从0到1Flink的成长之路(十四)
Posted 熊老二-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从0到1Flink的成长之路(十四)相关的知识,希望对你有一定的参考价值。
Source 数据源

1 基于Socket的Source
一般用于学习测试
需求:
1.在node1上使用 nc -lk 9999 向指定端口发送数据nc是netcat的简称,原本是用来设置路由器,我们可以利用它向某个端口发送数据,如果没有该命令可以下安装:yum install -y nc.
2.使用Flink编写流处理应用程序实时统计单词数量.
代码实现:
package xx.xxxxx.flink.source.basic;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* Flink 流计算数据源:Socket,进行词频统计
*/
public class StreamSourceSocketDemo {
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment() ;
env.setParallelism(2);
// 2. 数据源
DataStreamSource<String> inputDataStream = env.socketTextStream("node1.itcast.cn", 9999);
// 3. 转换操作-transformation
SingleOutputStreamOperator<Tuple2<String, Integer>> resultDataStream = inputDataStream
.filter(new FilterFunction<String>() {
@Override
public boolean filter(String line) throws Exception {
return null != line && line.trim().length() > 0;
}
})
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line,
Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = line.trim().toLowerCase().split("\\\\W+");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
})
// TODO: 指定分组,指定KeySelector选择器
.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
})
// TODO: 聚合操作,使用reduce函数聚合计数
.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1,
Tuple2<String, Integer> t2) throws Exception
{
return new Tuple2<>(t1.f0, t1.f1 + t2.f1);
}
});
// 4. 数据终端-sink
resultDataStream.printToErr();
// 5. 触发执行-execute
env.execute(StreamSourceSocketDemo.class.getSimpleName());
}
}
2 基于集合的Source
一般用于学习测试,和批处理的API类似,不再演示。
package xx.xxxxx.flink.source.basic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
/**
* Flink 流计算数据源:基于集合的Source,分别为可变参数、集合和自动生成数据
*/
public class StreamSourceCollectionDemo {
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2) ;
// 2. 数据源
DataStreamSource<String> dataStream01 = env.fromElements("spark", "flink", "mapreduce");
dataStream01.printToErr();
DataStreamSource<String> dataStream02 = env.fromCollection(Arrays.asList("spark", "flink", "mapreduce"));
dataStream02.print();
DataStreamSource<Long> dataStream03 = env.generateSequence(1, 10);
dataStream03.printToErr();
// 5. 触发执行-execute
env.execute(StreamSourceCollectionDemo.class.getSimpleName());
}
3 基于文件的Source
一般用于学习测试,和批处理的API类似,不再演示
package xx.xxxxx.flink.source.basic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* Flink 流计算数据源:基于文件的Source
* public class StreamSourceFileDemo {
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2) ;
// 2. 数据源
DataStreamSource<String> dataStream = env.readTextFile("datas/wordcount.data");
dataStream.printToErr();
// 5. 触发执行-execute
env.execute(StreamSourceFileDemo.class.getSimpleName());
}
}
*/
4 自定义Source:交易订单
API
一般用于学习测试,模拟生成一些数据
Flink提供数据源接口,可以实现自定义数据源,不同的接口有不同的功能,分类如下:
SourceFunction:非并行数据源(并行度parallelism=1)
RichSourceFunction:多功能非并行数据源(并行度parallelism=1)
ParallelSourceFunction:并行数据源(并行度parallelism>=1)
RichParallelSourceFunction:多功能并行数据源(parallelism>=1),Kafka数据源使用该接口
需求
每隔1秒随机生成一条订单信息(订单ID、用户ID、订单金额、时间戳)
要求:
- 随机生成订单ID:UUID ·
- 随机生成用户ID:0-2
- 随机生成订单金额:0-100
- 时间戳为当前系统时间:current_timestamp
代码实现
package xx.xxxxx.flink.source.customer;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import java.util.Random;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
/**
* 每隔1秒随机生成一条订单信息(订单ID、用户ID、订单金额、时间戳)
* - 随机生成订单ID:UUID
* - 随机生成用户ID:0-2
* - 随机生成订单金额:0-100
* - 时间戳为当前系统时间:current_timestamp
*/
public class StreamSourceOrderDemo {
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Order {
private String id;
private Integer userId;
private Double money;
private Long orderTime;
}
/**
* 自定义数据源,实时产生订单数据,继承RichParallelSourceFunction接口
*/
public static class OrderSource extends RichParallelSourceFunction<Order> {
// 标识符:表示是否运行产生数据
private boolean isRunning = true;
// 不断执行,实时产生数据
@Override
public void run(SourceContext<Order> ctx) throws Exception {
// 随机实例对象
Random random = new Random();
while (isRunning) {
// 创建订单对象
Order order = new Order(
UUID.randomUUID().toString().substring(1, 18), //
random.nextInt(2), //
random.nextDouble() * 100, //
System.currentTimeMillis() //
);
// 发送数据
ctx.collect(order);
// TODO: 每秒钟产生一条数据
TimeUnit.SECONDS.sleep(1);
}
}
@Override
public void cancel() {
// 当不在接收数据时,设置isRunning为false
isRunning = false;
}
}
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
// 2. 数据源-source
DataStreamSource<Order> orderDataStream = env.addSource(new OrderSource());
// 3. 数据终端-sink
orderDataStream.printToErr();
// 5. 触发执行-execute
env.execute(StreamSourceOrderDemo.class.getSimpleName());
}
}
5 自定义Source:mysql
需求:
实际开发中,经常会实时接收一些数据,要和MySQL中存储的一些规则进行匹配,那么这时候就可以使用Flink自定义数据源从MySQL中读取数据
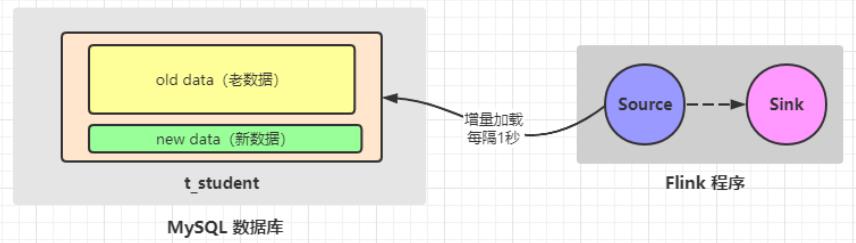
需求:从MySQL中实时加载数据,要求MySQL中的数据有变化,也能被实时加载出来
准备数据
CREATE DATABASE IF NOT EXISTS db_flink ;
USE db_flink ;
CREATE TABLE `t_student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO `t_student` VALUES ('1', 'jack', 18);
INSERT INTO `t_student` VALUES ('2', 'tom', 19);
INSERT INTO `t_student` VALUES ('3', 'rose', 20);
INSERT INTO `t_student` VALUES ('4', 'tom', 19);
INSERT INTO `t_student` VALUES ('5', 'jack', 18);
INSERT INTO `t_student` VALUES ('6', 'rose', 20);
INSERT INTO `t_student` VALUES ('9', 'zhangsan2', 19);
INSERT INTO `t_student` VALUES ('10', 'lisi2', 21);
代码实现:
package xx.xxxxx.flink.source.mysql;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.concurrent.TimeUnit;
/**
* 从MySQL中实时加载数据:要求MySQL中的数据有变化,也能被实时加载出来
*/
public class StreamSourceMySQLDemo {
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Student {
private Integer id;
private String name;
private Integer age;
}
/**
* 自定义数据源,实时从MySQL表获取数据,实现接口RichParallelSourceFunction
*/
public static class MySQLSource extends RichParallelSourceFunction<Student> {
// 标识符,是否实时接收数据
private boolean isRunning = true ;
private Connection conn = null;
private PreparedStatement pstmt = null;
private ResultSet result = null ;
private Integer whereId = 0 ;
@Override
public void open(Configuration parameters) throws Exception {
// 1. 加载驱动
Class.forName("com.mysql.jdbc.Driver");
// 2. 创建连接
conn = DriverManager.getConnection(
"jdbc:mysql://node1.itcast.cn:3306/?useUnicode=true&characterEncoding=utf-8&useSSL=false",
"root",
"123456"
);
// 3. 创建PreparedStatement
pstmt = conn.prepareStatement("select id, name, age from db_flink.t_student WHERE id > ?");
}
@Override
public void run(SourceContext<Student> ctx) throws Exception {
while (isRunning){
// 1. 执行查询
pstmt.setInt(1, whereId);
result = pstmt.executeQuery();
// 2. 遍历查询结果,收集数据
while (result.next()){
Integer id = result.getInt("id");
String name = result.getString("name") ;
Integer age = result.getInt("age") ;
// 输出
ctx.collect(new Student(id, name, age));
whereId = id ;
}
// 每隔3秒查询一次
TimeUnit.SECONDS.sleep(3);
}
}
@Override
public void close() throws Exception {
if(null != result) result.close();
if(null != pstmt) pstmt.close();
if(null != conn) conn.close();
}
@Override
public void cancel() {
isRunning = false ;
}
}
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 2. 数据源-source
DataStreamSource<Student> studentDataStream = env.addSource(new MySQLSource());
// 3. 数据终端-sink
studentDataStream.printToErr();
// 5. 应用执行-execute
env.execute(StreamSourceMySQLDemo.class.getSimpleName());
}
}
6 Kafka Source

6.1 API及其版本
Flink 里已经提供了一些绑定的 Connector,例如 Kafka Source 和 Sink,Elasticsearch Sink 等。
读写 Kafka、ES、RabbitMQ 时可以直接使用相应 connector 的 API 即可,虽然该部分是Flink 项目源代码里的一部分,但是真正意义上不算作 Flink 引擎相关逻辑,并且该部分没有打包在二进制的发布包里面。
所以在提交 Job 时候需要注意, job 代码 jar 包中一定要将相应的connetor 相关类打包进去,否则在提交作业时就会失败,提示找不到相应的类,或初始化某些类异常。
flink-docs
6.2 参数设置
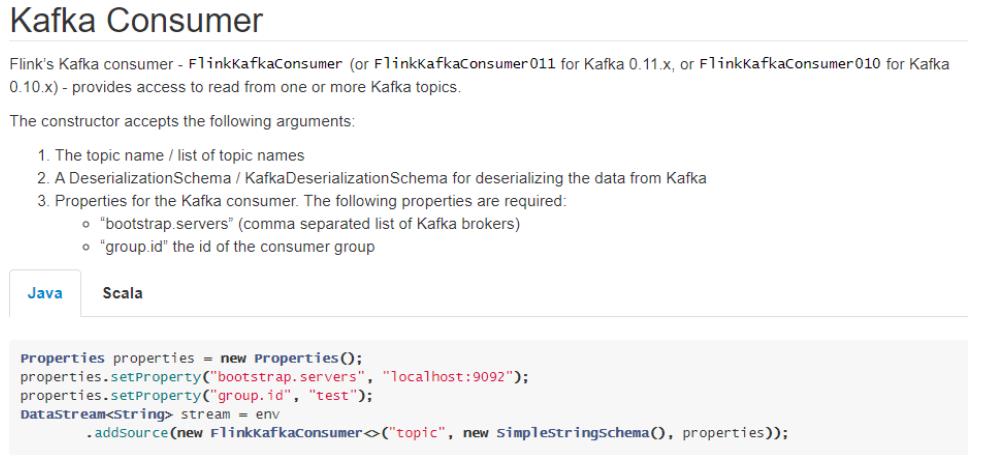
以下参数都必须/建议设置
1.订阅的主题:topic
2.反序列化规则:deserialization
3.消费者属性-集群地址:bootstrap.servers
4.消费者属性-消费者组id(如果不设置,会有默认的,但是默认的不方便管理):groupId
5.消费者属性-offset重置规则,如earliest/latest…:offset
6.动态分区检测:dynamic partition detection

6.3 Kafka命令
启动Kafka和Zookeeper命令,针对讲师提供虚拟机:
zookeeper-daemon.sh start
kafka-daemon.sh start
● 查看当前服务器中的所有topic
/export/server/kafka/bin/kafka-topics.sh --list --bootstrap-server node1.itcast.cn:9092
● 创建topic
/export/server/kafka/bin/kafka-topics.sh --create --topic flink-topic \\
--bootstrap-server node1.itcast.cn:9092 --replication-factor 1 --partitions 3
● 查看某个Topic的详情
/export/server/kafka/bin/kafka-topics.sh --describe --topic flink-topic \\
--bootstrap-server node1.itcast.cn:9092
● 删除topic
/export/server/kafka/bin/kafka-topics.sh --delete --topic flink-topic \\
--bootstrap-server node1.itcast.cn:9092
● 发送消息
/export/server/kafka/bin/kafka-console-producer.sh --topic flink-topic \\
--broker-list node1.itcast.cn:9092
● 消费消息
/export/server/kafka/bin/kafka-console-consumer.sh --topic flink-topic \\
--bootstrap-server node1.itcast.cn:9092 --from-beginning
● 修改分区
/export/server/kafka/bin/kafka-topics.sh --alter --topic flink-topic \\
--bootstrap-server node1.itcast.cn:9092 --partitions 4
6.4 代码实现
Flink 实时从Kafka消费数据,底层调用Kafka New Consumer API,演示案例代码如下:
package xx.xxxxx.flink.source.kafka;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.kafka.clients.CommonClientConfigs;
import java.util.Properties;
public class StreamSourceKafkaDemo {
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3) ;
// 2. 数据源-source:从Kafka 消费数据
// a. Kafka Consumer消费者配置属性设置
Properties props = new Properties() ;
props.setProperty(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, "node1.itcast.cn:9092");
props.setProperty("group.id", "test-1001");
// b. 创建FlinkKafkaConsumer对象
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<String>(
"flink-topic", // Topic 名称
new SimpleStringSchema(), //
props //
) ;
// c. 添加数据源
DataStreamSource<String> kafkaDataStream = env.addSource(kafkaConsumer);
// 3. 数据终端-sink
kafkaDataStream.printToErr();
// 4. 触发执行-execute
env.execute(StreamSourceKafkaDemo.class.getSimpleName()) ;
}
}
6.5 Kafka 消费起始位置
Kafka 可以被看成一个无限的流,里面的流数据是短暂存在的,如果不消费,消息就过期滚动没了。涉及一个问题:如果开始消费,就要定一下从什么位置开始。
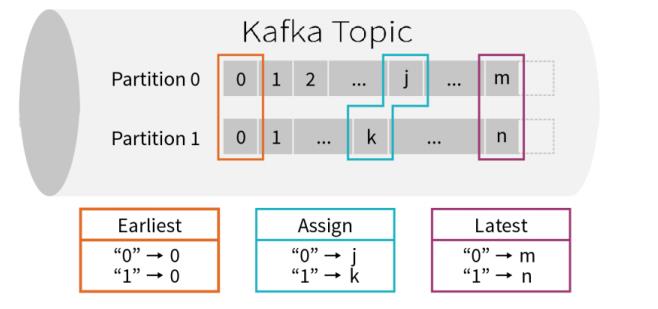
第一、earliest:从最起始位置开始消费,当然不一定是从0开始,因为如果数据过期就清掉了,所以可以理解为从现存的数据里最小位置开始消费;
第二、latest:从最末位置开始消费;
第三、per-partition assignment:对每个分区都指定一个offset,再从offset位置开始消费;

默认情况下,从Kafka消费数据时,采用的是:latest,最新偏移量开始消费数据。
在Flink Kafka Consumer 库中,允许用户配置从每个分区的哪个位置position开始消费数
据,具体说明如下所示:
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/connectors/kafka.html#kafka-consumers-start-position-configuration

在代码中设置消费数据起始位置相关API如下所示:
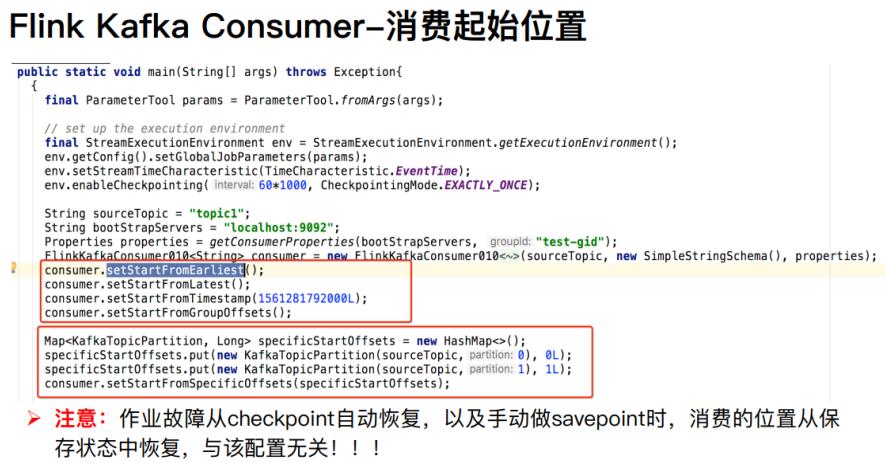
案例演示代码:
package xx.xxxxx.flink.source.kafka;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.internals.KafkaTopicPartition;
import org.apache.kafka.clients.CommonClientConfigs;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
public class StreamSourceKafkaOffsetDemo {
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3) ;
// 2. 数据源-source:从Kafka 消费数据
// a. Kafka Consumer消费者配置属性设置
Properties props = new Properties() ;
props.setProperty(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, "node1.itcast.cn:9092");
props.setProperty("group.id", "test-1001");
// b. 创建FlinkKafkaConsumer对象
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<String>(
"flink-topic", // Topic 名称
new SimpleStringSchema(), //
props //
) ;
// TODO: 1、Flink从topic中最初的数据开始消费
//kafkaConsumer.setStartFromEarliest() ;
// TODO: 2、Flink从topic中最新的数据开始消费
//kafkaConsumer.setStartFromLatest();
// TODO: 3、Flink从topic中指定的group上次消费的位置开始消费,所以必须配置group.id参数
//kafkaConsumer.setStartFromGroupOffsets() ;
// TODO: 4、Flink从topic中指定的offset开始,这个比较复杂,需要手动指定offset
Map<KafkaTopicPartition, Long> offsets = new HashMap<>();
offsets.put(new KafkaTopicPartition("flink-topic", 0), 28L);
offsets.put(new KafkaTopicPartition("flink-topic", 1), 94L);
offsets.put(new KafkaTopicPartition("flink-topic", 2), 108L);
//kafkaConsumer.setStartFromSpecificOffsets(offsets);
// TODO: 5、Flink从topic中指定的时间点开始消费,指定时间点之前的数据忽略
kafkaConsumer.setStartFromTimestamp(1603099781484L) ;
// c. 添加数据源
DataStreamSource<String> kafkaDataStream = env.addSource(kafkaConsumer);
// 3. 数据终端-sink
kafkaDataStream.printToErr();
// 4. 触发执行-execute
env.execute(StreamSourceKafkaOffsetDemo.class.getSimpleName()) ;
}
}

注意:开启 checkpoint 时 offset 是 Flink 通过状态 state 管理和恢复的,并不是从 kafka 的offset 位置恢复。在 checkpoint 机制下,作业从最近一次checkpoint 恢复,本身是会回放部分历史数据,导致部分数据重复消费,Flink 引擎仅保证计算状态的精准一次,要想做到端到端精准一次需要依赖一些幂等的存储系统或者事务操作。
6.6 Kafka 分区发现
实际的生产环境中可能有这样一些需求,比如:
场景一:有一个 Flink 作业需要将五份数据聚合到一起,五份数据对应五个 kafka topic,随着业务增长,新增一类数据,同时新增了一个 kafka topic,如何在不重启作业的情况下作业自动感知新的topic。
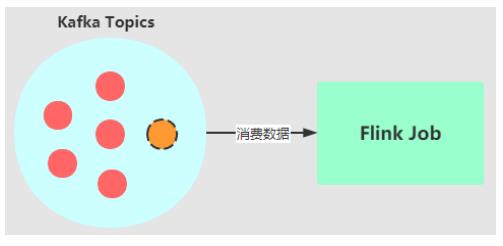
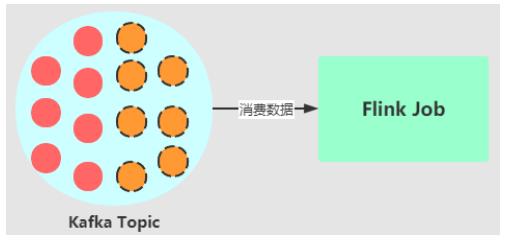
场景二:作业从一个固定的 kafka topic 读数据,开始该 topic 有 6 个 partition,但随着
业务的增长数据量变大,需要对 kafka partition 个数进行扩容,由 6 个扩容到 12。该情况
下如何在不重启作业情况下动态感知新扩容的 partition?
kafka-consumers-topic-and-partition-discovery

针对上面的两种场景,首先在构建 FlinkKafkaConsumer 时的 properties 中设置flink.partition-discovery.interval-millis 参数为非负值,表示开启动态发现的开关,及设置的时间间隔。此时FlinkKafkaConsumer内部会启动一个单独的线程定期去Kafka获取最新的meta信息。
针对场景一,还需在构建 FlinkKafkaConsumer 时,topic 的描述可以传一个正则表达式描述的 pattern。每次获取最新 kafka meta 时获取正则匹配的最新 topic 列表。
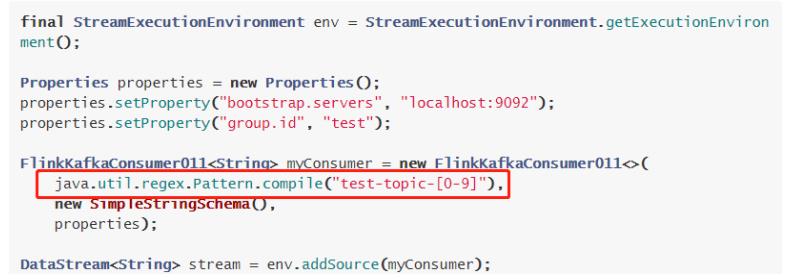
针对场景二,设置前面的动态发现参数,在定期获取 kafka 最新 meta 信息时会匹配新的
partition。为了保证数据的正确性,新发现的 partition 从最早的位置开始读取。
以上是关于从0到1Flink的成长之路(十四)的主要内容,如果未能解决你的问题,请参考以下文章