地时间。如果希望使用与系统时区不同的地区,那么必须要使用时区设置来配置该时区:
app.conf.timezone = 'Asia/Shanghai'
最优化
默认的配置并没有针对吞吐量进行优化,它试图在许多短任务和更少的长任务之间走中间路线,这是吞吐量和公平调度之间的折中
简易的celery 定时任务例子:
现在有需求需要添加定时任务
例如每一小时检查一下还在使用的,但是未同步到CDN的文件,然后进行同步
配置过程
celery的配置,task的编写都和之前区别不大
关键在这个参数(例如写在celeryconfig.py中)
CELERYBEAT_SCHEDULE = {
'every-minute': {
'task': 'celery_tasks.used_apk_cdn',
# 'schedule': crontab(minute='*/1'),
# 'args': (1,2),
'schedule': timedelta(seconds=5)
},
}
要把这个配置传递给celery,可以用这个
celery.config_from_object('celeryconfig')
具体的task举例:
@celery.task(name='celery_tasks.used_apk_cdn')
def used_apk_cdn():
logging.info("lalala")
pass
最后,命令行启动celery即可
$ celery -A tasks worker --loglevel=info
这个定时task和原先的flask的异步task可以并行不冲突,运行celery都会启动,关键在于配置参数的conf。
以上是关于flaskcelery+redis 实现定时任务和异步——的主要内容,如果未能解决你的问题,请参考以下文章