李宏毅老师2020年深度学习系列讲座笔记6
Posted ViviranZ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了李宏毅老师2020年深度学习系列讲座笔记6相关的知识,希望对你有一定的参考价值。
瞎看吧。。。。至少做个笔记
https://www.bilibili.com/video/BV1UE411G78S?from=search&
Q-learning:
首先复习一下critic:负责给一个actor打分,当actor处于某个state的时候,critic可以计算未来可能的期望。注意:critic给的打分和actor(policy\\pi)绑定的,同一个state不同的actor的话critic会给出不同的reward期望。
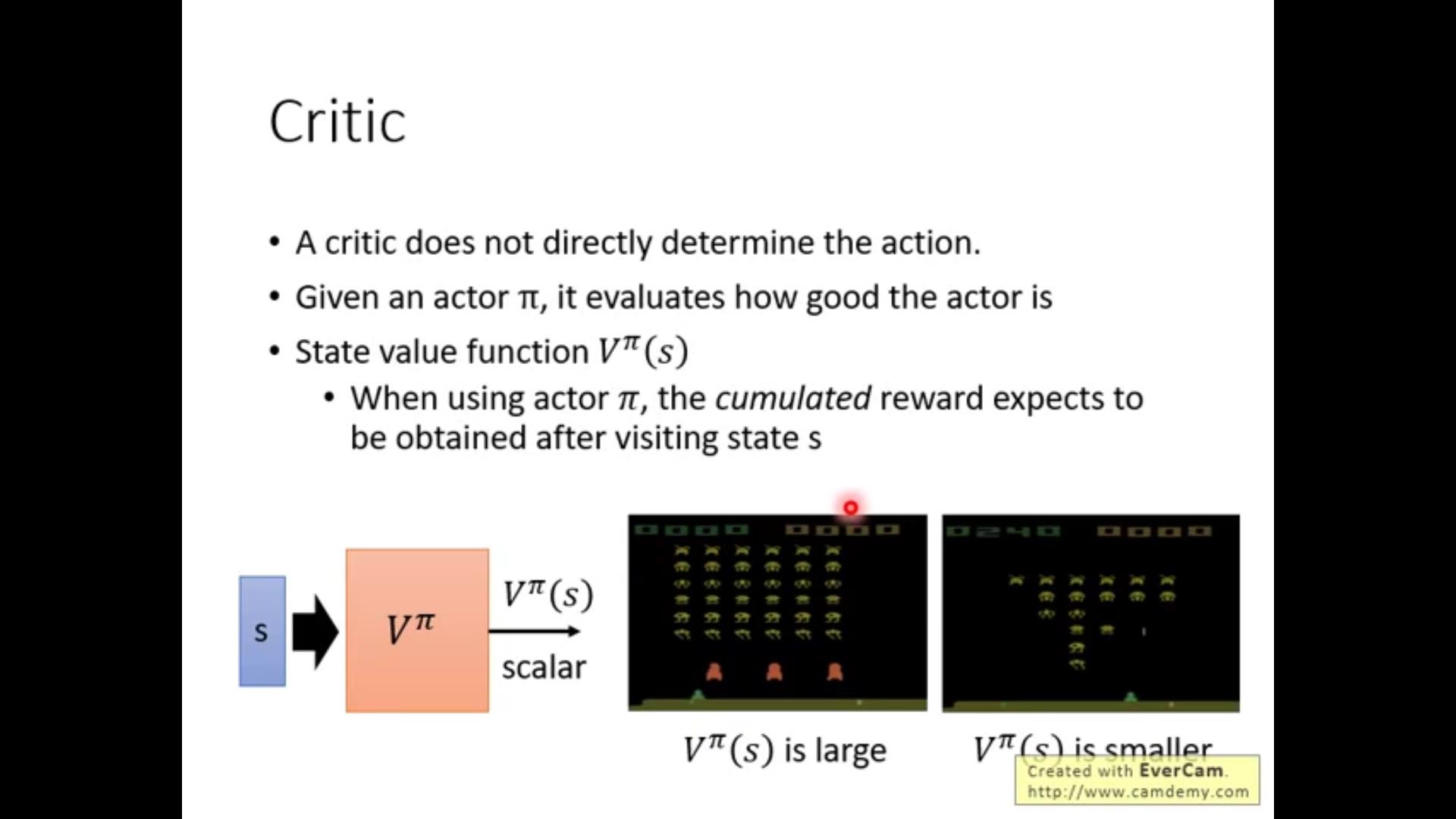
顺便复习一下critic打分的方法:
1.MC方法:
每次都要算accumulated reward,因此必须要玩到游戏结束才能update network。
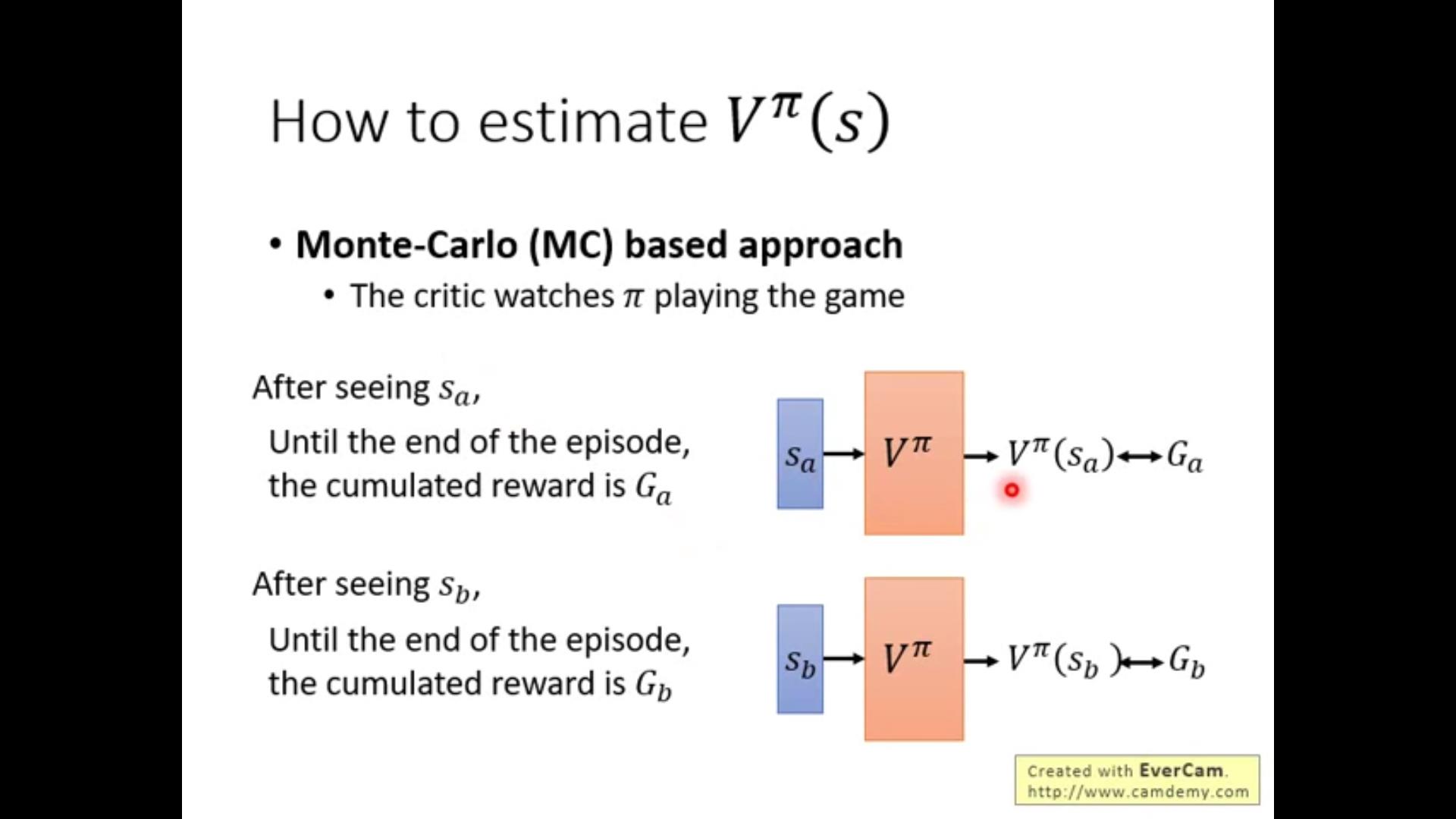
2.TD方法:
不需要玩到最后,只要玩完s_t进入s_{t+1}就可以更新

二者对比:
由于MC要进行到游戏结束,每一步都会有variance,多步是二次的积累,因此方差很大。
TD只往后计算一步,variance小;但是由于计算步数少会造成不准确。
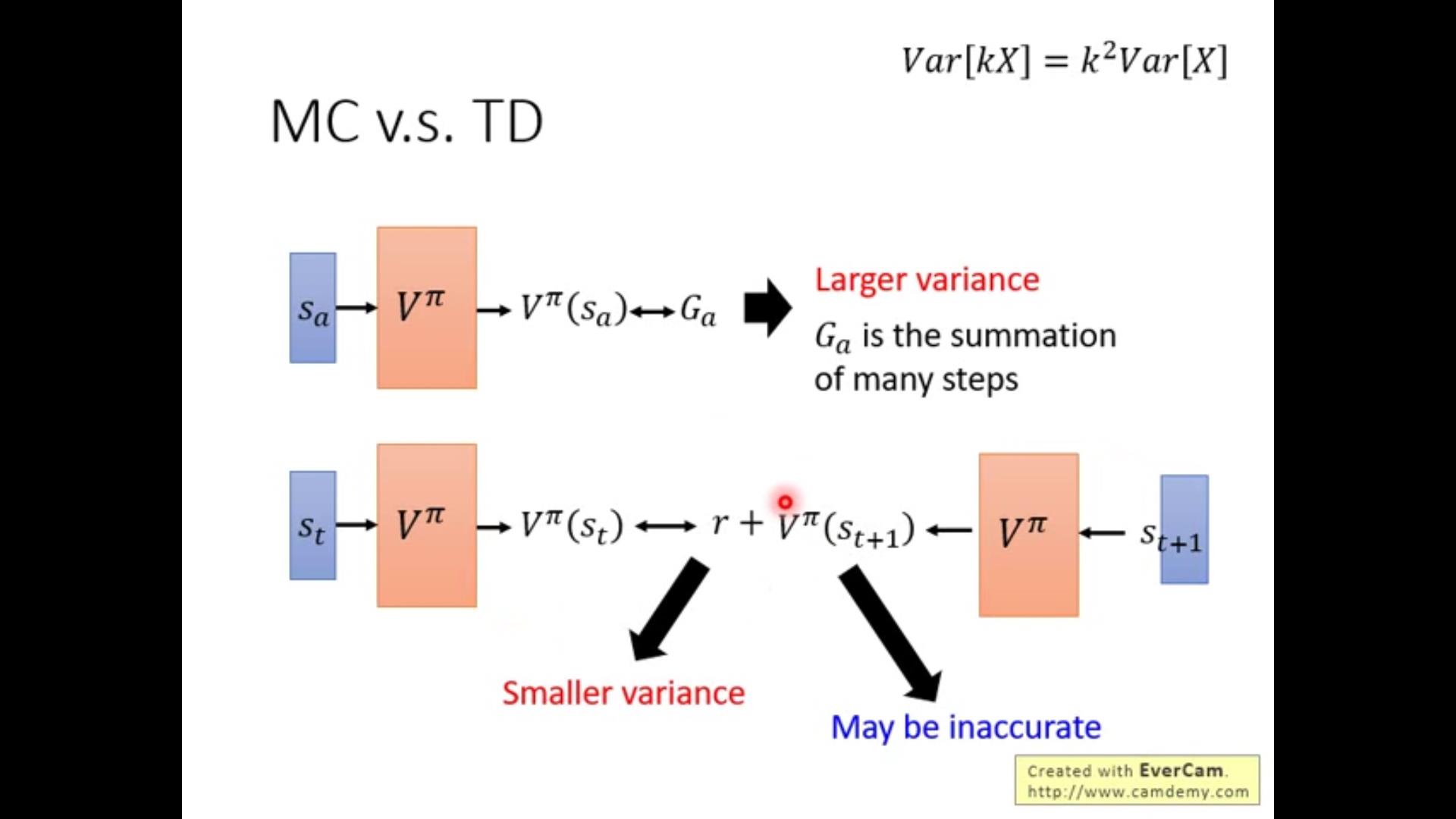
一个例子:
在计算s_a的时候,如果我们把sa视作是一个待赛的state,在MC中运算到最后得到sb证明它的reward应该是0;但是在TD方法中认为sb这个情况只是碰巧,可能是碰到了sb得到0的那1/4,而期望来看sb应该是3/4,也就是sa下应该得到的reward。

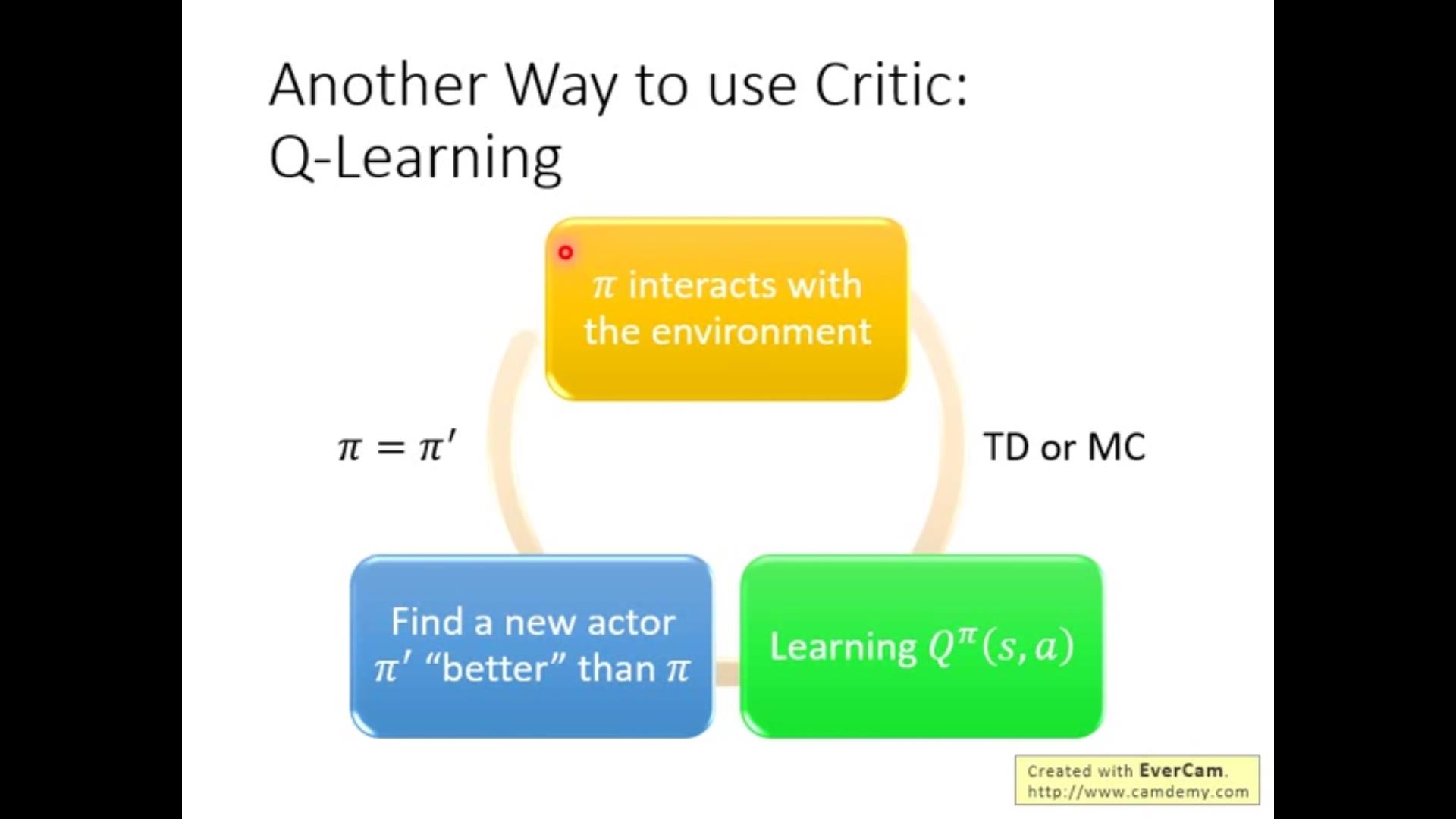
除了MC和TD之外的另一种critic-Q^\\pi(s,a),具体来说就是遇到state s的时候强制执行action a,其他的丢给agent自己按照\\pi来走。也有discrete的形式但是只适用于有限种action。
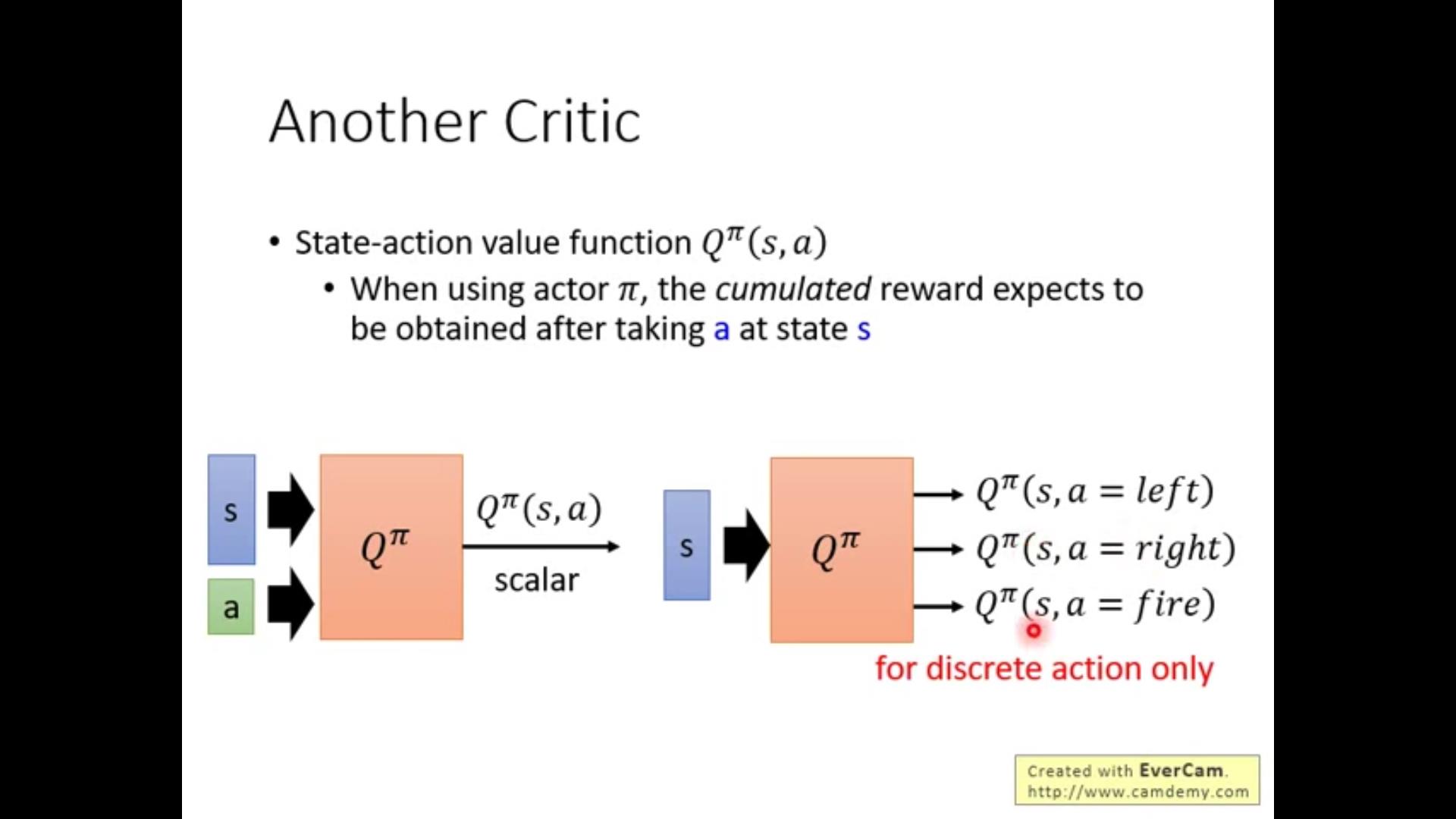
给个栗子:
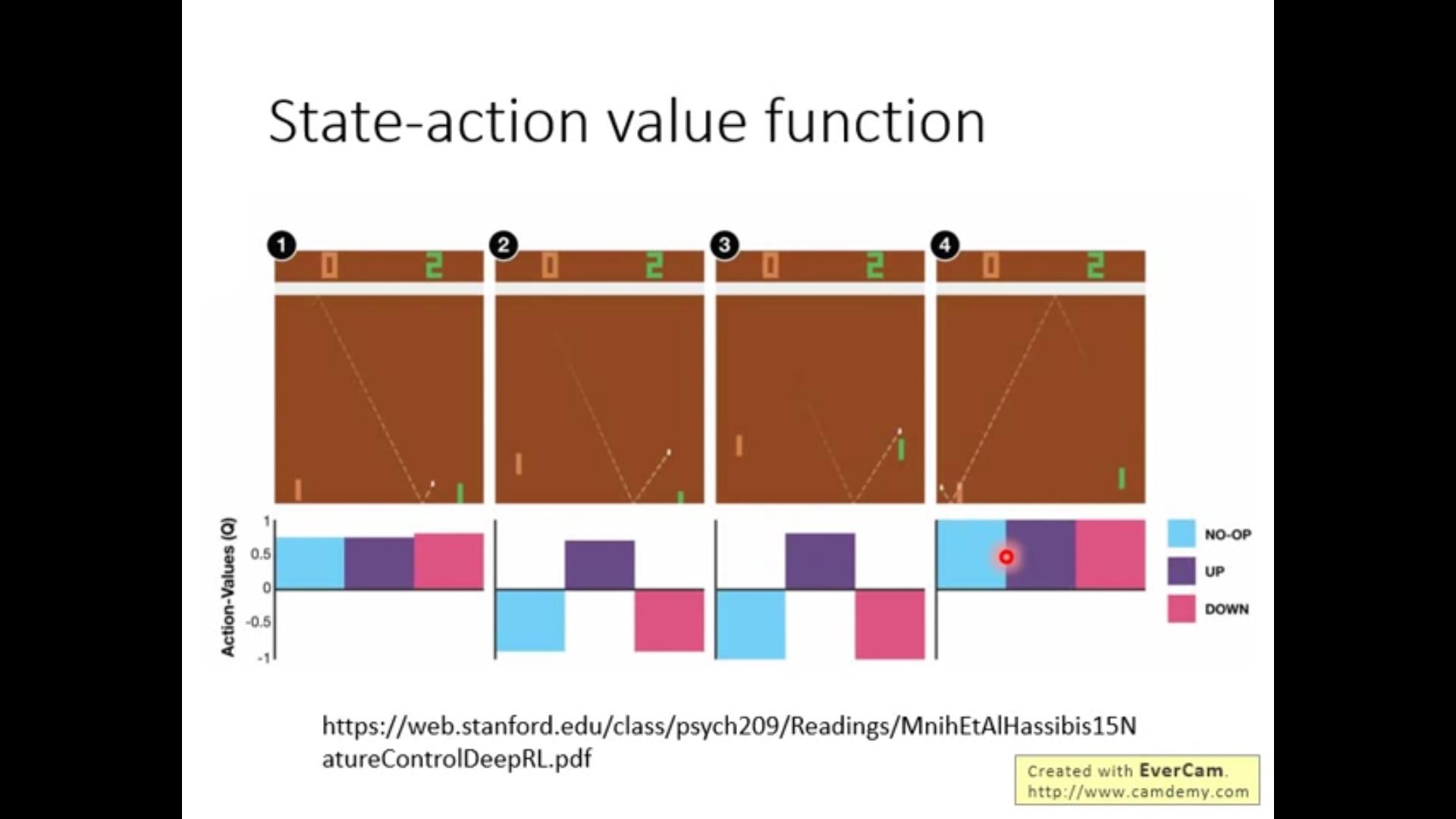
只要有一个Q function和任意一个policy\\pi 永远能找到一个比\\pi更好的policy \\pi',再求Q,再更新\\pi',总能越来越好。
什么叫做“好”?
是在state s的情况下考虑所有可能的action a,找到最大的那个定义为\\pi'对应的action a。

接下来证明一个prop:只要有一个state采取\\pi'(s)给定的action,无论整条路线采用的是哪一个policy\\pi,都会使得最后的Q值增大——更好!

以下几个tips:
actor-critic网络中两个网络。一个只负责走平时不动(target network);另一个疯狂动(……)负责产生尽量好的action,疯狂探索找到最好的下一步返给target,target走完到了下一个state再疯狂探索。。。。(倒霉催的)
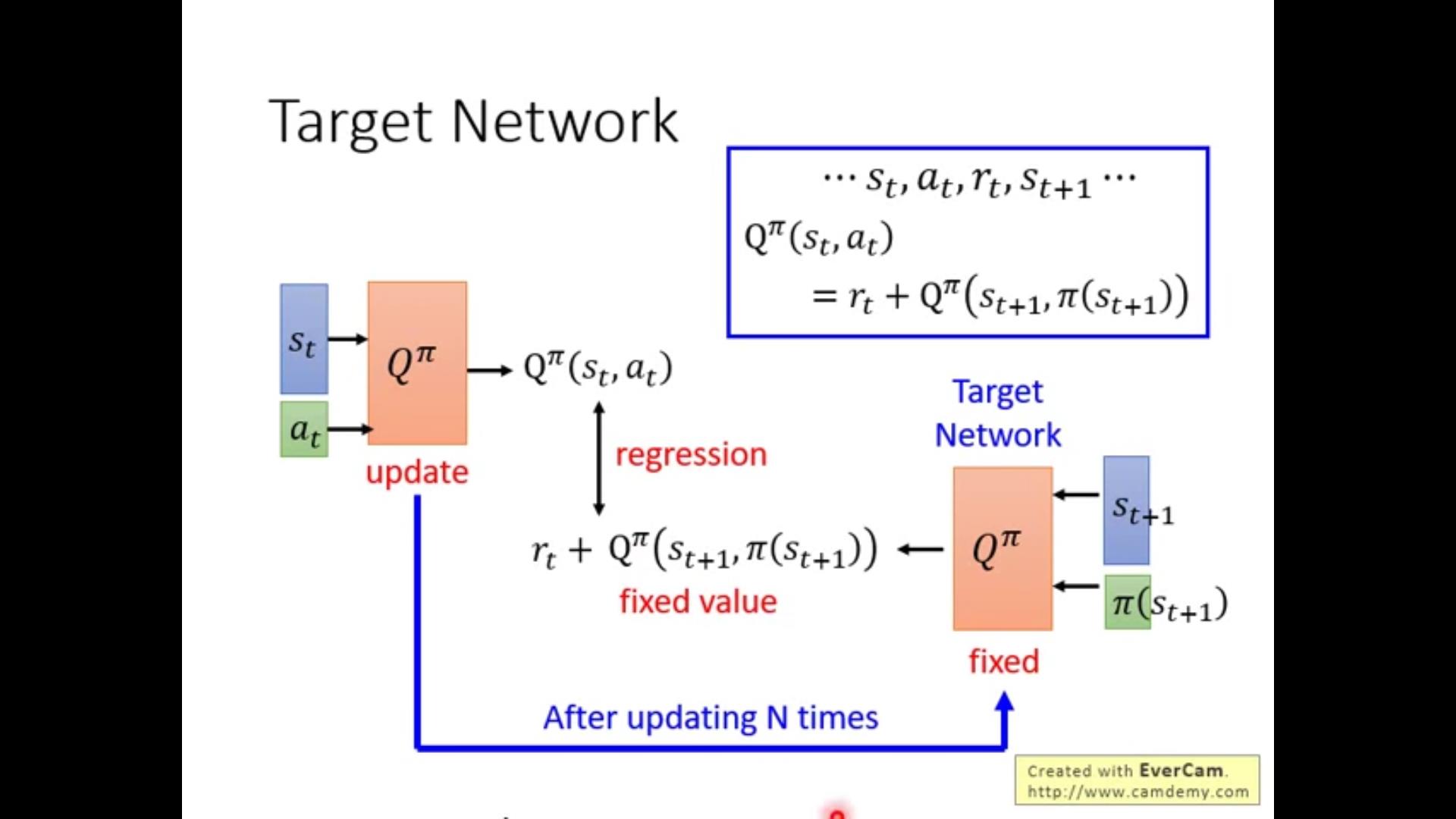
第二个是如果agent没有在state s做过action a,可能无法算出Q值,只能估算。如果Q是一个network还好说(Q怎么是network?不懂),但是generally这是一个问题。agent可能做到一个挺好的就一直做,但是说不定别的没做到的更好。。。所以我们给出\\epsilon-greedy算法和第二种~

第三个:关于存储。
我们希望Buffer里存储的数据尽量diversed。Buffer里存储的很多都是之前用过的\\pi'的数据-增加多样性。值得注意的是,采用\\pi'的数据去计算\\pi会不会导致问题?答案是不会(原因留了思考题?)
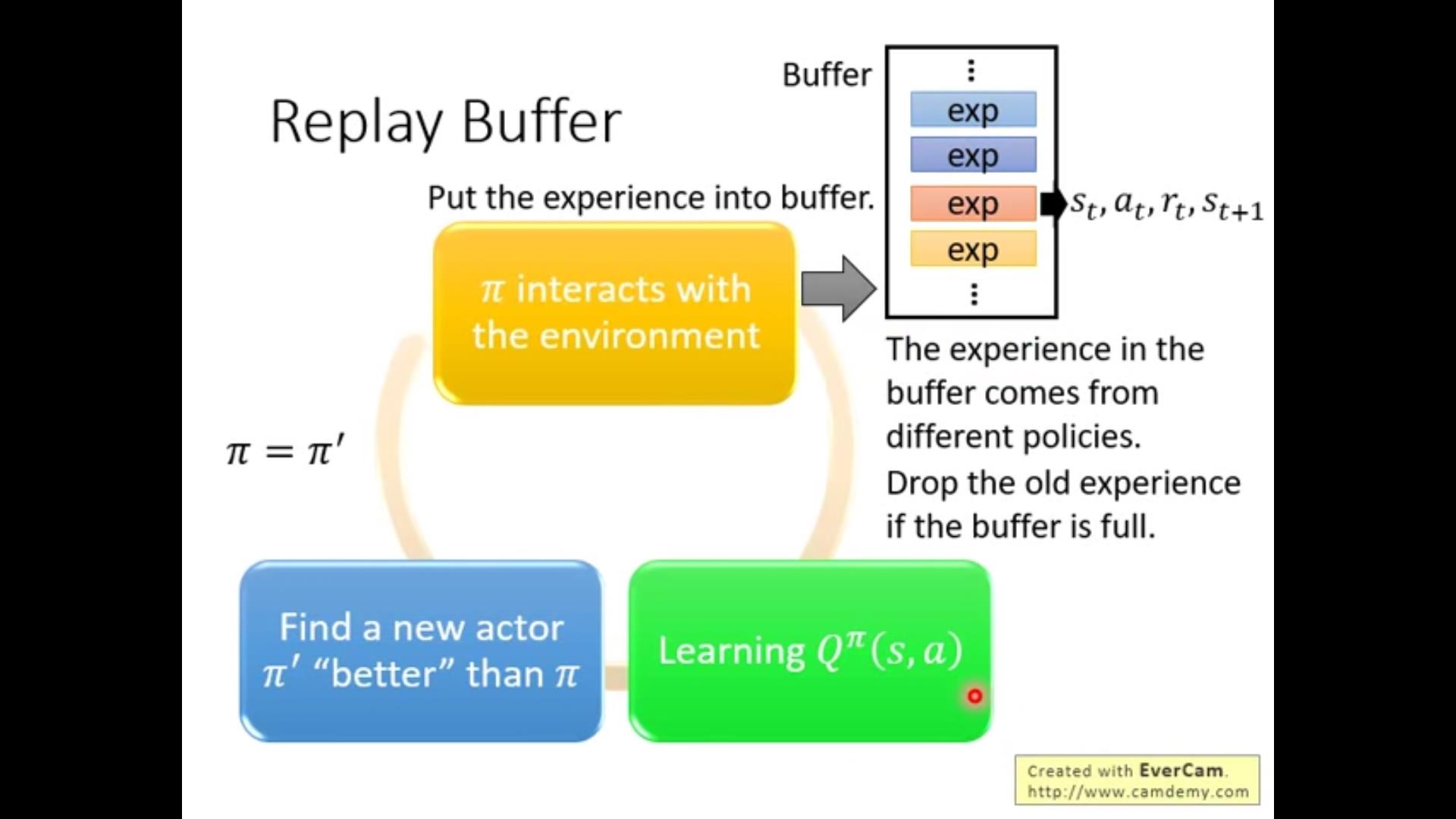
整体总结Q-learning的算法:
注意:
1.store的时候如果buffer满了丢一个出去。
2.sample的是一批(batch)而不是一条(notation可能不清晰)

!!关键想清楚,Q-learning、RL的目标是找到最优的Q!!!!
关于如果是连续的动作空间另一个网络怎么试探(探索exploration)????
Q-learning的方法有一些问题,因此有了Double DQN……(未完待续)
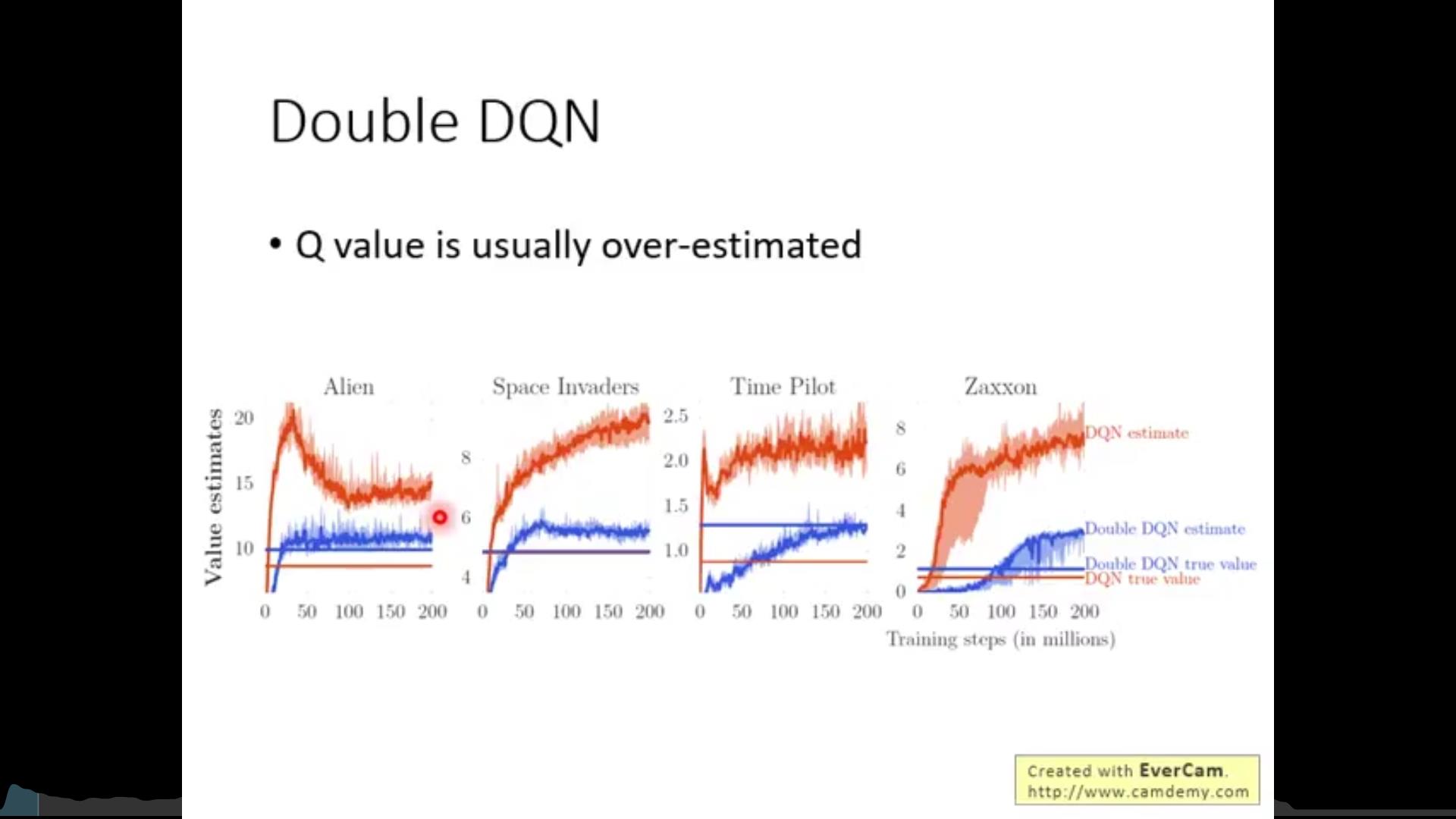
以上是关于李宏毅老师2020年深度学习系列讲座笔记6的主要内容,如果未能解决你的问题,请参考以下文章