python 复习—并发编程实战——线程多进程多协程加速程序运行实例(多线程和多进程的对比)
Posted 胖虎是只mao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 复习—并发编程实战——线程多进程多协程加速程序运行实例(多线程和多进程的对比)相关的知识,希望对你有一定的参考价值。
一、多线程实例
import threading
import time
lock = threading.Lock()
class Account:
def __init__(self, balance):
self.balance = balance
def draw(account, amount):
with lock:
if account.balance >= amount:
time.sleep(0.1)
print(threading.current_thread().name,
"取钱成功")
account.balance -= amount
print(threading.current_thread().name,
"余额", account.balance)
else:
print(threading.current_thread().name,
"取钱失败,余额不足")
if __name__ == "__main__":
account = Account(1000)
ta = threading.Thread(name="ta", target=draw, args=(account, 800))
tb = threading.Thread(name="tb", target=draw, args=(account, 800))
ta.start()
tb.start()
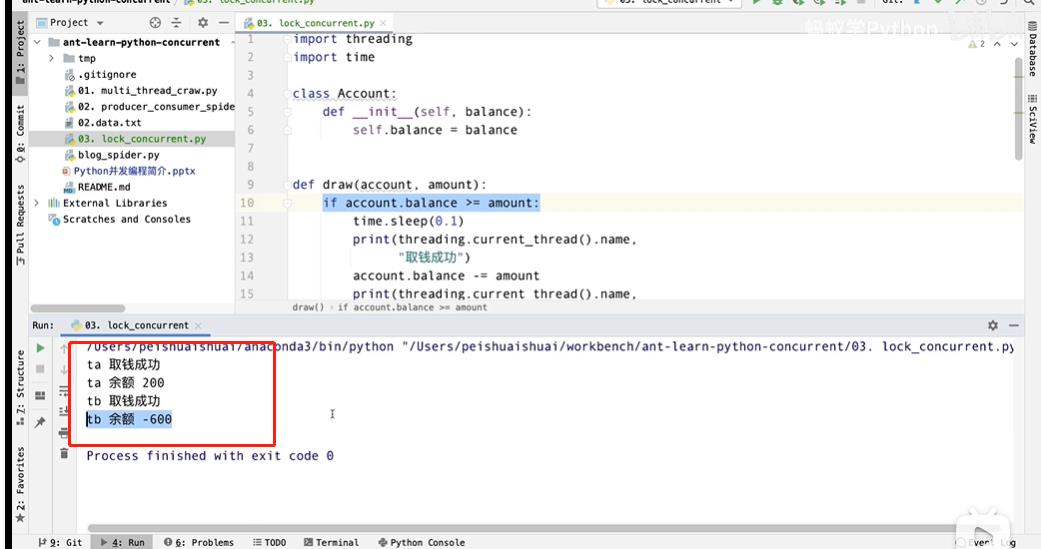
不加time.sleep 之前,线程会随机切换,导致余额随机变化。
加上后或者进行了远程调用,time.sleep一定会导致线程的阻塞,导致线程的切换,余额会变成 -600,出现问题
sleep 本身相当于做了一次IO操作
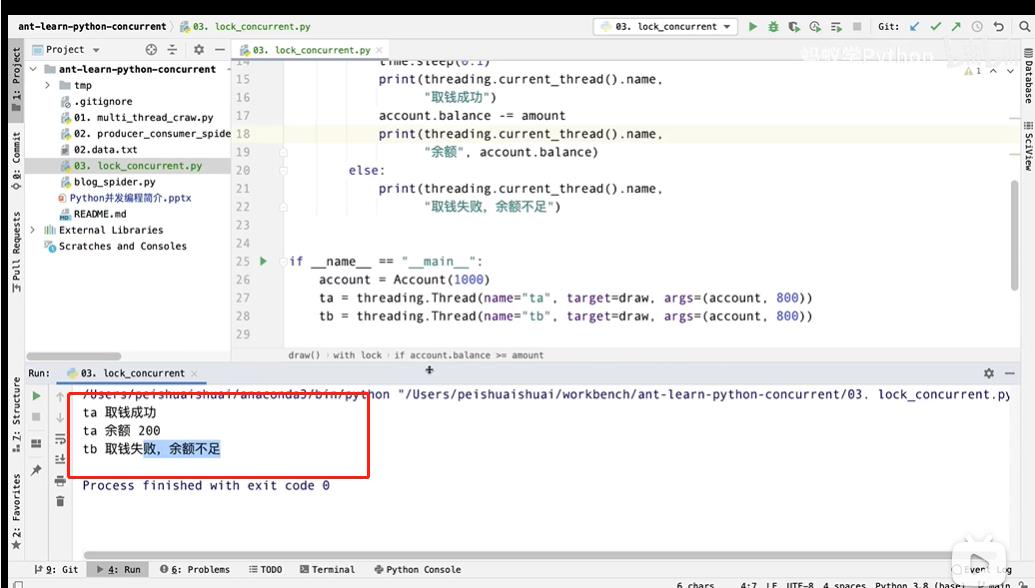
所以只能加lock锁, with lock, 代码运行正常。
第二个线程获取不到锁,就没法执行,只有第一个线程执行完,释放锁之后。第二个线程获得锁,才能执行
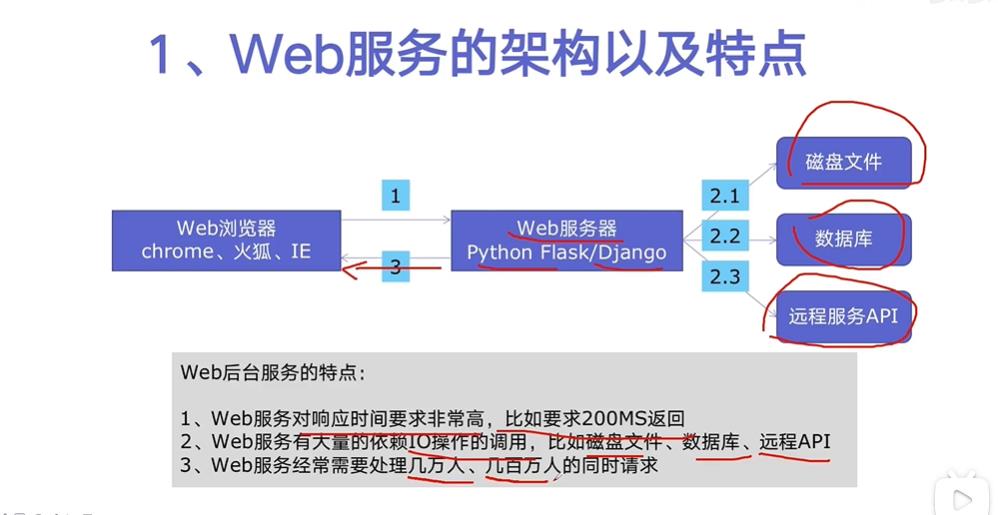
二 、WEB服务的架构与特点
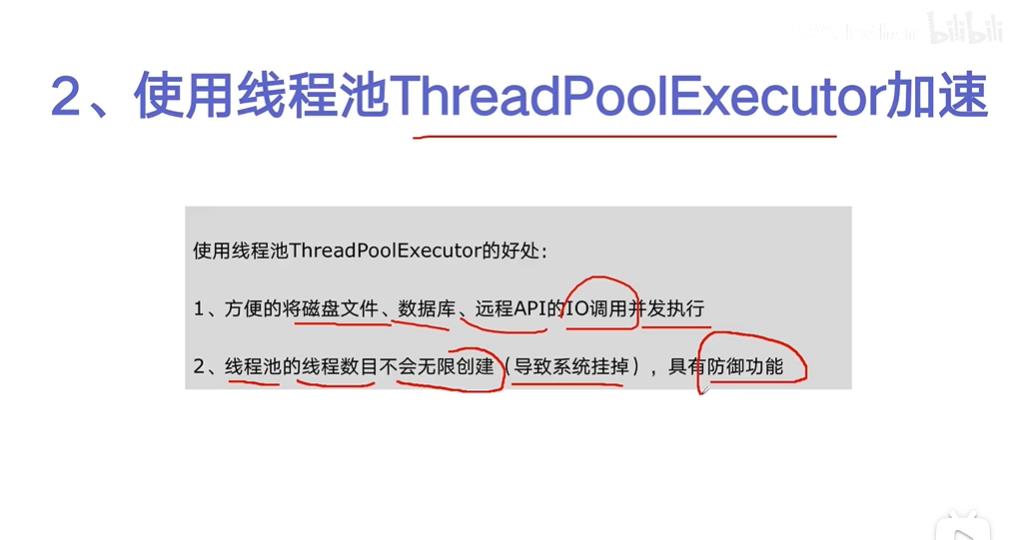
三、使用线程池 ThreadingPoolExecutor加速
✨
从Python3.2开始,标准库为我们提供了 concurrent.futures 模块,它提供了 ThreadPoolExecutor (线程池)和ProcessPoolExecutor (进程池)两个类。
相比 threading 等模块,该模块通过 submit 返回的是一个 future 对象,它是一个未来可期的对象,通过它可以获悉线程的状态主线程(或进程)中可以获取某一个线程(进程)执行的状态或者某一个任务执行的状态及返回值:
主线程可以获取某一个线程(或者任务的)的状态,以及返回值。
当一个线程完成的时候,主线程能够立即知道。
让多线程和多进程的编码接口一致。
线程池代码实例:
import flask
import json
import time
from concurrent.futures import ThreadPoolExecutor # 需安装
app = flask.Flask(__name__)
pool = ThreadPoolExecutor()
def read_file():
time.sleep(0.1)
return "file result"
def read_db():
time.sleep(0.2)
return "db result"
def read_api():
time.sleep(0.3)
return "api result"
@app.route("/")
def index():
result_file = pool.submit(read_file)
result_db = pool.submit(read_db)
result_api = pool.submit(read_api)
return json.dumps({
"result_file": result_file.result(),
"result_db": result_db.result(),
"result_api": result_api.result(),
})
if __name__ == "__main__":
app.run()
有了多线程 ,为什么还要用多进程
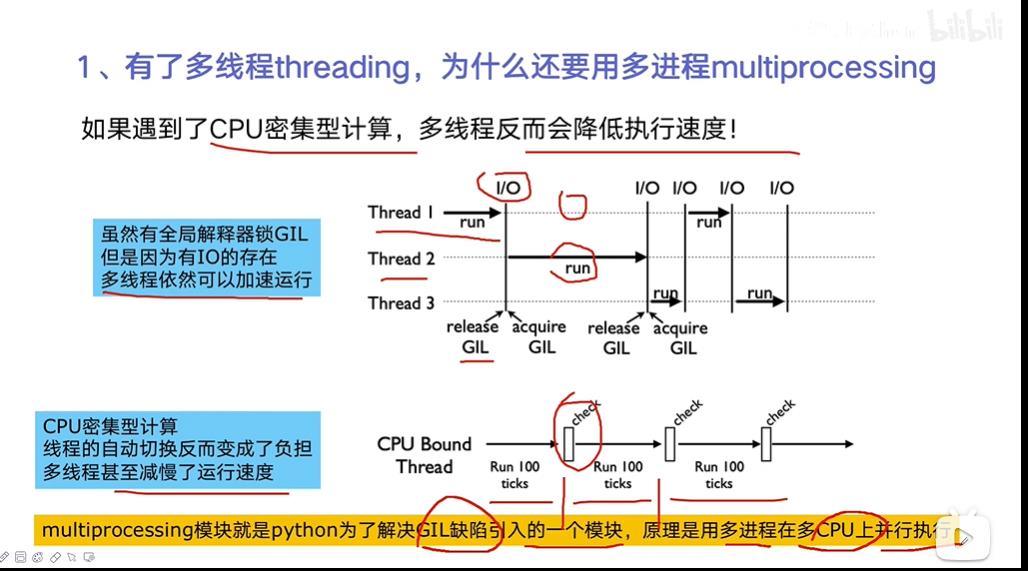
四、多线程和多进程的对比 (重要)

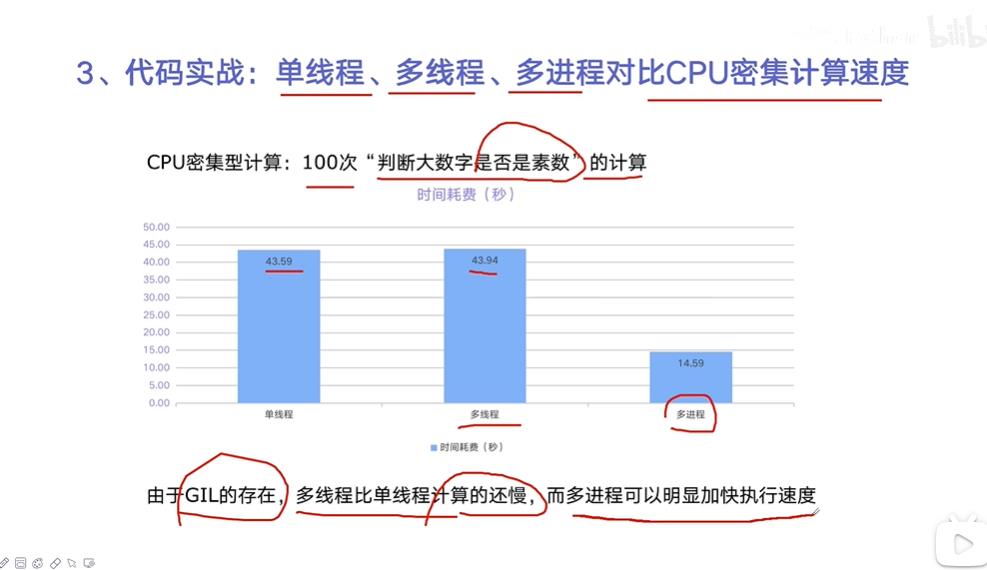
代码实例:
CPU密集型计算下,单线程、多线程、单进程的对比
import math
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import time
PRIMES = [112272535095293] * 100
def is_prime(n):
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def single_thread():
for number in PRIMES:
is_prime(number)
def multi_thread():
with ThreadPoolExecutor() as pool:
pool.map(is_prime, PRIMES)
def multi_process():
with ProcessPoolExecutor() as pool:
pool.map(is_prime, PRIMES)
if __name__ == "__main__":
start = time.time()
single_thread()
end = time.time()
print("single_thread, cost:", end - start, "seconds")
start = time.time()
multi_thread()
end = time.time()
print("multi_thread, cost:", end - start, "seconds")
start = time.time()
multi_process()
end = time.time()
print("multi_process, cost:", end - start, "seconds")
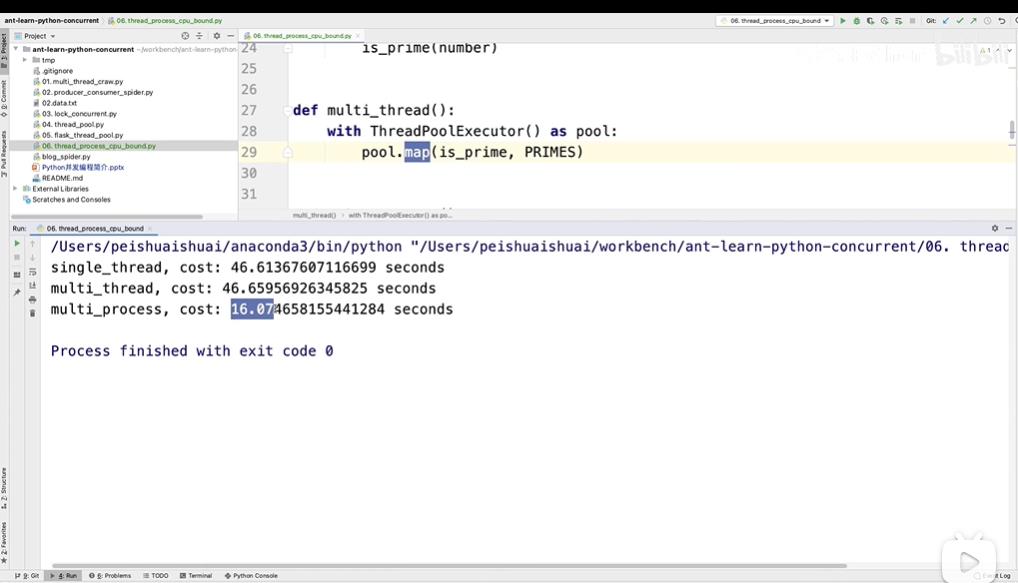
可以看出,在CPU密集型情况下,多线程反而会拖慢速度,可以使用多进程的方式加快速度
五、进程池在flask 中怎么应用
多进程环境之间相互是完全隔离的。多线程是共享当前进程的所有环境。大部分情况下,用多线程就可以。
import flask
from concurrent.futures import ProcessPoolExecutor
import math
import json
app = flask.Flask(__name__)
def is_prime(n):
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
@app.route("/is_prime/<numbers>")
def api_is_prime(numbers):
number_list = [int(x) for x in numbers.split(",")]
results = process_pool.map(is_prime, number_list)
return json.dumps(dict(zip(number_list, results)))
if __name__ == "__main__":
process_pool = ProcessPoolExecutor()
app.run()
六、协程:在单线程内实现并发
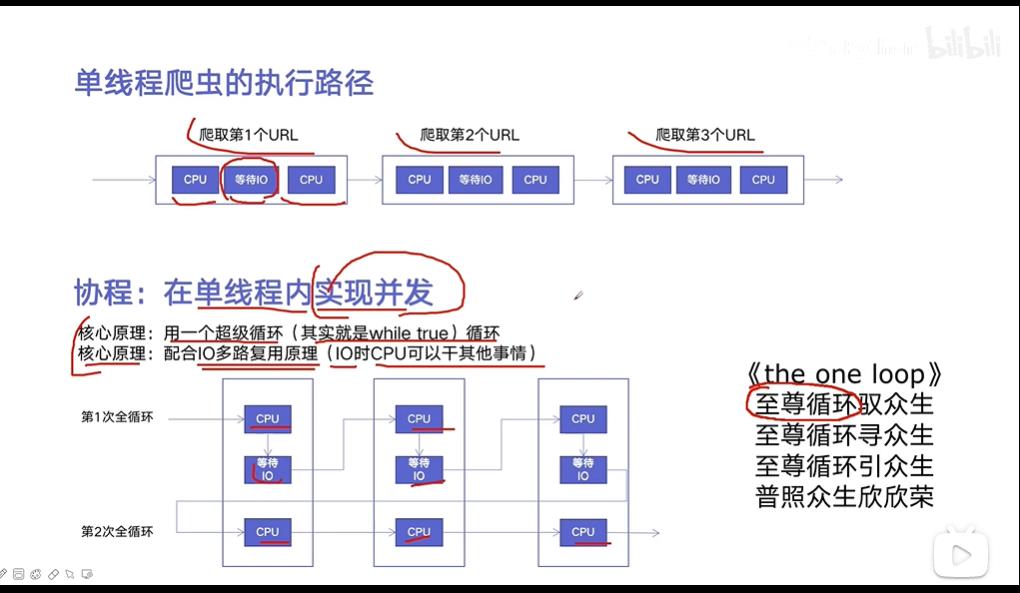

协程异步IO实现并发爬虫实例:
import asyncio
import aiohttp
import blog_spider
async def async_craw(url):
print("craw url: ", url)
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
result = await resp.text()
print(f"craw url: {url}, {len(result)}")
loop = asyncio.get_event_loop()
tasks = [
loop.create_task(async_craw(url))
for url in blog_spider.urls]
import time
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print("use time seconds: ", end - start)
在异步IO中使用信号量控制并发度

采用信号量控制协程异步IO 实现并发
import asyncio
import aiohttp
import blog_spider
semaphore = asyncio.Semaphore(10)
### 每5s 访问10 条url
async def async_craw(url):
async with semaphore:
print("craw url: ", url)
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
result = await resp.text()
await asyncio.sleep(5)
print(f"craw url: {url}, {len(result)}")
loop = asyncio.get_event_loop()
tasks = [
loop.create_task(async_craw(url))
for url in blog_spider.urls]
import time
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print("use time seconds: ", end - start)
七、 subprocess 模块


import subprocess
"""
proc = subprocess.Popen(
["start", "./datas/余生一个浪.mp3"],
shell=True
)
proc.communicate()
"""
proc = subprocess.Popen(
[r"C:\\Program Files\\7-Zip\\7z.exe",
"x",
"./datas/7z_test.7z",
"-o./datas/extract_7z",
"-aoa"],
shell=True
)
proc.communicate()
以上是关于python 复习—并发编程实战——线程多进程多协程加速程序运行实例(多线程和多进程的对比)的主要内容,如果未能解决你的问题,请参考以下文章
python 复习—并发编程实战——多线程和多进程的生产者消费者模型线程进程再总结