从0到1Flink的成长之路
Posted 熊老二-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从0到1Flink的成长之路相关的知识,希望对你有一定的参考价值。
基本函数
map
API
map:将函数作用在集合中的每一个元素上,并返回作用后的结果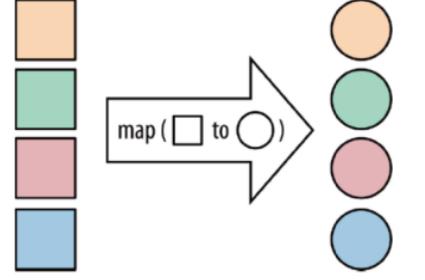
需求:
将click.log中的每一条日志转为javaBean对象
{
"browserType": "360浏览器",
"categoryID": 2,
"channelID": 3,
"city": "昌平",
"country": "china",
"entryTime": 1577890860000,
"leaveTime": 1577898060000,
"network": "移动",
"produceID": 11,
"province": "北京",
"source": "必应跳转",
"userID": 18
}
封装JSON数据实体类ClickLog:
package xx.xxxxx.flink.transformation;
import lombok.Data;
@Data
public class ClickLog {
//频道ID
private long channelId;
//产品的类别ID
private long categoryId;
//产品ID
private long produceId;
//用户的ID
private long userId;
//国家
private String country;
//省份
private String province;
//城市
private String city;
//网络方式
private String network;
//来源方式
private String source;
//浏览器类型
private String browserType;
//进入网站时间
private Long entryTime;
//离开网站时间
private Long leaveTime;
}代码实现:
// 1. 执行环境-env
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 数据源-source
DataSource<String> logDataSet = env.readTextFile("datas/click.log");
// 3. 数据转换-Transformation
// TODO: a. 使用map函数,将每条日志数据转换为实体类对象
MapOperator<String, ClickLog> clickLogDataSet = logDataSet.map(new MapFunction<String, ClickLog>() {
@Override
public ClickLog map(String log) throws Exception {
// 使用fastjson类库提供API解析
ClickLog clicklog = JSON.parseObject(log, ClickLog.class);
return clicklog;
}
});
// clickLogDataSet.printToErr();flatMap
API
flatMap:将集合中的每个元素变成一个或多个元素,并返回扁平化之后的结果
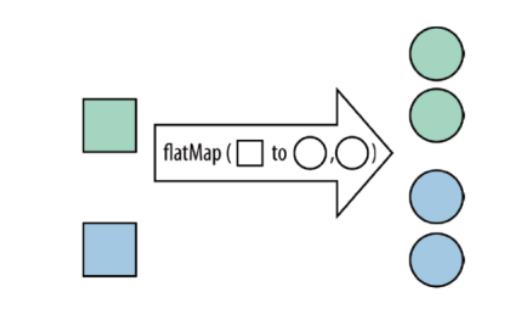
需求:
将每一条clickLog转换为如下三个纬度
(年-月-日-时,1)
(年-月-日,1)
(年-月,1)
代码实现:
// TODO: b. 使用flatMap函数,针对日期时间entryTime,获取不同形式时间日期
/*
entryTime=1577876460000 -> Long 类型
|
年月:yyyy-MM
年月日:yyyy-MM-dd
年月日时:yyyy-MM-dd:HH
*/
FlatMapOperator<ClickLog, String> timeDataSet = clickLogDataSet.flatMap(new FlatMapFunction<ClickLog, String>() {
@Override
public void flatMap(ClickLog clicklog, Collector<String> out) throws Exception {
Long entryTime = clicklog.getEntryTime();
// 使用工具类:lang3包DateFormatUtils
String month = DateFormatUtils.format(entryTime, "yyyy-MM");
out.collect(month);
String day = DateFormatUtils.format(entryTime, "yyyy-MM-dd");
out.collect(day);
String hour = DateFormatUtils.format(entryTime, "yyyy-MM-dd:HH");
out.collect(hour);
}
});
// timeDataSet.printToErr();filter
API
filter:按照指定的条件对集合中的元素进行过滤,过滤出返回true/符合条件的元素
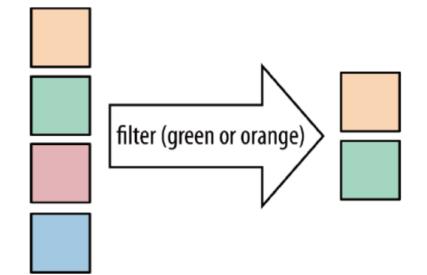
需求:
过滤出clickLog中使用谷歌浏览器访问的日志
代码实现:
// TODO: c. 使用filter函数,过滤出符合条件数据:谷歌浏览器
FilterOperator<ClickLog> filterDataSet = clickLogDataSet.filter(new FilterFunction<ClickLog>() {
@Override
public boolean filter(ClickLog clicklog) throws Exception {
return "谷歌浏览器".equals(clicklog.getBrowserType());
}
});
// filterDataSet.printToErr();
groupBy
API
groupBy:对集合中的元素按照指定的key进行分组
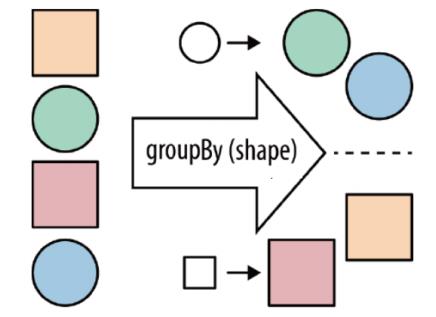
需求:
对ClickLog按照浏览器类型记为1并分组
代码实现:
// 将ClickLog 数据类型转换为二元组:Key -> BrowserType, Value -> 1
MapOperator<ClickLog, Tuple2<String, Integer>> tupleDataSet = clickLogDataSet.map(
new MapFunction<ClickLog, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(ClickLog clicklog) throws Exception {
return Tuple2.of(clicklog.getBrowserType(), 1);
}
}
);
// TODO: d. 使用groupBy函数,针对二元组数据进行分组
UnsortedGrouping<Tuple2<String, Integer>> groupDataSet = tupleDataSet.groupBy(0);
sum
API
sum:按照指定的字段对集合中的元素进行求和
需求:
统计各个浏览器类型的访问量
代码实现:
// TODO: e. 使用sum函数,对组内数据进行求和
AggregateOperator<Tuple2<String, Integer>> sumDataSet = groupDataSet.sum(1);
/*
(qq浏览器,29)
(360浏览器,23)
(火狐,24)
(谷歌浏览器,24)
*/
// sumDataSet.printToErr();
min和minBy/max和maxBy
API
min只会求出最小的那个字段,其他的字段不管
minBy会求出最小的那个字段和对应的其他的字段
max和maxBy同理
需求:
求最少的访问量以及对应的浏览器类型
代码实现:
// TODO: f. 使用min函数,指定字段最小值, 只会求出最小的那个字段,其他的字段不管
AggregateOperator<Tuple2<String, Integer>> minDataSet = sumDataSet.min(1);
// minDataSet.printToErr(); // (qq浏览器,23)
// TODO: g. 使用minBy函数,minBy会求出最小的那个字段和对应的其他的字段
ReduceOperator<Tuple2<String, Integer>> minByDataSet = sumDataSet.minBy(1);
// minByDataSet.printToErr(); // (360浏览器,23)
aggregate
API
aggregate:按照指定的聚合函数和字段对集合中的元素进行聚合,如SUM,MIN,MAX
需求:
使用aggregate完成求sum和min
代码实现:
// TODO: h. 使用aggregate函数,对分组过数据进行聚合操作
AggregateOperator<Tuple2<String, Integer>> aggregateDataSet = groupDataSet.aggregate(Aggregations.SUM, 1);
// aggregateDataSet.printToErr();
reduce和reduceGroup
API
reduce:对集合中的元素进行聚合
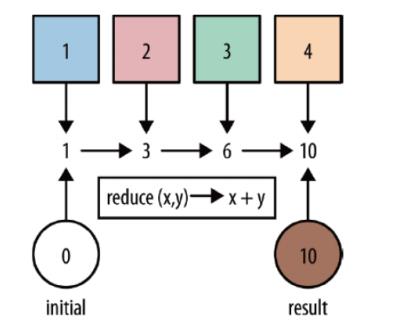
reduceGroup:对集合中的元素先进行预聚合再合并结果
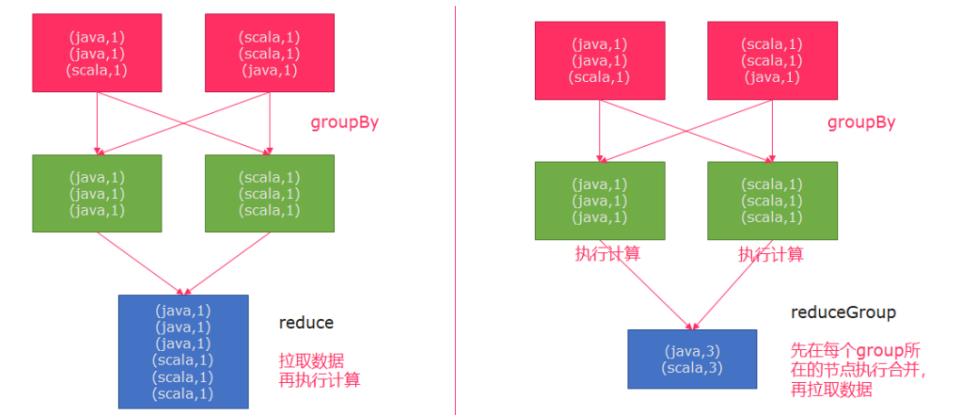
需求:
使用reduce和reduceGroup完成求sum
代码实现:
// TODO: i. 使用reduce函数,对分区过数据进行聚合操作
ReduceOperator<Tuple2<String, Integer>> reduceDataSet = groupDataSet.reduce(
new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1,
Tuple2<String, Integer> t2) throws Exception {
String key = t1.f0;
int sum = t1.f1 + t2.f1;
return Tuple2.of(key, sum);
}
});
// reduceDataSet.printToErr();
// TODO: j. 使用reduceGroup函数,对分区过数据进行聚合操作 , 推荐使用此函数
GroupReduceOperator<Tuple2<String, Integer>, Tuple2<String, Integer>> reduceGroupDataSet = groupDataSet.reduceGroup(
new GroupReduceFunction<Tuple2<String, Integer>, Tuple2<String, Integer>>() {
@Override
public void reduce(Iterable<Tuple2<String, Integer>> iter,
Collector<Tuple2<String, Integer>> out) throws Exception {
// 对组内数据进行聚合操作
// TODO: 定义临时变量
String key = null ;
Integer tmp = 0 ;
for (Tuple2<String, Integer> item: iter){
key = item.f0 ;
tmp += item.f1 ;
}
// 输出
out.collect(Tuple2.of(key, tmp));
}
});
// reduceGroupDataSet.printToErr();union
API
union:将两个集合进行合并但不会去重
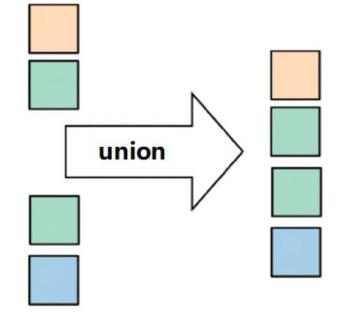
需求:
读取click.log和click2.log并使用union合并结果
代码实现:
// TODO: k. 使用union函数,将2个DataSet数据集进行合并
MapOperator<String, ClickLog> dataSet01 = env
.readTextFile("datas/input/click1.log")
.map(new MapFunction<String, ClickLog>() {
@Override
public ClickLog map(String log) throws Exception {
return JSON.parseObject(log, ClickLog.class);
}
});
MapOperator<String, ClickLog> dataSet02 = env
.readTextFile("datas/input/click2.log")
.map(new MapFunction<String, ClickLog>() {
@Override
public ClickLog map(String log) throws Exception {
return JSON.parseObject(log, ClickLog.class);
}
});
UnionOperator<ClickLog> unionDataSet = dataSet01.union(dataSet02);
System.out.println("dataSet01数据集条目数: " + dataSet01.count());
System.out.println("dataSet02数据集条目数: " + dataSet02.count());
System.out.println("unionDataSet数据集条目数: " + unionDataSet.count());
distinct
API
distinct:对集合中的元素进行去重
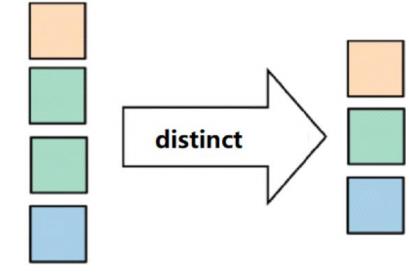
需求:
对合并后的结果进行去重
代码实现:
// TODO: l. 使用distinct函数,进行数据去重
DistinctOperator<ClickLog> distinctDataSet = unionDataSet.distinct(); // 如果是整条数据相同,进行去重
System.out.println("数据去重以后条目数: " + distinctDataSet.count());
// 指定字段,当值相同时,进行去重
DistinctOperator<ClickLog> resultDataSet = unionDataSet.distinct("browserType");
System.out.println("指定browserType字段,数据去重以后条目数: " + resultDataSet.count());
JOIN 函数
1 join
join:将两个集合按照指定的条件进行连接

需求:
将学生成绩数据score.csv和学科数据subject.csv进行关联,得到学生对应学科的成绩
代码实现:
package xx.xxxxx.flink.transformation;
import lombok.Data;
import org.apache.flink.api.common.functions.FlatJoinFunction;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.CrossOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.JoinOperator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class BatchJoinDemo {
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 数据源-source
DataSource<Score> scoreDataSet = env
.readCsvFile("datas/score.csv")
.fieldDelimiter(",")
.pojoType(Score.class, "id", "stuName", "subId", "score");
DataSource<Subject> subjectDataSet = env
.readCsvFile("datas/subject.csv")
.fieldDelimiter(",")
.pojoType(Subject.class, "id", "name");
// TODO: a. 等值JION
/* SELECT t1.xx, t2.xx FROM t1 JOIN t2 ON t1.x = t2.y */
JoinOperator.EquiJoin<Score, Subject, String> joinDataSet = scoreDataSet
.join(subjectDataSet) // 关联数据集
.where("subId").equalTo("id")
.with(new JoinFunction<Score, Subject, String>() {
@Override
public String join(Score left, Subject right) throws Exception {
return left.id + ", " + left.stuName + ", " + right.name + ", " + left.score;
}
});
// joinDataSet.printToErr();
}
@Data
public static class Score{
private Integer id;
private String stuName;
private Integer subId;
private Double score;
}
@Data
public static class Subject {
private Integer id;
private String name;
}
}2 leftOuterJoin
API
leftOuterJoin: 左外连接, 左边集合的元素全部留下,右边的满足条件的元素留下
需求
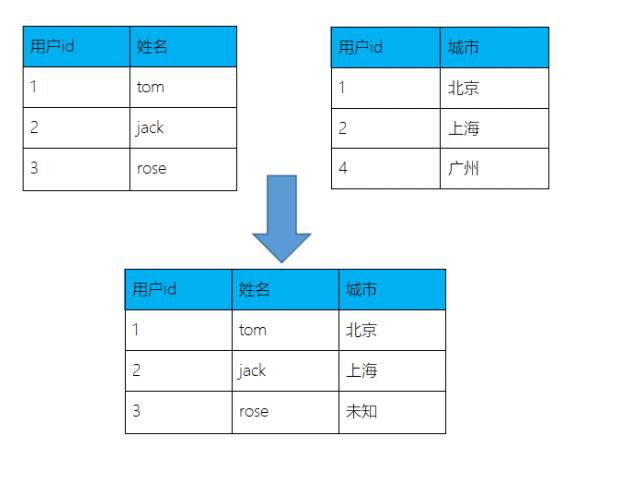
代码实现
DataSource<Tuple2<Integer, String>> userDataSet = env.fromElements(
Tuple2.of(1, "tom"), Tuple2.of(2, "jack"), Tuple2.of(3, "rose")
);
DataSource<Tuple2<Integer, String>> cityDataSet = env.fromElements(
Tuple2.of(1, "北京"), Tuple2.of(2, "上海"), Tuple2.of(4, "广州")
);
// TODO: b. 左外连接LeftJoin
JoinOperator<Tuple2<Integer, String>, Tuple2<Integer, String>, String> leftDataSet = userDataSet
.leftOuterJoin(cityDataSet)
.where(0).equalTo(0)
.with(new JoinFunction<Tuple2<Integer, String>, Tuple2<Integer, String>, String>() {
@Override
public String join(Tuple2<Integer, String> left,
Tuple2<Integer, String> right) throws Exception {
if(null != right){
return left.f0 + ", " + left.f1 + ", " + right.f1 ;
}else{
return left.f0 + ", " + left.f1 + ", " + "未知" ;
}
}
});
// leftDataSet.printToErr();
3 rightOuterJoin
API
rightOuterJoin: 右外连接, 右边集合的元素全部留下,左边的满足条件的元素留下
需求
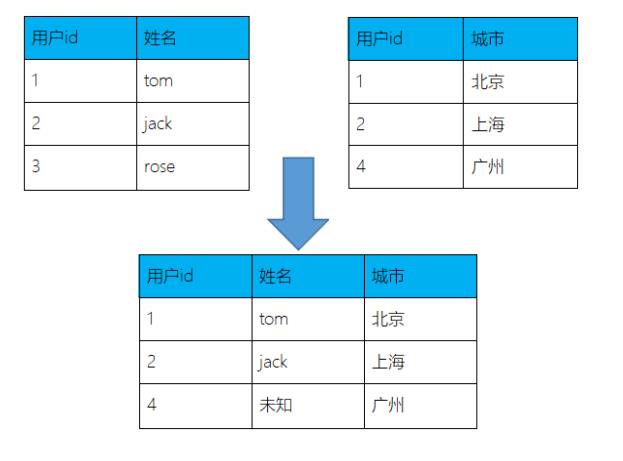
代码实现
// TODO: c. 右外连接RightJoin
JoinOperator<Tuple2<Integer, String>, Tuple2<Integer, String>, String> rightDataSet = userDataSet
.rightOuterJoin(cityDataSet)
.where(0).equalTo(0)
.with(new JoinFunction<Tuple2<Integer, String>, Tuple2<Integer, String>, String>() {
@Override
public String join(Tuple2<Integer, String> left,
Tuple2<Integer, String> right) throws Exception {
if(null != left){
return right.f0 + ", " + left.f1 + ", " + right.f1 ;
}else{
return right.f0 + ", " + "未知" + ", " + right.f1 ;
}
}
});
// rightDataSet.printToErr();
4 fullOuterJoin
API
fullOuterJoin: 全外连接, 左右集合中的元素全部留下
需求
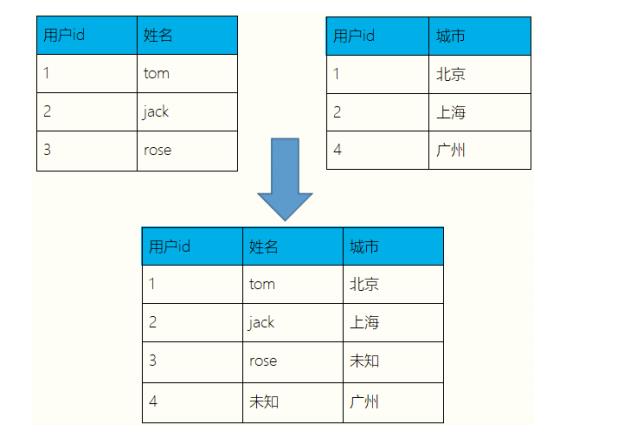
代码实现
// TODO: d. 完全连接:fullOuterJoin
JoinOperator<Tuple2<Integer, String>, Tuple2<Integer, String>, String> fullOuterDataSet = userDataSet
.fullOuterJoin(cityDataSet)
.where(0).equalTo(0)
.with(new FlatJoinFunction<Tuple2<Integer, String>, Tuple2<Integer, String>, String>() {
@Override
public void join(Tuple2<Integer, String> left,
Tuple2<Integer, String> right,
Collector<String> out) throws Exception {
if (null == left) {
out.collect(right.f0 + ", " + "未知" + ", " + right.f1);
} else if (null == right) {
out.collect(left.f0 + ", " + left.f1 + ", " + "未知");
} else {
out.collect(right.f0 + ", " + left.f1 + ", " + right.f1);
}
}
});
// fullOuterDataSet.printToErr();
5 cross
API
corss:求两个集合的笛卡尔积
需求
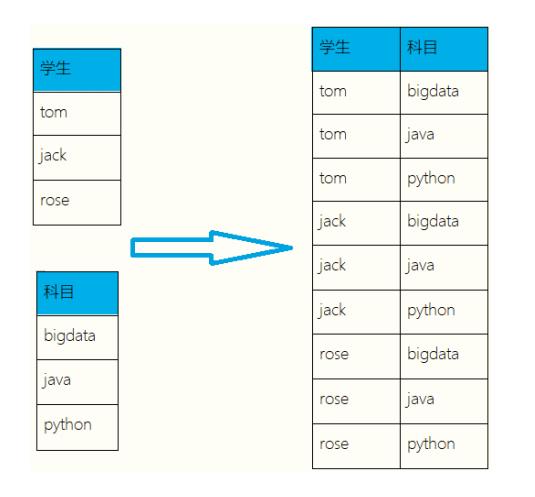
代码实现
// TODO: d. 笛卡尔积:cross
DataSource<String> dataSet01 = env.fromElements("tom", "jack", "rose");
DataSource<String> dataSet02 = env.fromElements("bigdata", "java", "python");
CrossOperator.DefaultCross<String, String> crossDataSet = dataSet01.cross(dataSet02);
crossDataSet.printToErr();
以上是关于从0到1Flink的成长之路的主要内容,如果未能解决你的问题,请参考以下文章