同事半个月都没搞懂selenium,我半个小时就给他整明白!顺手秀了一波爬淘宝的操作
Posted 不想秃头的里里
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了同事半个月都没搞懂selenium,我半个小时就给他整明白!顺手秀了一波爬淘宝的操作相关的知识,希望对你有一定的参考价值。
因为工作需要,同事刚开始学python,学到selenium这个工具半个月都没整明白,因为这个令他头秃了半个月,最后找到我给他解答。
所以我用一个淘宝爬虫实例给他解释了一遍,不用一个小时他就搞懂了。初学者也看得懂的爬虫项目。

在爬虫开始之前我们需要了解一些概念,本次爬虫会用到 selenium。
什么是selenium?
selenium是网页自动化测试工具,可以自动化的操作浏览器。如果需要操作哪个浏览器需要安装对应的driver,比如你需要通过selenium操作chrome,那必须安装chromedriver,而且版本与chrome保持一致。
了解完之后,安装selenium:
pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple
一、导入模块
首先我们先导入模块
from selenium import webdriver
后续我们还会用到其他的模块,我先把它全部放出来:
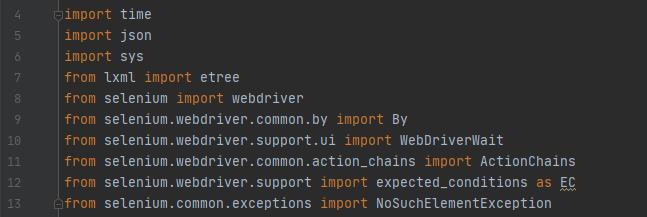
二、浏览器初始化
然后就是浏览器的初始化
browser = webdriver.Chrome()
可以用很多浏览器,android、blackberry、ie等等。想用其他的浏览器,下载对应的浏览器驱动就可以了。
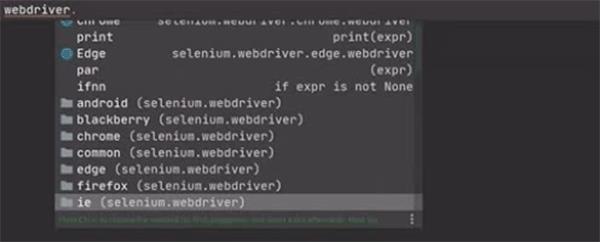
因为我这边只安装了谷歌浏览器的驱动,所以用的是chrome谷歌,驱动可以自己去下载。
chrome谷歌浏览器对应的driver:
http://npm.taobao.org/mirrors/chromedriver/
三、登录获取页面
首先要解决的是登录问题,登录时不要直接输入账号登录,因为淘宝的反爬特别严重,如果它检测到你是一个爬虫,就不允许登录,淘宝在登录这一块的措施是很严格的。
所以我用了另一种登录方法,支付宝扫码登录,请求到支付宝扫码登录页面的网址。
def loginTB():
browser.get(
'https://auth.alipay.com/login/index.htm?loginScene=7&goto=https%3A%2F%2Fauth.alipay.com%2Flogin%2Ftaobao_trust_login.htm%3Ftarget%3Dhttps%253A%252F%252Flogin.taobao.com%252Fmember%252Falipay_sign_dispatcher.jhtml%253Ftg%253Dhttps%25253A%25252F%25252Fwww.taobao.com%25252F¶ms=VFBMX3JlZGlyZWN0X3VybD1odHRwcyUzQSUyRiUyRnd3dy50YW9iYW8uY29tJTJG')
跳转到支付宝扫码登录界面。
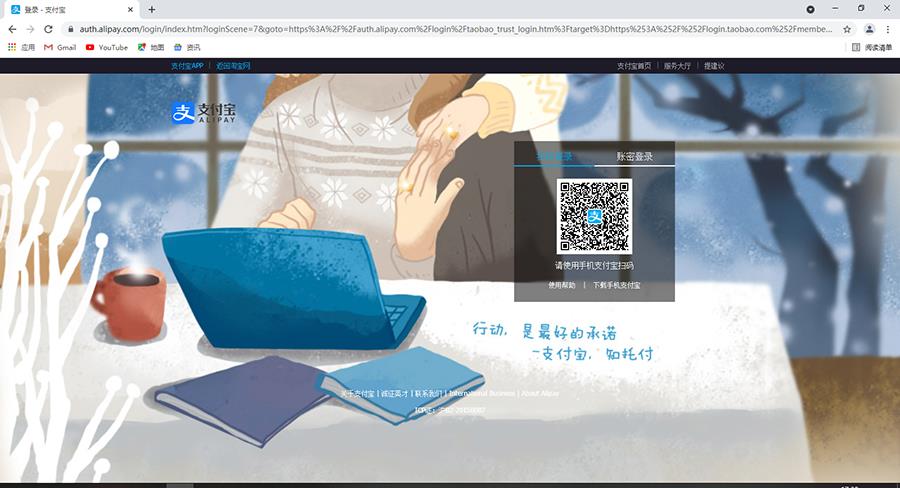
我这边设置了一个等待时间,180秒后搜索框出现,其实不会等待180秒,是一个显示等待,只要元素出现,就不会在等待了。
再查找搜索框并输入关键字搜索。
# 设置显示等待 等待搜索框出现
wait = WebDriverWait(browser, 180)
wait.until(EC.presence_of_element_located((By.ID, 'q')))
# 查找搜索框,输入搜索关键字并点击搜索
text_input = browser.find_element_by_id('q')
text_input.send_keys('美食')
btn = browser.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button')
btn.click()
四、解析数据
获取网页之后,再来解析数据,将所需要的商品数据爬到,这里用的是lxml解析库,XPath选取子节点直接解析。
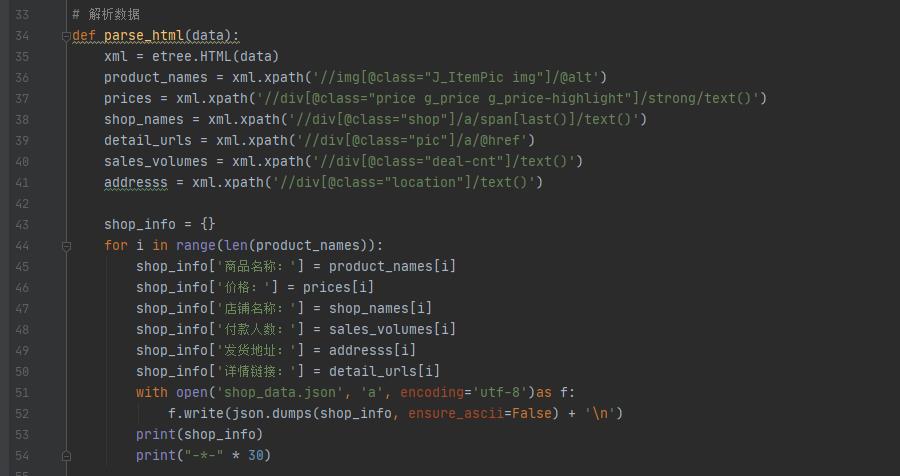
五、爬取页面
在搜索框搜索之后会出现所需要的商品页面详情,但是不只是爬取一页,是要不断的下一页爬取多页的商品信息。这里写了一个死循环,一直爬到商品页没有了
def loop_get_data():
page_index = 1
while True:
print("===================正在抓取第{}页===================".format(page_index))
print("当前页面URL:" + browser.current_url)
# 解析数据
parse_html(browser.page_source)
# 设置显示等待 等待下一页按钮
wait = WebDriverWait(browser, 60)
wait.until(EC.presence_of_element_located((By.XPATH, '//a[@class="J_Ajax num icon-tag"]')))
time.sleep(1)
try:
# 通过动作链,滚动到下一页按钮元素处
write = browser.find_element_by_xpath('//li[@class="item next"]')
ActionChains(browser).move_to_element(write).perform()
except NoSuchElementException as e:
print("爬取完毕,不存在下一页数据!")
print(e)
sys.exit(0)
time.sleep(0.2)
# 点击下一页
a_href = browser.find_element_by_xpath('//li[@class="item next"]')
a_href.click()
page_index += 1
六、爬虫完成
最后就是的调用 loginTB(), loop_get_data() 这两个之前写好的,def loop_get_data() 在while循环里就调用了,所以不需要再调用。
爬虫完成后存到了一个shop_data.json文件里。
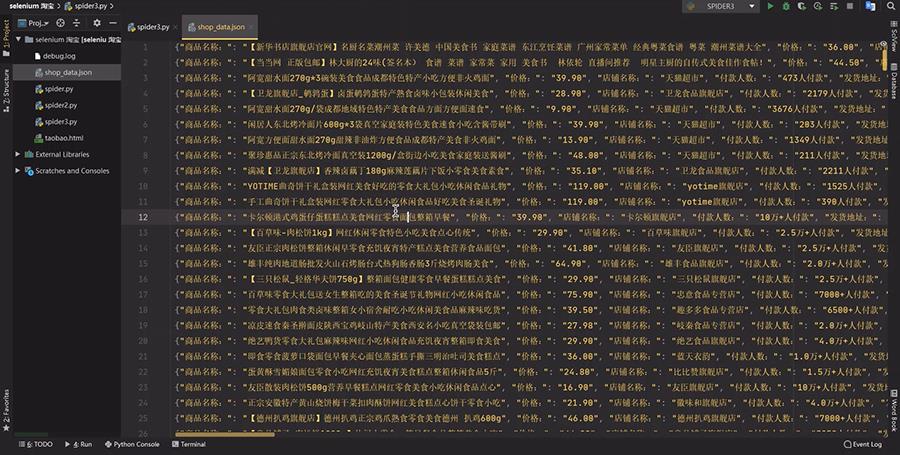
爬取的结果如下:

本次爬虫涉及到的网页均可替换,小伙伴们需要源代码,在评论区评论:taobao后私信我就可以,或者在爬取的过程中遇到什么问题可以随时问我。

感谢每一位愿意读完我文章的人,对于新媒体创作我也在不断学习中。创作是一件非常值得持续投入的事情,因为你们每一次的支持都是对我极大的肯定!
再次感谢大家的支持,在此我整理了一些适合大多数人学习的资料,免费给大家下载领取!
看!干货在这里↓ ↓ ↓
- 2000多本Python电子书。(主流的经典的都包含在内)
- Python基础入门、爬虫、web开发、大数据分析方面的视频。
- 多个项目及源码。(四五十个有趣且经典的练手项目及源码)
- Python所有方向学习路线图(更系统更高效的学习)
- 经典Python面试题。(面试大厂稳了)
- web前端开发学习视频及PDF电子书。(都是最新版次的书籍)
有需要的读者可以直接拿走,在我的QQ学习交流群。有学习上的疑问、或者代码问题需要解决的,想找到志同道合的伙伴也可以进群,记住哦仅限学习交流!!!
裙号是:298-154-825。

以上是关于同事半个月都没搞懂selenium,我半个小时就给他整明白!顺手秀了一波爬淘宝的操作的主要内容,如果未能解决你的问题,请参考以下文章