Apache Flink:使用countWindow(按照间隔步数统计)和window(按照间隔时间统计)
Posted 你是小KS
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Flink:使用countWindow(按照间隔步数统计)和window(按照间隔时间统计)相关的知识,希望对你有一定的参考价值。
1.声明
当前内容主要为本人学习和使用Flink,主要为window的一些操作,当前内容主要借鉴:官方GitHub的Demo和官方开发文档
内容主要为:
- 编写指定间隔步数内的最大温度显示(使用countWindow)
- 编写指定间隔时间内的最大温度显示(使用window)
- 分析两个的区别
- 分析类的区别
- 使用Flink本地模式
基本pom依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.13.0</flink.version>
<target.java.version>1.8</target.java.version>
<scala.binary.version>2.11</scala.binary.version>
<maven.compiler.source>${target.java.version}</maven.compiler.source>
<maven.compiler.target>${target.java.version}</maven.compiler.target>
<log4j.version>2.12.1</log4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-walkthrough-common_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- This dependency is provided, because it should not be packaged into
the JAR file. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope> -->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope> -->
</dependency>
<!-- Add connector dependencies here. They must be in the default scope
(compile). -->
<!-- 直接导入需要的flink到kafka的连接器 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.13.0</version>
</dependency>
<!-- These dependencies are excluded from the application JAR by default. -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
</dependencies>
2.数据源准备(采用无限流,来自随机数的数据)
1.创建实体类:电脑温度类
/**
*
* @author hy
* @createTime 2021-06-05 12:34:11
* @description 一个电脑温度的实体类
*
*/
public class ComputerTemperature {
private String name;// 电脑名称
private Double temperature; // 电脑温度
private long timestamp; // 电脑温度的时间错
// 省略get、set、toString、无参有参构造函数
}
2.创建Flink的DataSource
/**
*
* @author hy
* @createTime 2021-05-16 09:52:36
* @description 生成一个随机数的资源
*
*/
public class RandomComputerTemperatureSource extends FromIteratorFunction<ComputerTemperature> {
/**
*
*/
private static final long serialVersionUID = 1L;
public RandomComputerTemperatureSource(long sleepTime) {
super(new RandomComputerTemperatureIterator(sleepTime));
// TODO Auto-generated constructor stub
}
private static class RandomComputerTemperatureIterator implements Iterator<ComputerTemperature>, Serializable {
/**
*
*/
private static final long serialVersionUID = 1L;
private final long sleepTime;
private String[] computerNames = { "电脑1", "电脑2", "电脑3" };
private RandomComputerTemperatureIterator(long sleepTime) {
this.sleepTime = sleepTime;
}
@Override
public boolean hasNext() {
return true;
}
@Override
public ComputerTemperature next() {
// 默认休眠时间为1秒钟
try {
Thread.sleep(sleepTime);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
Double temperature = Math.random() * 100 + 1;
int index = (int) (Math.random() * computerNames.length);
long timestamp = new Date().getTime();
ComputerTemperature computerTemperature = new ComputerTemperature(computerNames[index], temperature,timestamp);
//StreamRecord<ComputerTemperature> streamRecord = new StreamRecord<ComputerTemperature>(computerTemperature,timestamp);
return computerTemperature;
}
}
}
主要为创建一个随机温度数,这个主要用于模拟工业传感器
3.编写countWindow(按照指定数量统计)
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;
import org.apache.flink.util.Collector;
import com.hy.flink.test.pojo.ComputerTemperature;
import com.hy.flink.test.source.RandomComputerTemperatureSource;
/**
*
* @author hy
* @createTime 2021-06-05 17:21:07
* @description 当前内容主要为测试和使用当前的countWindows,即当数据量达到指定的时候才会触发的函数,实现5次数据中的最大值温度
*
*/
public class CountWindowsTest {
public static void main(String[] args) throws Exception {
// 设置当前的环境为本地环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
// 设置数据来源为随机数方式的数据
DataStream<ComputerTemperature> dataStream = env.addSource(new RandomComputerTemperatureSource(1000));
// 将数据按照当前的名称进行分组操作,然后每5个统计一次,使用MyHandler进行统计操作
SingleOutputStreamOperator<Tuple3<String, Long, Double>> process = dataStream
.keyBy(x -> x.getName())
.countWindow(5l).process(new MyHandler());
// print the results with a single thread, rather than in parallel
// 打印结果并使用单个线程的方式,而不是平行计算
process.print().setParallelism(1);
env.execute("开始执行统计每个电脑的5次温度中的温度最大值");
}
// 这里是处理到达的5条的数据
static class MyHandler extends ProcessWindowFunction<ComputerTemperature, // 输入类型
Tuple3<String, Long, Double>, // 输出类型
String, // 键类型
GlobalWindow> {
@Override
public void process(String key,
ProcessWindowFunction<ComputerTemperature, Tuple3<String, Long, Double>, String, GlobalWindow>.Context context,
Iterable<ComputerTemperature> events, Collector<Tuple3<String, Long, Double>> out) throws Exception {
// TODO Auto-generated method stub
Double max = 0.0;
long time=0L;
// 这里为打印数据,显示5条汇总数据
System.out.println("开始处理数据.........");
events.forEach(x->System.out.println(x));
for (ComputerTemperature event : events) {
Double temperature = event.getTemperature();
if(temperature>max) {
max=temperature;
time=event.getTimestamp();
}
}
// 主要收集最大值的数据
out.collect(Tuple3.of(key, time, max));
}
}
}
其实就是按照ountWindow(5l)中的5来执行统计,即到达5个就开始执行后面的函数操作,未到达就等待
其中setParallelism就是设置平行执行数量,1个就是单线程执行,2个以上就是多线程执行
4.编写window(按照时间间隔方式统计)
/**
*
* @author hy
* @createTime 2021-06-05 17:21:07
* @description 当前内容主要为测试和使用官方的测试,使用window,每5秒执行一次统计的操作
*
*/
public class OfficeWindowsTest {
public static void main(String[] args) throws Exception {
// 设置当前的环境为本地环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
// 设置数据来源为随机数方式的数据
DataStream<ComputerTemperature> dataStream = env.addSource(new RandomComputerTemperatureSource(1000));
// 将数据按照当前的名称进行分组操作,然后每5秒统计一次,使用MyHandler进行统计操作
SingleOutputStreamOperator<Tuple3<String, Long, Double>> process = dataStream
.keyBy(x -> x.getName())
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.process(new MyHandler());
// print the results with a single thread, rather than in parallel
// 打印结果并使用单个线程的方式,采用并行计算,不管当前的是否有数据,都开始统计
process.print().setParallelism(3);
env.execute("开始执行统计5秒内每个电脑的最大温度");
}
//
static class MyHandler
extends ProcessWindowFunction<ComputerTemperature, Tuple3<String, Long, Double>, String, TimeWindow> {
@Override
public void process(String key,
ProcessWindowFunction<ComputerTemperature, Tuple3<String, Long, Double>, String, TimeWindow>.Context context,
Iterable<ComputerTemperature> events, Collector<Tuple3<String, Long, Double>> out) throws Exception {
// TODO Auto-generated method stub
Double max = 0.0;
long time = 0L;
// 这里为打印数据,显示5条汇总数据
System.out.println("开始处理数据.........");
events.forEach(x -> System.out.println(x));
for (ComputerTemperature event : events) {
Double temperature = event.getTemperature();
if (temperature > max) {
max = temperature;
time = event.getTimestamp();
}
}
// 主要收集最大值的数据
out.collect(Tuple3.of(key, time, max));
}
}
}
其实这里的MyHandler只有细微的差别,但是处理方式是使用window并且制定了处理间隔时间(每隔5秒就处理一次)
5.测试
1.测试countWindow的demo
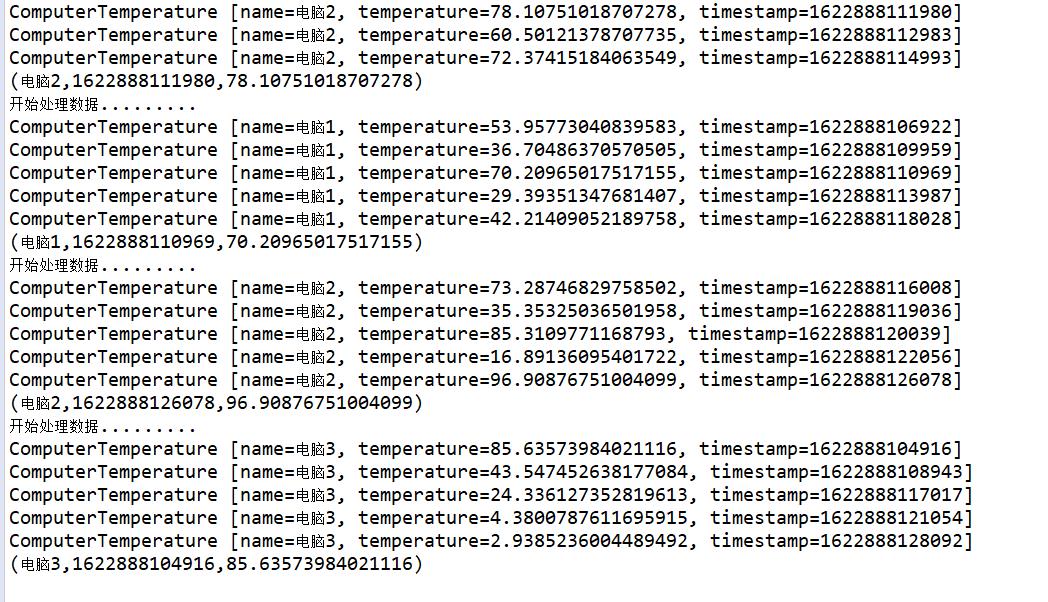
这里可看到,只有keyBy的数量达到5个的时候才会执行操作,所以每次显示的都是5个,并且执行获取最大温度的操作,并且当前的线程控制为1
2.测试window的demo
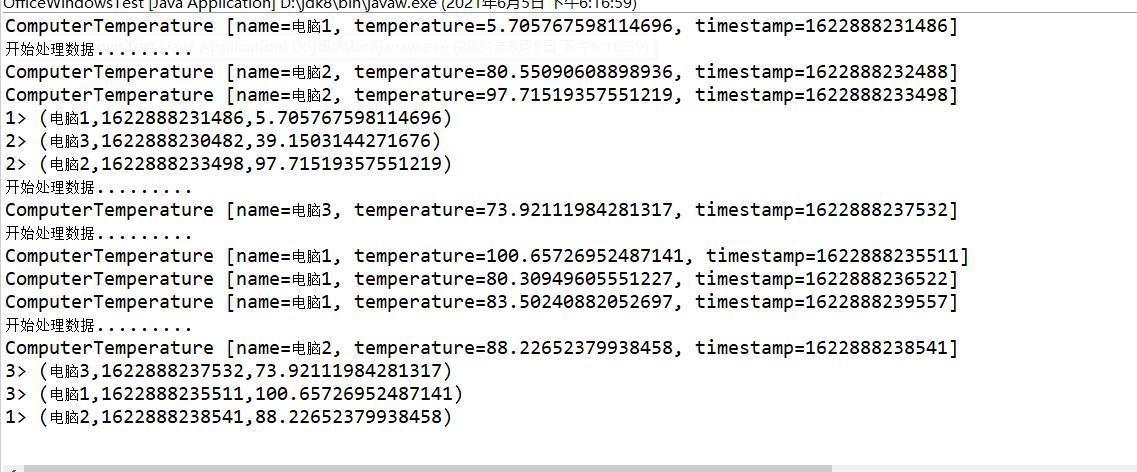
通过观察发现,当前的数量中,可以发现同时处理的为3个。对应上面的设置,且只有5秒的时间到达的时候才会打印数据,控制时间间隔
6.查看两个的区别
1.主要区别在于一个是countWindow(步数)、一个是window(时间间隔)
2.具体函数MyHandler的区别为
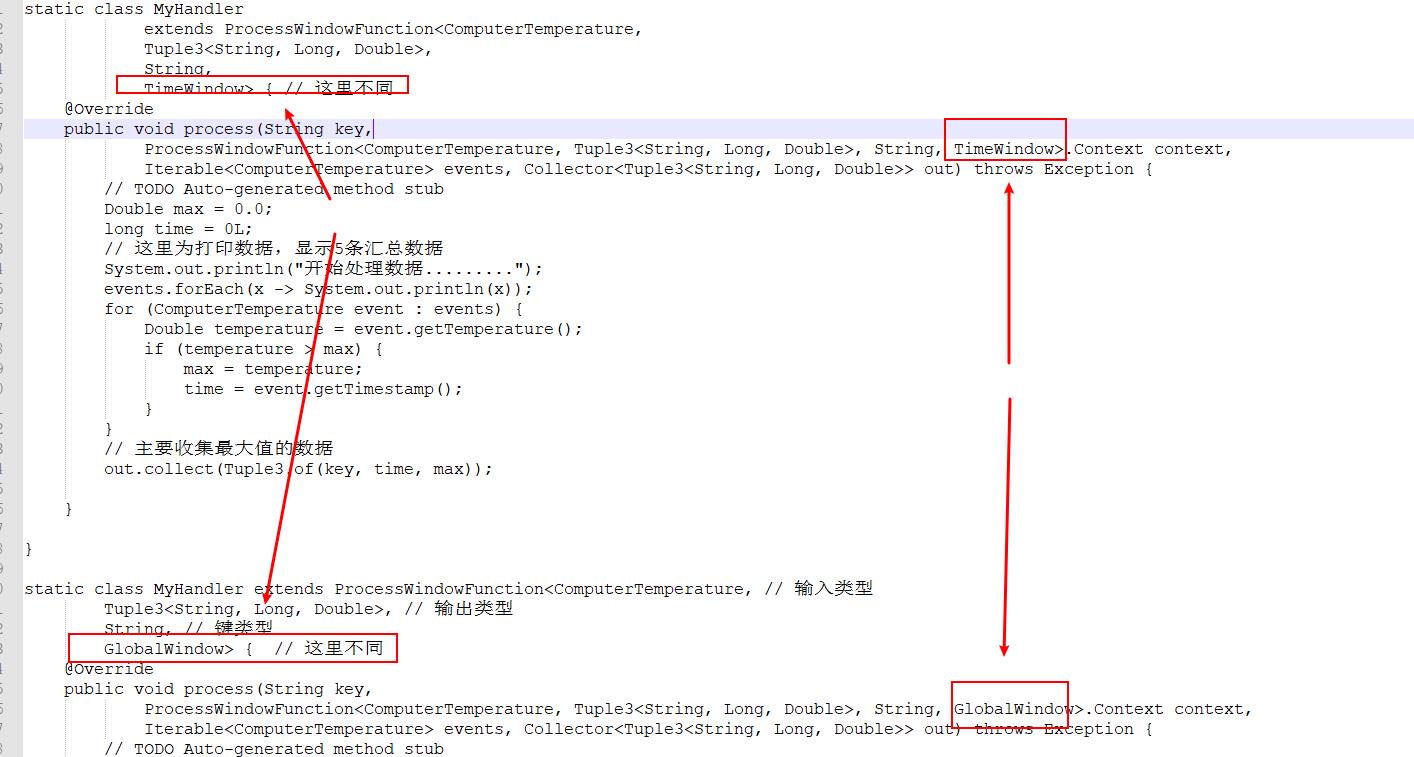
这个差异也是有countWindow和window产生的差异,其实函数体都是一样的
7.总结
1.Flink中的countWindow是按照间隔步数方式操作数据,而window是按照时间间隔统计数据
2.一般工业中的传感器都是统计时间间隔的
以上是关于Apache Flink:使用countWindow(按照间隔步数统计)和window(按照间隔时间统计)的主要内容,如果未能解决你的问题,请参考以下文章