python 复习—并发编程——线程锁threading.local线程池生产者消费者模型线程安全
Posted 胖虎是只mao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 复习—并发编程——线程锁threading.local线程池生产者消费者模型线程安全相关的知识,希望对你有一定的参考价值。
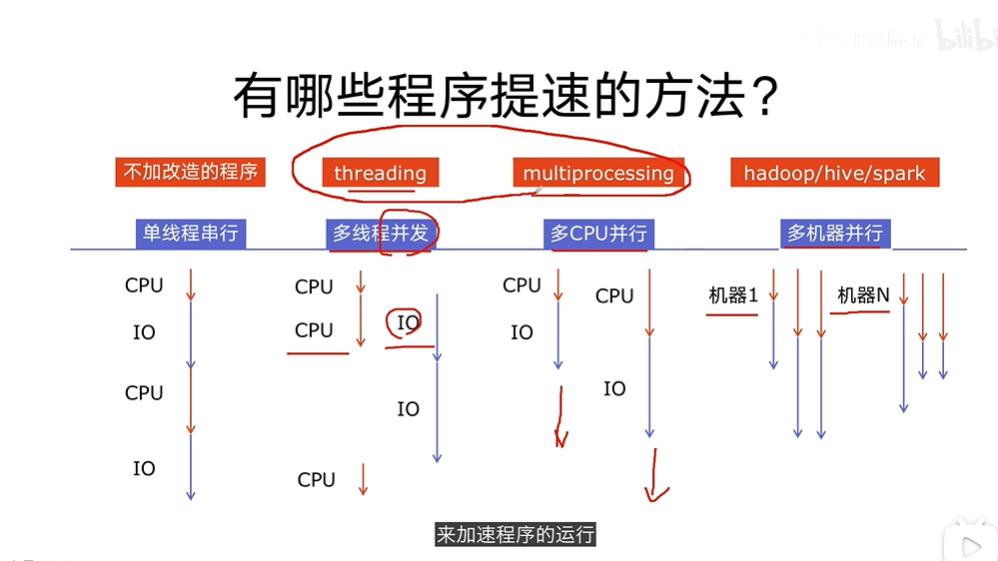
一、线程锁
线程安全,多线程操作时,内部会让所有线程排队处理。如:list/dict/Queue
线程不安全 + 人(锁) => 排队处理
1、RLock/Lock:一次放一个
a、创建10个线程,在列表中追加自己,如下代码:
import threading
v = []
def func(arg):
v.append(arg)
print(v)
for i in range(10):
t = threading.Thread(target=func, args=(i,))
t.start()
b、创建10个线程,把自己添加到列表中,再读取列表的最后一个,如下代码:
import threading
import time
v = []
lock = threading.Lock()
def func(arg):
lock.acquire() # 加锁
v.append(arg)
time.sleep(0.01)
m = v[-1]
print(arg,m)
lock.release() # 释放锁
for i in range(10):
t = threading.Thread(target=func, args=(i,))
t.start()
注意:RLock和Lock用法一样,只是Lock只能锁一次解一次,RLock支持锁多次解多次,以后用RLock。
2、BoundedSemaphore(n) ,信号量, 一次放n个,如下代码:
import threading
import time
lock = threading.BoundedSemaphore(3)
def func(arg):
lock.acquire() # 加锁
time.sleep(1)
print(arg)
lock.release() # 释放锁
for i in range(10):
t = threading.Thread(target=func, args=(i,))
t.start()
3、condition(),一次放x个,x可由用户动态输入,代码如下:
1)方式一:
import time
import threading
lock = threading.Condition()
def func(arg):
print('线程进来了')
lock.acquire()
lock.wait() # 加锁
print(arg)
time.sleep(1)
lock.release()
for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start()
while True:
inp = int(input('>>>'))
lock.acquire()
lock.notify(inp)
lock.release()
2)方式二:
import time
import threading
lock = threading.Condition()
def f1():
print('来执行函数了')
input(">>>")
return True
def func(arg):
print('线程进来了')
lock.wait_for(f1) # 等函数f1执行完毕后继续往下走
print(arg)
time.sleep(1)
for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start()
4、Event,一次放所有,如下示例:
import threading
lock = threading.Event()
def func(arg):
print('线程来了')
lock.wait() # 加锁:红灯
print(arg)
for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start()
input(">>>")
lock.set() # 绿灯
lock.clear() # 再次变红灯
for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start()
input(">>>")
lock.set()
总结:
线程安全,列表和字典线程安全;
为什么要加锁? 非线程安全,控制一段代码;
二、threading.local()
作用:内部自动为每个线程维护一个空间(本质是字典),用于当前线程存取属于自己的值,保证线程之间的数据隔离。(项目常用)
{
线程ID : { . . . },
线程ID : { . . . },
线程ID : { . . . },
线程ID : { . . . },
}
threading.local()的原理:
"""
以后:Flask框架内部看到源码 上下文管理
"""
import time
import threading
INFO = {}
class Local(object):
def __getattr__(self, item):
ident = threading.get_ident()
return INFO[ident][item]
def __setattr__(self, key, value):
ident = threading.get_ident()
if ident in INFO:
INFO[ident][key] = value
else:
INFO[ident] = {key:value}
obj = Local()
def func(arg):
obj.phone = arg # 调用对象的 __setattr__方法(“phone”,1)
time.sleep(2)
print(obj.phone,arg)
for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start()
get_ident()是Python中线程模块的内置方法。 它用于返回当前线程的“线程标识符”。 当一个线程退出并创建另一个线程时,可以回收线程标识符。 该值没有直接含义。
INFO = {}
class Local(object):
def __getattr__(self, item):
ident = threading.get_ident()
return INFO[ident][item]
def __setattr__(self, key, value):
ident = threading.get_ident()
if ident in INFO:
INFO[ident][key] = value
else:
INFO[ident] = {key:value}
obj = Local()
def func(arg):
obj.phone = arg # 调用对象的 __setattr__方法(“phone”,1)
time.sleep(2)
print(obj.phone,arg)
for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start()
三、线程池
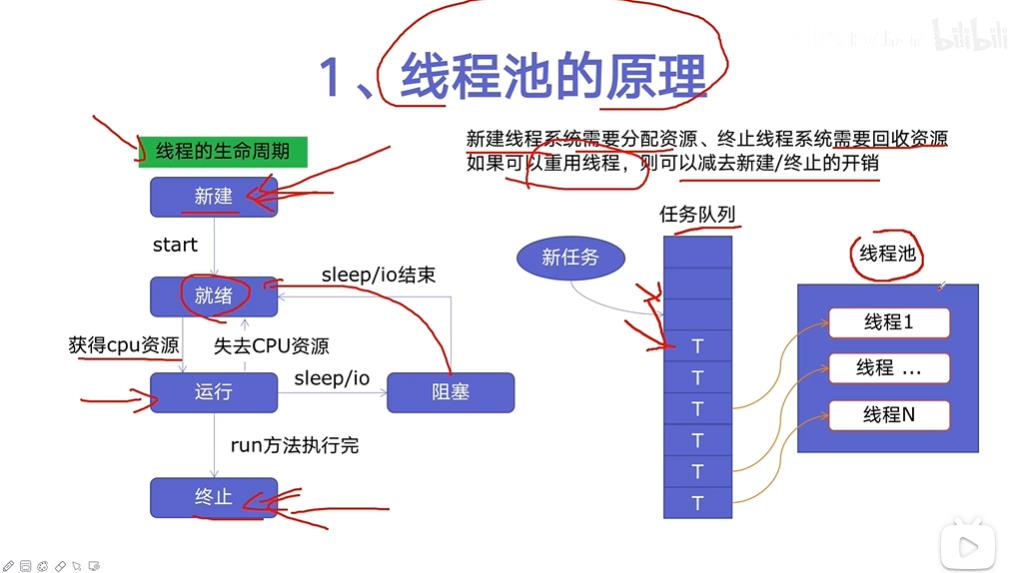
生命周期流程:
新建线程调用start方法,进入就绪状态,此时并没有真正运行。因为一个现成的运行是需要系统进行调度的,系统调度使得线程获得cpu的资源,进入运行状态。当运行过程中,可能失去cpu的资源,又回到就绪状态;也可能当cpu 遇到sleep或者io时,进入阻塞状态。然后等到sleep或者io 结束,阻塞状态会回到就绪状态等待系统的调度,当这个线程执行完了或者线程被终止,就会进入终止的状态。

以后写代码不要一个一个创建线程,而是创建一个线程池,再去线程池申请线程去执行任务,如下示例:
from concurrent.futures import ThreadPoolExecutor
import time
def task(a1,a2):
time.sleep(2)
print(a1,a2)
# 创建了一个线程池(最多5个线程)
pool = ThreadPoolExecutor(5)
for i in range(40):
# 去线程池中申请一个线程,让线程执行task函数。
pool.submit(task,i,8)
线程池有两种方法使用 pool.map()和 pool.submit()

as_completed() 函数不管哪个任务先执行完了,会先进行返回,不必按照顺序进行返回。
四、生产者消费者模型
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。
该模式通过平衡生产进程和消费进程的工作能力来提高程序的整体处理数据的速度。
举个应用栗子:
全栈开发时候,前端接收客户请求,后端处理请求逻辑。
当某时刻客户请求过于多的时候,后端处理不过来,
此时完全可以借助队列来辅助,将客户请求放入队列中,
后端逻辑代码处理完一批客户请求后马上从队列中继续获取,
这样平衡两端的效率。
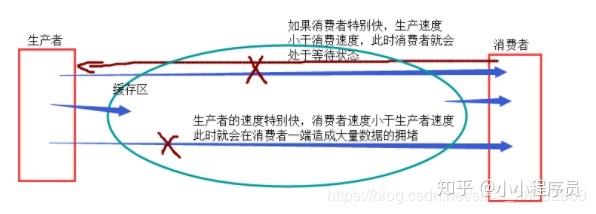
为什么要使用生产者和消费者模式
在进程世界里,生产者就是生产数据的进程,消费者就是消费数据的进程。
在多进程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。
同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。
为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。
生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,
所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,
消费者不找生产者要数据,而是直接从阻塞队列里取,
阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
三部分:生产者,消费者,队列
**队列:先进先出
栈:后进先出**
问题1:生产者消费者模型解决了什么问题?不用一直等待的问题。如下示例:
import time
import queue
import threading
q = queue.Queue() # 线程安全
def producer(id):
"""
生产者
:return:
"""
while True:
time.sleep(2)
q.put('包子')
print('厨师%s 生产了一个包子' %id )
for i in range(1,4):
t = threading.Thread(target=producer,args=(i,))
t.start()
def consumer(id):
"""
消费者
:return:
"""
while True:
time.sleep(1)
v = q.get()
print('顾客 %s 吃了一个%s' % (id,v))
for i in range(1,3):
t = threading.Thread(target=consumer,args=(i,))
t.start()
三种方法实现 生产者消费者模型:
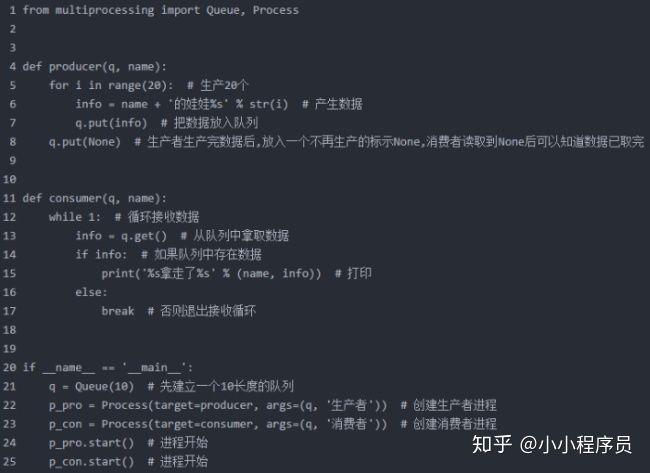
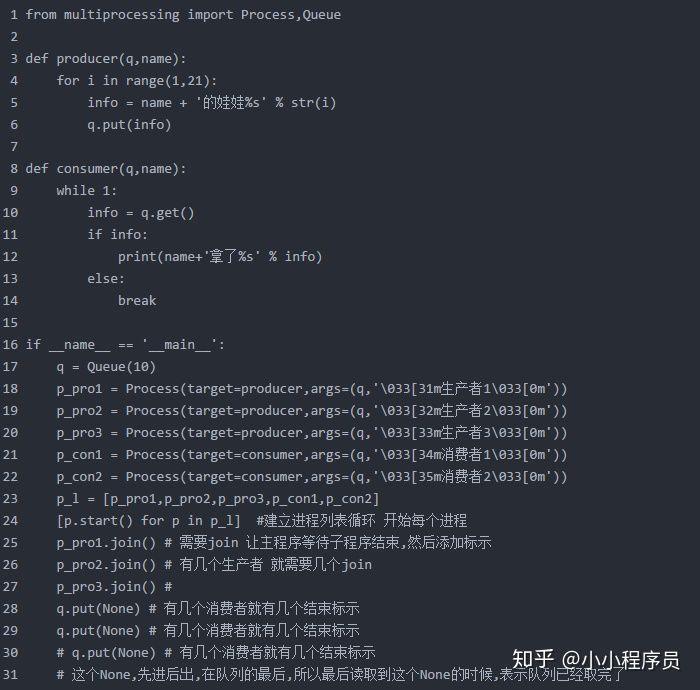
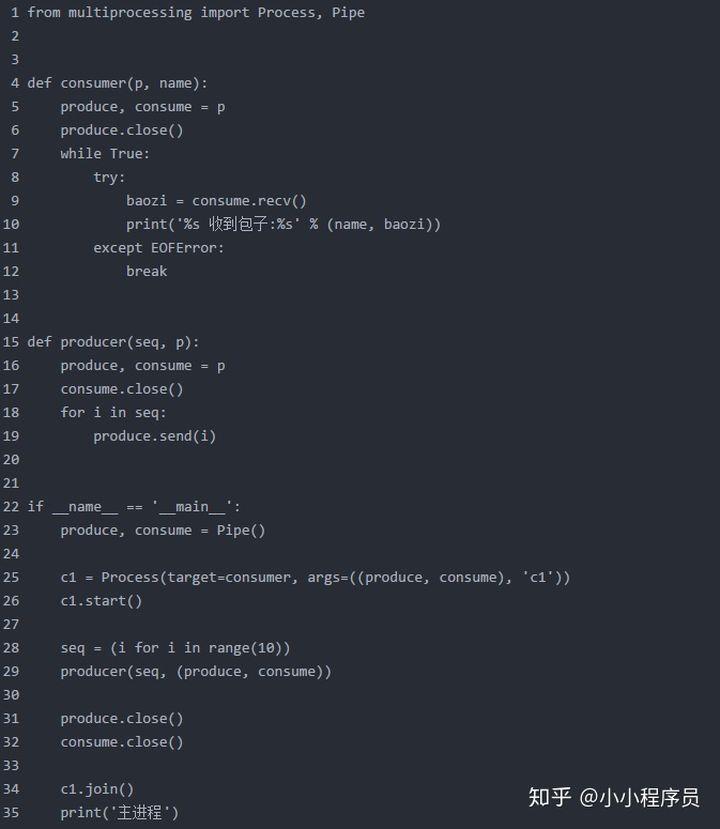
我们的思路就是发送结束信号而已,有另外一种队列提供了这种机制。
JoinableQueue([maxsize])
这就像是一个Queue对象,但队列允许项目的使用者通知生产者项目已经被处理。通知进程是使用共享的信号和条件变量来实现的。
其中maxsize是队列中允许最大项数,省略则无大小限制。
JoinableQueue的实例q除了与Queue对象相同的方法之外还具有:
task_done():消费者用此方法发出信息,表示q.get()的返回项目已经被处理。如果调用此方法的次数大于从队列中删除项目的数量,将会导致ValueError异常。
join():生产者调用此方法进行阻塞,直到队列中所有的项目都被处理了。
import time
import random
from multiprocessing import Process
from multiprocessing import JoinableQueue
def consumer(name,q):
while True:
res=q.get()
time.sleep(random.randint(1,3))
print('\\033[43m消费者》》%s 准备开吃%s\\033[0m'%(name,res))
q.task_done()#发送信号给生产者的q.join()说,已经处理完从队列中拿走的一个项目
def producer(name,q):
for i in range(5):
time.sleep(random.randint(1,2))#模拟生产时间
res='大虾%s'%i
q.put(res)
print('\\033[40m生产者》》》%s 生产了%s\\033[0m'%(name,res))
q.join()#等到消费者把自己放入队列中的所有项目都取走处理完后调用task_done()之后,生产者才能结束
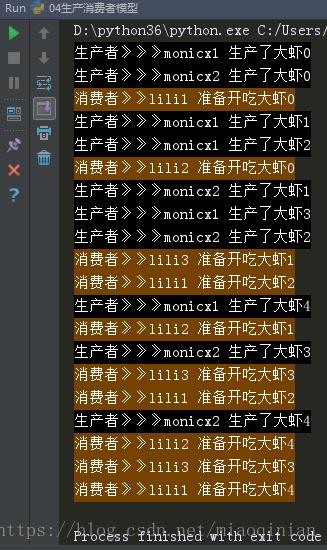
if __name__ == '__main__':
q=JoinableQueue()#实例一个队列
p1=Process(target=producer,args=('monicx1',q))
p2=Process(target=producer,args=('monicx2',q))
c1=Process(target=consumer,args=('lili1',q))
c2=Process(target=consumer,args=('lili2',q))
c3=Process(target=consumer,args=('lili3',q))
c1.daemon=True
c2.daemon=True
c3.daemon=True
p1.start()
p2.start()
c1.start()
c2.start()
c3.start()
p1.join()
p2.join()
五、面向对象补充(了解,以后不会写,flask源码中会遇到)
class Foo(object):
def __init__(self):
self.name = 'alex'
def __setattr__(self, key, value):
print(key,value)
obj = Foo() # 结果为:name alex (说明执行了Foo的__setattr__方法)
# 分析:因为obj.x自动执行__setattr__
print(obj.name) # 报错
# 分析:__setattr__方法中没有设置的操作,只有打印
示例一:
class Foo(object):
def __init__(self):
object.__setattr__(self, 'info', {}) # 在对象中设置值的本质
def __setattr__(self, key, value):
self.info[key] = value
def __getattr__(self, item):
return self.info[item]
obj = Foo()
obj.name = 'alex'
print(obj.name)
示例二:
线程安全

产生线程安全的原因: 多线程的环境下,系统会随时发生线程的切换
所以通过锁的方式 解决线程安全问题

如下例子:
import threading
import time
lock = threading.Lock()
class Account:
def __init__(self, balance):
self.balance = balance
def draw(account, amount):
with lock:
if account.balance >= amount:
time.sleep(0.1)
print(threading.current_thread().name,
"取钱成功")
account.balance -= amount
print(threading.current_thread().name,
"余额", account.balance)
else:
print(threading.current_thread().name,
"取钱失败,余额不足")
if __name__ == "__main__":
account = Account(1000)
ta = threading.Thread(name="ta", target=draw, args=(account, 800))
tb = threading.Thread(name="tb", target=draw, args=(account, 800))
ta.start()
tb.start()
以上是关于python 复习—并发编程——线程锁threading.local线程池生产者消费者模型线程安全的主要内容,如果未能解决你的问题,请参考以下文章