Apache Flink:测试使用reduce增量聚合和windowAll操作
Posted 你是小KS
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Flink:测试使用reduce增量聚合和windowAll操作相关的知识,希望对你有一定的参考价值。
1.声明
当前内容主要为测试和使用Apache Flink中的增量聚合操作,当前内容主要借鉴:Flink官方文档
主要内容有
- 使用Flink的增量聚合
- 分析增量聚合操作
- windowAll操作
pom依赖:参考前面的文章
2.增量聚合操作的demo
数据源参考前面博文中的ComputerTemperature这个实体类
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import com.hy.flink.test.pojo.ComputerTemperature;
import com.hy.flink.test.source.RandomComputerTemperatureSource;
/**
*
* @author hy
* @createTime 2021-06-06 08:22:07
* @description 当前内容主要为使用和测试Apache Flink中的增量聚合的操作,先window操作在reduce操作
*
*/
public class ReduceAndWindowTest {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
// 设定数据来源为当前的随机产生的数据,且数据来源
DataStream<ComputerTemperature> streams = env.addSource(new RandomComputerTemperatureSource(500))
.name("computer temperature streams");
SingleOutputStreamOperator<ComputerTemperature> process = streams.keyBy(x -> x.getName())
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce(new MyReduceHandler(), new MyWindowHandler());
// 这里处理所有的数据
process.print().setParallelism(3); // 输出实际的结果
// 最后开始执行
try {
env.execute("Fraud Detection");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
*
* @author hy
* @createTime 2021-06-06 08:25:51
* @description 直接获取当前的最大温度的电脑
*
*/
static class MyReduceHandler implements ReduceFunction<ComputerTemperature> {
public ComputerTemperature reduce(ComputerTemperature r1, ComputerTemperature r2) {
System.out.println("reduce handler .............");
System.out.println("r1==>" + r1 + ",r2==>" + r2);
return r1.getTemperature() > r2.getTemperature() ? r1 : r2;
}
}
// 上面的reduce处理后这里就只剩下一个最大的值了,这里主要是判断是否需要收集数据的操作
static class MyWindowHandler extends ProcessWindowFunction<ComputerTemperature, ComputerTemperature, String, TimeWindow> {
@Override
public void process(String key,
ProcessWindowFunction<ComputerTemperature, ComputerTemperature, String, TimeWindow>.Context context,
Iterable<ComputerTemperature> events, Collector<ComputerTemperature> out) throws Exception {
// TODO Auto-generated method stub
// 这里打印数据,但是由于前面的reduce已经处理了当前传递的数据,这里传递的只有一个数据
System.out.println("开始处理数据.........");
events.forEach(x -> System.out.println(x));
// 主要收集最大值的数据
out.collect(events.iterator().next());
}
}
}
当前主要为reduce中使用了两个类实例:ReduceFunction和ProcessWindowFunction
1.MyReduceHandler主要返回一个实例,这个应该就是比较后的实例,将结果传递给后面的windowHandler
2.MyWindowHandler主要就是处理或者收集需要的实例
3.测试
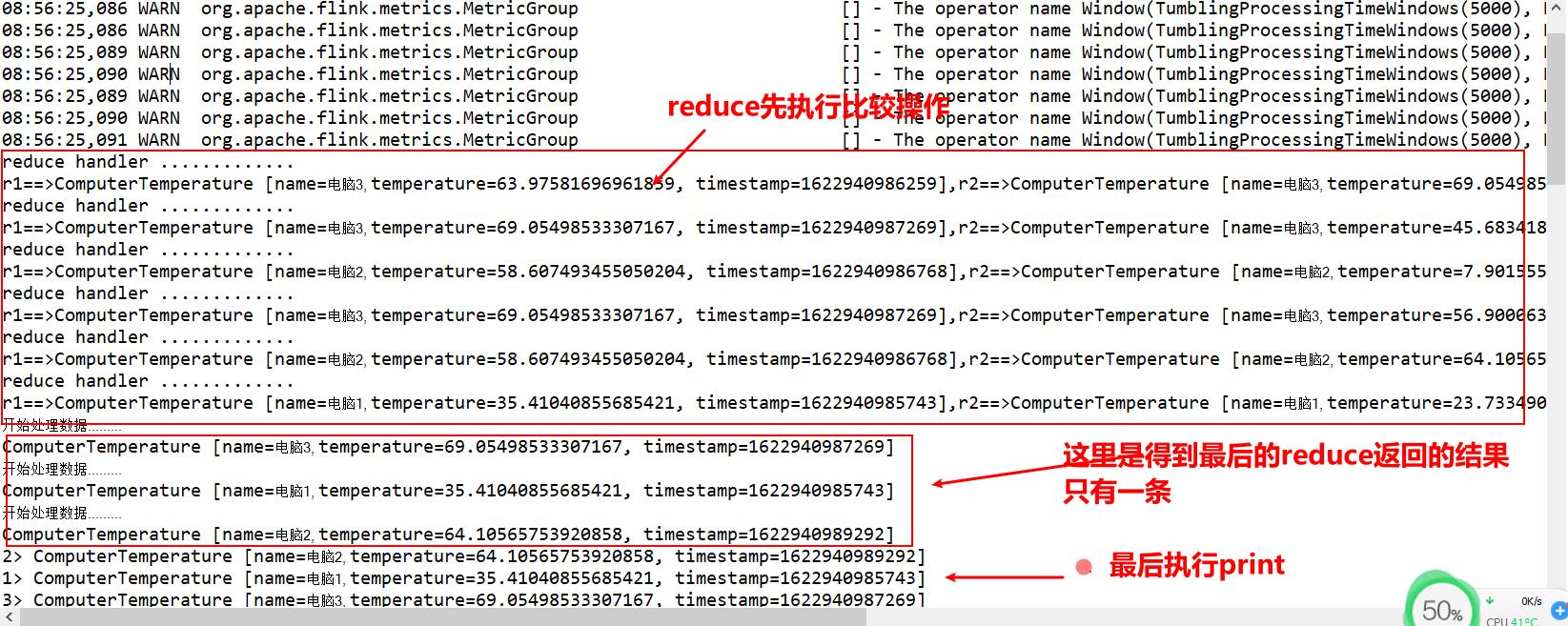
所以reduce就是处理获得一个结果,加了keyBy,就会产生分组操作,最后只会返回一个结果,这个结果将放在window中进行处理,window中才是收集数据的地方
对比官方解释

测试成功
4.windowAll操作
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessAllWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import com.hy.flink.test.pojo.ComputerTemperature;
import com.hy.flink.test.source.RandomComputerTemperatureSource;
/**
*
* @author hy
* @createTime 2021-06-03 15:55:44
* @description 当前内容主要为使用当前的Apache Flink 的windowAll的功能,查看该功能的与其他功能的区别
* windowAll 主要就是提供一个将数据合并一起的执行操作,比如当前的demo就是用于统计5秒内那个电脑的温度最大最小值平均值,直接收集起来
*
*/
public class WindowAllCountTest {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
// 设定数据来源为当前的随机产生的数据,且数据来源
DataStream<ComputerTemperature> streams = env.addSource(new RandomComputerTemperatureSource(1000))
.name("computer temperature streams");
SingleOutputStreamOperator<MyResultBean> process = streams
// windowAll不支持keyBy的分组方式
.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.process(new MyCollectorHandler());
// 这里处理所有的数据
process.print(); // 输出实际的结果
// 最后开始执行
try {
env.execute("Fraud Detection");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
static class MyResultBean {
private Tuple3<String, Long, Double> min;
private Tuple3<String, Long, Double> max;
private Double avg; // 平均值
// 省略get\\set\\toString\\无参有参构造函数
}
// 获取最大值最小值和平均值
static class MyCollectorHandler
extends ProcessAllWindowFunction<ComputerTemperature, MyResultBean, TimeWindow> {
@Override
public void process(ProcessAllWindowFunction<ComputerTemperature, MyResultBean, TimeWindow>.Context context,
Iterable<ComputerTemperature> events, Collector<MyResultBean> out) throws Exception {
// TODO Auto-generated method stub
Double max = 0.0;
int comCount = 0;
Double sum = 0.0;
long maxTime = 0L;
String maxKey=null;
String minKey=null;
long minTime = 0L;
// 这里为打印数据,显示5条汇总数据
System.out.println("开始处理数据.........");
events.forEach(x -> System.out.println(x));
for (ComputerTemperature event : events) {
Double temperature = event.getTemperature();
if (temperature > max) {
max = temperature;
maxTime = event.getTimestamp();
maxKey=event.getName();
}
sum += temperature;
comCount++;
}
Double min = max;
for (ComputerTemperature event : events) {
Double temperature = event.getTemperature();
if (temperature < min) {
min = temperature;
minTime = event.getTimestamp();
minKey=event.getName();
}
}
Tuple3<String, Long, Double> maxComputer = Tuple3.of(maxKey, maxTime, max);
Tuple3<String, Long, Double> minComputer = Tuple3.of(minKey, minTime, min);
Double avg = sum / comCount;
// 主要收集最大值的数据
out.collect(new MyResultBean(minComputer, maxComputer, avg));
}
}
}
主要获取所有电脑在5秒内的最大值温度,最小值温度,平均温度,并显示该电脑名称,主要用于所有产生的数据的操作,不进行分组操作
测试结果
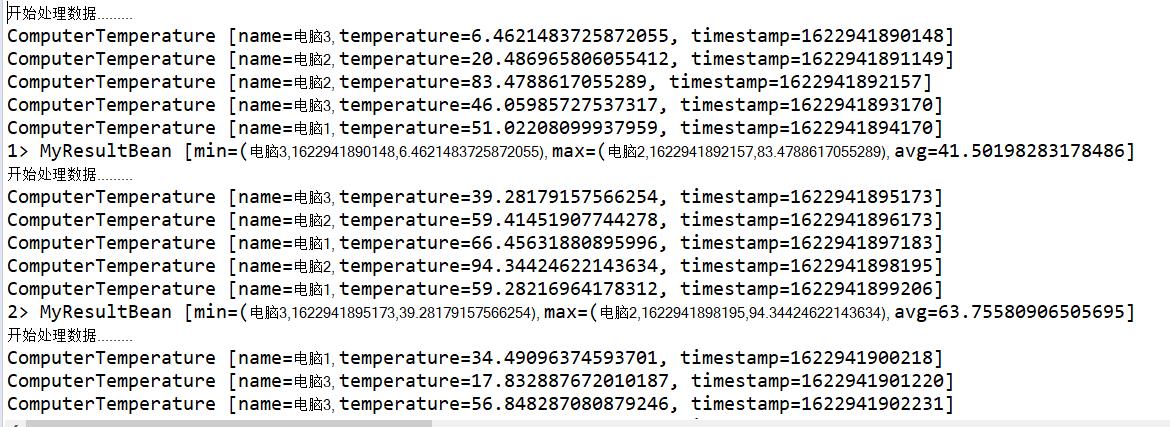
5.总结
1.reduce的增量聚合操作就是先执行reduceFunction获得最终的一个结果,最后将其交给windowFunction进行处理收集操作
2.windowAll的操作就是将所有数据全部一起处理,可以按照时间间隔方式处理数据,没有keyBy
以上是关于Apache Flink:测试使用reduce增量聚合和windowAll操作的主要内容,如果未能解决你的问题,请参考以下文章