从0到1Flink的成长之路
Posted 熊老二-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从0到1Flink的成长之路相关的知识,希望对你有一定的参考价值。
高级特性
在Flink 批处理中提供类似Spark框架的高级特性,比如累加器、广播变量和分布式缓存。
1 累加器
API
Flink中的累加器,与Mapreduce counter的应用场景类似,可以很好地观察task在运行期间的
数据变化,如在Flink job任务中的算子函数中操作累加器,在任务执行结束之后才能获得累加器
的最终结果。
Flink有以下内置累加器,每个累加器都实现了Accumulator接口。
IntCounter
LongCounter
DoubleCounter
编码步骤:
1.创建累加器
private IntCounter numLines = new IntCounter();
2.注册累加器
getRuntimeContext().addAccumulator("num-lines", this.numLines);
3.使用累加器
this.numLines.add(1);
4.获取累加器的结果
myJobExecutionResult.getAccumulatorResult("num-lines")代码实现:
package xx.xxxxx.flink.other;
import org.apache.flink.api.common.JobExecutionResult;
import org.apache.flink.api.common.accumulators.IntCounter;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.configuration.Configuration;
/**
* 演示Flink中累加器Accumulator使用,统计处理的条目数
*/
public class BatchAccumulatorDemo {
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 数据源-source
DataSource<String> dataSet = env.readTextFile("datas/u.data");
// 3. 数据转换-transformation
// map 函数,对数据不进行任何操作,仅仅为了使用累加器
MapOperator<String, String> resultDataSet = dataSet.map(new RichMapFunction<String, String>() {
// TODO: 其一、创建累加器
IntCounter counter = new IntCounter();
@Override
public void open(Configuration parameters) throws Exception {
// TODO: 其二、注册累加器
getRuntimeContext().addAccumulator("number-lines", counter);
}
@Override
public String map(String value) throws Exception {
// TODO: 其三,使用累加器
counter.add(1);
return value;
}
});
// 4. 数据终端-sink
resultDataSet.writeAsText("datas/accu-sink.txt").setParallelism(1);
// 5. 执行-execute
JobExecutionResult jobResult = env.execute(BatchAccumulatorDemo.class.getSimpleName());
// TODO: 其四、获取累加器数据
Object accumulatorResult = jobResult.getAccumulatorResult("number-lines");
System.out.println("Counter: " + accumulatorResult);
}
}
2 广播变量
API
Flink支持广播,可以将数据广播到TaskManager上就可以供TaskManager中的SubTask/task
去使用,数据存储到内存中。这样可以减少大量的shuffle操作,而不需要多次传递给集群节点;
比如在数据join阶段,不可避免的就是大量的shuffle操作,可以把其中一个dataSet广播出去,一直加载到taskManager的内存中,可以直接在内存中拿数据,避免了大量的shuffle,导致集群性能下降;
图解:
- 可以理解广播就是一个公共的共享变量
- 将一个数据集广播后,不同的Task都可以在节点上获取到
- 每个节点只存一份
- 如果不使用广播,每一个Task都会拷贝一份数据集,造成内存资源浪费
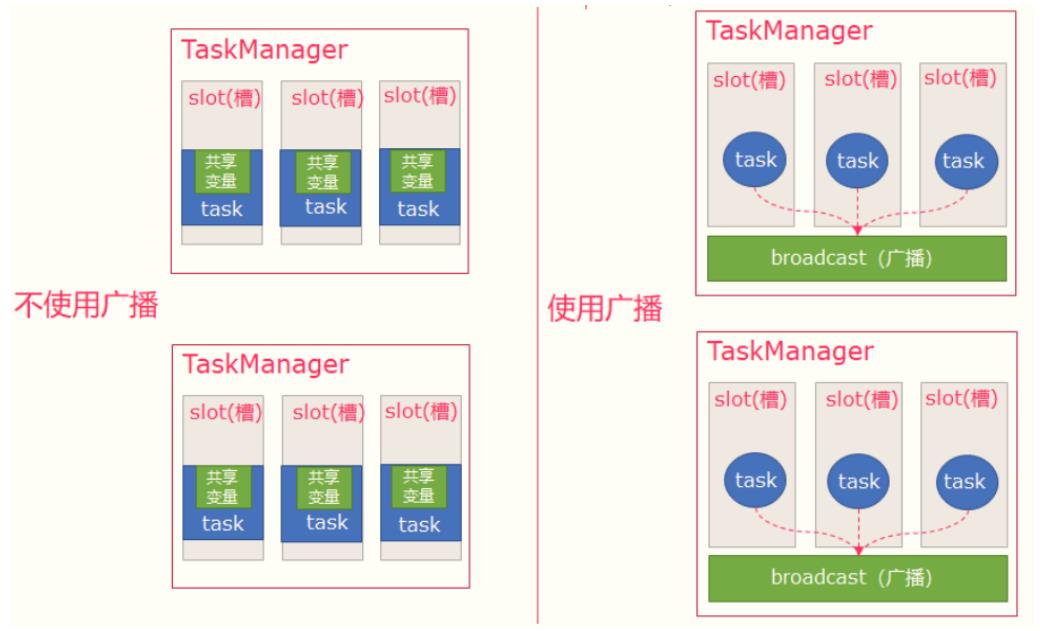
注意:
广播变量是要把dataset广播到内存中,所以广播的数据量不能太大,否则会出现OOM
广播变量的值不可修改,这样才能确保每个节点获取到的值都是一致的
编码步骤:
1:广播数据
.withBroadcastSet(DataSet, "name");
2:获取广播的数据
Collection<> broadcastSet = getRuntimeContext().getBroadcastVariable("name");
3:使用广播数据
需求:
将studentDS(学号,姓名)集合广播出去(广播到各个TaskManager内存中)
然后使用scoreDS(学号,学科,成绩)和广播数据(学号,姓名)进行关联,得到这样格式的数据:(姓名,
学科,成绩)
代码实现:
package xx.xxxxx.flink.other;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* Flink 批处理中广播变量:将小数据集广播至TaskManager内存中,便于使用
*/
public class BatchBroadcastDemo {
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 数据源-source:从本地集合构建2个DataSet
DataSource<Tuple2<Integer, String>> studentDataSet = env.fromCollection(
Arrays.asList(Tuple2.of(1, "张三"), Tuple2.of(2, "李四"), Tuple2.of(3, "王五"))
);
DataSource<Tuple3<Integer, String, Integer>> scoreDataSet = env.fromCollection(
Arrays.asList(Tuple3.of(1, "语文", 50), Tuple3.of(2, "数学", 70), Tuple3.of(3, "英语", 86))
);
// 3. 数据转换-transform:使用map函数,定义加强映射函数RichMapFunction,使用广播变量值
/*
(1, "语文", 50) -> "张三" , "语文", 50
(2, "数学", 70) -> "李四", "数学", 70
(3, "英语", 86) -> "王五", "英语", 86
*/
MapOperator<Tuple3<Integer, String, Integer>, String> resultDataSet = scoreDataSet
// 将scoreDataSet数据集中,每条数据的studentId转换为studentName
.map(new RichMapFunction<Tuple3<Integer, String, Integer>, String>() {
// 定义Map集合,存储Student数据,其中key: id, value: name
Map<Integer, String> stuMap = new HashMap<>();
@Override
public void open(Configuration parameters) throws Exception {
// TODO: 其二、获取广播变量的数据
List<Tuple2<Integer, String>> list = getRuntimeContext().getBroadcastVariable("students");
// 遍历list中数据,添加到Map集合中
for(Tuple2<Integer, String> item: list){
stuMap.put(item.f0, item.f1) ;
}
}
@Override
public String map(Tuple3<Integer, String, Integer> value) throws Exception {
// TODO: 使用广播变量数据
String studentName = stuMap.getOrDefault(value.f0, "None");
return studentName + ", " + value.f1 + ", " + value.f2;
}
})
// TODO: 其一、将studentDataSet数据集广播出去
.withBroadcastSet(studentDataSet, "students");
// 4. 数据终端-sink
resultDataSet.printToErr();
}
}
3 分布式缓存
API解释
Flink提供了一个类似于Hadoop的分布式缓存,让并行运行实例的函数可以在本地访问。
这个功能可以被使用来分享外部静态的数据,例如:机器学习的逻辑回归模型等
注意
广播变量是将变量分发到各个TaskManager节点的内存上,分布式缓存是将文件缓存到各个
TaskManager节点上;
编码步骤:
1:注册一个分布式缓存文件
env.registerCachedFile("hdfs:///path/file", "cachefilename")
2:访问分布式缓存文件中的数据
File myFile = getRuntimeContext().getDistributedCache().getFile("cachefilename");
3:使用
需求
将scoreDS(学号, 学科, 成绩)中的数据和分布式缓存中的数据(学号,姓名)关联,得到这样格式
的数据: (学生姓名,学科,成绩)
代码实现:
package xx.xxxxx.flink.other;
import org.apache.commons.io.FileUtils;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import java.io.File;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* Flink 批处理中分布式缓存:将小文件数据进行缓存
*/
public class BatchDistributedCacheDemo {
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// TODO: 其一、注册一个分布式缓存文件
env.registerCachedFile("datas/distribute_cache_student", "student_file");
// 2. 数据源-source:从本地集合构建DataSet
DataSource<Tuple3<Integer, String, Integer>> scoreDataSet = env.fromCollection(
Arrays.asList(Tuple3.of(1, "语文", 50), Tuple3.of(2, "数学", 70), Tuple3.of(3, "英语", 86))
);
// 3. 数据转换-transform:使用map函数,定义加强映射函数RichMapFunction,使用分布式缓存文件数据集进行转换
/*
(1, "语文", 50) -> "张三" , "语文", 50
(2, "数学", 70) -> "李四", "数学", 70
(3, "英语", 86) -> "王五", "英语", 86
*/
MapOperator<Tuple3<Integer, String, Integer>, String> resultDataSet = scoreDataSet.map(
new RichMapFunction<Tuple3<Integer, String, Integer>, String>() {
// 定义Map集合,存储Student数据,其中key: id, value: name
Map<Integer, String> stuMap = new HashMap<>();
@Override
public void open(Configuration parameters) throws Exception {
// TODO: 其二、获取分布式缓存文件数据
File file = getRuntimeContext().getDistributedCache().getFile("student_file");
// 使用工具类,读取文件内容
List<String> list = FileUtils.readLines(file);
// 循环遍历列表数据,字符串分割,将数据添加Map集合
for (String line : list) {
String[] split = line.trim().split(",");
stuMap.put(Integer.valueOf(split[0]), split[1]);
}
}
@Override
public String map(Tuple3<Integer, String, Integer> value) throws Exception {
// TODO: 使用分布式缓存的数据
String studentName = stuMap.getOrDefault(value.f0, "None");
return studentName + ", " + value.f1 + ", " + value.f2;
}
}
);
// 4. 数据终端-sink
resultDataSet.printToErr();
}
}
以上是关于从0到1Flink的成长之路的主要内容,如果未能解决你的问题,请参考以下文章