借助多容器Pod,轻松扩展K8S中的应用
Posted K8S中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了借助多容器Pod,轻松扩展K8S中的应用相关的知识,希望对你有一定的参考价值。
Kubernetes提供了巨大的灵活性和运行各种应用的能力。如果你的应用是云原生微服务或12要素(12-factor)应用,那么在Kubernetes中运行它们有可能会相对简单。
但是,运行那些没有明确设计为在容器化环境中运行的应用程序呢?Kubernetes也可以处理这些问题,但是设置起来可能会比较麻烦。
Kubernetes提供的最强大的工具之一是多容器pod(尽管多容器pod在各种情况下对云原生应用也很有用)。为什么要在一个 pod 中运行多个容器?因为多容器pod可以让你在不改变其代码的情况下更改应用程序的行为。
这在各种情况下都很有用,特别是对于那些最初没有被设计成在容器中运行的应用程序来说,这很方便。我们来看看一个例子。
Elasticsearch是在容器流行之前诞生的(当然现在在Kubernetes中运行也十分简单),它可以看成在虚拟机中运行的传统Java应用的替代。
我们将Elasticsearch作为示例应用程序,然后使用多容器pods来增强它。
以下是十分基本的(非生产环境就绪)Elasticsearch Deployment和服务:
apiVersion: apps/v1kind: Deploymentmetadata:name: elasticsearchspec:selector:matchLabels:app.kubernetes.io/name: elasticsearchtemplate:metadata:labels:app.kubernetes.io/name: elasticsearchspec:containers:- name: elasticsearchimage: elasticsearch:7.9.3env:- name: discovery.typevalue: single-nodeports:- name: httpcontainerPort: 9200---apiVersion: v1kind: Servicemetadata:name: elasticsearchspec:selector:app.kubernetes.io/name: elasticsearchports:- port: 9200targetPort: 9200
discovery.type环境变量是让它以单个副本运行的必要条件。
Elasticsearch默认通过HTTP端口9200进行监听。你可以通过在集群中运行另一个Pod并curl到elasticsearch服务来确认pod工作。
kubectl run -it --rm --image=curlimages/curl curl \-- curl http://elasticsearch:9200{"name" : "elasticsearch-77d857c8cf-mk2dv","cluster_name" : "docker-cluster","cluster_uuid" : "z98oL-w-SLKJBhh5KVG4kg","version" : {"number" : "7.9.3","build_flavor" : "default","build_type" : "docker","build_hash" : "c4138e51121ef06a6404866cddc601906fe5c868","build_date" : "2020-10-16T10:36:16.141335Z","build_snapshot" : false,"lucene_version" : "8.6.2","minimum_wire_compatibility_version" : "6.8.0","minimum_index_compatibility_version" : "6.0.0-beta1"},"tagline" : "You Know, for Search"}
现在,假设你正在向零信任安全模式发展,你需要对网络上的所有流量进行加密。如果应用程序没有原生的TLS支持,你会如何去做?
近期版本的Elasticsearch支持TLS,但它在之前很长一段时间内是一个付费功能。
我们首先想到的可能是用nginx ingress做TLS终止,因为ingress是集群中路由外部流量的组件。但这并不能满足要求,因为ingress pod和Elasticsearch pod之间的流量可能会在未加密的情况下通过网络。
外部流量被路由到Ingress,然后路由到Pod
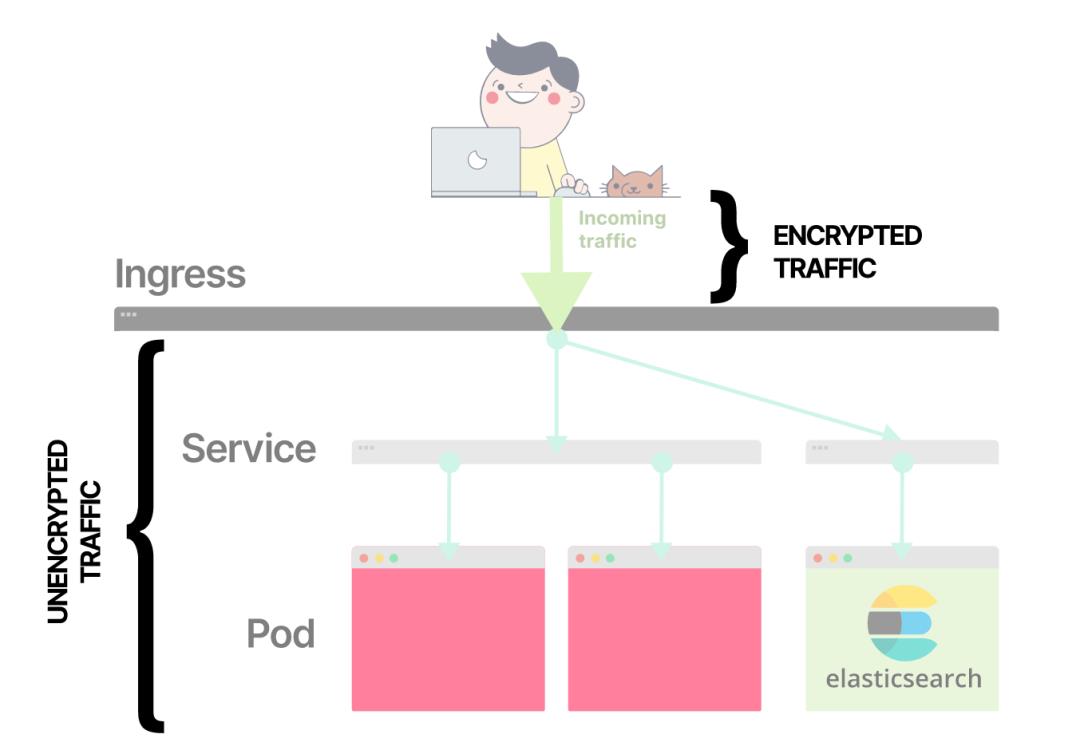
如果你在Ingress终止TLS,剩下的流量将不会加密。
一个能满足要求的解决方案是在pod上加一个nginx代理容器,通过TLS进行监听。从用户到Pod的一路流量都是加密的。
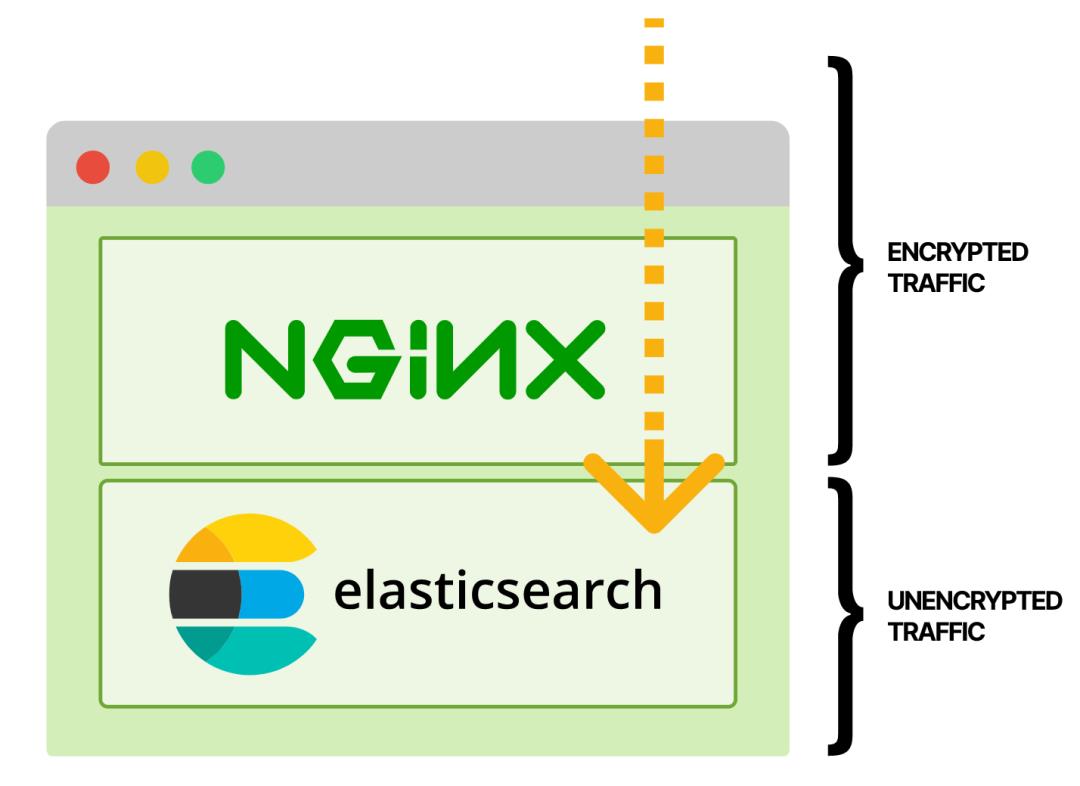
如果在pod中包含一个代理容器,你可以在Nginx pod中终止TLS。
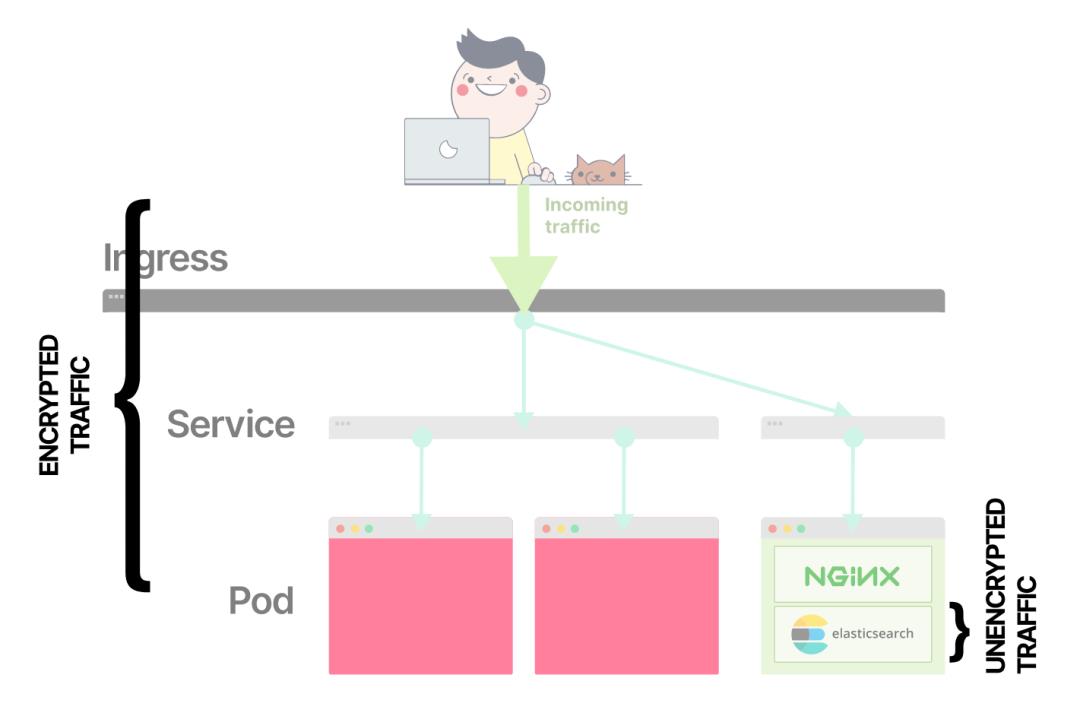
当你比较当前的设置时,你可以注意到,在Elasticsearch容器之前,流量一直是加密的。
以下是部署的情况:
apiVersion: apps/v1kind: Deploymentmetadata:name: elasticsearchspec:selector:matchLabels:app.kubernetes.io/name: elasticsearchtemplate:metadata:labels:app.kubernetes.io/name: elasticsearchspec:containers:- name: elasticsearchimage: elasticsearch:7.9.3env:- name: discovery.typevalue: single-node- name: network.hostvalue: 127.0.0.1- name: http.portvalue: '9201'- name: nginx-proxyimage: nginx:1.19.5volumeMounts:- name: nginx-configmountPath: /etc/nginx/conf.dreadOnly: true- name: certsmountPath: /certsreadOnly: trueports:- name: httpscontainerPort: 9200volumes:- name: nginx-configconfigMap:name: elasticsearch-nginx- name: certssecret:secretName: elasticsearch-tls---apiVersion: v1kind: ConfigMapmetadata:name: elasticsearch-nginxdata:elasticsearch.conf: |server {listen 9200 ssl;server_name elasticsearch;ssl_certificate /certs/tls.crt;ssl_certificate_key /certs/tls.key;location / {proxy_pass http://localhost:9201;}}
让我们来解读一下:
Elasticsearch在端口9201上监听localhost,而不是默认的0.0.0.0:9200(那是network.host和http.port环境变量的作用)。
新的nginx-proxy容器通过HTTPS在9200端口监听,并在9201端口代理请求到Elasticsearch。(elasticsearch-tls secret包含TLS证书和密钥,例如可以用cert-manager生成)。
所以来自pod外部的请求会通过HTTPS进入9200端口的Nginx,然后转发到9201端口的Elasticsearch。
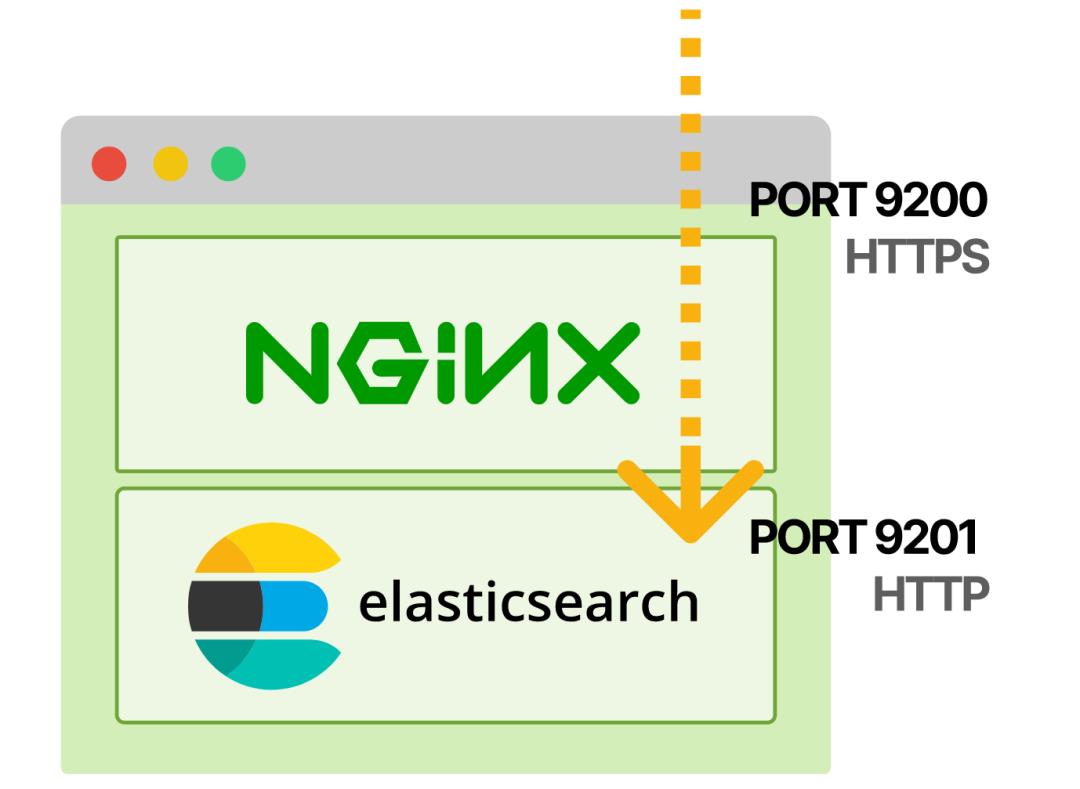
你可以通过在集群内发出HTTPS请求来确认它是否可以正常工作。
kubectl run -it --rm --image=curlimages/curl curl \-- curl -k https://elasticsearch:9200{"name" : "elasticsearch-5469857795-nddbn","cluster_name" : "docker-cluster","cluster_uuid" : "XPW9Z8XGTxa7snoUYzeqgg","version" : {"number" : "7.9.3","build_flavor" : "default","build_type" : "docker","build_hash" : "c4138e51121ef06a6404866cddc601906fe5c868","build_date" : "2020-10-16T10:36:16.141335Z","build_snapshot" : false,"lucene_version" : "8.6.2","minimum_wire_compatibility_version" : "6.8.0","minimum_index_compatibility_version" : "6.0.0-beta1"},"tagline" : "You Know, for Search"}
对于自签名的TLS证书,-k版本是必要的。在生产环境中,你需要使用可信的证书。
快速查看日志,显示该请求通过了Nginx代理:
kubectl logs elasticsearch-5469857795-nddbn nginx-proxy | grep curl10.88.4.127 - - [26/Nov/2020:02:37:07 +0000] "GET / HTTP/1.1" 200 559 "-" "curl/7.73.0-DEV" "-"
你也可以检查你是否无法通过未加密的连接连接到Elasticsearch:
kubectl run -it --rm --image=curlimages/curl curl \-- curl http://elasticsearch:9200<html><head><title>400 The plain HTTP request was sent to HTTPS port</title></head><body><center><h1>400 Bad Request</h1></center><center>The plain HTTP request was sent to HTTPS port</center><hr><center>nginx/1.19.5</center></body></html>
你已经强制执行了TLS,而无需接触Elasticsearch代码或容器镜像。
代理容器是一种常见的模式
在pod中添加代理容器的做法很常见,以至于它有一个名字:Ambassador模式。
添加基本的TLS支持只是一个开始。这里有一些其他的事情你可以用Ambassador模式来做:
如果你想让集群中的所有流量都用TLS证书加密,你可能会在集群中的每个pod中安装一个nginx(或其他)代理。你甚至可以更进一步,使用相互TLS来确保所有的请求都是经过认证以及加密的。(这是Istio和Linkerd等服务网格使用的主要方法)。
你可以使用代理来确保集中的OAuth授权通过验证jwts来认证所有请求。例如,gcp-iap-auth,它可以验证请求是否被GCP Identity-Aware Proxy认证。
你可以通过安全隧道连接到外部数据库。这对于那些没有内置TLS支持的数据库来说尤其方便(比如旧版本的Redis)。
我们先来了解Kubernetes上pod和容器之间的区别,以便更好地了解其底层是如何工作的。
一个传统的容器(例如由docker run启动的容器)提供了几种形式的隔离:
资源隔离(如,内存限制)
进程隔离
Filesystem和挂载隔离
网络隔离
Docker还有其他一些设置,但这些是最主要的。
底层使用的工具是Linux命名空间和控制组(cgroups)。
控制组是一种用来限制资源的便捷方法,比如一个特定进程可以使用的CPU或内存。例如,你可以说你的进程应该只使用2GB的内存和4个CPU核心中的一个。
命名空间则负责隔离进程以及限制该进程能看到的东西。例如,进程只能看到与它直接相关的网络数据包,它无法看到流经网络适配器的所有网络数据包。或者你可以隔离filesystem,让进程相信它可以访问所有的filesystem。
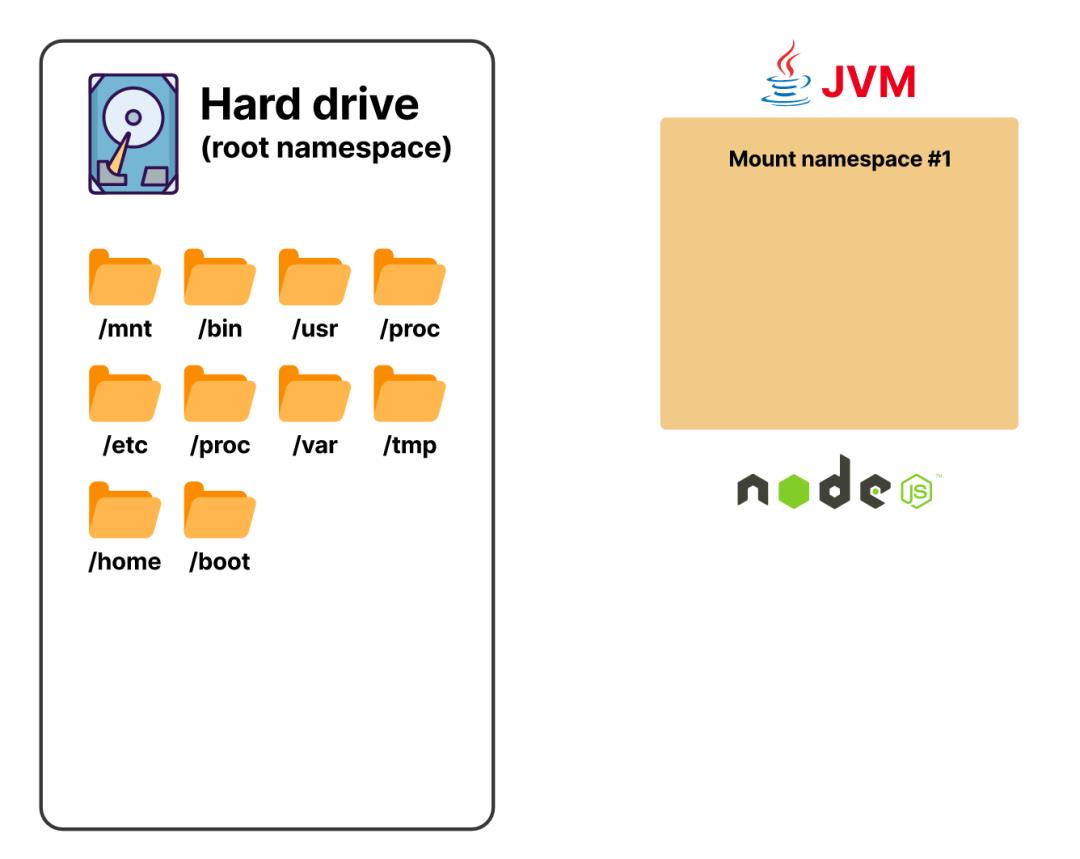
从内核5.6版本开始,有八种命名空间,挂载命名空间是其中之一
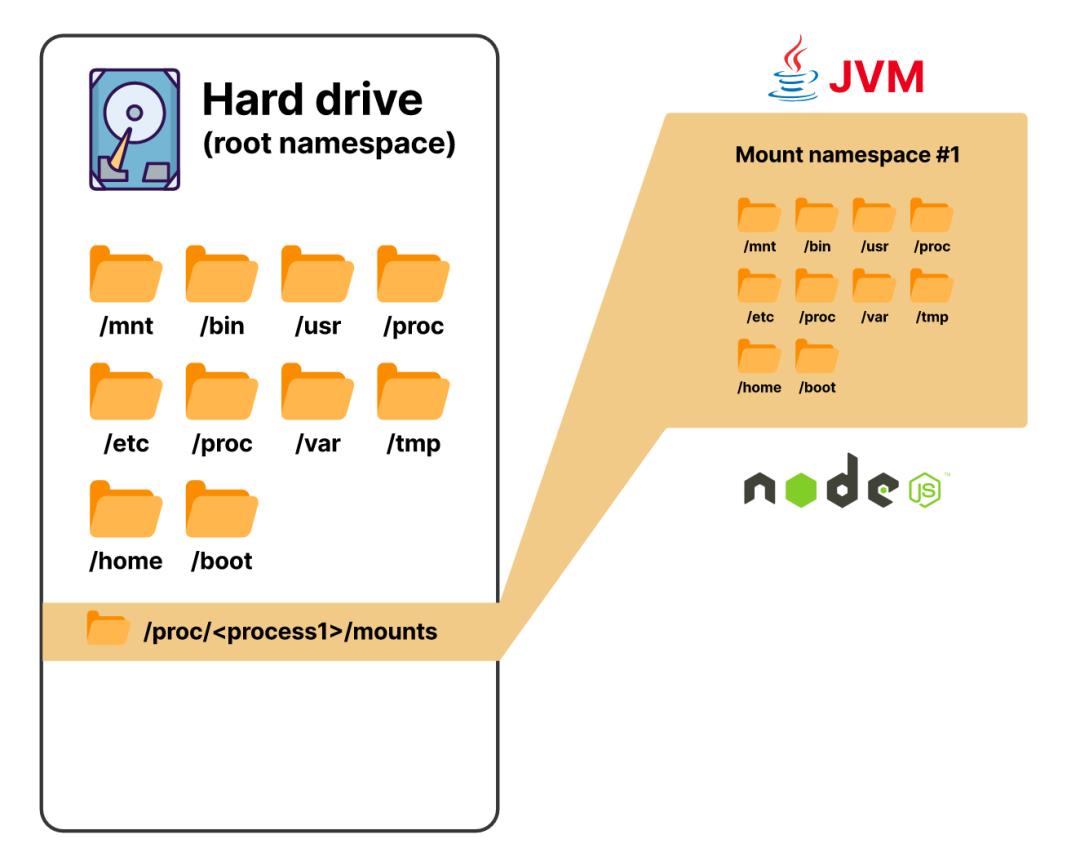
有了挂载命名空间,你可以让进程认为它可以访问主机上的所有目录,而事实上它并没有
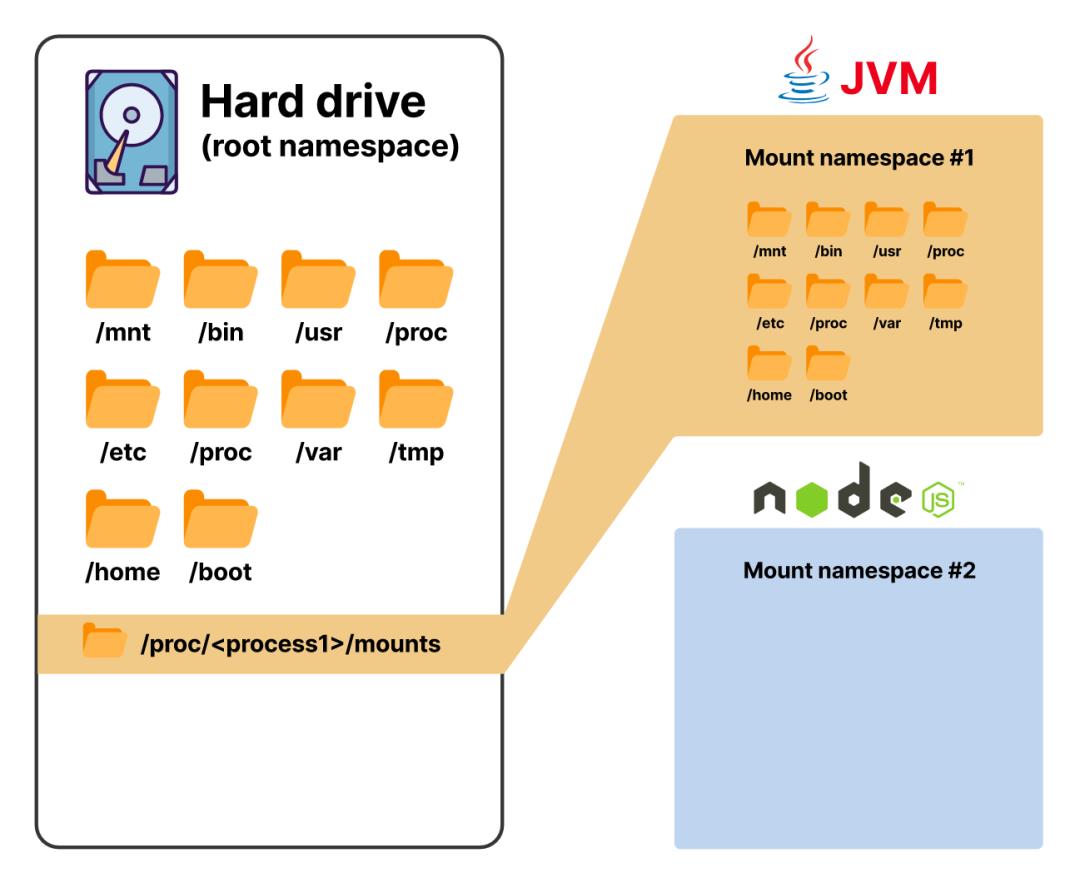
挂载命名空间被设计为隔离资源——在本例中是filesystem。
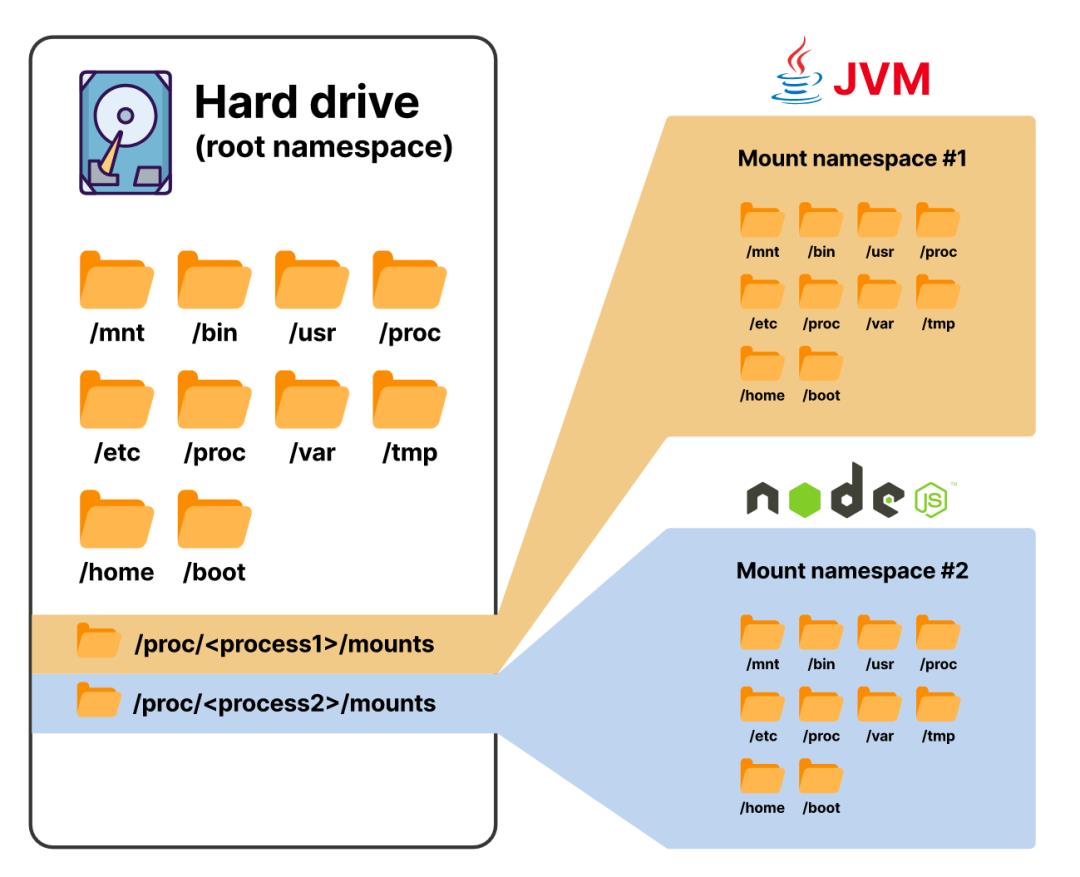
每个进程都可以看到同一个filesystem,同时还可以与其他进程隔离
如果你需要复习一下cgroups和namespaces,这里有一篇很好的博客文章,深入探讨了一些技术细节:
https://jvns.ca/blog/2016/10/10/what-even-is-a-container/
在Kubernetes上,容器提供了所有形式的隔离,除了网络隔离。网络隔离发生在pod层面。换句话说,一个pod中的每个容器都会有自己的filesystem、进程表等,但它们都会共享同一个网络命名空间。
让我们来看看一个简单pod容器,以更好地了解它是如何工作的。
apiVersion: v1kind: Podmetadata:name: podtestspec:containers:- name: c1image: busyboxcommand: ['sleep', '5000']volumeMounts:- name: sharedmountPath: /shared- name: c2image: busyboxcommand: ['sleep', '5000']volumeMounts:- name: sharedmountPath: /sharedvolumes:- name: sharedemptyDir: {}
我们将上面的代码段拆解一下:
有两个容器,这两个容器都会沉睡一段时间。
有一个emptyDir卷,它本质上是一个临时的本地卷,在pod的生命周期内持续存在。
emptyDir卷安装在每个pod中的/shared目录下。
你可以使用kubectl exec看到卷被挂载在第一个容器上:
kubectl exec -it podtest --container c1 -- sh该命令将终端会话连接到podtest pod中的容器c1。
kubectl exec的--container选项通常缩写为-c。
mount | grep shared/dev/vda1 on /shared type ext4 (rw,relatime)
如你所见,一个卷挂载在/shared上——这就是我们之前创建的shared卷。现在我们来创建一些文件:
echo "foo" > /tmp/fooecho "bar" > /shared/bar
我们从第二个容器中检查相同的文件。首先连接到它:
kubectl exec -it podtest --container c2 -- shcat /shared/barbarcat /tmp/foocat: can't open '/tmp/foo': No such file or directory
如你所见,在shared目录中创建的文件在两个容器上都是可用的,但/tmp中的文件却不可用。这是因为除了卷之外,容器的filesysytem之间是完全隔离的。
现在我们来看看网络和进程隔离。一个很好的方法是使用命令ip link来查看网络是如何设置的,它可以显示Linux系统的网络设备。让我们在第一个容器中执行这个命令:
kubectl exec -it podtest -c c1 -- ip link1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00178: eth0@if179: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueuelink/ether 46:4c:58:6c:da:37 brd ff:ff:ff:ff:ff:ff
在另一个容器中执行同样的命令:
kubectl exec -it podtest -c c2 -- ip link1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00178: eth0@if179: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueuelink/ether 46:4c:58:6c:da:37 brd ff:ff:ff:ff:ff:ff
你可以看到两个容器都有:
相同的设备eth0
现在让我们来看看网络共享的操作吧!我们先连接到第一个容器:
ubectl exec -it podtest -c c1 -- sh借助nc启动一个简单的网络监听器:
nc -lk -p 5000 127.0.0.1 -e 'date'该命令在端口5000的localhost上启动一个监听器,并向任何连接的TCP客户端输入date命令。
那么第二个容器可以连接到它吗?
使用以下命令在第二个容器中打开终端:
kubectl exec -it podtest -c c2 -- sh现在你可以验证第二个容器可以连接到该网络监听器,但不能看到nc进程:
telnet localhost 5000Connected to localhostSun Nov 29 00:57:37 UTC 2020Connection closed by foreign hostps auxPID USER TIME COMMAND1 root 0:00 sleep 500073 root 0:00 sh81 root 0:00 ps aux
通过telnet连接,可以看到date的输出,证明nc监听器在工作,但是ps aux(显示容器上的所有进程)根本没有显示nc。这是因为pod内的容器有进程隔离,但没有网络隔离。这就解释了Ambassador模式的工作原理:
由于所有的容器都共享同一个网络命名空间,所以一个容器可以监听所有的连接——甚至是外部的连接。
其余的容器只接受来自localhost的连接——拒绝任何外部连接。
接收外部流量的容器就是Ambassador,因此该模式也被称为Ambassador模式。
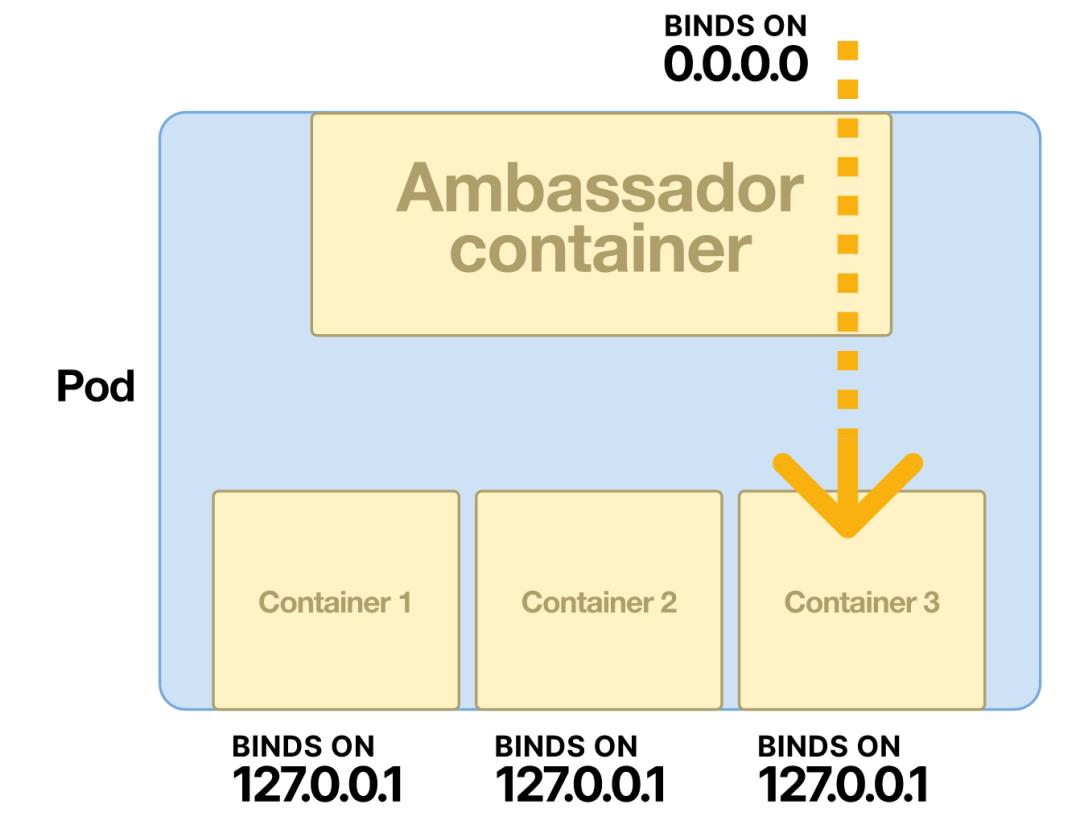
不过有一点很关键,要记住:因为网络命名空间是共享的,所以一个pod中的多个容器不能在同一个端口监听。
让我们来看看多容器pod的一些其他用例。
假设你已经标准化地使用Prometheus来监控Kubernetes集群中的所有服务,但你使用的一些应用程序并没有原生导出Prometheus指标(如,Elasticsearch)。
你能在不改变你的应用程序代码的情况下,将Prometheus指标添加到你的pod中吗?事实上,你可以,使用Adapter模式。
对于Elasticsearch的例子,让我们在pod中添加一个 "exporter"容器,以Prometheus格式暴露各种Elasticsearch指标。
这并不困难,因为有一个Elasticsearch的开源exporter(你还需要将相关端口添加到服务中):
apiVersion: apps/v1kind: Deploymentmetadata:name: elasticsearchspec:selector:matchLabels:app.kubernetes.io/name: elasticsearchtemplate:metadata:labels:app.kubernetes.io/name: elasticsearchspec:containers:- name: elasticsearchimage: elasticsearch:7.9.3env:- name: discovery.typevalue: single-nodeports:- name: httpcontainerPort: 9200- name: prometheus-exporterimage: justwatch/elasticsearch_exporter:1.1.0args:- '--es.uri=http://localhost:9200'ports:- name: http-prometheuscontainerPort: 9114---apiVersion: v1kind: Servicemetadata:name: elasticsearchspec:selector:app.kubernetes.io/name: elasticsearchports:- name: httpport: 9200targetPort: http- name: http-prometheusport: 9114targetPort: http-prometheus
一旦应用了这个功能,你就可以在9114端口找到暴露的指标:
kubectl run -it --rm --image=curlimages/curl curl \-- curl -s elasticsearch:9114/metrics | head# HELP elasticsearch_breakers_estimated_size_bytes Estimated size in bytes of breaker# TYPE elasticsearch_breakers_estimated_size_bytes gaugeelasticsearch_breakers_estimated_size_bytes{breaker="accounting",name="elasticsearch-ss86j"} 0elasticsearch_breakers_estimated_size_bytes{breaker="fielddata",name="elasticsearch-ss86j"} 0elasticsearch_breakers_estimated_size_bytes{breaker="in_flight_requests",name="elasticsearch-ss86j"} 0elasticsearch_breakers_estimated_size_bytes{breaker="model_inference",name="elasticsearch-ss86j"} 0elasticsearch_breakers_estimated_size_bytes{breaker="parent",name="elasticsearch-ss86j"} 1.61106136e+08elasticsearch_breakers_estimated_size_bytes{breaker="request",name="elasticsearch-ss86j"} 16440# HELP elasticsearch_breakers_limit_size_bytes Limit size in bytes for breaker# TYPE elasticsearch_breakers_limit_size_bytes gauge
再次,你已经能够改变你的应用程序的行为,而无需实际改变你的代码或容器镜像。你已经暴露了标准化的Prometheus指标,这些指标可以被集群范围内的工具(如Prometheus Operator使用),从而实现了应用程序和底层基础设施之间的良好分离。
Tailing logs
接下来,我们来看看Sidecar模式,在这一模式下你可以将容器添加到Pod,该pod可以以某些方式增强应用程序。
Sidecar模式十分通用,可以应用到不同类型的用例中。我们接下来探索以下sidecar的经典用例:log tailing sidecar。
在容器化环境中,最佳实践是始终将日志记录到标准输出,这样可以集中收集和汇总日志。但许多旧的应用程序被设计成日志输出到文件,而改变这一方式并非易事。而添加一个log tailing sidecar意味着你不需要更改原有的方式也可以实现日志的集中收集和汇总。
我们继续以Elasticsearch为例,这可能会有点别扭,因为Elasticsearch容器默认是将日志记录到标准输出的(而且让它记录到文件也不是件容易的事)。
以下是部署情况:
apiVersion: apps/v1kind: Deploymentmetadata:name: elasticsearchlabels:app.kubernetes.io/name: elasticsearchspec:selector:matchLabels:app.kubernetes.io/name: elasticsearchtemplate:metadata:labels:app.kubernetes.io/name: elasticsearchspec:containers:- name: elasticsearchimage: elasticsearch:7.9.3env:- name: discovery.typevalue: single-node- name: path.logsvalue: /var/log/elasticsearchvolumeMounts:- name: logsmountPath: /var/log/elasticsearch- name: logging-configmountPath: /usr/share/elasticsearch/config/log4j2.propertiessubPath: log4j2.propertiesreadOnly: trueports:- name: httpcontainerPort: 9200- name: logsimage: alpine:3.12command:- tail- -f- /logs/docker-cluster_server.jsonvolumeMounts:- name: logsmountPath: /logsreadOnly: truevolumes:- name: logging-configconfigMap:name: elasticsearch-logging- name: logsemptyDir: {}
日志配置文件是一个单独的ConfigMap,因为它太长了所以这里没有包括它。
两个容器共享相同的volume,名为logs。Elasticsearch容器将日志写入该卷,而日志容器只是从相应的文件中读取并输出到标准输出。你可以用kubectl logs指定相应的容器来检索日志流:
kubectl logs elasticsearch-6f88d74475-jxdhl logs | head{"type": "server","timestamp": "2020-11-29T23:01:42,849Z","level": "INFO","component": "o.e.n.Node","cluster.name": "docker-cluster","node.name": "elasticsearch-6f88d74475-jxdhl","message": "version[7.9.3], pid[7], OS[Linux/5.4.0-52-generic/amd64], JVM"}{"type": "server","timestamp": "2020-11-29T23:01:42,855Z","level": "INFO","component": "o.e.n.Node","cluster.name": "docker-cluster","node.name": "elasticsearch-6f88d74475-jxdhl","message": "JVM home [/usr/share/elasticsearch/jdk]"}{"type": "server","timestamp": "2020-11-29T23:01:42,856Z","level": "INFO","component": "o.e.n.Node","cluster.name": "docker-cluster","node.name": "elasticsearch-6f88d74475-jxdhl","message": "JVM arguments […]"}
使用sidecar的好处是,流式传输到标准输出并不是唯一的选择。
如果你需要切换到一个自定义的日志聚合服务,你可以只改变sidecar容器,而无需改变你的应用程序中任何其他东西。
其他sidecar用例
Sidecar有许多用例,日志容器只是其中一个比较简单的用例。
以下是你在其他方面可能用到的一些其他用例:
实时重新加载ConfigMaps,而不需要重新启动pod
将 Hashicorp Vault 中的secret注入到应用程序中
将本地 Redis 实例添加到你的应用程序中,以实现低延迟的内存缓存
到目前为止,本篇文章所介绍的所有多容器pod的例子都涉及到多个容器同时运行。Kubernetes还提供了运行Init Containers的能力,Init Containers是在 "常规 "容器启动之前运行完成的容器。
这允许你在你的pod正式启动之前运行一个初始化脚本。为什么你希望你的准备工作在一个单独的容器中运行,而不是在你的容器的entrypoint脚本中添加一些初始化?
让我们来看看Elasticsearch的一个实际例子。Elasticsearch文档推荐在生产就绪部署中设置vm.max_map_count的sysctl设置。这在容器化环境中是有问题的,因为没有容器级的sysctl隔离,任何更改都必须发生在节点级。
在不能自定义Kubernetes节点的情况下,如何处理这个问题?
一种方法是在特权容器中运行Elasticsearch,这将使Elasticsearch能够改变其主机节点上的系统设置,并改变entrypoint脚本以添加sysctls。但从安全角度来看,这将是非常危险的!如果Elasticsearch服务被入侵,攻击者将拥有对其主机节点的root权限。你可以使用init container来一定程度上降低这个风险:
apiVersion: apps/v1kind: Deploymentmetadata:name: elasticsearchspec:selector:matchLabels:app.kubernetes.io/name: elasticsearchtemplate:metadata:labels:app.kubernetes.io/name: elasticsearchspec:initContainers:- name: update-sysctlimage: alpine:3.12command: ['/bin/sh']args:- -c- |sysctl -w vm.max_map_count=262144securityContext:privileged: truecontainers:- name: elasticsearchimage: elasticsearch:7.9.3env:- name: discovery.typevalue: single-nodeports:- name: httpcontainerPort: 9200
pod在特权init container中设置了sysctl,之后Elasticsearch容器按预期启动。
你仍然在使用一个特权容器,这并不是理想状态,但至少它持续时间很短,所以攻击面要低得多。
这是Elastic Cloud Operator推荐的方法:
https://www.elastic.co/guide/en/cloud-on-k8s/current/k8s-virtual-memory.html
使用特权init container为运行pod的节点做准备是一种相当常见的模式。例如,Istio使用init container来设置每次pod运行时的iptables规则。
使用init container的另一个原因是以某种方式准备 pod 的filesystem。一个常见的用例是secrets管理。
其他的init container用例
如果你使用类似HashicCorp Vault这样的工具来管理secrets,而不是Kubernetes secrets,你可以在一个init container中检索secrets,并将它们持久化到一个共享的emptyDir卷。
如下所示:
apiVersion: apps/v1kind: Deploymentmetadata:name: myapplabels:app.kubernetes.io/name: myappspec:selector:matchLabels:app.kubernetes.io/name: myapptemplate:metadata:labels:app.kubernetes.io/name: myappspec:initContainers:- name: get-secretimage: vaultvolumeMounts:- name: secretsmountPath: /secretscommand: ['/bin/sh']args:- -c- |vault read secret/my-secret > /secrets/my-secretcontainers:- name: myappimage: myappvolumeMounts:- name: secretsmountPath: /secretsvolumes:- name: secretsemptyDir: {}
现在secret/my-secret secret将在myapp容器的filesystem中可用。
这就是Vault Agent Sidecar Injector等系统工作的基本思路。然而,它们在实践中相当复杂(结合mutating webhooks、init container和sidecars来隐藏大部分的复杂性)。
此外,还有一些其他你可能想要使用init container的原因:
你希望数据库迁移脚本在你的应用程序之前运行(这通常可以在一个entrypoint脚本中完成,但有时使用专用容器更容易做到这一点)。
你想从S3或GCS中检索一个你的应用所依赖的大文件(为此使用一个init container有助于避免应用容器的臃肿)。
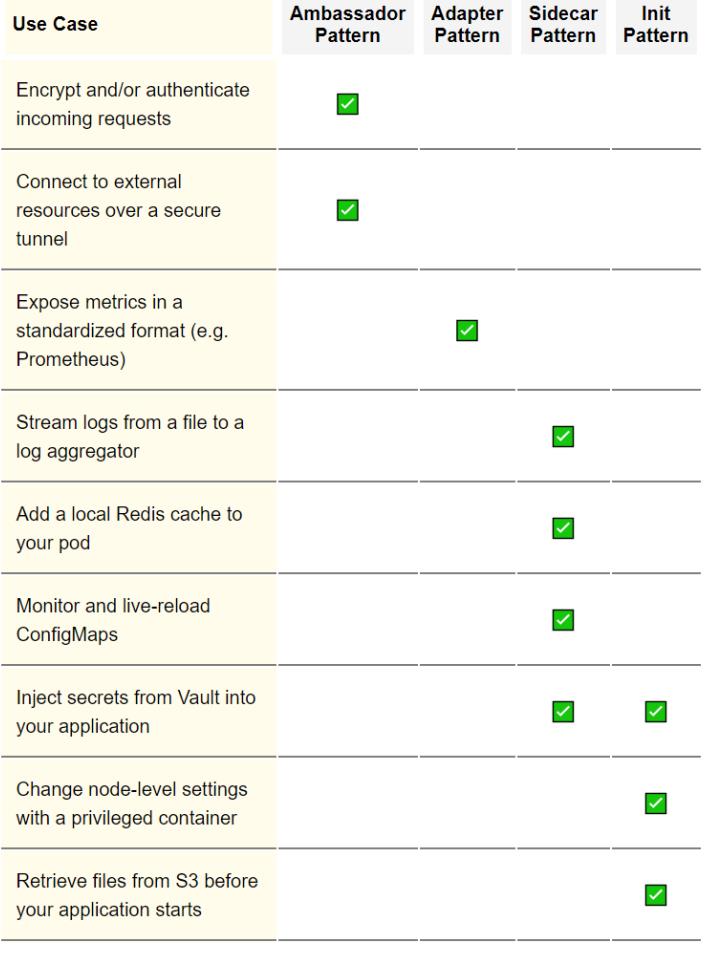
这篇文章涵盖了相当多的内容,所以这里有一个表格,列出了一些多容器模式,以及你什么时候可能要使用它们:
如果你想深入研究这个问题,请务必阅读官方文档和原始容器设计模式文件:
https://kubernetes.io/docs/concepts/workloads/pods/
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45406.pdf
文章来源:RancherLabs /
原文链接:
https://learnk8s.io/sidecar-containers-patterns
以上是关于借助多容器Pod,轻松扩展K8S中的应用的主要内容,如果未能解决你的问题,请参考以下文章