每天学一点系列~这些内存函数你知道么?还记得么[doge]
Posted 白龙码~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了每天学一点系列~这些内存函数你知道么?还记得么[doge]相关的知识,希望对你有一定的参考价值。

Part I 、《简单说两句》
相信大多数学过C的同学对于<string.h>这个头文件里的许多函数并不陌生,像是strcat、strcpy等等。对于操作字符串而言,这些函数用着简直不要太爽,可如果我想操作其他类型的数组,比如,int?double?那我又该用什么函数呢?我又没有必要写个函数,叫intcpy?doublecpy?可以,但没这个必要。
我们知道,数组最大的特点之一就是,它在内存中的存储是连续的,这意味着,如果我们想直接通过内存操作数组中的数据,简直不要太easy!听到这里是不是很激动?让我们一起开始今天的学习——内存函数冲冲冲。
Part II、内存函数介绍
1、memcpy
库函数里的memcpy是这样定义的——
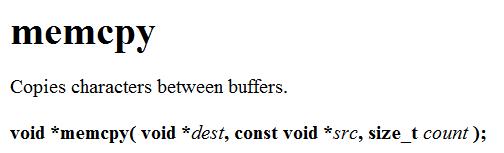
src是我们的数据的来源地(source),我们要从它那里拷贝count个字节的内容到dest中,也就是我们的目的地(destination),然后将dest作为返回值返回。
代码实现一波,感受这个函数的内在机制:
void* my_memcpy(void* dest, const void* src, size_t count)
{
assert(dest && src);
void* ret = dest;
while (count--)
{
*(char*)dest = *(char*)src;
(char*)dest = (char*)dest + 1;
(char*)src = (char*)src + 1;
}
return ret;
}
函数的使用:
int main()
{
int src[] = { 1,2,3,4,5,6,7,8,9,10 };
int dest[10] = { 0 };
memcpy(dest, src, 20);
int i;
for (i = 0; i < 10; i++)
{
printf("%d ", dest[i]);
}
return 0;
}
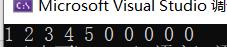
【注:我们的函数调用:memcpy(dest, src, 20);这意味着我们仅仅将src的前20个字节(也就是5个int类型的数组成员)拷贝到dest中,而我们的dest有40个字节(也就是10个int型数组成员,且全被初始化为0),所以调用函数memcpy并打印dest后我们发现前五个被改为src的前五个,而剩下的没改变,依然为0】
我们再看一个情况:
int main()
{
int src[] = { 1,2,3,4,5,6,7,8,9,10 };
my_memcpy(src+3, src,20);
int i;
for (i = 0; i < 10; i++)
{
printf("%d ", src[i]);
}
return 0;
}
也就是说:源src与目的地dest有一部分是重合的,那么按照我们原先代码的逻辑,还能实现拷贝功能吗?
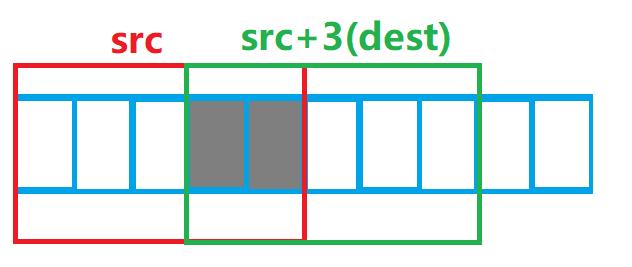
让我们来看一下输出结果:

这乱七八糟的是什么?
仔细分析后我们不难发现,当一开始,我们把src的前四个字节拷贝到src+3时(也就是第一个灰色方格),由于src与dest在这一灰色部分是重合的,所以src+3被改变的同时,原先那个位置上的要拷贝的数据也被覆盖了!
查阅资料后我们可以看到这句话:
If the source and destination overlap, this function does not ensure that the original source bytes in the overlapping region are copied before being overwritten. Use memmove to handle overlapping regions.
也就是说,倘若dest和src有一部分重合,那么这个memcpy函数不会确保重合部分在被拷贝之前不会被其他数据覆盖!此时考虑使用memmove函数。
什么是memmove?如果你想知道什么是memmove的话,现在就带你研究~
2、 memmove
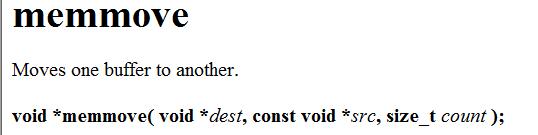
与memcpy对比后我们发现:这两个函数的参数部分是一样的,而memmove比memcpy牛的地方在于上面我们所看到的:可以避免src与dest有重合部分带来的问题。
如果刚刚memcpy的最后一部分没看懂,那么接下来我将更加细致的分析src与dest有重合部分的情况!

假设我们要将src的前20个字节(红色部分)拷贝到dest的前20个字节中,要怎么做呢?
假设我们从前往后拷贝,即数据1是我们最先要拷贝过去的:
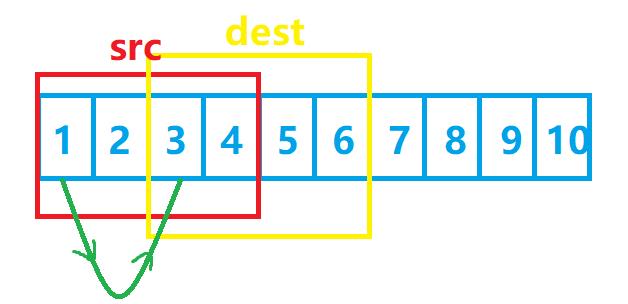
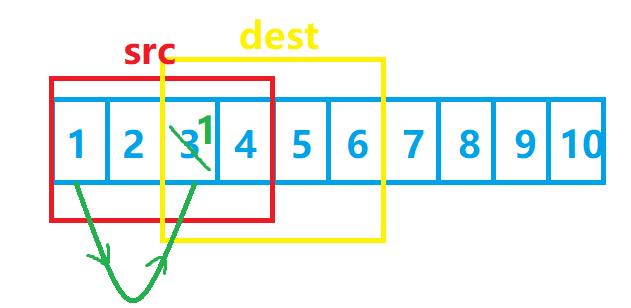
接下来是数据2被拷贝过去:
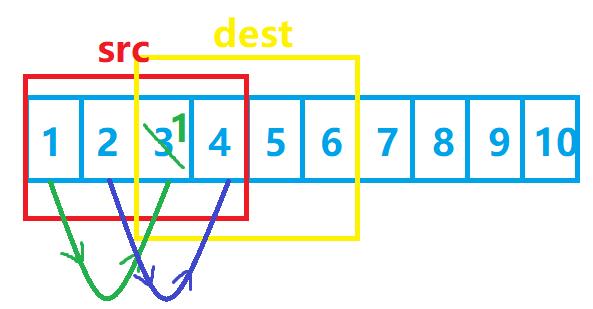
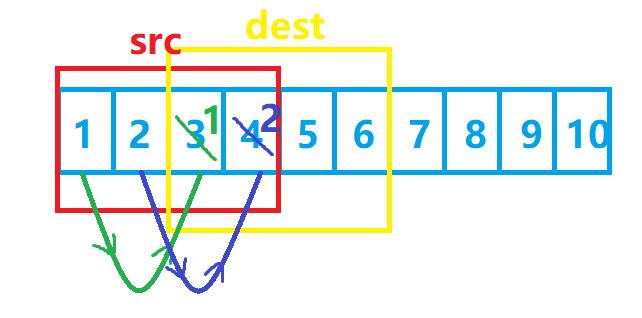
那么第9-12个字节(也就是src数组的第三个数据)的拷贝就出现了问题:我们原先是要把3给拷贝过去的,但是3在一开始拷贝的时候就已经被覆盖掉了,这时候再拷贝,就已经与我们原先的想法背道而驰了!
但是,如果我们换个方式:我们不再从前往后地把src拷贝到dest中,而是从后往前地把src拷贝到dest,是不是就避免了上述问题呢?
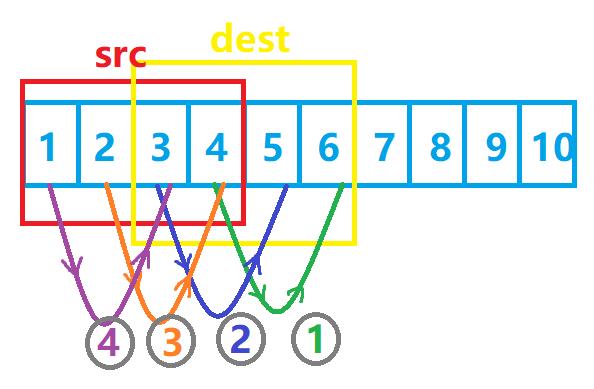
好的,我们发现,当src比dest小时,我们是从后往前地拷贝数据,那么当src大于dest时呢?
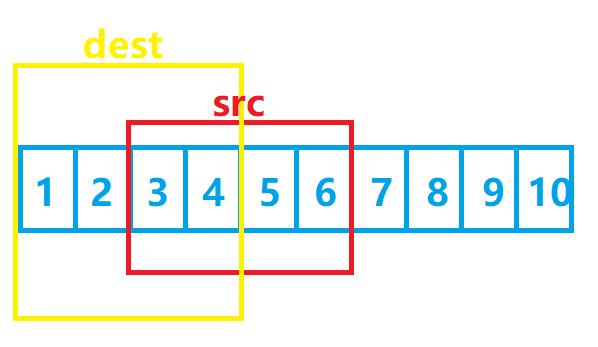
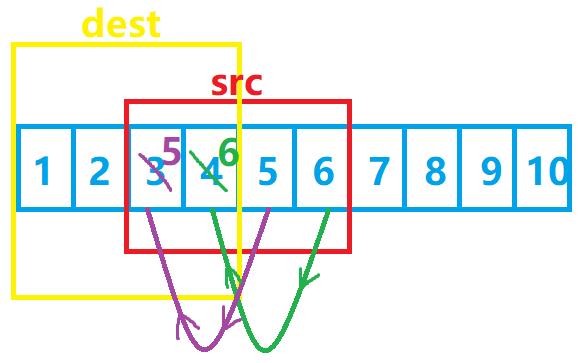
很明显,答案是no!
在这种情况下,从后往前会导致数据的覆盖!
这个时候我们就要考虑从前往后进行拷贝——
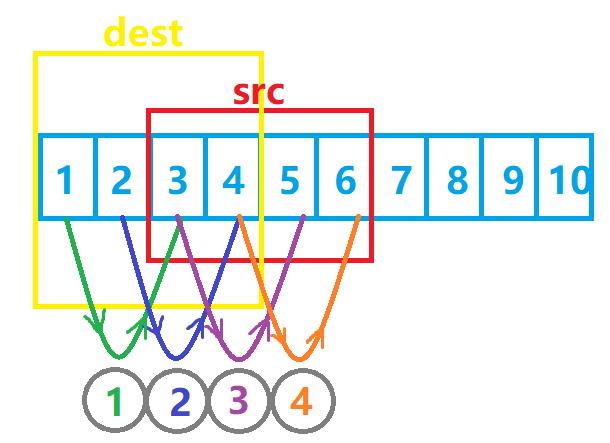
这就完美避开了数据覆盖的问题!
理论分析结束,代码实现!
void* my_memmove(void* dest, const void* src, size_t num)
{
assert(dest && src);
void* ret = dest;
//当dest<src时,src从前往后挪到dest
if (dest < src)
{
while (num--)
{
*(char*)dest = *(char*)src;
(char*)dest = (char*)dest + 1;
(char*)src = (char*)src + 1;
}
}
//当dest>src时,src从后往前挪到dest
else
{
while (num--)
{
*((char*)dest + num) = *((char*)src + num);
}
}
return ret;
}
我们再次运行之前strcpy无法完成的那个程序:
int main()
{
int src[] = { 1,2,3,4,5,6,7,8,9,10 };
my_memmove(src + 3, src, 20);
int i;
for (i = 0; i < 10; i++)
{
printf("%d ", src[i]);
}
return 0;
}
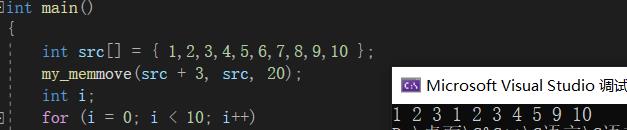
没问题!
3、memcmp
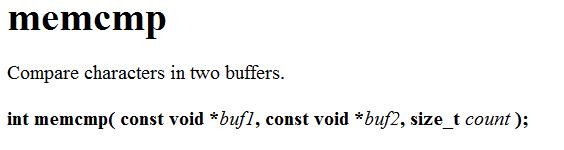
不知道大家还记不记得strcmp函数。对于给定的两个字符串,strcmp在两者的对应位置遇到第一个不一样的数时就会进行比较并返回正数(对应位置前者的ASCII码比后者大)、负数(对应位置前者的ASCII码比后者小)或0(两者完全相等)。
对于memcmp函数也一样,与strcmp不同的是,memcmp可以比较任意类型的数据并返回它们的大小关系!
使用示例:
int main()
{
double buf1[] = { 1.0,2.0,3.0 };
double buf2[] = { 1.0,3.0,4.0 };
int ret = memcmp(buf1, buf2, 16);//比较前16个字节
printf("%d", ret);
return 0;
}
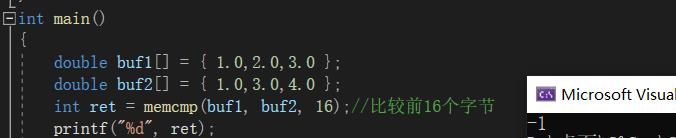
由于buf1[1]<buf2[1],所以ret的结果为-1理所当然~
我们简单实现一下这个函数:
int my_memcmp(const char* buf1, const char* buf2, size_t count)
{
assert(buf1 && buf2);
while (count)
{
if (*(char*)buf1 != *(char*)buf2)
{
break;
}
(char*)buf1 = (char*)buf1 + 1;
(char*)buf2 = (char*)buf2 + 1;
count--;
}
if (count == 0)//count==0,说明相等
{
return 0;
}
else
{
return *(char*)buf1 > *(char*)buf2 ? 1 : -1;
}
}
思想很简单,就是一个字节一个字节地比较,遇到不同的就返回这两个不同字节内容的比较结果~
但是,值得注意的是:由于是按照字节数count比较的,所以如果我们用memcmp函数比较两个字符串,一定要确保count不超过字符串的长度,因为memcmp不会因为遇到’\\0’就停止比较,而是会继续往后比较,直到遇到两个不同的数据单元或者比较的字节数达到了count个——这很有可能会导致出错!
4、memset

函数的作用:将dest的前count个字节全部设置成整型c。
下面我们来做一个判断题——观察一下代码:
int main()
{
int arr[10] = { 0 };
memset(arr, 1, 40);
int i;
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
请问这里输出的结果是什么?十个1?
实则不然,这是大多数人由于下意识的反应而出错!
memset是内存函数,操作的是内存!
而这里我们是将数组arr的40个字节全部设置为1,而不是将数组内容变成1;
调试一下:
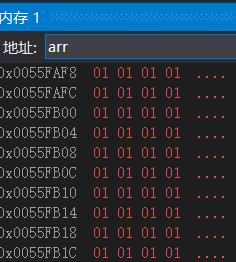
我们看到,数组的每一个字节都被设置为1!(由于内存是十六进制表示,并且由于小端存储的缘故,所以这里我们看到的都是010101…不懂得可以看看这里:数据存储详解!
对于int、float等类型的数组而言,memset有其局限性,但是对于char类型数组而言,memset可以说是神器,因为char类型刚好占1个字节!
Part III、小结一下
内存函数,对于我们操纵内存可以说是相当方便了,如果掌握了,想必可以在程序开发方面获得不少开发效率上的提升!
//都看到这里了,不点个赞嘛ლ(′◉❥◉`ლ)
//跪求各位看客老爷们三连!
//同时欢迎评论区指教哈~

以上是关于每天学一点系列~这些内存函数你知道么?还记得么[doge]的主要内容,如果未能解决你的问题,请参考以下文章