从0到1Flink的成长之路
Posted 熊老二-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从0到1Flink的成长之路相关的知识,希望对你有一定的参考价值。
重分区函数
rebalance 重平衡分区
API
类似于Spark中的repartition,但是功能更强大,可以直接解决数据倾斜
Flink也有数据倾斜的时候,比如当前有数据量大概10亿条数据需要处理,在处理过程中可能会发
生如图所示的状况,出现了数据倾斜,其他3台机器执行完毕也要等待机器1执行完毕后才算整体
将任务完成;
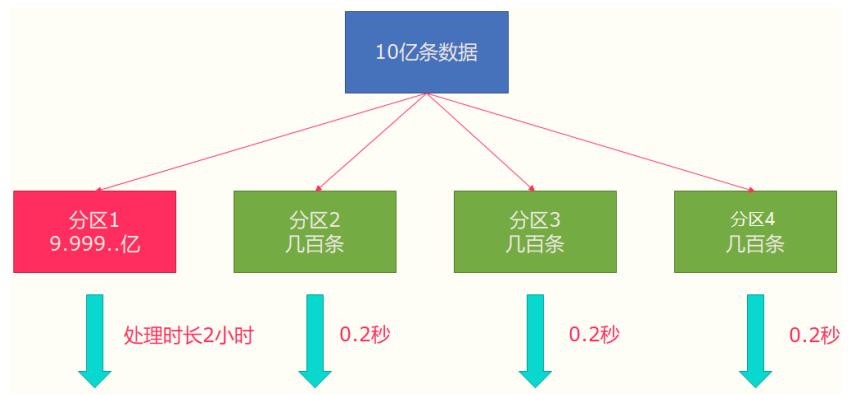
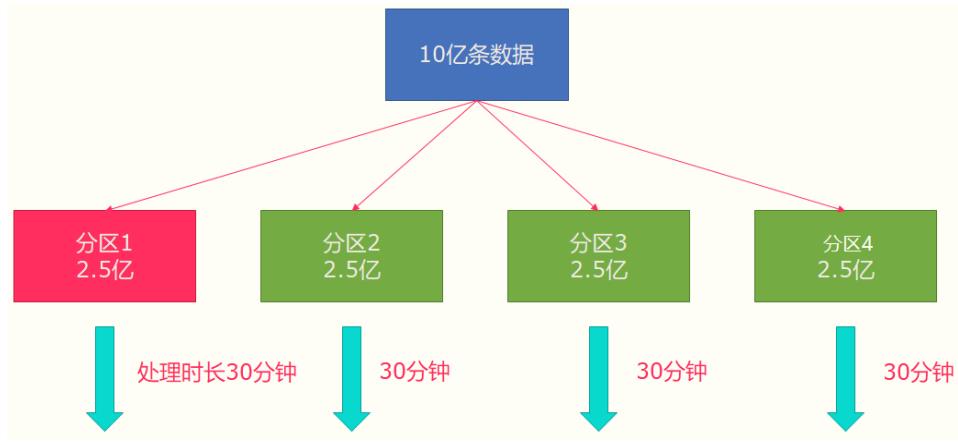
所以在实际的工作中,出现这种情况比较好的解决方案就是rebalance(内部使用round robin
方法将数据均匀打散)。
代码演示:
package xx.xxxxx.flink.transformation;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.common.functions.RichFilterFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FilterOperator;
import org.apache.flink.api.java.operators.PartitionOperator;
import org.apache.flink.api.java.tuple.Tuple3;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
/**
* Flink 批处理DataSet API中分区函数
* TODO: rebalance、partitionBy*
*/
public class BatchRepartitionDemo {
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 设置并行度为3
env.setParallelism(3);
// 2. 数据源-source
DataSource<Long> dataset = env.generateSequence(1, 30);
dataset
// 获取各个分区编号
.map(new RichMapFunction<Long, String>() {
@Override
public String map(Long value) throws Exception {
int index = getRuntimeContext().getIndexOfThisSubtask();
return index + ": " + value;
}
})
.printToErr();
// TODO: 使用filter函数,过滤数据
FilterOperator<Long> filterDataSet = dataset.filter(new RichFilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return value > 5 && value < 26;
}
});
filterDataSet
// 获取各个分区编号
.map(new RichMapFunction<Long, String>() {
@Override
public String map(Long value) throws Exception {
int index = getRuntimeContext().getIndexOfThisSubtask();
return index + ": " + value;
}
})
.printToErr();
// TODO:使用rebalance函数,对数据集进行重新划分采用的是轮询机制
PartitionOperator<Long> rebalanceDataSet = filterDataSet.rebalance();
rebalanceDataSet
// 获取各个分区编号
.map(new RichMapFunction<Long, String>() {
@Override
public String map(Long value) throws Exception {
int index = getRuntimeContext().getIndexOfThisSubtask();
return index + ": " + value;
}
})
.printToErr();
}
}其他分区
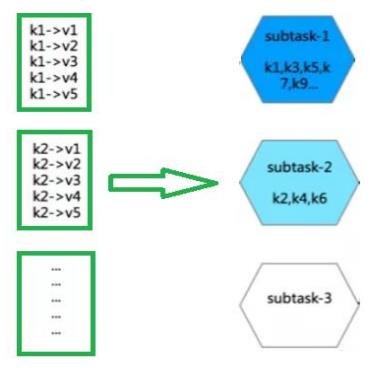
代码实现
// TODO: 其他一些分区函数,针对数据类型为Tuple元组
List<Tuple3<Integer,Long,String>> list = new ArrayList<>();
list.add(Tuple3.of(1, 1L, "Hello"));
list.add(Tuple3.of(2, 2L, "Hello"));
list.add(Tuple3.of(3, 2L, "Hello"));
list.add(Tuple3.of(4, 3L, "Hello"));
list.add(Tuple3.of(5, 3L, "Hello"));
list.add(Tuple3.of(6, 3L, "hehe"));
list.add(Tuple3.of(7, 4L, "hehe"));
list.add(Tuple3.of(8, 4L, "hehe"));
list.add(Tuple3.of(9, 4L, "hehe"));
list.add(Tuple3.of(10, 4L, "hehe"));
list.add(Tuple3.of(11, 5L, "hehe"));
list.add(Tuple3.of(12, 5L, "hehe"));
list.add(Tuple3.of(13, 5L, "hehe"));
list.add(Tuple3.of(14, 5L, "hehe"));
list.add(Tuple3.of(15, 5L, "hehe"));
list.add(Tuple3.of(16, 6L, "hehe"));
list.add(Tuple3.of(17, 6L, "hehe"));
list.add(Tuple3.of(18, 6L, "hehe"));
list.add(Tuple3.of(19, 6L, "hehe"));
list.add(Tuple3.of(20, 6L, "hehe"));
list.add(Tuple3.of(21, 6L, "hehe"));
// 将数据打乱,进行洗牌
Collections.shuffle(list);
DataSource<Tuple3<Integer, Long, String>> tupleDataSet = env.fromCollection(list);
env.setParallelism(2);
// TODO: a. 指定字段,按照hash进行分区
tupleDataSet
.partitionByHash(2)
.map(new RichMapFunction<Tuple3<Integer, Long, String>, String>() {
@Override
public String map(Tuple3<Integer, Long, String> value) throws Exception {
int index = getRuntimeContext().getIndexOfThisSubtask();
return index + ": " + value.toString();
}
})
.printToErr();
// TODO: b. 指定字段,按照Range范围进行分区
tupleDataSet
.partitionByRange(0)
.map(new RichMapFunction<Tuple3<Integer, Long, String>, String>() {
@Override
public String map(Tuple3<Integer, Long, String> value) throws Exception {
int index = getRuntimeContext().getIndexOfThisSubtask();
return index + ": " + value.toString();
}
})
.printToErr();
// TODO: c. 自定义分区规则
tupleDataSet
.partitionCustom(new Partitioner<Integer>() {
@Override
public int partition(Integer key, int numPartitions) {
return key % 2; // 奇数,偶数 划分
}
}, 0
)
.map(new RichMapFunction<Tuple3<Integer, Long, String>, String>() {
@Override
public String map(Tuple3<Integer, Long, String> value) throws Exception {
int index = getRuntimeContext().getIndexOfThisSubtask();
return index + ": " + value.toString();
}
})
.printToErr();
以上是关于从0到1Flink的成长之路的主要内容,如果未能解决你的问题,请参考以下文章