python 复习—并发编程——进程数据共享进程锁进程池requests模块和bs4(beautifulsoup)模块
Posted 胖虎是只mao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 复习—并发编程——进程数据共享进程锁进程池requests模块和bs4(beautifulsoup)模块相关的知识,希望对你有一定的参考价值。
一、进程
1、进程间数据不共享,每个进程都有自己的一个列表,如下示例:
import multiprocessing
data_list = []
def task(arg):
data_list.append(arg)
print(data_list) # 每个进程都有自己的一个列表
def run():
for i in range(10):
p = multiprocessing.Process(target=task,args=(i,))
p.start()
if __name__ == '__main__':
run()
2、进程的常用功能
join(6)等待进程完成,最多等6秒
import multiprocessing
import time
def task(arg):
time.sleep(2)
print(arg)
def run():
print(11111111)
p1 = multiprocessing.Process(target=task,args=(1,))
p1.start()
p1.join(6) # 等待进程完成,最多等6秒
print(22222222)
p2 = multiprocessing.Process(target=task,args=(2,))
p2.start()
p2.join()
print(33333333)
if __name__ == '__main__':
run()
join
p1.daemon = False # 等待进程完成,默认
import multiprocessing
import time
def task(arg):
time.sleep(2)
print(arg)
def run():
print(11111111)
p1 = multiprocessing.Process(target=task,args=(1,))
p1.daemon = False # 等待进程完成,默认
p1.start()
print(22222222)
p2 = multiprocessing.Process(target=task,args=(2,))
p2.daemon = True # 不等进程完成
p2.start()
print(33333333)
if __name__ == '__main__':
run()
daemon
p = multiprocessing.current_process() # 获取当前进程
name = p.name 获取当前进名称
id1 = p.ident # 获取进程id
id2 = p.pid # 获取进程id
import multiprocessing
import time
def task(arg):
time.sleep(2)
p = multiprocessing.current_process() # 获取当前进程
name = p.name
id1 = p.ident # 获取进程id
id2 = p.pid # 获取进程id
print(arg,name,id1,id2)
def run():
print(11111111)
p1 = multiprocessing.Process(target=task,args=(1,))
p1.name = 'pp1' # 为进程设置名字pp1
p1.start()
print(22222222)
p2 = multiprocessing.Process(target=task,args=(2,))
p2.name = 'pp2' # 为进程设置名字pp2
p2.start()
print(33333333)
if __name__ == '__main__':
run()
name / current_process() / ident/pid
二、数据共享(内存级别)
线程安全是 多个线程同时并发的访问数据,不会出现冲突
1、Queue
linux示例:
import multiprocessing
q = multiprocessing.Queue()
def task(arg,q):
q.put(arg)
def run():
for i in range(10):
p = multiprocessing.Process(target=task, args=(i, q,))
p.start()
while True:
v = q.get()
print(v)
run()
import multiprocessing
def task(arg,q):
q.put(arg)
if __name__ == '__main__':
q = multiprocessing.Queue()
for i in range(10):
p = multiprocessing.Process(target=task,args=(i,q,))
p.start()
while True:
v = q.get()
print(v)
windows示例:
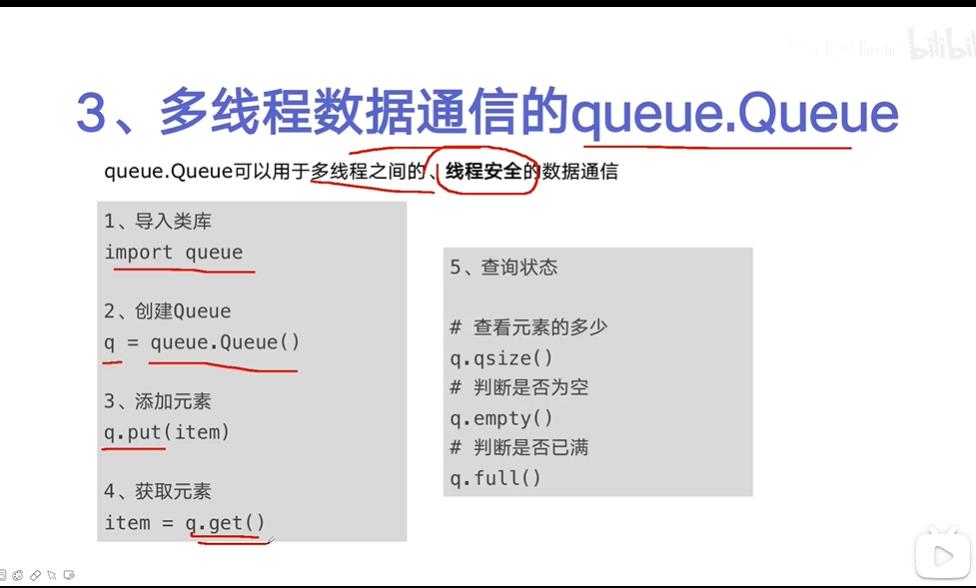
put()和 get() 方法都是阻塞的
get() 会卡住,直到有数据取出来
put() 当队列满了之后,会卡住,知道有空闲的位置之后,才能put进去
2、Manager
import multiprocessing
m = multiprocessing.Manager()
dic = m.dict()
def task(arg):
dic[arg] = 100
def run():
for i in range(10):
p = multiprocessing.Process(target=task, args=(i,))
p.start()
input('>>>')
print(dic.values())
if __name__ == '__main__':
run()
linux示例:
import multiprocessing
import time
def task(arg,dic):
time.sleep(2)
dic[arg] = 100
if __name__ == '__main__':
m = multiprocessing.Manager()
dic = m.dict()
process_list = []
for i in range(10):
p = multiprocessing.Process(target=task, args=(i,dic,))
p.start()
process_list.append(p)
while True:
count = 0
for p in process_list:
if not p.is_alive(): # 如果某进程已经执行完毕,则count加1
count += 1
if count == len(process_list):
break
print(dic)
windows示例:
三、进程锁
进程锁同线程锁的种类和用法一样,参见线程锁。如下是进程锁RLock示例:
import time
import multiprocessing
lock = multiprocessing.RLock()
def task(arg):
print('鬼子来了')
lock.acquire()
time.sleep(2)
print(arg)
lock.release()
if __name__ == '__main__':
p1 = multiprocessing.Process(target=task,args=(1,))
p1.start()
p2 = multiprocessing.Process(target=task, args=(2,))
p2.start()
问题1:为什么要加进程锁?
线程锁是为了在线程不安全的时候,为一段代码加上锁来控制实现线程安全,即线程间数据隔离;
进程间的数据本来就是隔离的,所以一般不用加锁,当进程间共用某个数据的时候需要加锁;
四、进程池
import time
from concurrent.futures import ProcessPoolExecutor
def task(arg):
time.sleep(2)
print(arg)
if __name__ == '__main__':
pool = ProcessPoolExecutor(5) # 创建一个进程池
for i in range(10):
pool.submit(task,i)
五、requests模块和bs4(beautifulsoup)模块 – (初识爬虫)
1、安装:
pip3 install requests
pip3 install beautifulsoup4
2、示例代码(爬取抽屉网的标题和链接):
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
# 模拟浏览器发送请求
# 内部创建 sk = socket.socket()
# 和抽屉进行socket连接 sk.connect(...)
# sk.sendall('...')
# sk.recv(...)
def task(url):
print(url)
r1 = requests.get(
url=url,
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/69.0.3497.92 Safari/537.36'
}
)
# 查看下载下来的文本信息
soup = BeautifulSoup(r1.text,'html.parser')
# print(soup.text)
content_list = soup.find('div',attrs={'id':'content-list'})
for item in content_list.find_all('div',attrs={'class':'item'}):
title = item.find('a').text.strip()
target_url = item.find('a').get('href')
print(title,target_url)
def run():
pool = ThreadPoolExecutor(5)
for i in range(1,50):
pool.submit(task,'https://dig.chouti.com/all/hot/recent/%s' %i)
if __name__ == '__main__':
run()
总结:
1)以上示例进程和线程哪个好?
线程好,因为socket属于IO请求,不占用CPU,所以用多线程即节省资源又提高效率;
2)requests模块模拟浏览器发送请求:
requests.get( . . . ) 本质:
创建socket客户端
连接【阻塞】
发送请求
接收请求【阻塞】
断开连接
以上是关于python 复习—并发编程——进程数据共享进程锁进程池requests模块和bs4(beautifulsoup)模块的主要内容,如果未能解决你的问题,请参考以下文章
python 复习—并发编程系统并发线程和进程协程GIL锁CPU/IO密集型计算
python并发编程之多进程:互斥锁(同步锁)&进程其他属性&进程间通信(queue)&生产者消费者模型
Python之路(第三十八篇) 并发编程:进程同步锁/互斥锁信号量事件队列生产者消费者模型