大数据实战之mapreduce编程
Posted 进击的鱼豆腐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据实战之mapreduce编程相关的知识,希望对你有一定的参考价值。



采用IDEA作为编写mapreduce程序的编辑器,所以前期要配置好mapreduce的编程环境,这里采用maven来管理jar包。
1. 在IDEA中创建maven工程
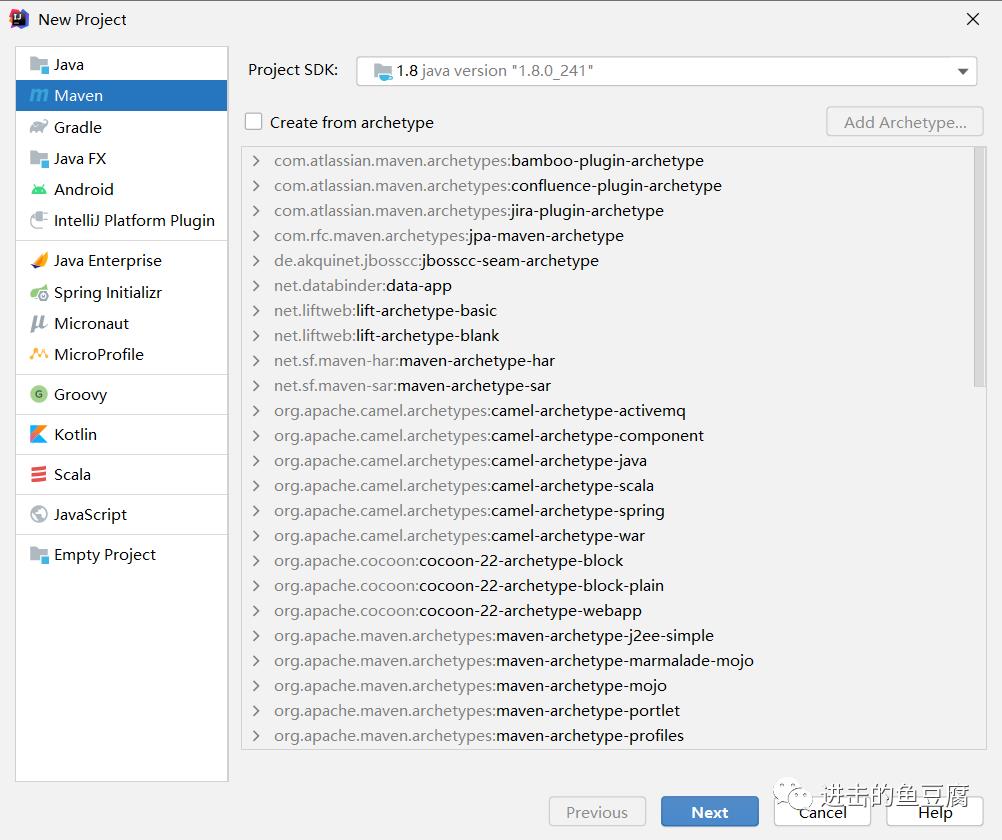
2. 填写工程信息
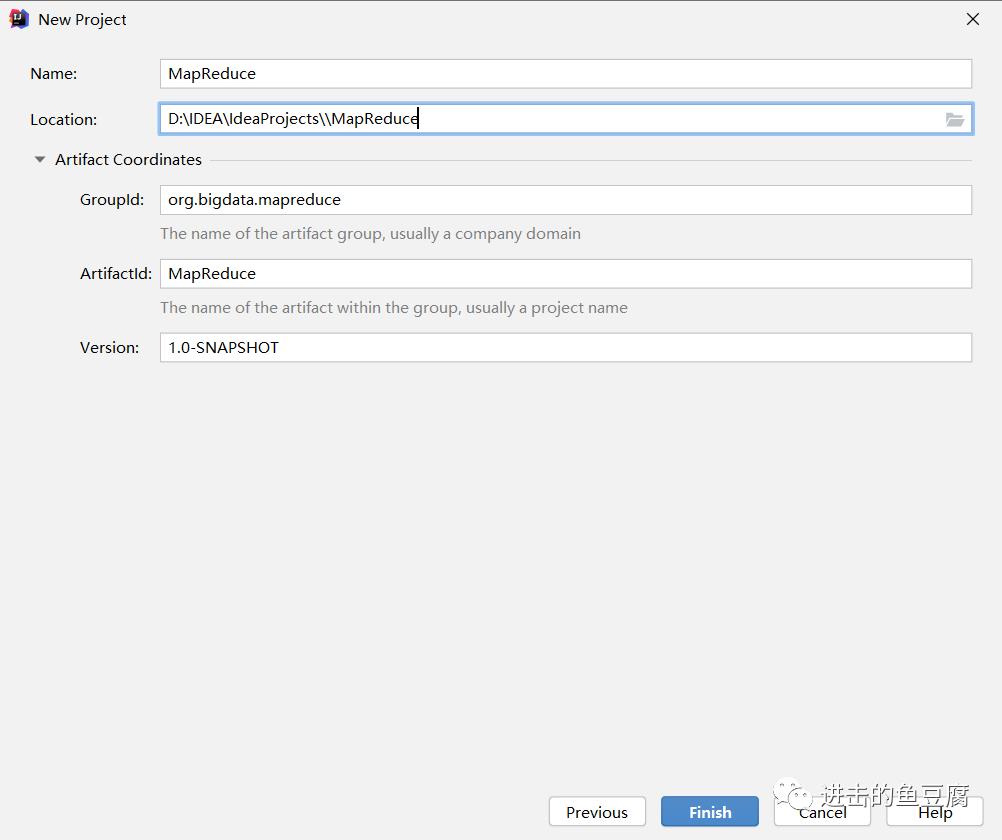
3. 项目创建完成后如下,打开pom.xml文件进行填写信息
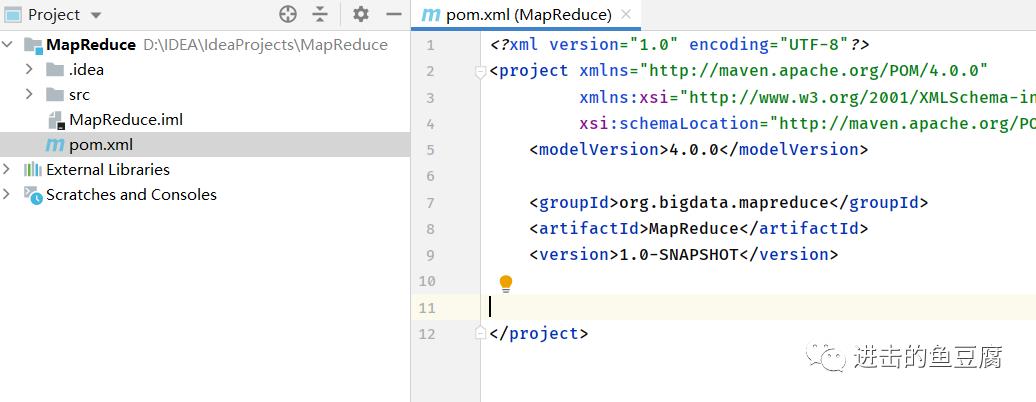
4. 添加如下信息,然后导入库
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.mapreduce.wordcount.Driver</mainClass><!--主类名-->
</transformer>
</transformers>
<artifactSet>
</artifactSet>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs-client</artifactId>
<version>3.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-yarn-api -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-api</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.2.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.13.3</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.13.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
</dependency>
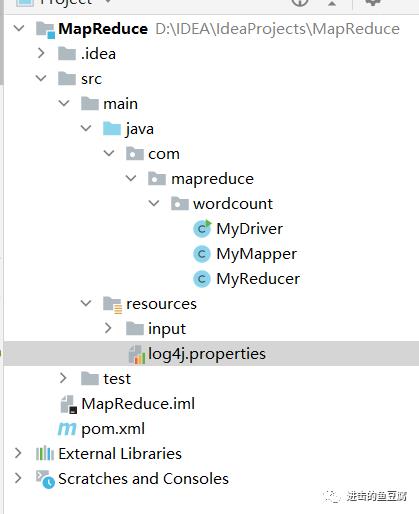
</dependencies>5. 环境配置完后,创建如下目录结构,接下来就可以开始编写代码啦
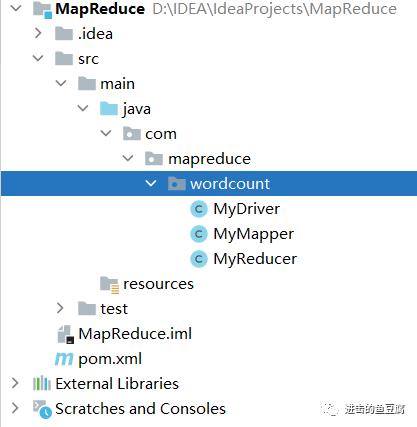
wordcount程序中主要由三部分组成,Mapper,Reducer和Driver。下面通过编写这三部分来一一体会三种模块的功能。
编写Mapper
MyMapper中写入的内容如下
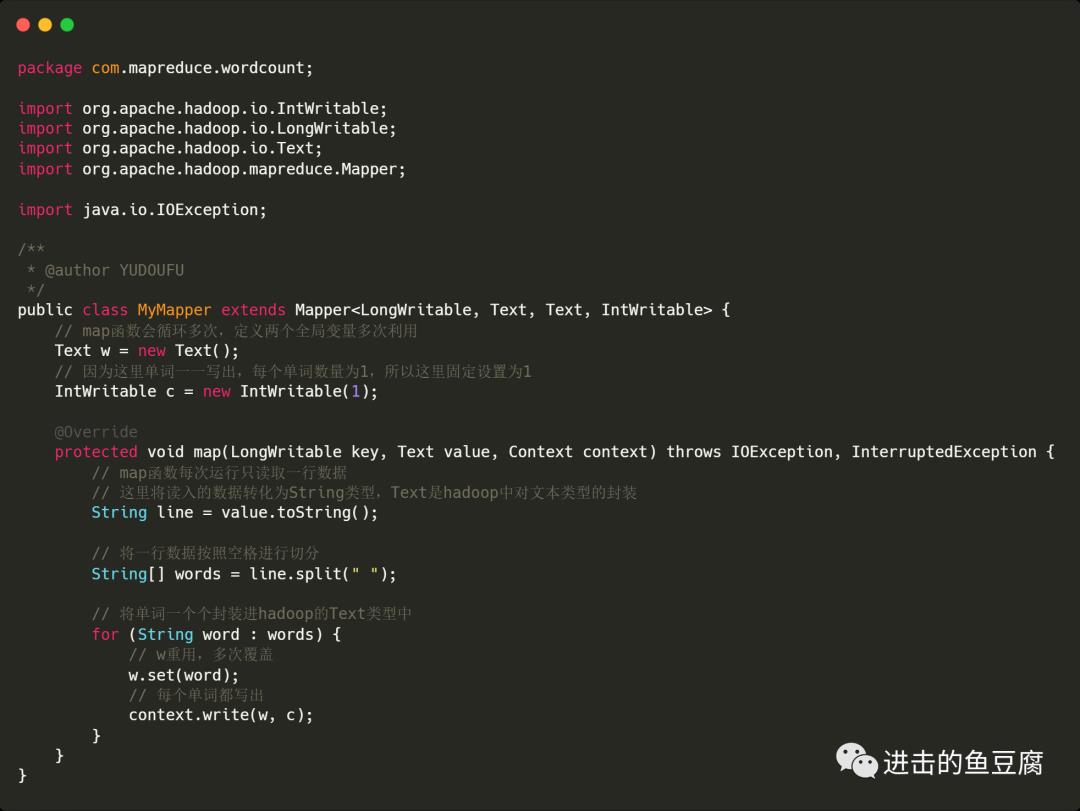
编写Reducer
MyReducer中写入如下内容
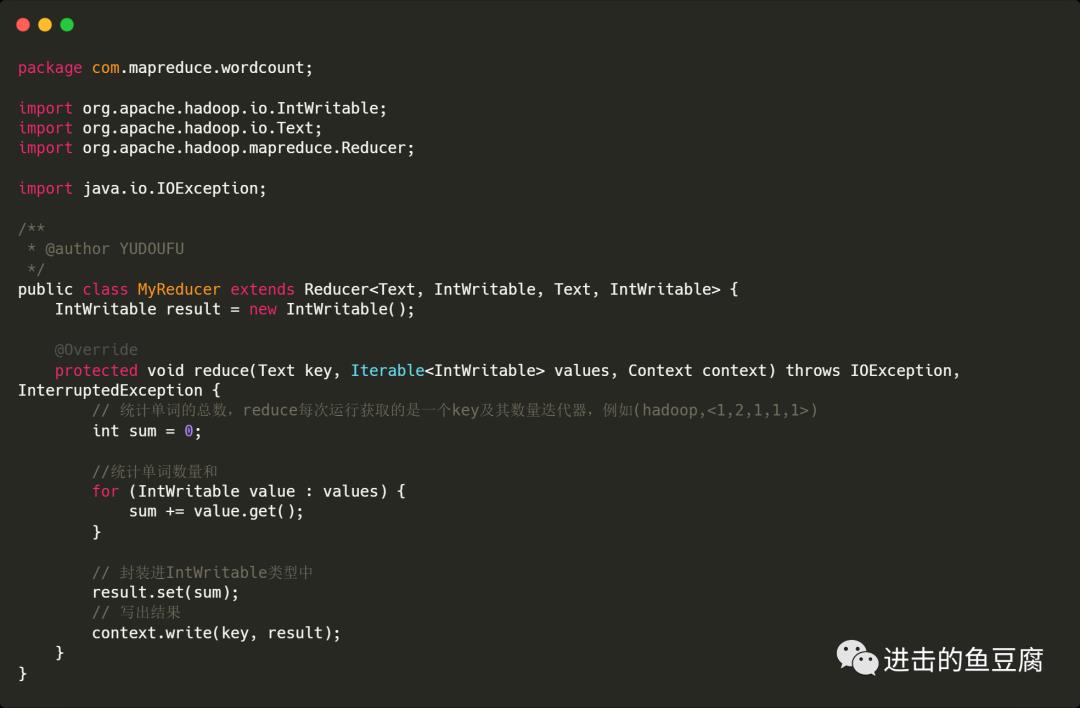
编写Driver
MyDriver中输入内容如下
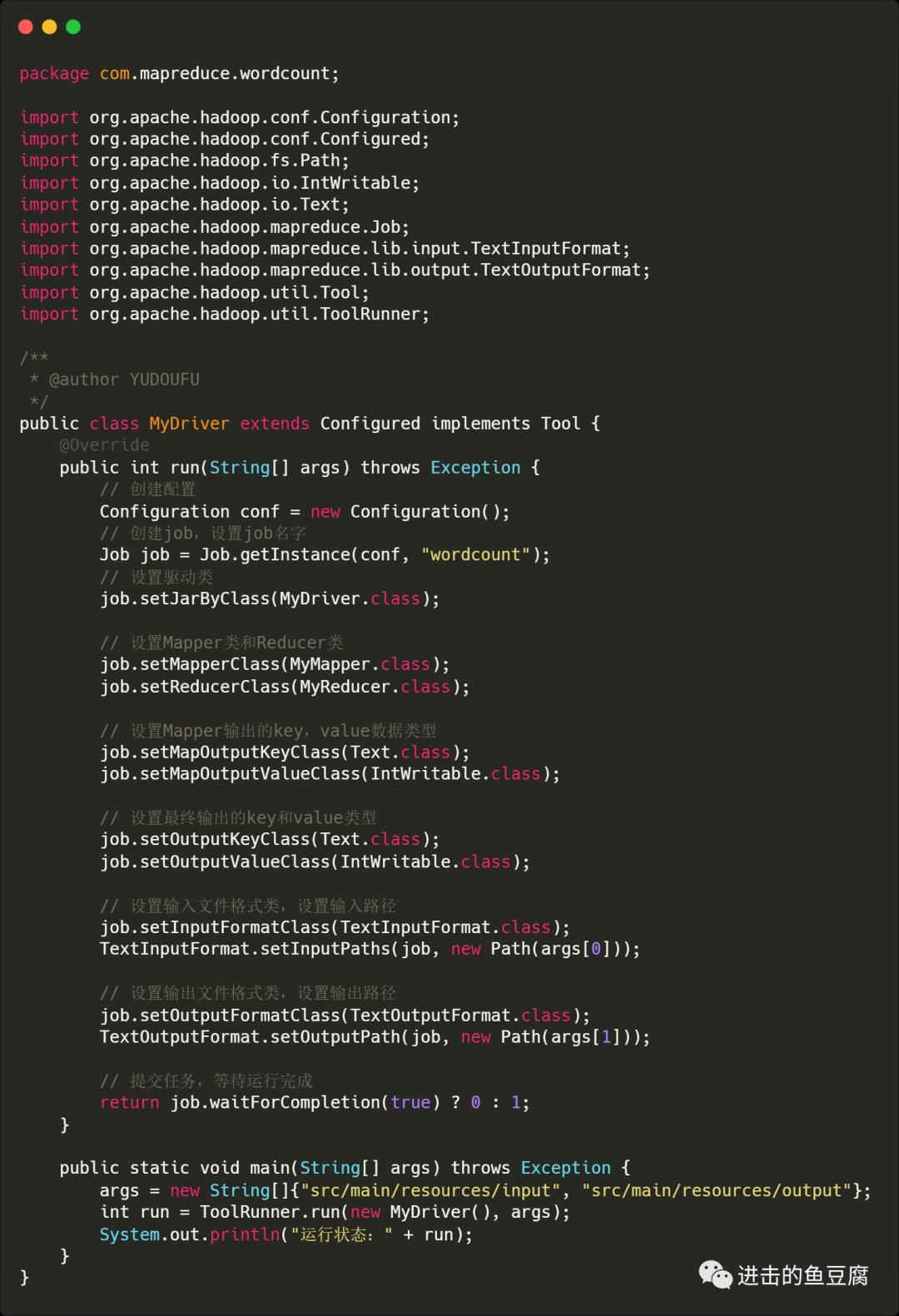
配置日志文件
为了方便观察运行日志,需要将日志打印在控制台显示。
1. 在resources文件夹下面创建log4j.properties文件
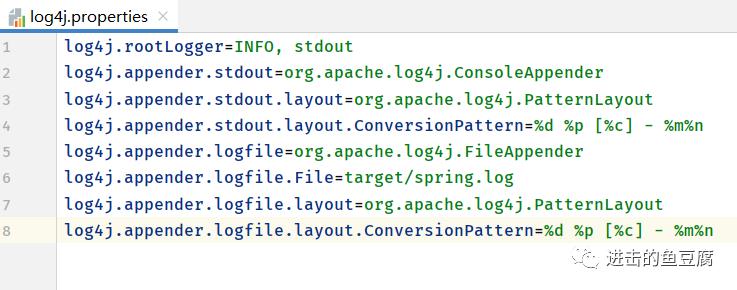
2. 填入以下内容
log4j.rootLogger=INFO, stdoutlog4j.appender.stdout=org.apache.log4j.ConsoleAppenderlog4j.appender.stdout.layout=org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%nlog4j.appender.logfile=org.apache.log4j.FileAppenderlog4j.appender.logfile.File=target/spring.loglog4j.appender.logfile.layout=org.apache.log4j.PatternLayoutlog4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
准备输入文件
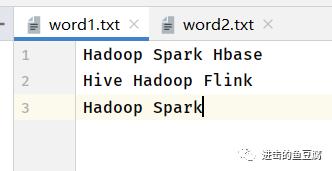
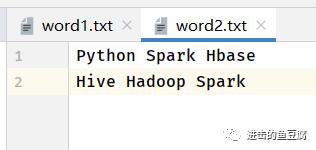
在resources文件夹下面创建input文件夹,创建两个文件word1.txt,word2.txt
内容如下:
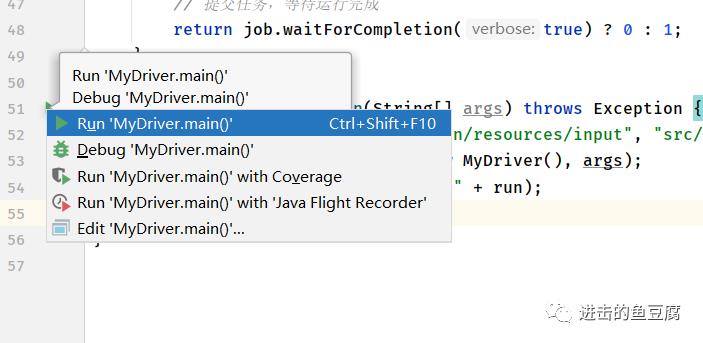
1. 运行main函数
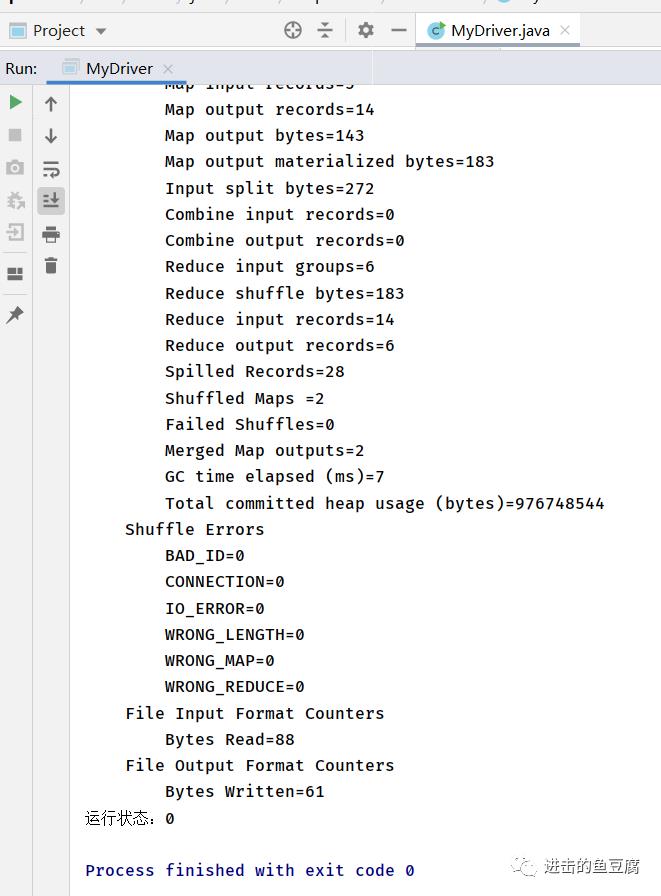
2. 控制台运行结果
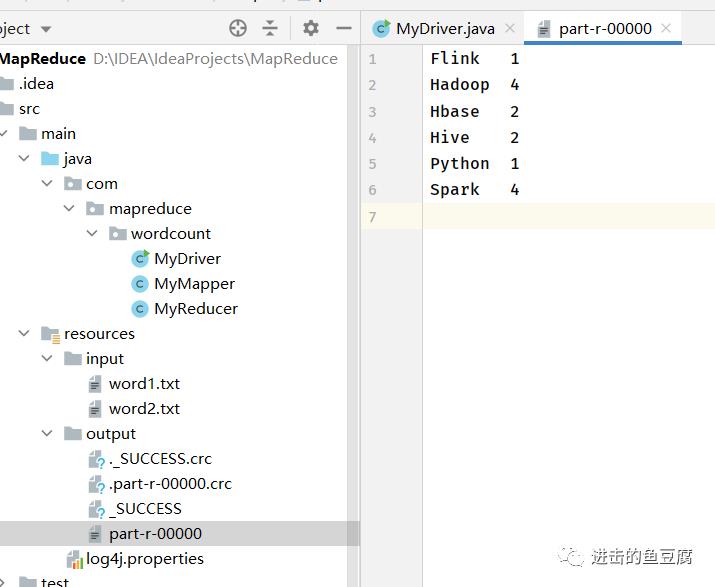
3. 查看resources下生成的output文件夹的结果,可以验证与上篇推断的结果一致,如果需要再次运行,需要更改输出目录或删除生成的output文件夹
以上就是本地运行mapreduce程序的流程,下一节将尝试如何将程序打包上传至集群运行,跟上节奏一起来看看吧。
本章内容已打包
wordcount
即可获取项目代码!
往期推荐

扫描二维码获取
更多精彩

进击的鱼豆腐
点个在看再去干饭
以上是关于大数据实战之mapreduce编程的主要内容,如果未能解决你的问题,请参考以下文章