物流项目问题 ing
Posted ChinaManor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了物流项目问题 ing相关的知识,希望对你有一定的参考价值。
物流项目问题
1、物流项目的背景介绍(行业、特点、案例、痛点)
1)、行业背景介绍: 自从国内电商购物节开始以后,每年用户电商APP购买物品增加,快递数量指数级别增长。
2)、物流行业特点:物流行业属于复合型产业,实时产生大量的业务数据,需要关联性分析处理。
3)、项目背景介绍:基于上述诉求,需要将快递物流产生相关业务数据,存储到大数据平台引擎中,进行分析(离线报表和实时查询检索)。
4)、物流大数据作用
物流大数据应用对于物流企业来讲具有以下3个方面的重要作用
提高物流的智能化水平
降低物流成本
提高用户服务水平
5)、物流大数据应用案例
针对物流行业的特性,大数据应用主要体现在车货匹配、运输路线优化、库存预测、设备修理预检测、供应链协同管理等方面。
2、项目的解决方案是什么?
(数据源、采集、存储、计算、技术亮点)
数据源
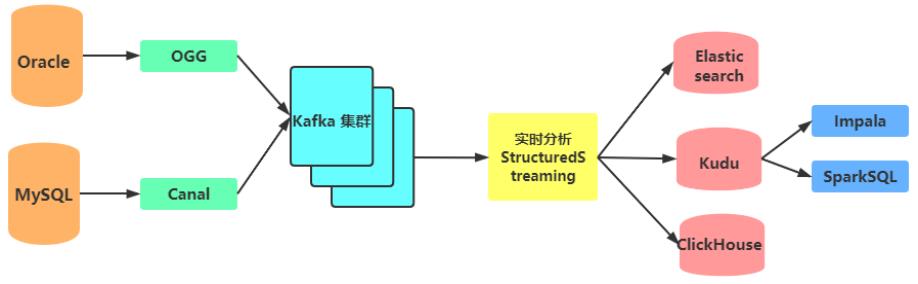
数据源主要有两种方式:Oracle数据库、mysql数据库
实时采集
Oracle数据库采用ogg进行实时采集,MySQL数据库采用Canal进行实时采集。采集到的数据会存放到Kafka消息队列临时存储中。
存储
Kafka 做临时存储、
Kudu 支持更新,也支持大规模数据存储、
HDFS 存储冷热数据并基于hdfs数据分析、
ElasticSearch 业务数据实现、
ClickHouse 实时OLAP分析

计算
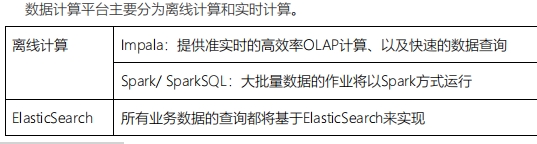
离线计算:
Impala 提供准实时的高效率OLAP计算和快速的数据查询;
Spark/SparkSQL 大批量数据的;
ES:所有业务数据的查询都将基于ES实现;
技术亮点
完整Lambda 架构系统,有离线业务 也有实时业务
ClickHouse实时存储 计算引擎
Kudu +Impala准实时分析系统
基于Docker 搭建异构数据源 还原企业真实应用场景
以企业主流的Spark生态圈为核心技术
ES全文检索
SpringCloud 搭建数据服务
性能调优

3、请描述出物流项目的数据流转?
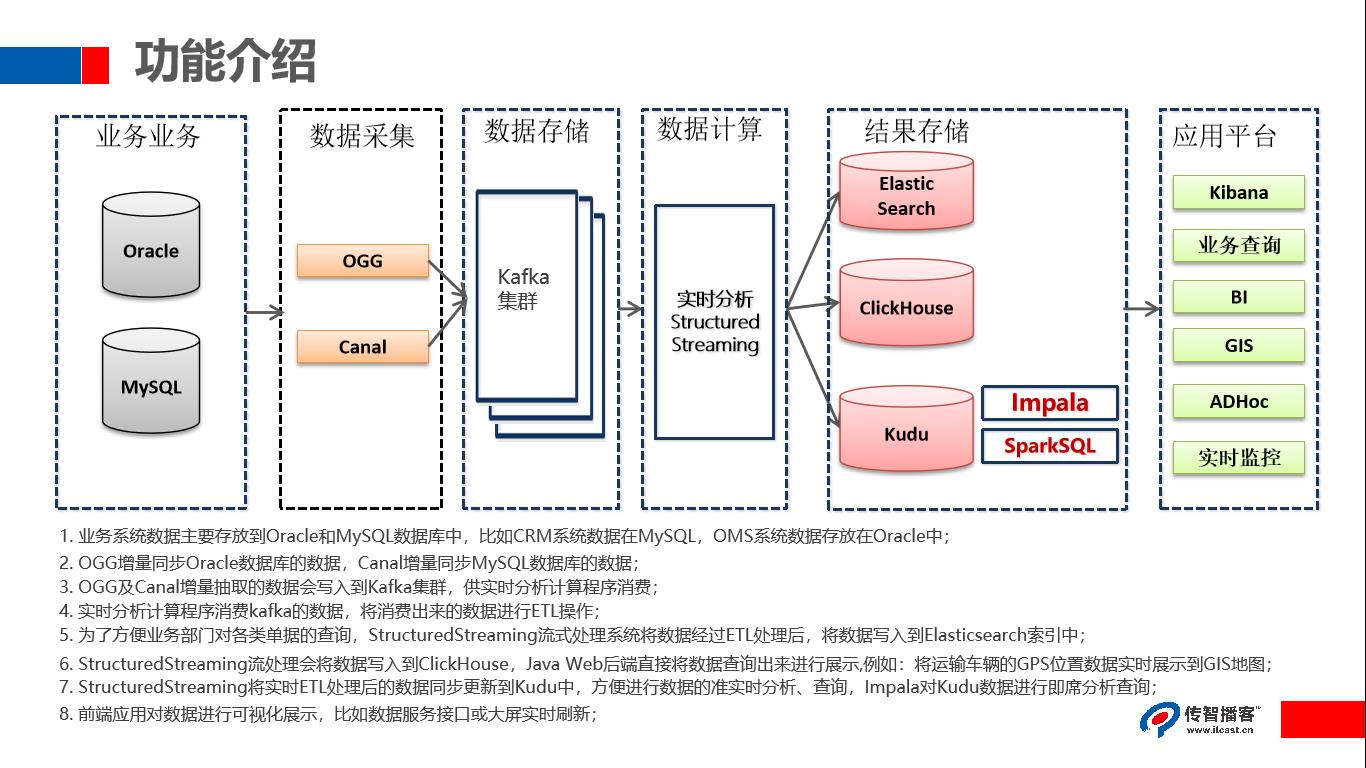
1.业务系统数据主要存放到Oracle和 MySQL数据库中,比如CRM系统数据在 MySQL,OMS系统数据存放在 Oracle中
2.OGG增量同步 Oracle数据库的数据, Canal增量同步 MySQL数据库的数据
3.OGG及Canal增量抽取的数据会写入到 Kafka集群,供实时分析计算程序消费
4.实时分析计算程序消费 kafka的数据,将消费出来的数据进行ETL操作
5.为了方便业务部门对各类单据的查询, StructuredStreaming流式处理系统将数据经过ETL处理后,将数据写入到 Elasticsearch索引中
- StructuredStreaming流处理会将数据写入到 ClickHouse, Java Web后端直接将数据查询出来进行展示例如:将运输车辆的GPS位置数据实时展示到GIS地图
7.StructuredStreaming将实时ETL处理后的数据同步更新到Kudu中,方便进行数据的准实时分析、查询, Impala对Kudu数据进行即席分析查询
8.前端应用对数据进行可视化展示,比如数据服务接口或大屏实时刷新
4、请描述出物流项目包括哪些模块?
任何一个大数据项目,首先数据流转图:项目数据从哪里来的,存储到哪里去,进行什么应用分析。
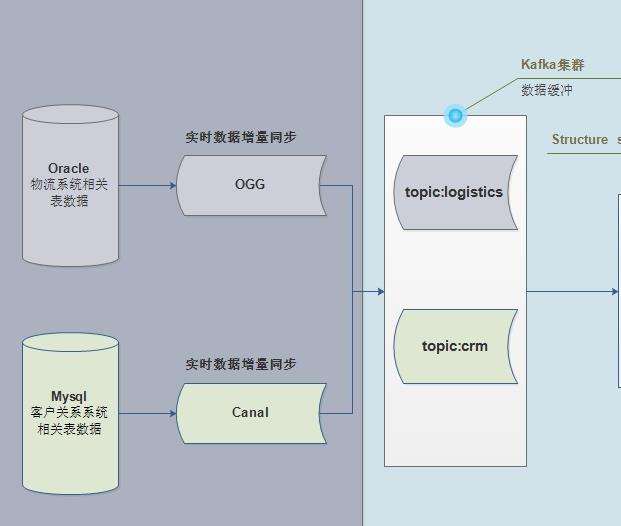
- 1)、业务服务器(存储业务数据)
- 物流项目来说,需要将多个业务系统数据,实时采集到大数据框架Kafka中
- 物流系统Logistics业务数据,存储Oracle数据库
- CRM客户关系管理系统业务数据,存储MySQL数据库
2)、大数据服务器(存储业务数据、分析数据和调度执行)
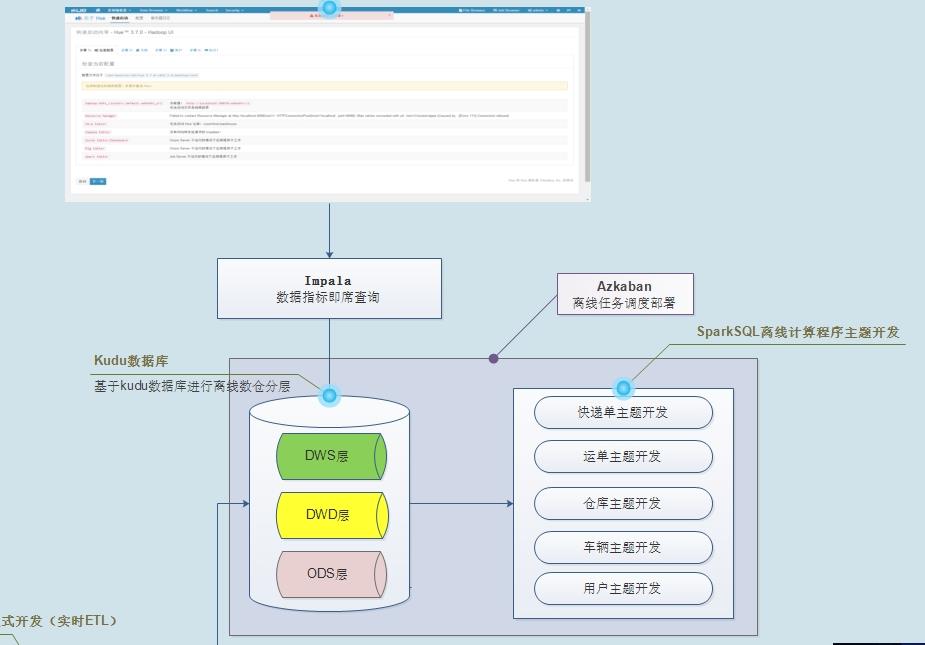
- 第一部分功能、离线报表和即席查询
- 将业务数据实时增量存储数据库:Kudu(类比HBase数据库)
- SparkSQL分析Kudu表数据,进行离线报表统计
Impala查询Kudu表数据,进行即席查询,一对CP组合
- 第二部分功能:实时大屏展示
- 将业务数据存储到ClickHouse表中,需要实时查询 ,快速的查询(分组,聚合和排序)
- 通过服务接口对外提供数据查询功能及数据导出。
- 第三部分功能:物流信息检索
- 将核心业务数据(快递单数据和运单数据)存储至Elasticsearch索引中,可以快速检索物流
3)、如何将业务数据实时ETL存储到Es、CK或Kudu中呢??
- 编写
结构化流应用程序,实时从Kafka消费数据,进行ETL转换后,存储到各种存储引擎。val spark: SparkSession spark.readStream.format("kafka").option().load streamDF.writeStream.format("es/clickhouse/kudu").option().start
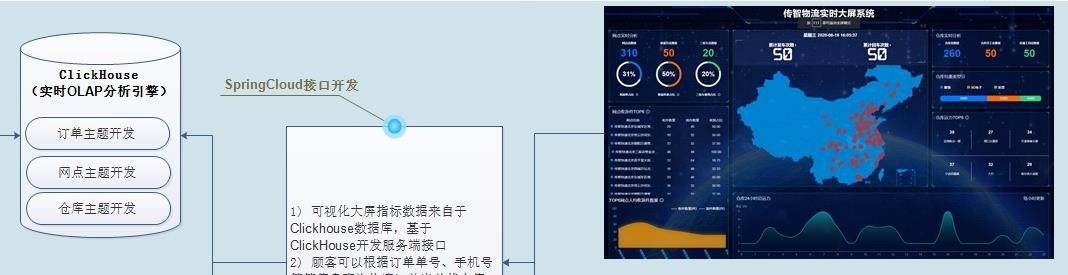
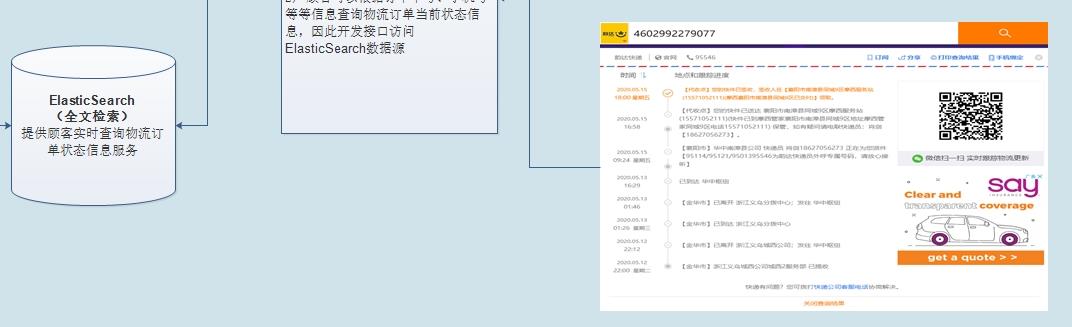
5、分别阐述一下每个模块主要解决什么问题?-1
6、分别描述一下每个模块的技术架构?
接下来,看一下整个物流项目:逻辑技术架构图,项目中每个步骤使用什么技术,[技术选项(为什么选这个技术框架)。]()
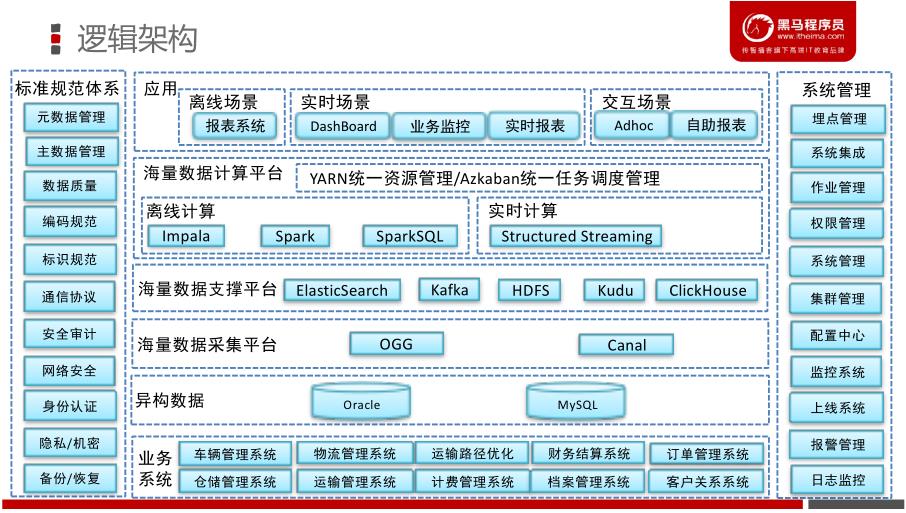
即席查询,在大数据领域中,比较普遍需求,随时依据用户的需求,查询分析海量数据。
在神策数据产品中,用户自定义查询,就是所说的即席查询,底层使用Impala分析引擎。
思考 :为什么选择这些技术框架,原因是什么???
- 业务系统包括车辆管理系统,物流管理系统,运输路径优化,仓储管理系统,运输管理系统等等
- 1)、异构数据源:表示业务数据存储到不同系统中,此处仅仅演示2个数据库

- 2)、数据采集平台:物流项目数据采集属于实时增量采集,类似Flume日志数据。

- 3)、数据存储平台

- 4)、数据计算平台:实时查询(Impala和StructuredStreaming、ES)和离线分析(SparkSQL)

- 5)、大数据平台应用
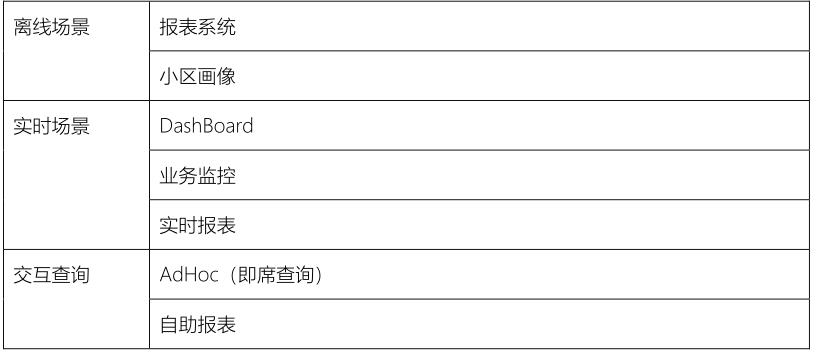
7、请详细描述一下物流项目中离线数仓?-1
(技术、主题、分层建模、指标维度、事实表维度表)
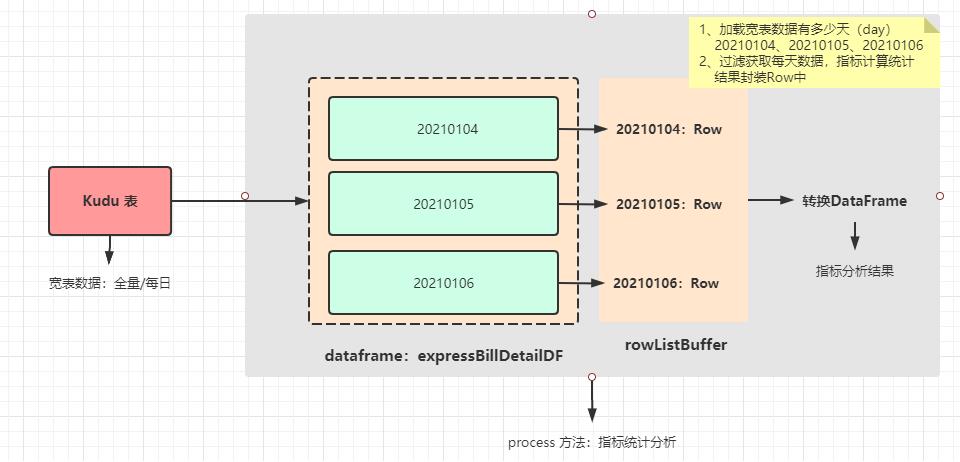
2)、离线报表分析,编写SparkSQL程序,针对每个主题报表开发
数仓架构分层管理数据,每个主题报表开发2个程序:DWD层数据拉宽和DWS层指标计算
DWS层指标计算,全量加载数据还是增量加载数据,都是按照每天统计,最终转换为DataFrame
客户主题报表分析,指标统计,最好深入理解,背下来
8、请详细描述一下实时大屏展示整体架构和业务指标?
(技术、指标)
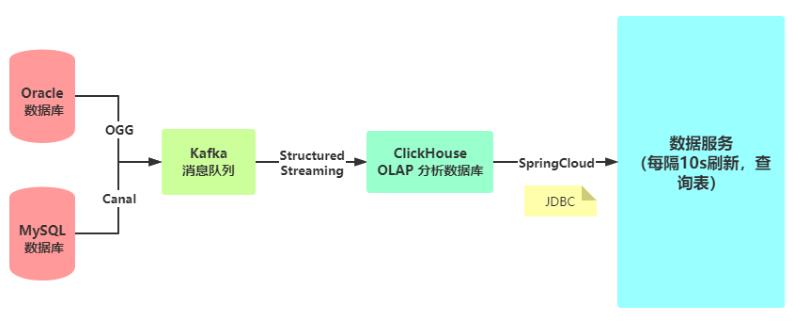
将物流系统和CRM系统业务数据实时同步到
ClickHouse数据库表中以后,需要开发三个应用:
- 1)、 实时大屏展示 ,每隔一定时间从ClickHouse表中查数据,在前端展示
- 固定指标实时查询分析
- 2)、 数据服务接口 ,提供给其他用户导出相关业务数据,进行使用
- 接口就是:Url连接地址,需要传递参数,进行访问请求,返回JSON格式数据
- 3)、 OLAP实时分析
- 依据不确定需求,实时查询分析,得到结果,比如临时会议所需要报表数据、临时统计分析。
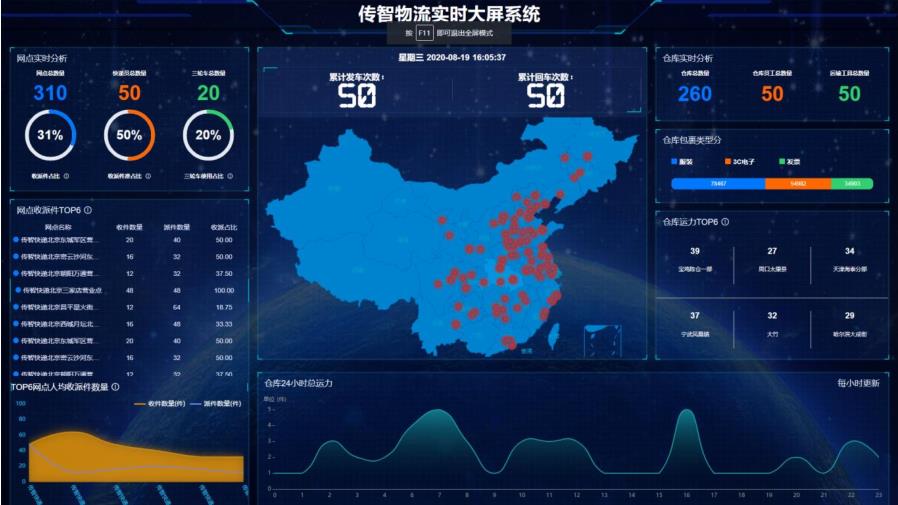
物流实时大屏展示的数据, 从ClickHouse·表中读取,底层调用的是
JDBC Client API,通过服务接口提供给前端页面展示,每隔10秒刷新页面从ClickHouse表中查询数据 。
实时大屏截图,各个指标对应的SQL语句如下所示:
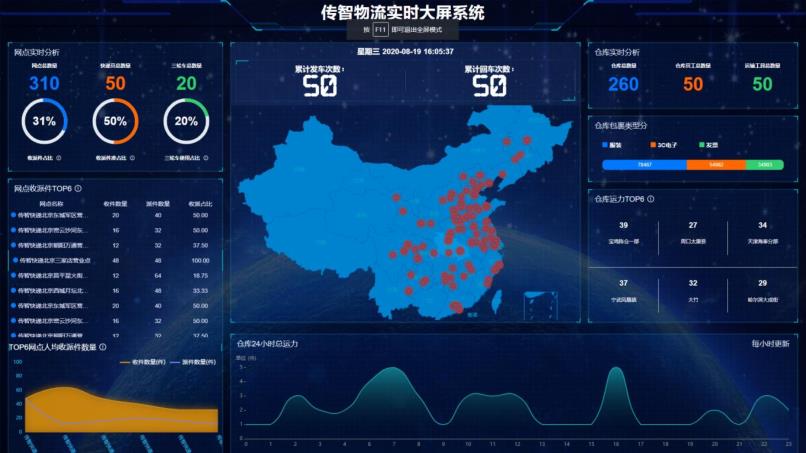
实时大屏上指标如下所示:

9、请详细描述一下实时搜索业务整体架构?
(技术、指标)
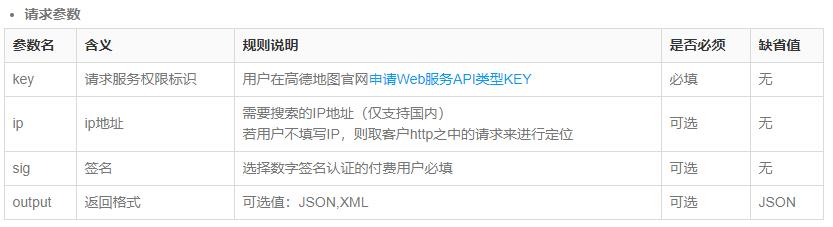
服务接口: 给用户提供URL地址信息,通过传递参数,请求服务端,获取数据,通常以JSON格式返回 。
高德地图给开发者用户提供数据服务接口,比如 依据IP地址,查询归属地(省份、城市等信息)
- 高德网站:https://developer.amap.com/api/webservice/guide/api/ipconfig (注册)
- IP定位,提供URL地址

url: https://restapi.amap.com/v3/ip?key=e34eb745a49cd9907f15d96418c4f9c0&ip=116.30.197.230 parameters: key: e34eb745a49cd9907f15d96418c4f9c0 ip: 116.30.197.230在浏览器上输入URL地址,回车请求,获取信息数据
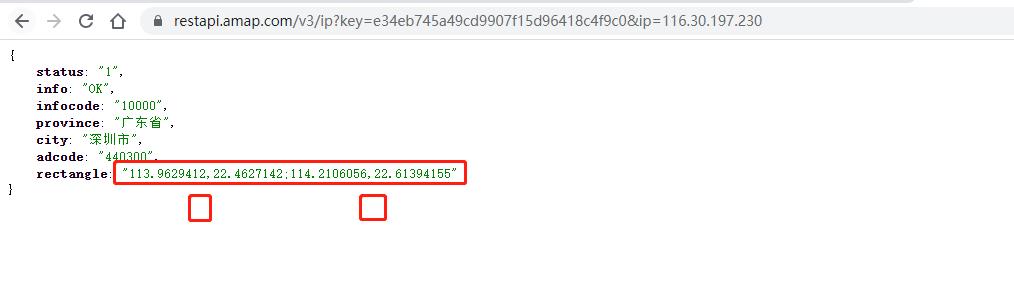
GET 请求参数信息:
开发api接口访问后端存储介质,可视化页面通过http访问开发的后端api接口,从而将数据通过图表展示出来或者以JSON格式返回数据。
在物流项目中,开发数据服务接口,分别
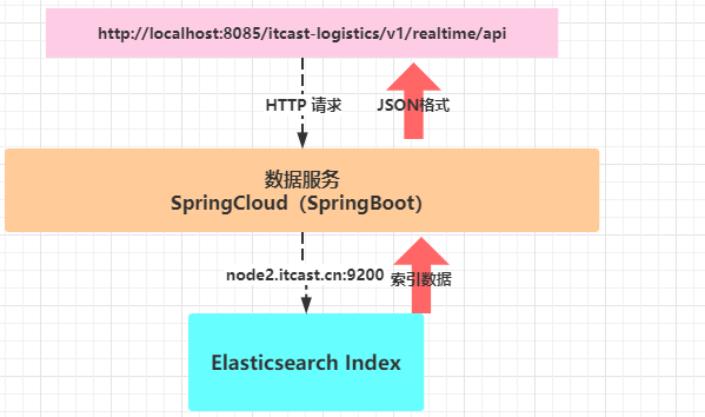
查询Es索引Index数据和ClickHouse表数据,对外提供服务
- 1)、物流业务数据存储Elasticsearh索引Index中时,开发数据服务接口,流程示意图:
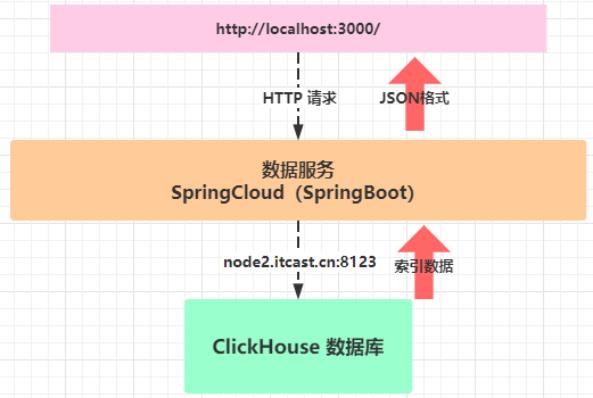
- 2)、物流业务数据存储ClickHouse表中时,开发数据服务接口,流程示意图:
10、请详细描述一下数据如何展示的?
(技术)
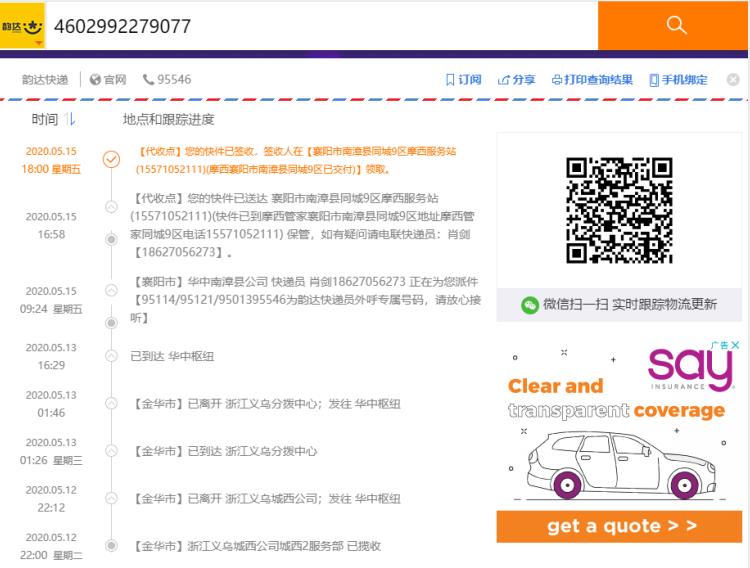
快递物流查询:
针对物流快递来说,需要给用户提供接口,实时依据
快递单号或者运单号,查询快递物流信息,选择使用框架:Elasticsearch 索引Index。
实时将业务数据同步到Es索引时,仅仅需要物流系统中:
运单数据和快递单数据即可。
- 1)、结构化流与Es集成,官方提供库,直接使用即可
- 2)、业务数据存储Es索引以后,还可以进行一些简易查询,此次使用Kibana简易报表和图表展示
- 3)、Es索引中,存储的都是最近业务数据,不存储历史业务数据
- 比如,快递单表和运单表存储最近3个月数据,或者1个月数据。
实时OLAP 分析:
将物流业务数据存储至
ClickHouse分析数据库中,一次写入(批量写入)多次查询。
- 1)、需要从海量数据进行实时OLAP分析,实时查询
- 2)、物流系统,往往与第三方合作,需要提供服务接口给第三方,导出向数据
- 3)、实时大屏展示
[复习]-物流项目回顾之技术面试题
由于物流项目基于Spark框架实时采集数据、离线报表分析及Impala即席查询和ClickHouse OALP分析。
-
1、数据采集如何完成
- OGG 不要涉及,Oracle DBA完成
- Canal数据采集,一定知道高可用HA集群模式
-
2、数据量大小
-
Kafka topic 数据存储生命周期(多久)
7天
-
Kafka Topic 个数及分区数和副本
Topic 个数通常情况:多少个日志类型就多少个 Topic。也有对日志类型进行合并的。
分区数:分区数并不是越多越好,一般分区数不要超过集群机器数量。分区数越多占用内存越大(ISR
等),一个节点集中的分区也就越多,当它宕机的时候,对系统的影响也就越大。
分区数一般设置为:3-10 个
副本:一般我们设置成 2 个或 3 个,很多企业设置为 2 个。
- Kafka 集群规模及机器配置
-
Kafka 机器数量=2*(峰值生产速度*副本数/100)+1
Kafka 的硬盘大小 每天的数据量*7 天
-
3、实时增量ETL程序开发,为什么选择使用StructuredStreaming??
-
4、消费Kafka数据几种方式及区别,如何保存偏移量?
- SparkStreaming Checkpoint或自己管理
- StructuredStreaming 使用Checkpoint管理
-
5、为什么使用Kudu存储,不使用HBase??
- 两者区别??
- Kudu中数据读写流程
- Kudu如何存储数据,每个表分区策略???
- Kudu使用注意事项,Kudu集群对时间同步极其严格
-
6、DataFrame与Dataset、RDD区别
- RDD 特性有哪些??你是如何理解RDD的???
- 为什么Spark计算比较快,与MapReduce相比较优势是什么??
- SparkSQL中优化有哪些???使用常见函数有哪些???
-
7、Impala 分析引擎
- Impala架构,实现目的,目前架构如何
- Hue与Impala集成
-
8、离线数仓
- 数仓分层如何划分呢???为什么要划分??为什么要如此设计???
- 雪花模型和星型模型区别是什么????
-
9、ClickHouse 为什么选择,有哪些优势??
-
10、SparkSQL外部数据源实现(难点)
-
11、大数据平台集群规模、服务配置、项目人员安排、项目开发周期等等
-
12、业务线:你完成什么,你做了什么,你遇到什么问题,你是如何解决的????
-
Kudu如何存储数据,每个表分区策略???
-
Kudu使用注意事项,Kudu集群对时间同步极其严格
-
6、DataFrame与Dataset、RDD区别
- RDD 特性有哪些??你是如何理解RDD的???
- 为什么Spark计算比较快,与MapReduce相比较优势是什么??
- SparkSQL中优化有哪些???使用常见函数有哪些???
-
7、Impala 分析引擎
- Impala架构,实现目的,目前架构如何
- Hue与Impala集成
-
8、离线数仓
- 数仓分层如何划分呢???为什么要划分??为什么要如此设计???
- 雪花模型和星型模型区别是什么????
-
9、ClickHouse 为什么选择,有哪些优势??
-
10、SparkSQL外部数据源实现(难点)
-
11、大数据平台集群规模、服务配置、项目人员安排、项目开发周期等等
-
12、业务线:你完成什么,你做了什么,你遇到什么问题,你是如何解决的????
以上是关于物流项目问题 ing的主要内容,如果未能解决你的问题,请参考以下文章