深入浅出 Linux 惊群:现象原因和解决方案
Posted CSDN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入浅出 Linux 惊群:现象原因和解决方案相关的知识,希望对你有一定的参考价值。
2020 年转眼间白驹过隙般飞奔而去,在岁末年初的当口,笔者在回顾这一年程序员世界的大事件后,突然发觉如何避免程序员面向监狱编程是个特别值得一谈的话题。
"惊群"简单地来讲,就是多个进程(线程)阻塞睡眠在某个系统调用上,在等待某个 fd(socket)的事件的到来。当这个 fd(socket)的事件发生的时候,这些睡眠的进程(线程)就会被同时唤醒,多个进程(线程)从阻塞的系统调用上返回,这就是"惊群"现象。"惊群"被人诟病的是效率低下,大量的 CPU 时间浪费在被唤醒发现无事可做,然后又继续睡眠的反复切换上。本文谈谈 linux socket 中的一些"惊群"现象、原因以及解决方案。

Accept"惊群"现象
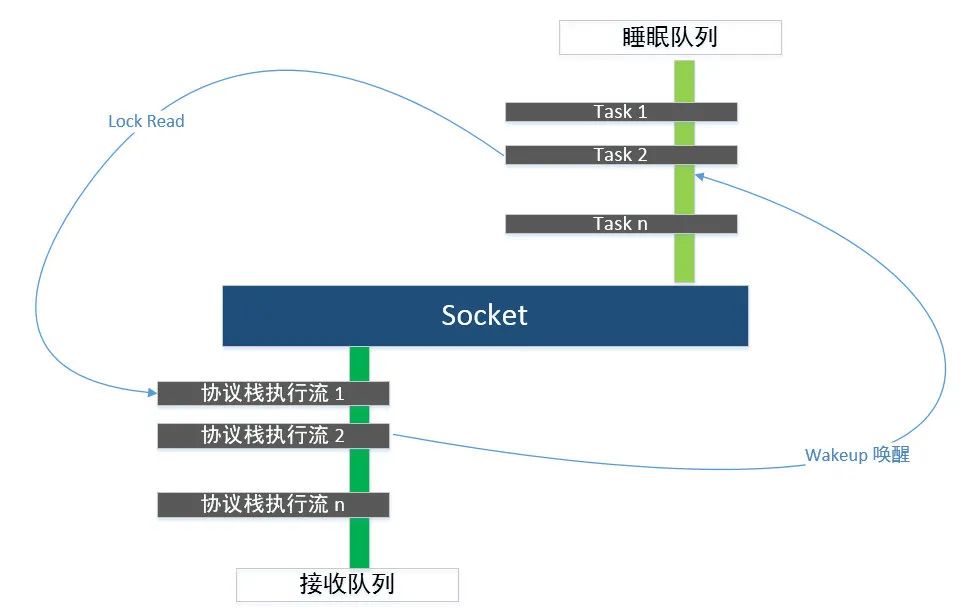
数据包到来后的事件通知
收到事件通知的Task执行流,响应事件并从队列中取出数据包
网卡通知数据包到来,中断协议栈收包;
协议栈将数据包填充 socket 的接收队列,通知应用程序有数据可读,这里仅讨论数据到达协议栈之后的事情。
协议栈将数据包放入socket的接收缓冲区队列,并通知持有该socket的应用程序;
持有该socket的应用程序响应通知事件,将数据包从socket的接收缓冲区队列中取出
/** The core wakeup function. Non-exclusive wakeups (nr_exclusive == 0) just* wake everything up. If it's an exclusive wakeup (nr_exclusive == small +ve* number) then we wake all the non-exclusive tasks and one exclusive task.** There are circumstances in which we can try to wake a task which has already* started to run but is not in state TASK_RUNNING. try_to_wake_up() returns* zero in this (rare) case, and we handle it by continuing to scan the queue.*/static void __wake_up_common(wait_queue_head_t *q, unsigned int mode,int nr_exclusive, int wake_flags, void *key){wait_queue_t *curr, *next;list_for_each_entry_safe(curr, next, &q->task_list, task_list) {unsigned flags = curr->flags;if (curr->func(curr, mode, wake_flags, key) &&(flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)break;}}

select/poll/Epoll "惊群"现象
2.1 Nginx 的 epoll"惊群"避免
进入ngx_trylock_accept_mutex,加锁抢夺accept权限(ngx_shmtx_trylock(&ngx_accept_mutex)),加锁成功,则调用ngx_enable_accept_events(cycle) 来将一个或多个listen fd加入epoll监听READ事件(设置事件的回调函数ngx_event_accept),并设置ngx_accept_mutex_held = 1;标识自己持有锁。
如果ngx_shmtx_trylock(&ngx_accept_mutex)失败,则调用ngx_disable_accept_events(cycle, 0)来将listen fd从epoll中delete掉。
如果ngx_accept_mutex_held = 1(也就是抢到accept权),则设置延迟处理事件标志位flags |= NGX_POST_EVENTS; 如果ngx_accept_mutex_held = 0(没抢到accept权),则调整一下自己的epoll_wait超时,让自己下次能早点去抢夺accept权。
进入ngx_process_events(ngx_epoll_process_events),在ngx_epoll_process_events将调用epoll_wait等待相关事件到来或超时。
epoll_wait返回,循环遍历返回的事件,如果标志位flags被设置了NGX_POST_EVENTS,则将事件挂载到相应的队列中(Nginx有两个延迟处理队列,(1)ngx_posted_accept_events:listen fd返回的事件被挂载到的队列。(2)ngx_posted_events:其他socket fd返回的事件挂载到的队列),延迟处理事件,否则直接调用事件的回调函数。
ngx_epoll_process_events返回后,则开始处理ngx_posted_accept_events队列上的事件,于是进入的回调函数是ngx_event_accept,在ngx_event_accept中accept客户端的请求,进行一些初始化工作,将accept到的socket fd放入epoll中。
ngx_epoll_process_events处理完成后,如果本进程持有accept锁ngx_accept_mutex_held = 1,那么就将锁释放。
接着开始处理ngx_posted_events队列上的事件。
避免新请求不能及时得到处理的饿死现象
工作worker在抢夺到accept权限,加锁成功的时候,要将事件的处理delay到释放锁后在处理(为什么ngx_posted_accept_events队列上的事件处理不需要延迟呢? 因为ngx_posted_accept_events上的事件就是listen fd的可读事件,本来就是我抢到的accept权限,我还没accept就释放锁,这个时候被别人抢走了怎么办呢?)。否则,获得锁的工作worker由于在处理一个耗时事件,这个时候大量请求过来,其他工作worker空闲,然而没有处理权限在干着急。
避免总是某个worker进程抢到锁,大量请求被同一个进程抢到,而其他worker进程却很清闲。
Nginx有个简单的负载均衡,ngx_accept_disabled表示此时满负荷程度,没必要再处理新连接了,我们在nginx.conf曾经配置了每一个nginx worker进程能够处理的最大连接数,当达到最大数的7/8时,ngx_accept_disabled为正,说明本nginx worker进程非常繁忙,将不再去处理新连接。每次要进行抢夺accept权限的时候,如果ngx_accept_disabled大于0,则递减1,不进行抢夺逻辑。

Epoll"惊群"之 LT(水平触发模式)、ET(边沿触发模式)
LT 水平触发模式
只要仍然有未处理的事件,epoll就会通知你,调用epoll_wait就会立即返回。ET 边沿触发模式
只有事件列表发生变化了,epoll才会通知你。也就是,epoll_wait返回通知你去处理事件,如果没处理完,epoll不会再通知你了,调用epoll_wait会睡眠等待,直到下一个事件到来或者超时。
3.1 epoll 的核心机制
等待队列 waitqueue
队列头(wait_queue_head_t)往往是资源生产者
队列成员(wait_queue_t)往往是资源消费者
当头的资源ready后, 会逐个执行每个成员指定的回调函数,来通知它们资源已经ready了内核的poll机制
被Poll的fd, 必须在实现上支持内核的Poll技术,比如fd是某个字符设备,或者是个socket, 它必须实现file_operations中的poll操作, 给自己分配有一个等待队列头wait_queue_head_t,主动poll fd的某个进程task必须分配一个等待队列成员, 添加到fd的等待队列里面去, 并指定资源ready时的回调函数,用socket做例子, 它必须有实现一个poll操作, 这个Poll是发起轮询的代码必须主动调用的, 该函数中必须调用poll_wait(),poll_wait会将发起者作为等待队列成员加入到socket的等待队列中去,这样socket发生事件时可以通过队列头逐个通知所有关心它的进程。epollfd本身也是个fd, 所以它本身也可以被epoll
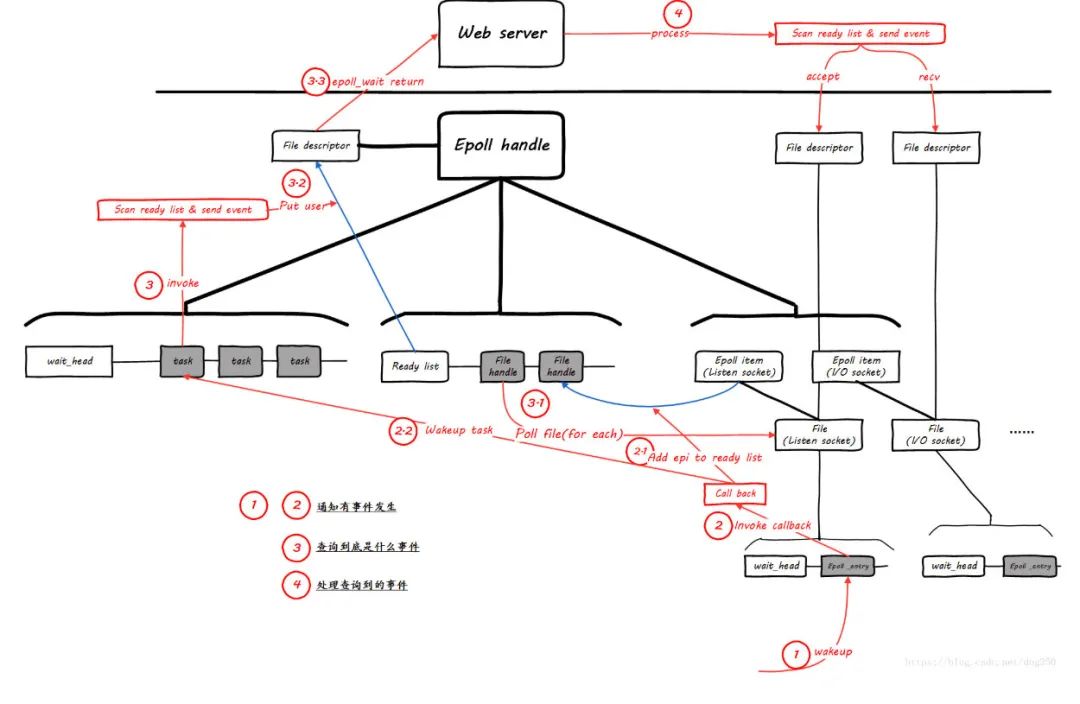
这个时候一个请求RQ_1上来,listen fd这个时候ready了,开始唤醒其睡眠队列上的epoll entry,并执行之前epoll注册的回调函数ep_poll_callback。
ep_poll_callback主要做两件事情,(1)发生的event事件是epoll entry关心的,则将epi挂载到epoll的就绪队列ready list并进入(2),否则结束。(2)如果当前wq不为空,则唤醒睡眠在epoll等待队列上睡眠的task(这里唤醒一个还是多个,是区分epoll的ET模式还是LT模式,下面在细讲)。
epoll_wait被唤醒继续前行,在ep_poll中调用ep_send_events将fd相关的event事件和数据copy到用户空间,这个时候就需要遍历epoll的ready list以便收集task需要监控的多个fd的event事件和数据上报给用户进程task,这个在ep_scan_ready_list中完成,这里会将ready list清空。
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events, int maxevents, long timeout){int res = 0, eavail, timed_out = 0;bool waiter = false;...eavail = ep_events_available(ep);//是否有fd就绪if (eavail)goto send_events;//有fd就绪,则直接跳过去上报事件给用户if (!waiter) {waiter = true;init_waitqueue_entry(&wait, current);//为当前进程task构造一个睡眠entryspin_lock_irq(&ep->wq.lock);//插入到epoll的wq后面,注意这里是排他插入的,就是带WQ_FLAG_EXCLUSIVE flag__add_wait_queue_exclusive(&ep->wq, &wait);spin_unlock_irq(&ep->wq.lock);}for (;;) {//将当前进程设置位睡眠, 但是可以被信号唤醒的状态, 注意这个设置是"将来时", 我们此刻还没睡set_current_state(TASK_INTERRUPTIBLE);// 检查是否真的要睡了if (fatal_signal_pending(current)) {res = -EINTR;break;}eavail = ep_events_available(ep);if (eavail)break;if (signal_pending(current)) {res = -EINTR;break;}// 检查是否真的要睡了 end//使得当前进程休眠指定的时间范围,if (!schedule_hrtimeout_range(to, slack, HRTIMER_MODE_ABS)) {timed_out = 1;break;}}__set_current_state(TASK_RUNNING);send_events:/** Try to transfer events to user space. In case we get 0 events and* there's still timeout left over, we go trying again in search of* more luck.*/// ep_send_events往用户态上报事件,即那些epoll_wait返回后能获取的事件if (!res && eavail &&!(res = ep_send_events(ep, events, maxevents)) && !timed_out)goto fetch_events;if (waiter) {spin_lock_irq(&ep->wq.lock);__remove_wait_queue(&ep->wq, &wait);spin_unlock_irq(&ep->wq.lock);}return res;}
static int ep_poll_callback(wait_queue_entry_t *wait, unsigned mode, int sync, void *key){int pwake = 0;struct epitem *epi = ep_item_from_wait(wait);struct eventpoll *ep = epi->ep;__poll_t pollflags = key_to_poll(key);unsigned long flags;int ewake = 0;....//判断是否有我们关心的eventif (pollflags && !(pollflags & epi->event.events))goto out_unlock;//将当前的epitem放入epoll的ready listif (!ep_is_linked(epi) &&list_add_tail_lockless(&epi->rdllink, &ep->rdllist)) {ep_pm_stay_awake_rcu(epi);}//如果有task睡眠在epoll的等待队列,唤醒它if (waitqueue_active(&ep->wq)) {....wake_up(&ep->wq);//}....}
static int ep_send_events(struct eventpoll *ep,struct epoll_event __user *events, int maxevents){struct ep_send_events_data esed;esed.maxevents = maxevents;esed.events = events;ep_scan_ready_list(ep, ep_send_events_proc, &esed, 0, false);return esed.res;}static __poll_t ep_scan_ready_list(struct eventpoll *ep,__poll_t (*sproc)(struct eventpoll *,struct list_head *, void *),void *priv, int depth, bool ep_locked){...// 所有的epitem都转移到了txlist上, 而rdllist被清空了list_splice_init(&ep->rdllist, &txlist);...//sproc 就是 ep_send_events_procres = (*sproc)(ep, &txlist, priv);...//没有处理完的epitem, 重新插入到ready listlist_splice(&txlist, &ep->rdllist);/* ready list不为空, 直接唤醒... */ // 保证(2)if (!list_empty(&ep->rdllist)) {if (waitqueue_active(&ep->wq))wake_up(&ep->wq);...}}static __poll_t ep_send_events_proc(struct eventpoll *ep, struct list_head *head,void *priv){...//遍历就绪fd列表list_for_each_entry_safe(epi, tmp, head, rdllink) {...//然后从链表里面移除当前就绪的epilist_del_init(&epi->rdllink);//读取当前epi的事件revents = ep_item_poll(epi, &pt, 1);if (!revents)continue;//将当前的事件和用户传入的数据都copy给用户空间if (__put_user(revents, &uevent->events) ||__put_user(epi->event.data, &uevent->data)) {//如果发生错误了, 则终止遍历过程,将当前epi重新返回就绪队列,剩下的也会在ep_scan_ready_list中重新放回就绪队列list_add(&epi->rdllink, head);ep_pm_stay_awake(epi);if (!esed->res)esed->res = -EFAULT;return 0;}}if (epi->event.events & EPOLLONESHOT)epi->event.events &= EP_PRIVATE_BITS;else if (!(epi->event.events & EPOLLET)) { // 保证(1)//如果是非ET模式(即LT模式),当前epi会被重新放到epoll的ready list。list_add_tail(&epi->rdllink, &ep->rdllist);ep_pm_stay_awake(epi);}}
遍历并清空epoll的ready list,遍历过程中,对于每个epi收集其返回的events,如果没收集到event,则continue去处理其他epi,否则将当前epi的事件和用户传入的数据都copy给用户空间,并判断,如果是在LT模式下,则将当前epi重新放回epoll的ready list
遍历epoll的ready list完成后,如果ready list不为空,则继续唤醒epoll睡眠队列wq上的其他task B。task B从epoll_wait醒来继续前行,重复上面的流程,继续唤醒wq上的其他task C,这样链式唤醒下去。
3.2 epoll_create& fork
3.2.1 先 epoll_create 后 fork
epoll在ET模式下不存在“惊群”现象,LT模式是epoll“惊群”的根源,并且LT模式下的“惊群”没办法避免。
LT的“惊群”是链式唤醒的,唤醒过程直到当前epi的事件被处理了,无法获得到新的事件才会终止唤醒过程。
例如有A、B、C、D...等多个进程task睡眠在epoll的睡眠队列上,并且都监控同一个listen fd的可读事件。一个请求上来,会首先唤醒A进程,A在epoll_wait的处理过程中会唤醒进程B,这样进程B在epoll_wait的处理过程中会唤醒C,这个时候A的epoll_wait处理完成返回,进程A调用accept读取了当前这个请求,进程C在自己的epoll_wait处理过程中,从epi中获取不到事件了,于是终止了整个链式唤醒过程。
多个进程的epoll fd由于指向同一个epoll内核对象,他们对epoll fd的相关epoll_ctl操作会相互影响。一不小心可能会出现一些比较诡异的行为。
想象这样一个场景(实际上应该不是这样用),有一个服务在1234,1235,1236这3个端口上提供服务,于是它epoll_create得到epoll fd后,fork出3个工作的子进程A、B、C,它们分别在这3个端口创建listen fd,然后加入到epoll中监听其可读事件。这个时候端口1234上来一个请求,A、B、C同时被唤醒,A在epoll_wait返回后,在进行accept前由于种种原因卡住了,没能及时accept。B、C在epoll_wait返回后去accept又不能accept到请求,这样B、C重新回到epoll_wait,这个时候又被唤醒,这样只要A没有去处理这个请求之前,B、C就一直被唤醒,然而B、C又无法处理该请求。
ET模式下,一个fd上的同事多个事件上来,只会唤醒一个睡眠在epoll上的task,如果该task没有处理完这些事件,在没有新的事件上来前,epoll不会在通知task去处理。
listen fd上一个请求C_1上来,该请求唤醒了A进程,A进程从epoll_wait返回准备去accept该请求来处理。
这个时候,第二个请求C_2上来,由于睡眠队列上是B、C,于是epoll唤醒B进程,B进程从epoll_wait返回准备去accept该请求来处理。
A进程在自己的accept循环中,首选accept得到C_1,接着A进程在第二个循环继续accept,继续得到C_2。
B进程在自己的accept循环中,调用accept,由于C_2已经被A拿走了,于是B进程accept返回EAGAIN错误,于是B进程退出accept流程重新睡眠在epoll_wait上。
A进程继续第三个循环,这个时候已经没有请求了, accept返回EAGAIN错误,于是A进程也退出accept处理流程,进入请求的处理流程。
3.2.2 先 fork 后 epoll_create
由于相对同一个listen fd而言, 多个进程之间的epoll是平等的,于是,listen fd上的一个请求上来,会唤醒所有睡眠在listen fd睡眠队列上的epoll,epoll又唤醒对应的进程task,从而唤醒所有的进程(这里不管listen fd是以LT还是ET模式加入到epoll)。
多个进程间的epoll是独立的,对epoll fd的相关epoll_ctl操作相互独立不影响。


允许多个socket bind/listen在相同的IP,相同的TCP/UDP端口
目的是同一个IP、PORT的请求在多个listen socket间负载均衡
安全上,监听相同IP、PORT的socket只能位于同一个用户下
Listen Socket数量发生变化的时候,会造成握手数据包的前一个数据包路由到A listen socket,而后一个握手数据包路由到B listen socket,这样会造成client的连接请求失败。
短时间内各个listen socket间的负载不均衡
惊不"惊群"其实是个问题
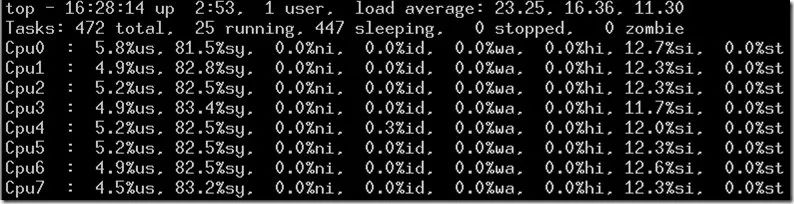
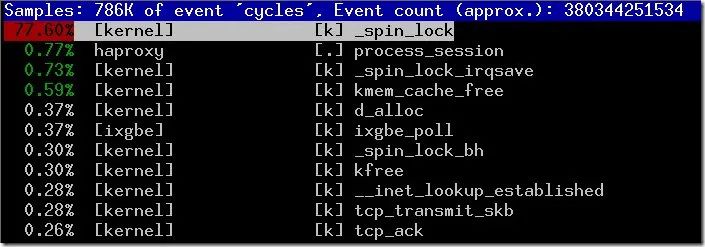
6.1 问题原因
协议栈内部之间的竞争
用户进程内部之间的竞争
协议栈和用户之间的竞争
6.2 问题的解决
6.2.1 多队列化 - SO_REUSEPORT
6.2.2 listen socket 无锁化- 旁门左道之 SYN Cookie
6.2.3 listen socket 无锁化- Linux 4.4 内核给出的 Lockless TCP listener
TCP 数据包 skb 到达本机,内核协议栈从全局 socket 表中查找 skb 的目的 socket(sk),如果是 SYN 包,当然查找到的是 listen_socket 了,于是,协议栈根据 skb 构造出一个新的 socket(tmp_sk),并将 tmp_sk 的 listener 标记为 listen_socket,并将 tmp_sk 的状态设置为 SYNRECV,同时将构造好的 tmp_sk 排入全局 socket 表中,并回复 syn_ack 给 client。
如果到达本机的 skb 是 syn_ack 的 ack 数据包,那么查找到的将是 tmp_sk,并且 tmp_sk 的 state 是 SYNRECV,于是内核知道该数据包 skb 是 syn_ack 的 ack 包了,于是在 new_sk 中拿出连接所属的 listen_socket,并且根据 tmp_sk 和到来的 skb 构造出 client_socket,然后将 tmp_sk 从全局 socket 表中删除(它的使命结束了),最后根据所属的 listen_socket 将 client_socket 排如 listen_socket 的 accept 队列中,整个握手过程结束。
7.参考文献
https://blog.csdn.net/dog250/article/details/50528426
https://zhuanlan.zhihu.com/p/51251700
https://blog.csdn.net/dog250/article/details/80837278


以上是关于深入浅出 Linux 惊群:现象原因和解决方案的主要内容,如果未能解决你的问题,请参考以下文章