李宏毅老师2020年深度学习系列讲座笔记3
Posted ViviranZ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了李宏毅老师2020年深度学习系列讲座笔记3相关的知识,希望对你有一定的参考价值。
瞎看吧。。。。至少做个笔记
https://www.bilibili.com/video/BV1UE411G78S?from=search&seid=11796990666136537025
Learning to Interact with Envs
强化学习关键点:
在环境(environment/state)的影响下产生action,action会影响接下来的环境。
不能完全copy模板,1.copy的话reward有上界-永远不能超过模板 2.可能会学一些不相关的有的没的的行为(Behavior Cloning);更可怕的是很多时候不能全学习,在选择那些更重要更应该学习的时候就失败了。
强化学习的本质问题:
本身对于一个trajectory想要得到一个reward,但是reward函数里面有一些参数是不知道的,因此我们想要通过强化学习给出这些参数
口诀:如果发现不能微分就用policy gradient硬train一发
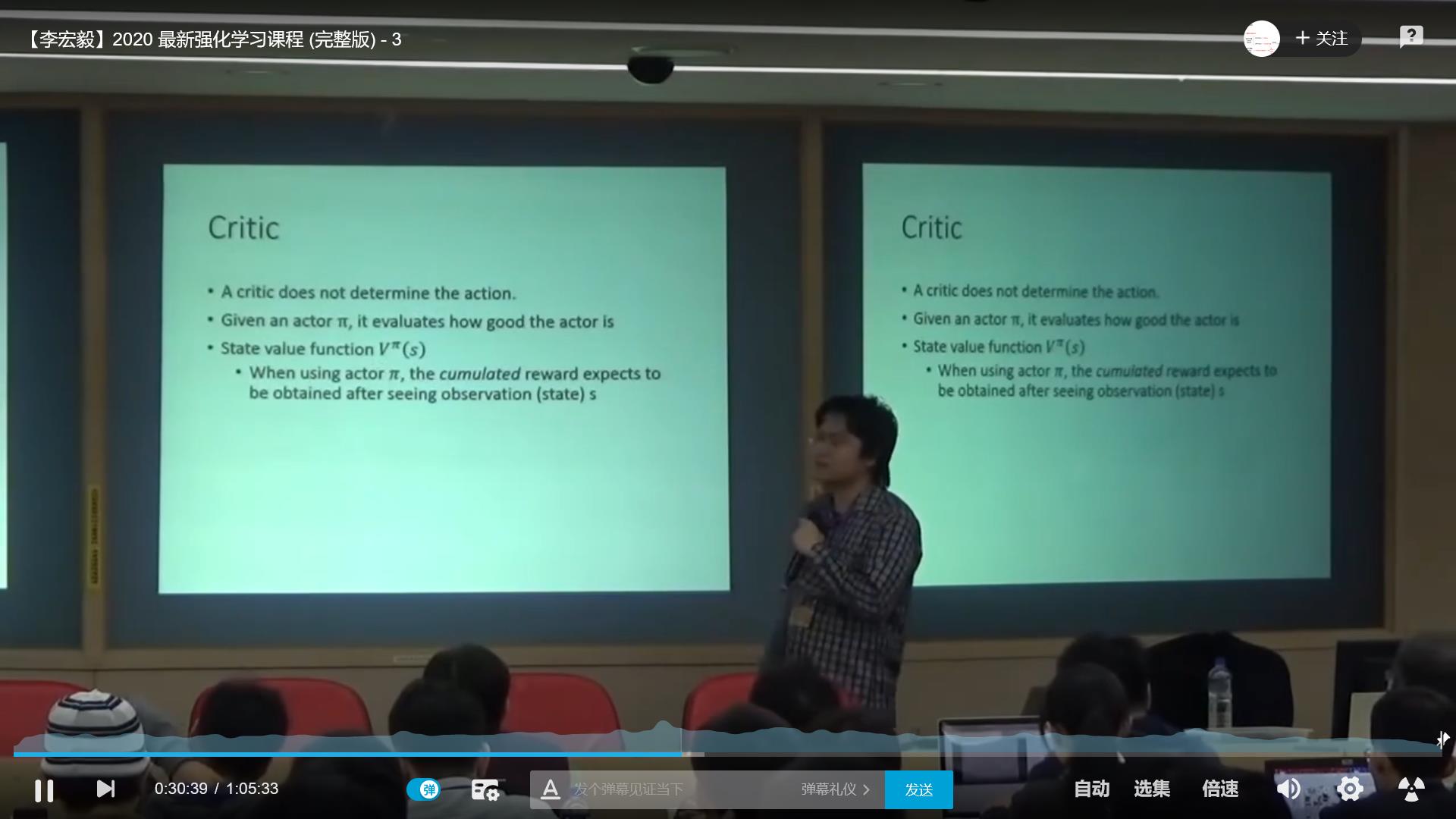
√critic:
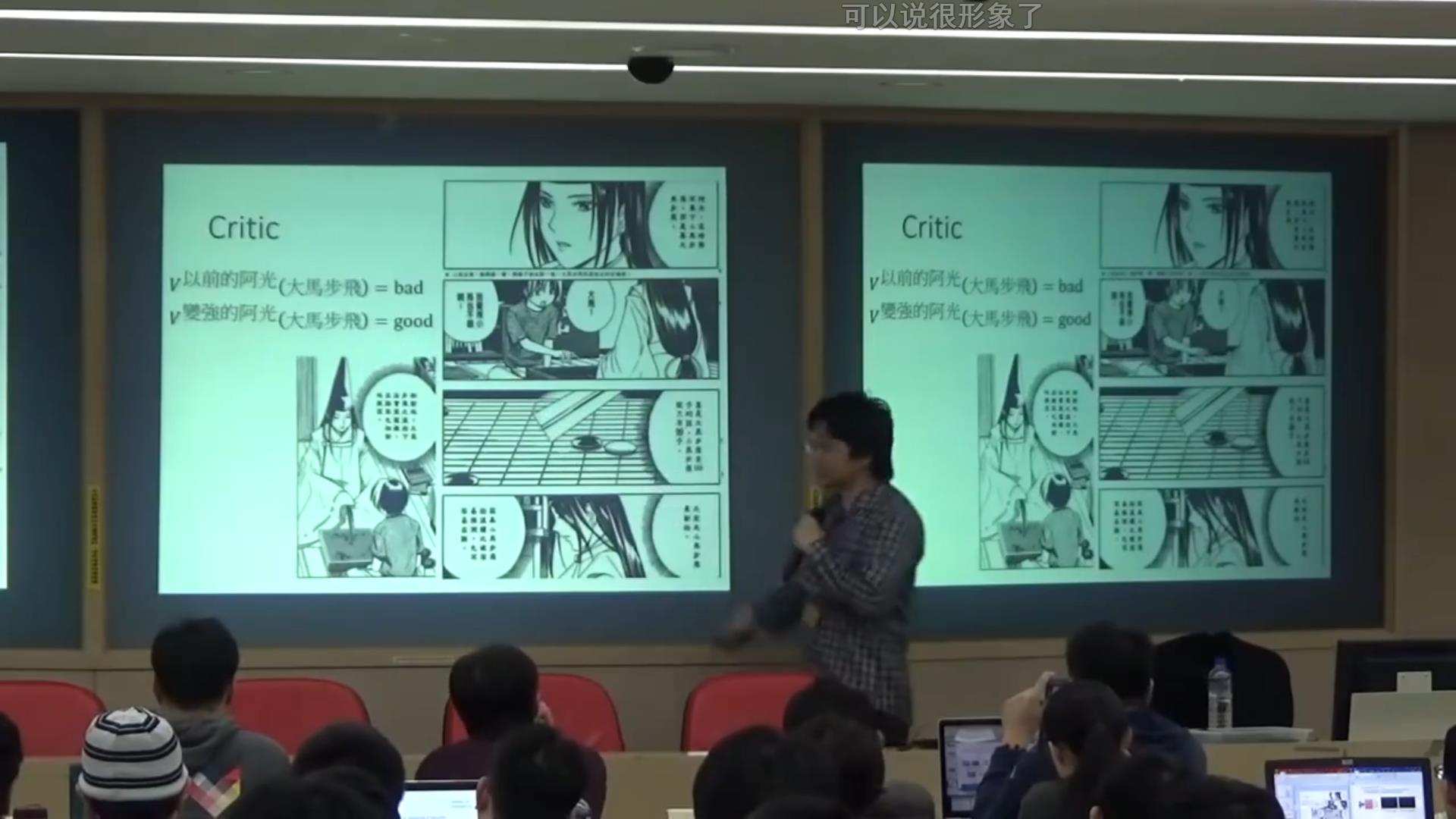
老师给了一个很有意思的例子,是棋魂里面的
如何确认reward的function呢?
a.蒙特卡洛算法

TD方法:

不用玩到最后了,只要再往后玩一步,通过两个value的插值让它尽量接近………………
运用MC和TD的方法:

详细讲讲:

搜论文“Rainbow”
√actor-critic:
只要actor不是根据环境 而是根据critic的反馈学习的都可以叫做actor-critic
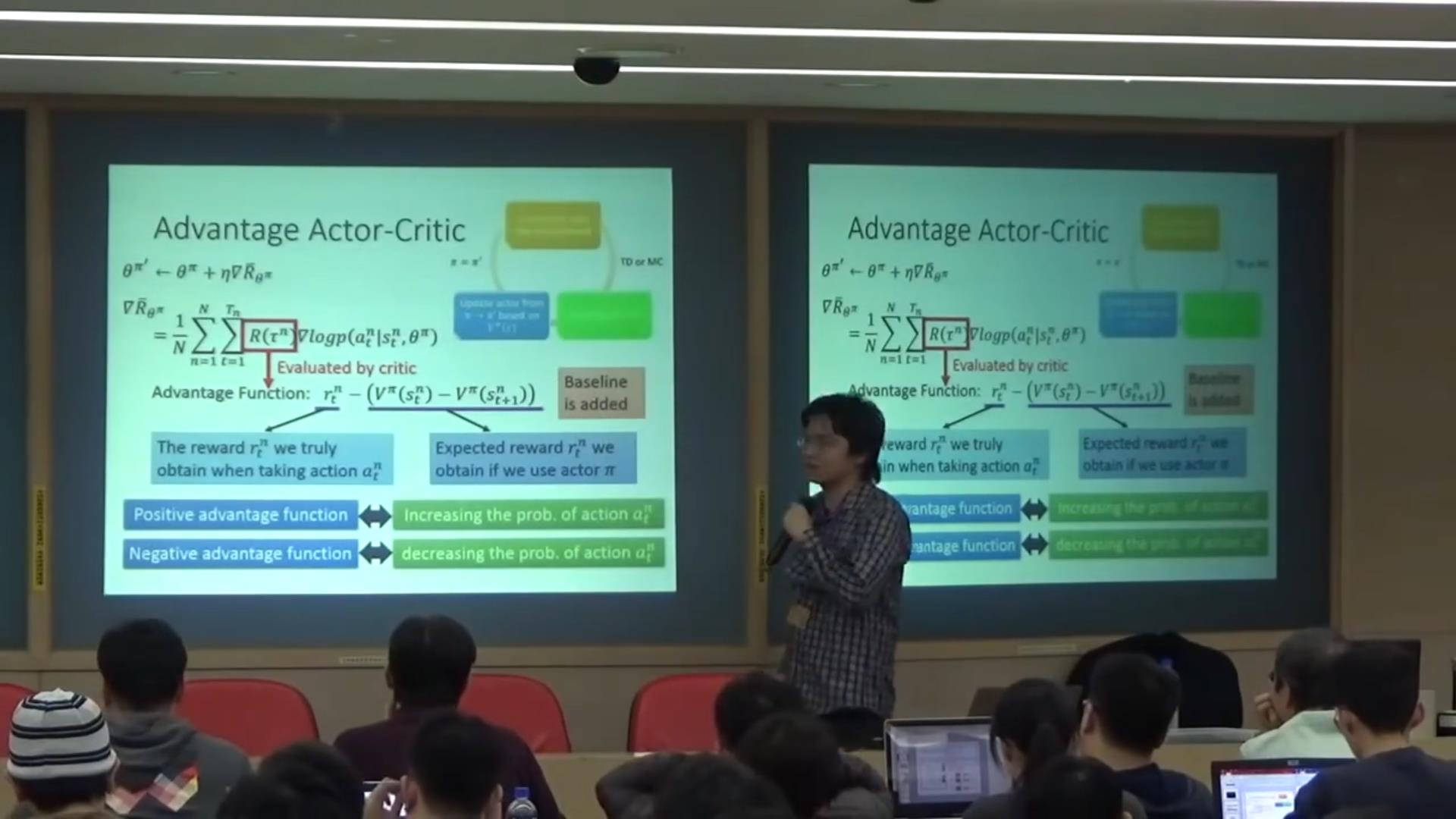
经常出现一个问题:实际生活中不像游戏会有一个明确的规则,比如自动驾驶,撞到人给-100分?那么撞到狗呢?这是不确定的;如果一个机器人目标设定是尽可能快地把碗摆放整齐,它有可能直接摔然后碗全碎掉了。。。因此我们有IRL


具体方法:
老师玩一次学生玩一次-定一个reward function让学生的reward比老师低-学生修改使得分高之后-reward function也相应修改-继续学
以上是关于李宏毅老师2020年深度学习系列讲座笔记3的主要内容,如果未能解决你的问题,请参考以下文章