Apache Flink:使用Apache Kafka作为DataSource的简单demo
Posted 你是小KS
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Flink:使用Apache Kafka作为DataSource的简单demo相关的知识,希望对你有一定的参考价值。
1. 声明
当前内容主要为测试和使用Apache Kafka作为Flink的DataSource的最基本的demo
其中使用kafka发送消息的参考:博文
当前内容为
- 使用Apache Flink接收Kafka的topic中的消息作为DataSource
- 简单的print当前接收的消息
2. 基本pom依赖
核心为:flink-connector-kafka_2.12
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.13.0</flink.version>
<target.java.version>1.8</target.java.version>
<scala.binary.version>2.11</scala.binary.version>
<maven.compiler.source>${target.java.version}</maven.compiler.source>
<maven.compiler.target>${target.java.version}</maven.compiler.target>
<log4j.version>2.12.1</log4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-walkthrough-common_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- This dependency is provided, because it should not be packaged into
the JAR file. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope> -->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope> -->
</dependency>
<!-- Add connector dependencies here. They must be in the default scope
(compile). -->
<!-- 直接导入需要的flink到kafka的连接器 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
</dependencies>
3. 基本的demo
这里订阅的topic为test-events(只用设置这个即可)
import java.util.Properties;
import org.apache.flink.api.common.JobExecutionResult;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
/**
*
* @author hy
* @createTime 2021-05-23 10:38:40
* @description 当前内容主要为测试和使用当前的Kafka作为Flink的数据源,开始接受来自Kafka的数据
*
*/
public class LocalRunningKafkaDataSourceTest {
public static void main(String[] args) {
// 采用本地模式
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
// 设定数据来源为集合数据
String topic = "test-events"; //设置监听的主题
Properties props = new Properties();
props.setProperty("bootstrap.servers", "192.168.1.101:9092");
props.setProperty("group.id", "test");
DataStream<String> kafkaStream = env
.addSource(new FlinkKafkaConsumer<String>(topic, new SimpleStringSchema(), props));
kafkaStream.print();
try {
// 最后开始执行
JobExecutionResult result = env.execute("Fraud Detection");
if (result.isJobExecutionResult()) {
System.out.println("执行完毕......");
}
System.out.println();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
4. 测试
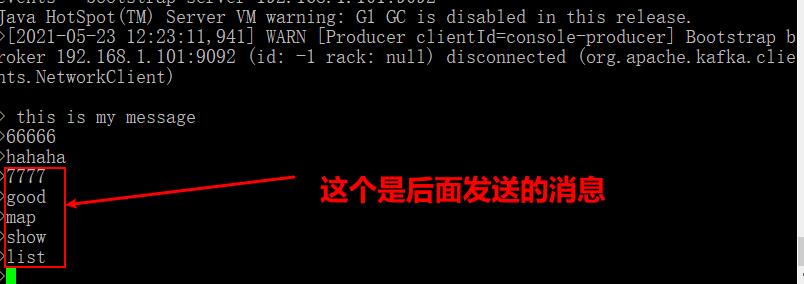
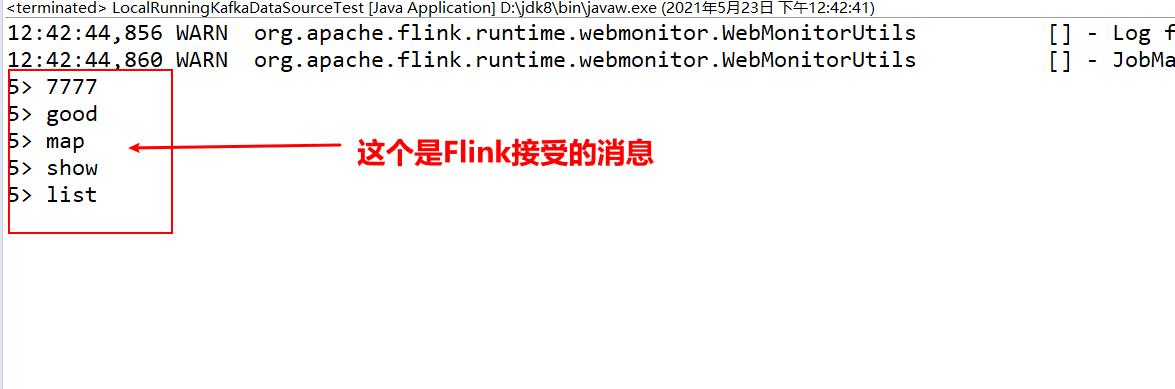
上面的部分发送有的是测试了kafka的自己接受消息的没有关,后面追加的才是对的(没有数据丢失的问题)
以上是关于Apache Flink:使用Apache Kafka作为DataSource的简单demo的主要内容,如果未能解决你的问题,请参考以下文章