从0到1Flink的成长之路(二十)-Flink 高级特性之无状态和有状态计算
Posted 熊老二-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从0到1Flink的成长之路(二十)-Flink 高级特性之无状态和有状态计算相关的知识,希望对你有一定的参考价值。
无状态和有状态计算
1 无状态计算
无状态(Stateless)计算特性:
不需要考虑历史数据
相同的输入得到相同的输出
如map、filter、flatMap等方法

首先举一个无状态计算的例子:消费延迟计算。
假设现在有一个消息队列,消息队列中有一个生产者持续往消费队列写入消息,多个消费者分别从消息队列中读取消息。从图上可以看出,生产者已经写入 16 条消息,Offset 停留在 15 ;有 3 个消费者,有的消费快,而有的消费慢。消费快的已经消费了 13 条数据,消费者慢的才消费了 8 条数据。
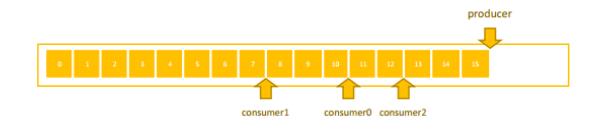
如何实时统计每个消费者落后多少条数据,如图给出了输入输出的示例。可以了解到输入的时间点有一个时间戳,生产者将消息写到了某个时间点的位置,每个消费者同一时间点分别读到了什么位置。刚才也提到了生产者写入了 15 条,消费者分别读取了 10、7、12 条。那么问题来了,怎么将生产者、消费者的进度转换为右侧示意图信息呢?

consumer 0 落后了 5 条,consumer 1 落后了 8 条,consumer 2 落后了 3 条,根据Flink 的原理,此处需进行 Map 操作。Map 首先把消息读取进来,然后分别相减,即可知道每个 consumer 分别落后了几条。Map 一直往下发,则会得出最终结果。
大家会发现,在这种模式的计算中,无论这条输入进来多少次,输出的结果都是一样的,因为单条输入中已经包含了所需的所有信息。消费落后等于生产者减去消费者。生产者的消费在单条数据中可以得到,消费者的数据也可以在单条数据中得到,所以相同输入可以得到相同输出,这就是一个无状态的计算。
2 有状态计算
有状态(State)计算特性:
需要考虑历史数据
相同的输入得到不同的输出/不一定得到相同的输出
如sum/reduce等方法

以访问日志统计量的例子进行说明,比如当前拿到一个 nginx 访问日志,一条日志表示一个请求,记录该请求从哪里来,访问的哪个地址,需要实时统计每个地址总共被访问了多少次,也即每个 API 被调用了多少次。可以看到下面简化的输入和输出,输入第一条是在某个时间点请求GET 了 /api/a;第二条日志记录了某个时间点 Post /api/b ;第三条是在某个时间点 GET了一个/api/a,总共有 3 个 Nginx 日志。
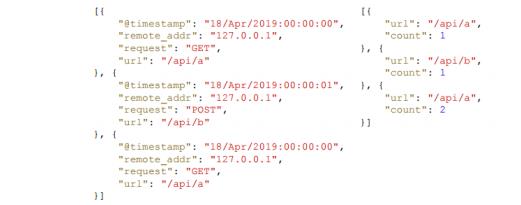
从这 3 条 Nginx 日志可以看出,第一条进来输出 /api/a 被访问了一次,第二条进来输出
/api/b 被访问了一次,紧接着又进来一条访问 api/a,所以 api/a 被访问了 2 次。不同的是,两条 /api/a 的 Nginx 日志进来的数据是一样的,但输出的时候结果可能不同,第一次输出count=1 ,第二次输出 count=2,说明相同输入可能得到不同输出。输出的结果取决于当前请求的 API 地址之前累计被访问过多少次。第一条过来累计是 0 次,count = 1,第二条过来 API 的访问已经有一次了,所以 /api/a 访问累计次数 count=2。单条数据其实仅包含当前这次访问的信息,而不包含所有的信息。要得到这个结果,还需要依赖 API 累计访问的量,即状态。这个计算模式是将数据输入算子中,用来进行各种复杂的计算并输出数据。这个过程中算子会去访问之前存储在里面的状态。另外一方面,它还会把现在的数据对状态的影响实时更新,如果输入 200 条数据,最后输出就是 200 条结果。
未完待续…
以上是关于从0到1Flink的成长之路(二十)-Flink 高级特性之无状态和有状态计算的主要内容,如果未能解决你的问题,请参考以下文章