利用Kafka和Cassandra构建实时异常检测实验
Posted 架构师社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用Kafka和Cassandra构建实时异常检测实验相关的知识,希望对你有一定的参考价值。
导言
异常检测是一种跨行业的方法,用于发现事件流中的异常事件 - 它适用于物联网传感器,财务欺诈检测,安全性,威胁检测,数字广告欺诈以及许多其他应用程序。此类系统检查流数据以检查异常或不规则,并在检测时发送警报以处理这些异常并确定它们是否确实代表安全威胁或其他问题。
检测系统通过将事件与历史模式进行比较来查找流数据中的异常,识别先前分类的异常和与预期显着不同的新事件。执行此检测需要技术堆栈,该技术堆栈利用机器学习,统计分析,算法优化技术和数据层技术来提取,处理,分析,传播和存储流数据。
实际上,为每天可能产生数百万甚至数十亿事件的应用程序创建异常检测系统会带来重大的开发挑战,从异常检测算法必须克服的计算障碍到系统的数据层技术必须满足的性能和可扩展性需求。在Instaclustr,我们最近使用开源 Apache Kafka 和 Apache Cassandra 作为其数据层技术创建了一个纯粹的实验性异常检测应用程序,然后从可伸缩性,性能和可用性分析了该体系结构的有效性。成本效益的立场。
构建异常检测管道
1、事件以流形式到达;
2、从流中获取下一个事件;
3、将事件写入数据库;
4、(数据存储在历史事件数据库中);
5、查询数据库中的历史数据;
6、如果有足够的观测值,请运行异常检测器;
7、如果检测到潜在的异常,请采取适当的措施;
架构与技术决策
Apache Kafka 和 Apache Cassandra 是支持异常检测系统的强大技术选择,原因有很多:它们价格合理,高性能,可扩展,可以无缝协同工作。
Kafka支持快速,线性可扩展的流数据摄取,支持多种异构数据源,数据持久性和设计复制,即使在某些节点发生故障时也能消除数据丢失。Kafka的存储和转发设计还允许它作为缓冲区将易失性外部数据源与Cassandra数据库分开,这样当大数据浪涌发生时,Cassandra不会被淹没,并且数据可以进一步防止丢失。在Kafka中将数据发送到其他地方(例如Cassandra数据库)以及实时连续处理流数据非常简单。以下是Kafka处理负载峰值的示例,允许Cassandra以稳定的速率继续处理事件:
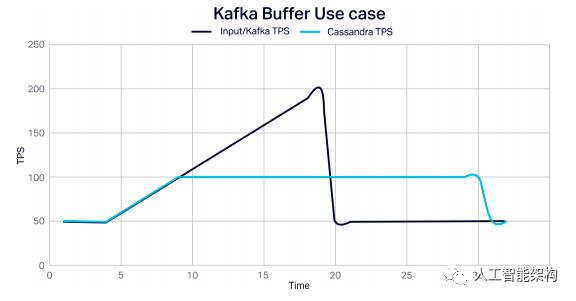
与此同时,Cassandra作为快速存储高速流数据和时间序列数据的强大选择,因为它是针对写入优化的。Cassandra还在重读数据的任务中茁壮成长,因为它支持随机访问查询,虽然使用了复杂的主键,由一个简单的或复合的分区键和零个或多个集群键组成,这些键决定了数据的返回顺序。与Kafka一样,Cassandra还提供线性可扩展性,即使在故障期间也能维护数据。
对于我们的异常检测实验,我们将Kafka,Cassandra和我们的应用程序结合在一个Lambda架构中,Kafka和流管道作为“速度层”,Cassandra作为“批处理”和“服务”层。
我们还尝试使用更简单的Kappa架构,利用Kafka具有不可变数据副本的事实来运行异常检测管道,仅作为Kafka流应用程序。然而,我们发现Kafka只有在连续重放以前的数据时才有效,因为它缺乏索引或支持随机访问查询。这意味着对于大量的ID,消费者在找到匹配的ID之前需要读取大量不相关的记录。不可扩展的替代想法包括为每个ID分配一个分区,或者使用流状态存储来缓存数据 - 这是不切实际的,因为有问题的大数据不能完整地保存在RAM中。因此,我们证明了我们的Lambda架构是必要的,也是最好的方法。
异常检测数据模型和应用程序设计
通过我们的技术选择和架构建立,我们转向实验的数据模型和应用程序设计。
我们的数据模型使用数字<key,value>对,包括在摄取数据时嵌入Kafka元数据中的Kafka时间戳。然后将数据作为时间序列存储在Cassandra中,从而能够有效读取给定键(id)的先前N值(对于我们的实验,50)。数据模型使用复合主键,其中id作为分区键,时间作为聚类键,从而可以按降序检索行数据。
create table event_stream (
id bigint,
time timestamp,
value double,
Primary key (id, time)
) with clustering order by (time desc);
使用以下Cassandra查询,我们可以检索特定键的最后50条记录,然后可以通过检测算法进行处理。
SELECT * from event_stream where limit 50;异常检测应用程序的主要组件包括事件生成器(依赖于Kafka生产者),Kafka集群,异常检测管道和Cassandra集群。

异常检测管道本身包括Kafka使用者(具有自己的线程池)和处理阶段(使用单独的线程池)。对于通过消费者到达的每个事件,Cassandra客户端将事件写入Cassandra,从Cassandra读取历史数据,运行异常检测算法,并决定事件是否具有异常的高风险。应用程序可以通过增加每个组件可用的线程,应用程序实例和服务器资源来进行扩展。
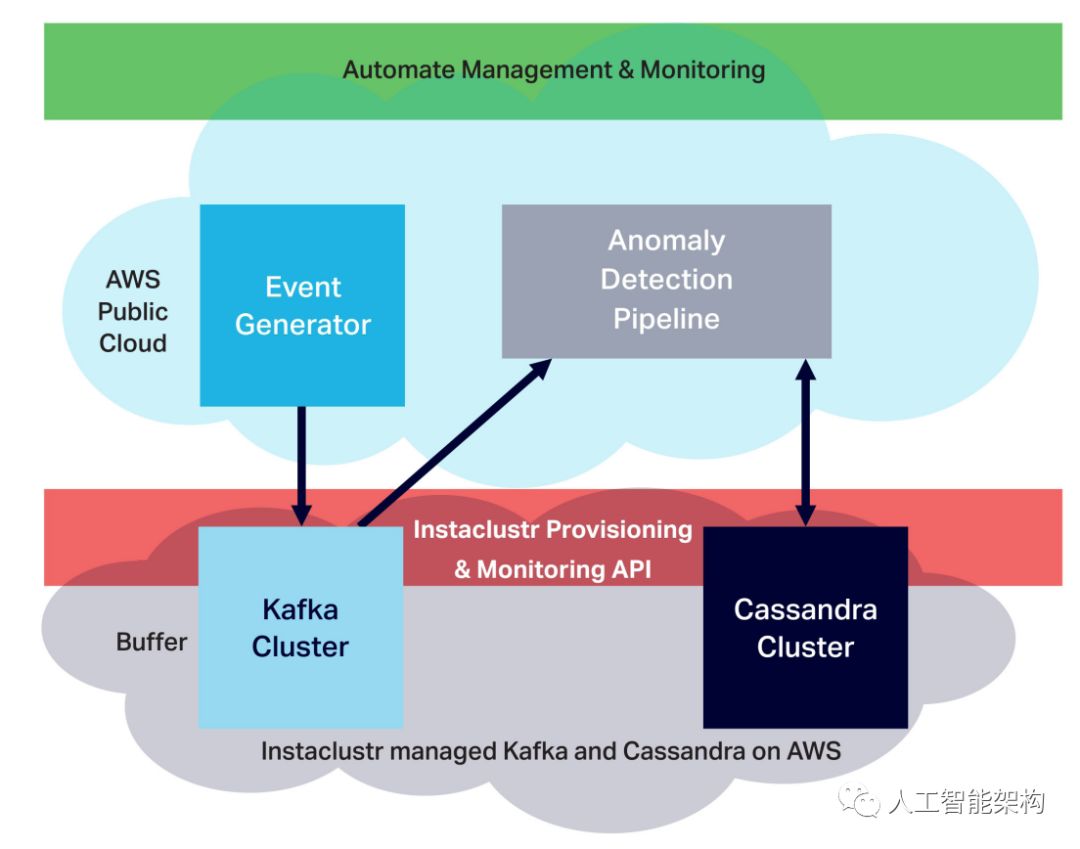
云中的自动化和仪表化
在较高的层面上,我们通过在AWS上的Instaclustr托管平台上构建Kafka和Cassandra集群,将实验部署到云中。这使我们能够快速轻松地创建任何规模的集群(包括任何云提供商,节点类型和数量),并轻松管理其运营并对实验进行全面监控。然后,我们在AWS EKS上使用Kubernetes来自动化应用程序的配置,部署和扩展。为了使应用程序在Kubernetes上运行时可观察 - 为了监视,调试和微调管道的每个阶段,然后报告异常检测应用程序的可伸缩性和性能指标 - 我们使用开源Prometheus进行度量监控和OpenTracing和耶格 用于分布式跟踪。
在Kubernetes上部署生产中的应用程序
使用Kubernetes(AWS EKS)在AWS上部署事件生成器和异常检测管道 - 它带有学习曲线并需要认真努力才能使AWS EKS运行,创建工作节点,并以平稳的方式配置和部署应用程序 - 我们有一个可重复的应用程序可伸缩性过程。我们还可以轻松地更改,重新配置和调整应用程序,并根据需要在尽可能多的Kubernetes Pod中运行它,以满足我们的扩展需求。
Prometheus在Kubernetes集群中运行,使我们能够在浏览器中访问Prometheus Server URL,在那里我们可以查看应用程序生成的完整指标。
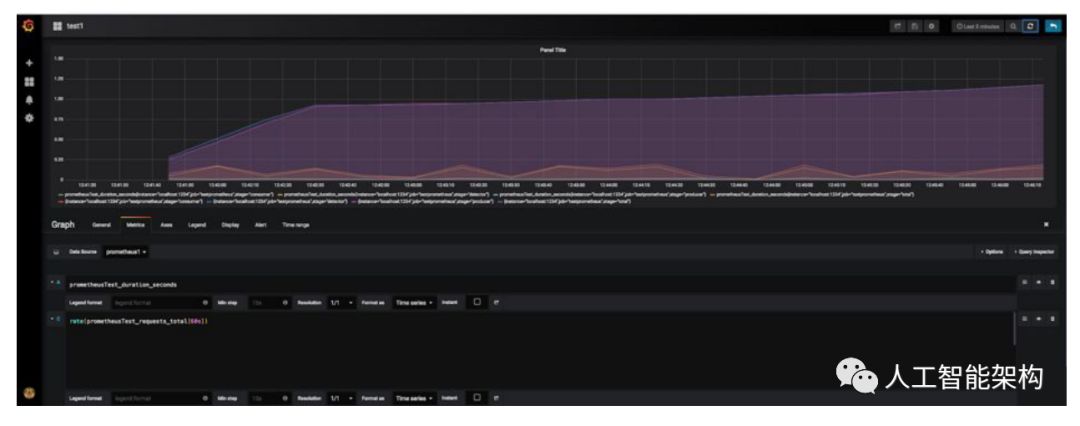
使用这种架构,我们可以通过编写表达式和使用Grafana绘制来自Prometheus的指标(如探测器速率和持续时间)来详细了解应用程序的性能。
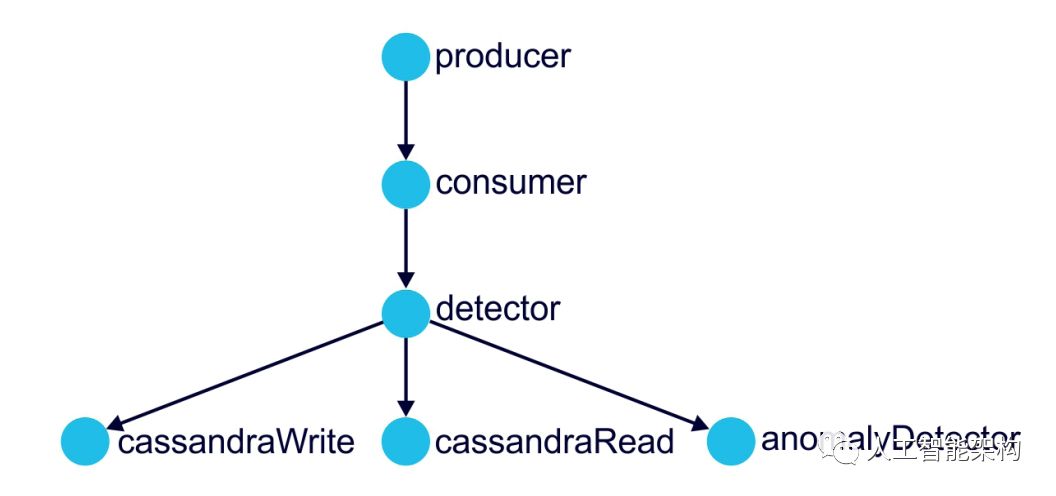
我们还使用OpenTracing对应用程序进行了检测,得到了下面所示的Jaeger依赖关系(进一步的视图详细显示了单个跟踪)。该视图概述了系统的拓扑结构,以及从生产者到消费者的跨流程边界的跟踪。
大规模运行异常检测管道
通过构建和部署异常检测管道,我们将注意力转向确保其可扩展。我们采用缓慢而有效的方法来增加规模,同时监控,调试和微调组件,而不是简单地在大型集群上运行系统,因为我们认识到提高效率的机会。在我们的Prometheus指标的指导下,我们优化了异常检测应用程序和集群,改变了运行应用程序的Pod数量,以及线程池,Kafka消费者和分区以及Cassandra连接 - 随着Kafka和Cassandra集群规模的增加,性能最大化通过其他节点。例如,我们发现通过将Kafka分区和Cassandra连接的数量保持在最小值,我们可以通过增加Pod来优化吞吐量。
使用托管的Cassandra集群,可以轻松添加额外的节点。因此,可以逐步增加簇大小,开发适当的调整方法,并实现近线性可伸缩性。随着总核心数量的增加,下图显示具有接近线性的可扩展性。
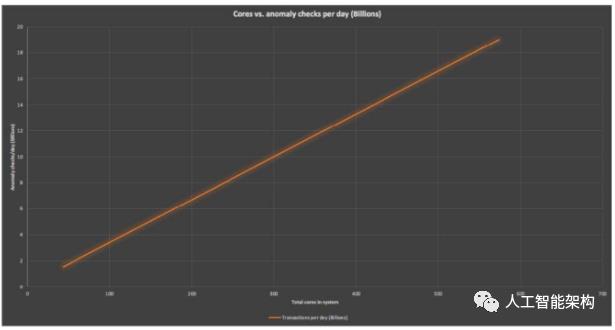
最终的实验结果
考虑到Kafka充当保护Cassandra免受事件负载峰值影响的缓冲区的用例,我们的目标是让Kafka集群能够在几分钟内每秒处理至少200万次写入。同时,异常检测管道的其余部分需要扩展到其最大容量,以便尽可能快地处理事件积压,而不会受到事件负载峰值的阻碍。
在我们的初始测试中,当使用具有9个节点和每个节点8个CPU核心的Kafka群集时,9个Kafka生产者Pod足以实现每秒超过200万次写入,具有200个分区。
当使用大型集群来实现我们最实际的结果时,我们使用了具有这些规范的集群(所有集群都在AWS,美国东北弗吉尼亚州运行):
Instaclustr管理的Kafka集群 - EBS:高吞吐量1500 9 x r4.2xlarge-1500(1,500 GB磁盘,61 GB RAM,8个内核),Apache Kafka 2.1.0,复制
Instaclustr管理的Cassandra集群 - 超大型,48 x i3.2xlarge(1769 GB(SSD),61 GB RAM,8个内核),Apache Cassandra 3.11.3,复制
AWS EKS Kubernetes集群工作节点 - 2 x c5.18xlarge(72核,144 GB RAM,25 Gbps网络),Kubernetes版本1.10,平台版本eks.3
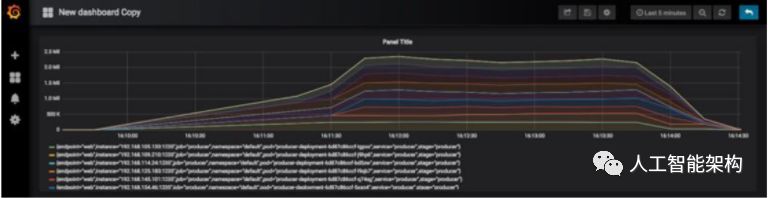
下面堆叠的Grafana图显示了Prometheus指标,显示Kafka生产商从一个Kubernetes Pods升级到9个Kubernetes Pods,加载时间为两分钟,并且每秒处理230万个事件达到峰值。
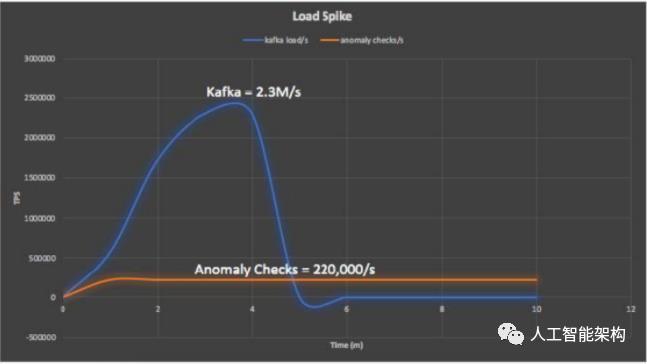
下图显示异常检查率达到每秒可持续的220,000个事件,并继续运行直到处理完所有事件。在这种情况下,异常检测应用程序在100 Kubernetes Pods上运行。

总之,Kafka达到了每秒230万次写入的峰值,其余的管道每秒可执行220,000次异常检查。这相当于每天进行了大量的190亿次异常检查。
异常检测系统使用574个核心,384个Cassandra核心,118个Kubernetes集群工作核心和72个Kafka核心。109个应用程序Pod(用于Kafka生产者和检测管道)在Kubernetes集群上运行,还有一些Prometheus Pods。总计,系统每核心每秒处理400次异常检查。
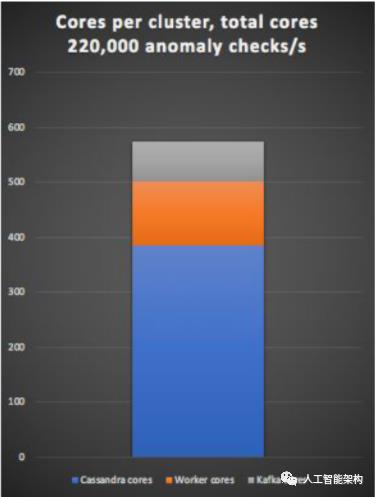
虽然Kafka集群的事件负载能力是Cassandra集群的十倍(每秒230万,而每秒220,000),但Cassandra集群的规模是Kafka集群规模的五倍多。因此,采用Kafka作为缓冲区来处理负载峰值的方法显然更为实际,而不是将Cassandra集群中的节点数量增加10倍。
将此实验与其他实验进行比较,去年发布的类似系统使用240个核心达到每秒200次异常检查。该系统使用监督异常检测,需要每日一次的分类器培训,开发团队使用Apache Spark进行机器学习,特征工程和分类,以及Kafka和Cassandra。
通过调整为每个系统供电的不同资源,我们的经验实现了大约500倍的吞吐量以及更快的实时延迟。由于其功能工程阶段,另一个系统还具有更多开销,并且Apache Spark的使用增加了长达200秒的延迟,因此无法实时提供异常检测。
相比之下,我们的实验确实提供了实时异常检测和阻塞,检测延迟平均仅为500毫秒。如果输入负载超过管道容量,则处理时间确实增加,从而提高了检测异常需要通过其他方法解决的可能性(例如冻结完整帐户并在必要时联系客户)。
经济高效,可扩展的异常检测
通过这种异常检测实验能够轻松扩展并每天处理190亿个事件,它完全能够满足大型企业的需求(当然,如果它是一个上市解决方案 - 它不是)。从价格角度来看,使用按需AWS实例运行系统的成本为每天1000美元 - 因此只需1美元,就可以对1900万个事件进行异常检查。
企业的总成本还需要考虑异常检测应用程序的开发,以及持续维护,管理服务成本和其他相关费用。由于系统易于扩展和缩小,因此可轻松安装以满足企业的特定业务需求,总体基础架构成本也按比例缩放(例如,在我们的实验检查器中测试的最小系统每天15亿个事件,AWS基础设施成本每天约100美元)。
长按订阅更多精彩▼
如有收获,点个在看,诚挚感谢
以上是关于利用Kafka和Cassandra构建实时异常检测实验的主要内容,如果未能解决你的问题,请参考以下文章