什么是smo
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是smo相关的知识,希望对你有一定的参考价值。
smo(Search Media Optimization):搜索媒体优化,即用户搜索行为与呈现位置、优质内容的完美匹配,以服务代替信息,深度融入用户生活。
社会媒体优化,简称SMO,就是利用社会媒体对外发布网站的新闻,这不是对网站本身的某些元素进行优化,SMO要求网站的管理员加入到社会网络,并积极在网络中发布跟网站有关的各种内容。通过参与社会网络:优化所发布的网站信息,就能给网站带来访问量。除此之外,社会媒体优化还有很多其他好处。参与各种社会网络都是免费的,所需要的只是时间,不要据此认为SMO是一件很轻松的事情,这种优化需要投入大量的时间,如果想要使自己发布的内容能够引起他人注意,则必须熟悉这个社区,并积极参与其中,扩大自己的影响力。
社会化媒体优化(SMO)是通过社会化媒体、在线组织及社区网站获得公共传播的一整套方法。
不知道你问的是和什么相关的,和临床试验相关的话,员工主要是临床研究协调员CRC(Clinical Research Coordinator),那SMO就是以下定义:
“SMO是一个相当新地产业,为具有整和临床资源运作的专业管理组织,扮演试验机构、PI、申办企业、生技公司及CRO之间沟通协调的角色”
SMO似乎是由传统CRO细分出来的机构,作为专门处理临床资源管理的单位,更多地职责是不是在于“公关”,临床具体操作的事宜相对较少。
事实上,临床资源越来越被医药企业所看重,因为临床资源不仅仅关乎于一个新药的研发上市,一个运作良好,沟通有效的临床资源网可以起到很好的市场推广作用,甚至辐射到其他上市品种。“市场在临床中已经开展了”在日本一直是有CRO与SMO的区别的,在我国有些企业也有CRO与SMO业务重心偏向一边的特点。 参考技术B 社会媒体优化,社会化媒体营销 参考技术C 社会化媒体优化SMO是通过社会化媒体、在线组织及社区网站获得公共传播的一整套方法。SMO的方法包括添加RSS订阅、“Digg This”顶上去、博客写作及非合作形式的第三方社区功能(如:Flickr图片幻灯片、YouTube的视频分享)。社会化媒体优化是网络营销的一种最新形式。
SMO是史麦欧电脑的字母标识。史麦欧取英文SMILE的中文译音。微笑之意。 史麦欧电脑工作室创始人:郭俊楠 (原名:郭宇) 英文名:GALAXY。 2007年7月毕业于辽阳职业技术学院计算机科学系。 于2008年在沈阳市近海经济开发区创建了史麦欧电脑工作室。 工作室目前主要业务有电脑DIY组装销售,电脑维修维护,电脑培训等
机器学习之支持向量机:SMO算法
注:关于支持向量机系列文章是借鉴大神的神作,加以自己的理解写成的;若对原作者有损请告知,我会及时处理。转载请标明来源。
序:
我在支持向量机系列中主要讲支持向量机的公式推导,第一部分讲到推出拉格朗日对偶函数的对偶因子α;第二部分是SMO算法对于对偶因子的求解;第三部分是核函数的原理与应用,讲核函数的推理及常用的核函数有哪些;第四部分是支持向量机的应用,按照机器学习实战的代码详细解读。
机器学习之支持向量机(四):支持向量机的Python语言实现
1 SMO算法的概念
这里补充一点,后面的K () 函数是核函数,是把低维度的数据投射到高维度中,即把非线性转换成线性分类。知道k 是核函数就可以了,后面会再详细讲解k 函数。我们在上篇中得到关于对偶因子的式子,对其求 α 极大,现在添加符号转化成求极小,两者等价。

转化后的目标函数:
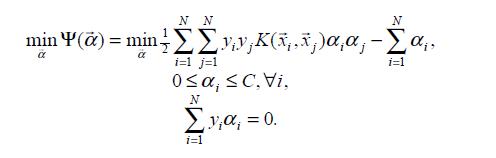
其中 约束条件中 C 是惩罚系数,由对非线性加上松弛因子得到的。
1998年,由Platt提出的序列最小最优化算法(SMO)可以高效的求解上述SVM问题,它把原始求解N个参数二次规划问题分解成很多个子二次规划问题分别求解,每个子问题只需要求解2个参数,方法类似于坐标上升,节省时间成本和降低了内存需求。每次启发式选择两个变量进行优化,不断循环,直到达到函数最优值。
2 SMO算法原理分析
我们的目标:求解对偶因子 α (α1, α2, ... , αN)
2.1 目标函数化成二元函数
SMO算法是通过一定的规定选择两个参数进行优化,并固定其余 N - 2 个参数,假如选取优化的参数是 α1, α2 ,固定α3, α4 , .., αN ,对目标函数进行化简成二元函数得:

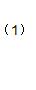
这里强调一下,式子中的 Kij 是核函数,知道意思就可以,不了解不太影响SMO算法的推导。
2.2 将二元函数化成一元函数
约束条件:
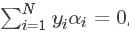 得到
得到 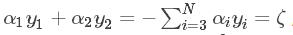 ,其中 ζ 是一个定值。
,其中 ζ 是一个定值。
让两边同时乘以y1 ,化简得到:
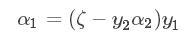

将(2)式带入到(1)中可得:
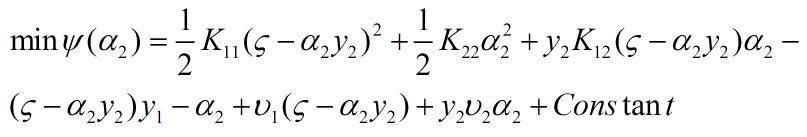
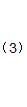
2.3 对一元函数求极值点
对(3)式求导并等于0,得:

假设求解得到的值,记为α1new 、α2new 优化前的解记为α1old 、α2old ,由约束条件知:
 得到:
得到: 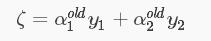
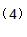
再设支持向量机超平面模型为:f (x) = ωTx + b , ω = Σ αi yi xi 即 f (xi) 为样本xi 的预测值,yi 表示 xi 的真实值,则令Ei 表示误差值。
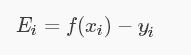
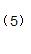
由于 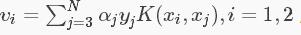 可得:
可得:
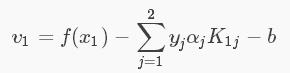
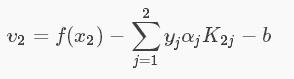
将上面的式子(4)(6)(7)带入求导公式中,此时解出的 α2new 没有考虑到约束条件,先记为 α2new unclipped ,得:
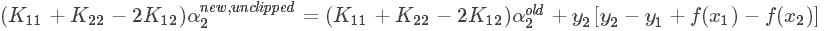
带入(5)式子,得:
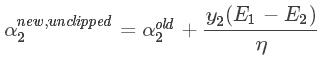

2.4 求得最终的对偶因子
以上求得的 α2new unclipped 没考虑约束条件:
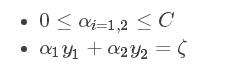
当![]() 和
和![]() 异号时,也就是一个为1,一个为-1时,他们可以表示成一条直线,斜率为1。
异号时,也就是一个为1,一个为-1时,他们可以表示成一条直线,斜率为1。
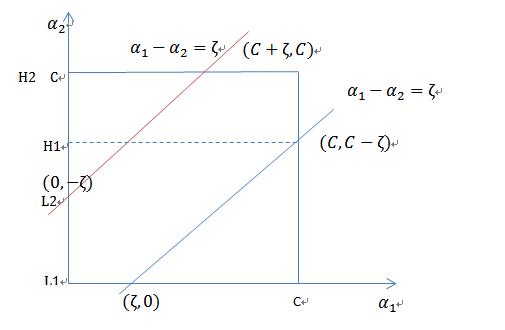
横轴是![]() ,纵轴是
,纵轴是![]() ,
,![]() 和
和![]() 既要在矩形方框内,也要在直线上,因此 L <= α2new <= H
既要在矩形方框内,也要在直线上,因此 L <= α2new <= H
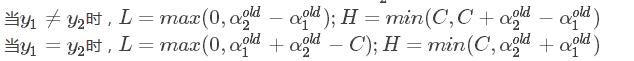
最终得到的值:
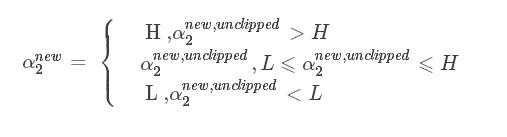
再根据 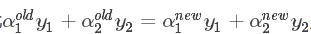 得到 α1new :
得到 α1new :
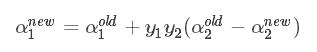
2.5 临界情况的求值
对于大部分情况 η = K11 + K22 - 2K12 > 0 ,求解方式如上;但 η <= 0 , α2new 取临界点L或H。

当η<0时,目标函数为凸函数,没有极小值,极值在定义域边界处取得。
当η=0时,目标函数为单调函数,同样在边界处取极值。
计算方法:

3 启发式选取变量
3.1 对第一个变量的选取
第一个变量的选择称为外循环,首先遍历整个样本集,选择违反KKT条件的αi作为第一个变量,接着依据相关规则选择第二个变量(见下面分析),对这两个变量采用上述方法进行优化。当遍历完整个样本集后,遍历非边界样本集(0<αi<C)中违反KKT的αi作为第一个变量,同样依据相关规则选择第二个变量,对此两个变量进行优化。当遍历完非边界样本集后,再次回到遍历整个样本集中寻找,即在整个样本集与非边界样本集上来回切换,寻找违反KKT条件的αi作为第一个变量。直到遍历整个样本集后,没有违反KKT条件αi,然后退出。

3.2 对第二个变量的选取
SMO称第二个变量的选择过程为内循环,假设在外循环中找个第一个变量记为α1,第二个变量的选择希望能使α2有较大的变化,由于α2是依赖于|E1−E2|,当E1为正时,那么选择最小的Ei作为E2,如果E1为负,选择最大Ei作为E2,通常为每个样本的Ei保存在一个列表中,选择最大的|E1−E2|来近似最大化步长。
4 阈值b的计算
每完成两个变量的优化后,都要对阈值 b 进行更新,因为关系到 f(x) 的计算,即关系到下次优化时计算。

这部分结束了,通过SMO算法解出的对偶因子的值,可以得到最优的超平面方程 f (x) = ωTx + b ,即对样本能够划分。以上大多借鉴了勿在浮沙筑高台的blog 文章,他写的已经很清晰,我只是在他的基础上
增加或删去不好理解的内容。下篇是对核函数和KKT条件的解释。
机器学习之支持向量机(四):支持向量机的Python语言实现
参考:
1 【机器学习详解】SMO算法剖析 http://blog.csdn.net/luoshixian099/article/details/51227754
2 支持向量机(五)SMO算法
以上是关于什么是smo的主要内容,如果未能解决你的问题,请参考以下文章