三个问题揭秘HDFS Router中的RPC流转
Posted 哈逗噗哈呜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了三个问题揭秘HDFS Router中的RPC流转相关的知识,希望对你有一定的参考价值。
问题:
1、client经由router转发到namenode的rpc请求如何流转?
2、router在中间是否会影响rpc吞吐效率?
带着这两个问题进入本文。文末会提出一个新的问题可以讨论。
RBF Router概述
HDFS Router Federation是解决Namenode扩展性问题的一个方案,对原先的Federation+viewFS方案进行改进,可以理解为服务端的viewFS,相对于viewFS最大的好处在于做到对用户的完全透明。官网架构图如下:
核心概念:
l 底层由多个namespace的子集群组成,可以是独立的hdfs集群,也可以是Federation集群,或者他们的混合。
l 通常每个namenode节点上会部署一个Router,Router向客户端提供namenode接口的服务,Router本身无状态。
l StateStore维护federation的状态信息,比如底层NameNode的信息MembershipState、路径挂载信息MountTable等。默认的实现stateStore信息存放在zookeeper上。
RBF在原先的HDFS基础上增加了Router服务,Router类图如下:

根据类包含的成员变量我们可以了解router提供的一些功能,
router对外提供了rpcServer、adminServer、httpServer服务接口;
支持全局的quota配置管理;
定时心跳更新自己在statestore里的状态(默认zookeeper实现)

RBF Router核心特性包括StateStore、QuotaManager、NameNodeHeartbeat等等,本文仅聚焦于Rpc的流转过程。
核心类介绍
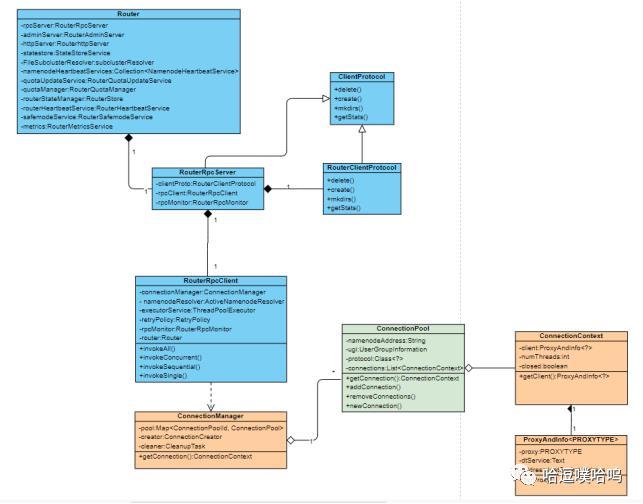
Router提供了RouterRpcServer处理客户端的rpc请求。RouterRpcServer会实例化一个RouterRpcClient来做客户端与NameNodeRPC通信连接的媒介,几乎所有非Federation模式下的HDFS的RPC请求都会经过RouterRpcClient才能转发到具体的NameNode请求响应。
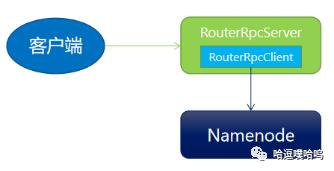
RouterRpcClient
RouterRpcClient作为Router到NameNode通信(用NameNode ClientProtocol)的客户端代理,提供了调用远程ClientProtocol 方法、处理重试和故障转移的路由。将rpc转发到具体的NS,提供了以下几种调用方式:
invokeSingle |
只向一个NS发起请求。 |
invokeSequential |
向排序的多个NS顺序发起一连串的请求,直到一个请求返回正常结果、或者所有NS都被尝试过。 |
InvokeAll |
类似invokeSequential,只是并发调用。 |
invokeConcurrent |
向多个NS发起并发的请求,并且返回所有的结果整合 |
根据不同类型的rpc操作和不同的挂载策略,RpcClient会选择不同的调用方式。
我们看到RouterRpcClient里几个重要的成员变量:
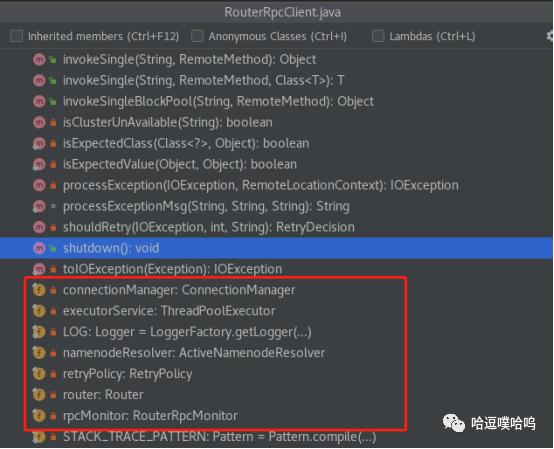
ActiveNamenodeResolver:
用来获取NS的active namenode,其实现类MembershipNamenodeResolver通过与StateStoreService通信获取active NN并维护一个本地缓存以减少对statestore的访问。
ExecutorService:
提交与NameNode通信的异步任务的线程池服务,主要被invokeConcurrent调用。线程池大小可配置:dfs.federation.router.client.thread-size,默认32。
ConnectionManager:
连接池管理器,维护user到NN的连接池:Map<ConnectionPoolId, ConnectionPool> pools,每个user到一个NN的连接都在一个pool内。每个连接池的大小(单个pool内最大连接数)可配置:dfs.federation.router.connection.pool-size,默认值64。
ConnectionManager内有两个重要的线程:ConnectionCreator和CleanupTask,都是内部类,ConnectionCreator负责创建连接。
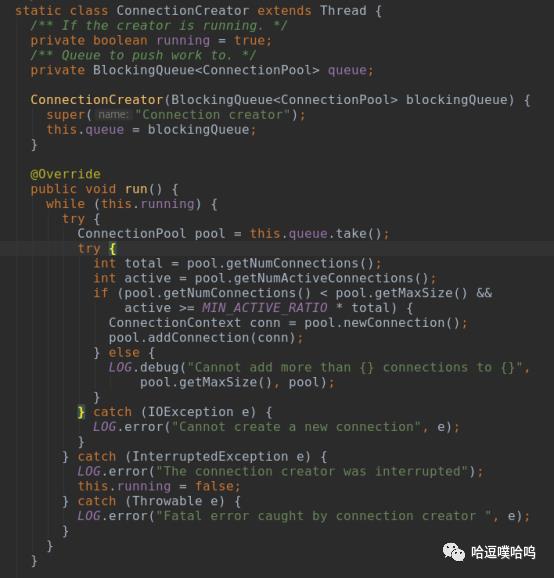
CleanupTask负责清理过期的连接。
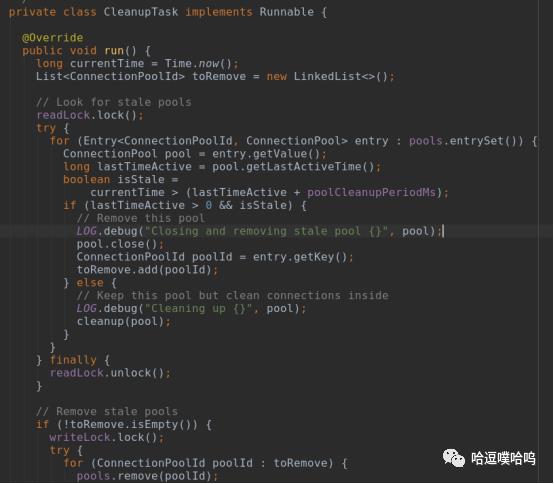
ConnectionPool:
代表一个用户到NN连接的连接池实例,一个ConnectionPool内有多个ConnectionContext。
值得注意的是,连接池和连接都是“懒加载”的,只有当有用户rpc请求getConnection时,才会创建一个pool。并且超时后会自动销毁。
连接池的作用也降低了Router作为rpc转发的性能损耗,不需要每次rpc请求时都实时创建rpc连接。可以预见,在持续稳定的运行生产环境中,Router对于NameNode Rpc吞吐的性能损耗很微小。
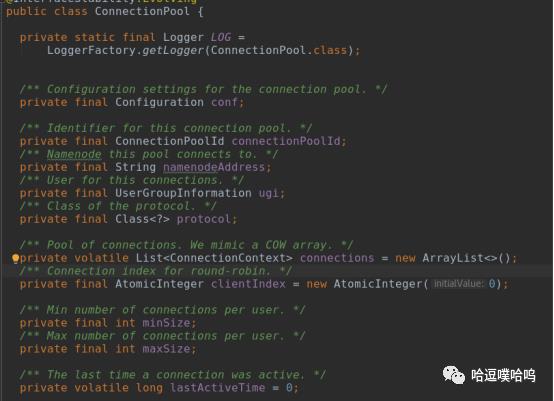
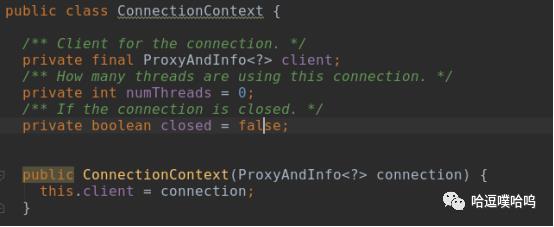
ConnectionContext:
代表一个实际的RPC连接,当一个client使用一个连接,numThreads会++,表示该连接是active的,不能被复用;当连接用完后,numThreads会--。client存储着 NameNode的代理信息,可以获取代理对象。
看图总结:一条RPC流转涉及到RouterRpcServer,RouterRpcClient,RouterClientProtocol,ConnectionManager,ConnectionPool,ConnectionContext这些类。
RPC流转过程
介绍完相关的类之后,我们简单回顾下整个流程。
1、RPC到达RouterRpcServer后,server委托RouterClientProtocol执行;

2、RouterClientProtocol将global 路径根据mounttable解析成具体NS下的路径。
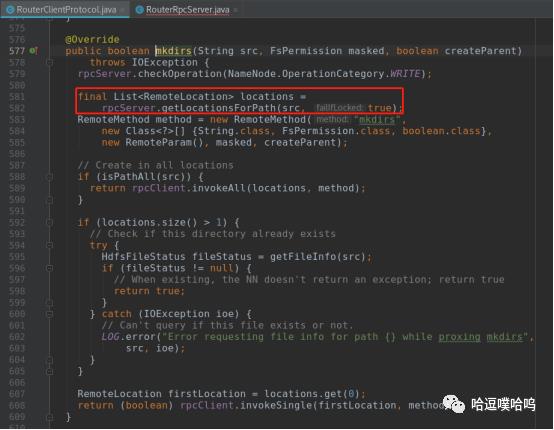
具体调用如下:
RouterRpcServer.getLocationsForPath()--->MultipleDestinationMountTableResolver.getDestinationForPath()--->MountTableResolver.getDestinationForPath()--->从缓存locationCache获取或者lookupLocation()-->findDeepest()找到最深的挂载路径。
注意:
1)一个global路径可能挂载到多个NS;
2)也可能当前path没有挂载,则递归寻找其已经挂载了的父目录;
3)如果父目录都没有挂载,则需要启用defaultNameServices(由dfs.federation.router.default.nameserviceId配置,默认为各个router所在NN节点的NS名)
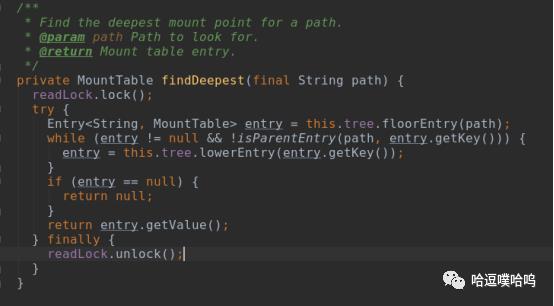
3、获取到locations后,RouterRpcClient再根据挂载的策略和具体rpc类型,决定采用invokeSingle还是invokeAll,invokeSequential或者invokeConcurrent方式向NameNode发起请求,这几种invoke最终都会调用invokeMethod。
4、在invokeMethod向NameNode发请求时,需要通过RouterRpcClient获取User到NN的连接。调用ConnectionManager.getConnection()。
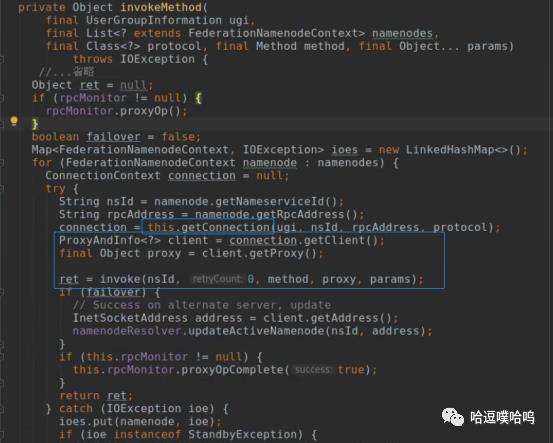
ConnectionManager.getConnection()代码解析:
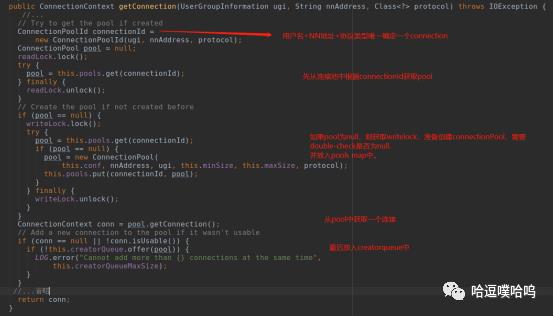
用ugi、nnAddress和Protocol唯一确定一个connectionPoolId;
如果缓存pools(Map<ConnecitonPoolId, ConnectionPool>类型)中有这个poolId,则直接返回pool,继续获取ConnectionContext。
否则,需要新建一个ConnectionPool连接池加入pools内。
 ConnectionPool构造函数:创建ConnectionPool时会同时初始化minSize个ConnectionContext。
ConnectionPool构造函数:创建ConnectionPool时会同时初始化minSize个ConnectionContext。

最后调用ConnectionPool.getConnection()获取具体的proxy client:
采用round-robin方式轮询获取一个可用的connectionContext,clientIndex作为标志位。
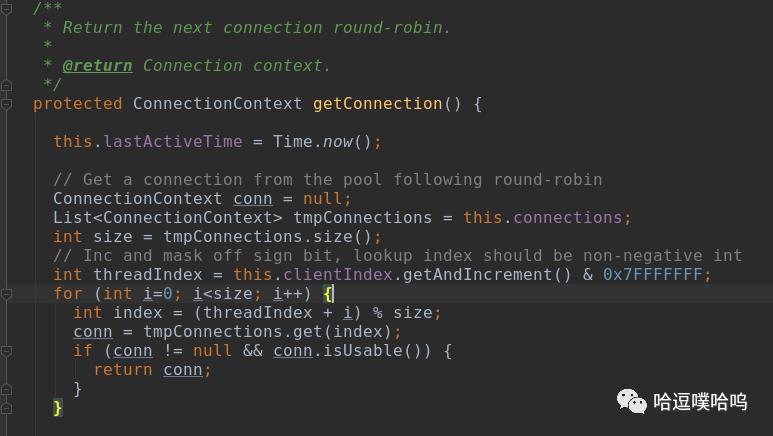
5、连接(ConnectionContext)的client中包含NameNode代理对象,最终反射实现具体的RPC请求发送。至此,一条经过Router转发 的RPC就顺利到达NameNode了。
思考:Router实现Rpc限流
以上文字大体回答了文章开头所提的两个问题。
最后我们再讨论一个问题:如果要在router端实现RPC的限流,可以怎么做?
笔者想着三个方向:
1、Router里有“overload”的概念。RouterRpcClient的线程池服务executorService为Router创建到NameNode rpc异步请求。executorService.getActiveCount()可以获知当前正在运行的异步请求数量。用当前活跃的线程数与最大线程池大小比较,可以判断是否overload,如果overload就抛出StandbyException。某种程度上达到了限流的效果。
但这只是针对invokeConcurrent调用方式,可以限制异步请求的并发数。对于顺序调用invokeSequential没有限制。
3、在ConnectionPool层创建一个RPCThrottleHandler,在invokeMethod里获取连接时切入限流逻辑,可以对每个用户,甚至具体路径、具体操作类型作多租户、细粒度的限流控制。我们目前实现了该方案。
以上是关于三个问题揭秘HDFS Router中的RPC流转的主要内容,如果未能解决你的问题,请参考以下文章