ConditionalGAN(CGAN)介绍及实现图像转图像生成应用
Posted 康x呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ConditionalGAN(CGAN)介绍及实现图像转图像生成应用相关的知识,希望对你有一定的参考价值。
ConditionalGAN(CGAN)介绍及实现图像转图像生成应用
一.引言
1.1文字生成图像

下图是传统监督学习文字生成图像的示意图:

存在的问题:输出较多,且神经网络只能给出一中模糊的结果,给不出一个具体的结果及自己真正想生成的效果。接下来具体给出CGAN的解决方法
二.Conditional GAN
2.1Conditional GAN生成器
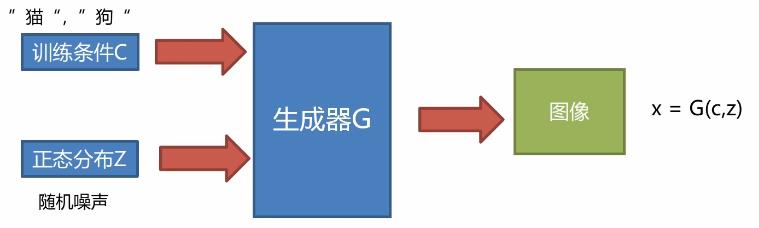
与传统的GAN的不同之处在于,CGAN的输入有两部分,一部分是随机噪声分布,另外一部分是条件标签输入。
2.1Conditional GAN判别器
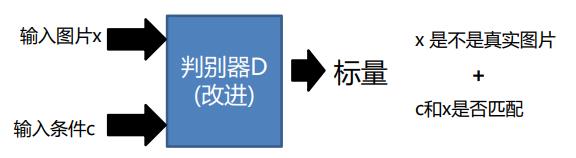
对于输入图像X,可能是生成的也可能是伪造的,然后将标签C也同时输入。输出一个标量,可以判断x是不是真实的图片或者C和X是否匹配。
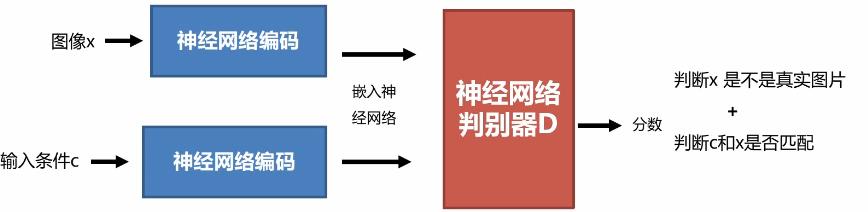
2.2Conditional GAN判别器结构
大多数论文采用的判别器架构如下:
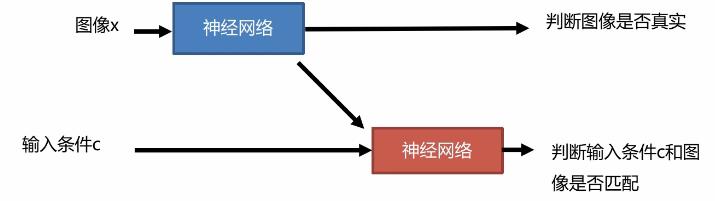
其他判别器架构:
三.StackGAN
StackGAN的结构如下图:
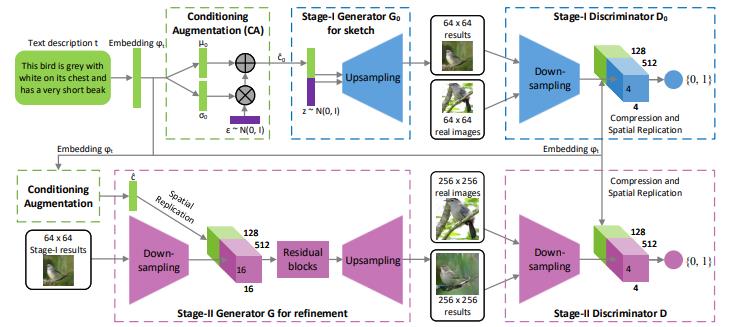
CGAN可以生成带有条件的图像,但是图像精度很低,我们如果希望我们的精度更高一些,因此使用StackGAN可以更好的解决这个问题。我们先将条件跟随机噪声放入生成器,进行一个上采样操作,也就是一个逐步变大的卷积网络中。然后再将生成的伪造的64×64的图片跟真实的图像放入判别器中,进行一个逐步缩小的卷积网络中,上述操作跟传统的CGAN操作基本是一样的,紧接着我们将生成的图像作为条件与64×64的图像一并作为输入再放入到另外一个生成器中,进行放小然后放大,最终生成一个256×256的图像然后进行判别。
核心思想:想要生成高精度的图像,使用两阶段的对抗学习模型,先生成低精度图像,再逐步生成高精度图像。
四.PatchGAN
想要生成高精度图像我们也可以使用PatchGAN,就是对高精度图片进行裁剪,输入图片局部进行逐步生成,PatchGAN并不神秘,其只是一个全卷积网络而已,只是最终输出是一个特征图X,而非一个实数.它就相当于对图像先进行若干次70x70的随机剪裁,将剪裁后图像输入判别器,然后对所有输出的实数值取平均。
五.图像转图像的应用
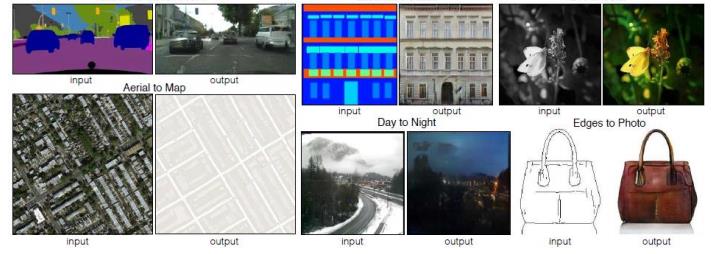
5.1图像转图像简介

与文字生成图像类似,只是将条件换做是图片即可。类似于下图可应用用如下场景:
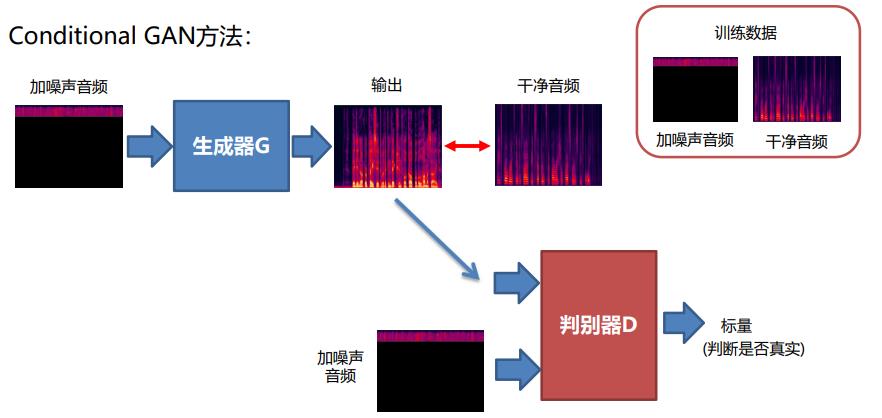
5.1语音增强
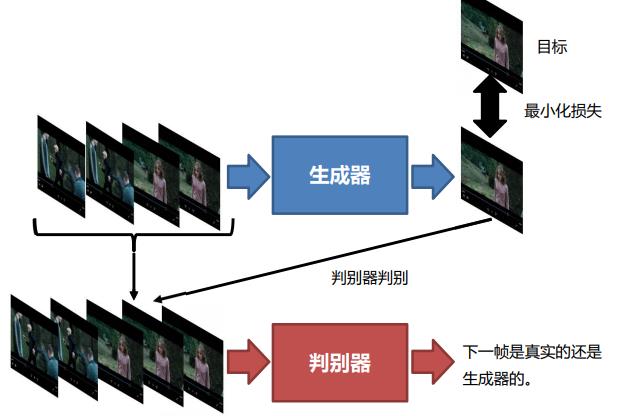
5.2 视频生成
六.可控数字图像生成应用及代码编写
6.1可控数字图像生成具体代码
// An highlighted block
import tensorflow as tf
import numpy as np
import time
import os
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import DataHandler as dh
class CGAN_MNIST(object):
def __init__(self, noise_dim=10, img_h=32, img_w=32, img_c=1, lr=0.0004):
"""
初始化CGAN对象
:param noise_dim:随机噪声维度
:param img_h: 图像高度
:param img_w: 图像宽度
:param img_c: 图像深度
:param lr: 学习
"""
self.noise_dim = noise_dim
self.img_h = img_h
self.img_w = img_w
self.img_c = img_c
self.lr = lr
self.d_dim = 1
self.label = tf.placeholder(dtype=tf.float32, shape=[None, 10])
self.isTrain = tf.placeholder(dtype=tf.bool)
self.gen_x = tf.placeholder(dtype=tf.float32, shape=[None, 1, 1, self.noise_dim])
self.gen_out = self._init_generator(input=self.gen_x, label=self.label, istrain=self.isTrain) # 生成数据
self.gen_logis = self._init_discriminator(input=self.gen_out, label=self.label, isTrain=self.isTrain)
self.x = tf.placeholder(dtype=tf.float32, shape=[None, self.img_w, self.img_h, self.img_c], name="input_data")
self.real_logis = self._init_discriminator(input=self.x, label=self.label, isTrain=self.isTrain, reuse=True)
self._init_train_methods()
def _init_discriminator(self, input, label, isTrain=True, reuse=False):
"""
初始化判别器
:param input:输入数据op
:param label: 输入数据标签
:param isTrain: 是否训练状态
:param reuse: 是否复用内部参数
:return: 判断结果
"""
with tf.variable_scope("discriminator", reuse=reuse):
# hidden layer 1 input=[None,32,32,1]
labels = tf.reshape(label, shape=[-1, 1, 1, 10])
data_sum = tf.shape(input=input)[0]
la = labels * tf.ones([data_sum, self.img_w, self.img_h, 10])
input = tf.concat([input, la], axis=3)
conv1 = tf.layers.conv2d(input, 32, [4, 4], strides=[2, 2], padding="same")
active1 = tf.nn.leaky_relu(conv1) #[none,16,16,32]
# layer 2
conv2 = tf.layers.conv2d(active1, 64, [4, 4], strides=[2, 2], padding="same")
bn2 = tf.layers.batch_normalization(conv2,training=isTrain)#[none,8,8,64]
active2 = tf.nn.leaky_relu(bn2)#[none,8,8,64]
# layer 3
conv3 = tf.layers.conv2d(active2, 128, [4, 4], strides=[2, 2], padding="same")
bn3 = tf.layers.batch_normalization(conv3,training=isTrain)
active3 = tf.nn.leaky_relu(bn3)#[none,4,4,128]
# out layer
out_logis = tf.layers.conv2d(active3,1,[4,4],strides=[1,1],padding="valid") #[none,1,1,1]
return out_logis
def _init_generator(self, input, label, istrain=True, resue=False):
"""
初始化生成器
:param input:输入噪声
:param label: 输入数据标签
:param istrain: 是否训练状态
:param resue: 是否复用内部参数
:return: 生成数据op
"""
with tf.variable_scope("generator",reuse=resue):
# input[none,1,1,self.noise_dim]
labels = tf.reshape(label,shape=[-1,1,1,10])
input = tf.concat([input,labels],axis=3)
# hidden layer 1
conv1 = tf.layers.conv2d_transpose(input,256,[4,4],strides=(1,1),padding="valid")
bn1 = tf.layers.batch_normalization(conv1,training=istrain)
active1 = tf.nn.leaky_relu(bn1) #[none,4,4,256]
conv2 = tf.layers.conv2d_transpose(active1,128,[4,4],strides=(2,2),padding="same")
bn2 = tf.layers.batch_normalization(conv2,training=istrain)
active2 = tf.nn.leaky_relu(bn2) #[none,8,8,128]
# layer 3
conv3 = tf.layers.conv2d_transpose(active2,64,[4,4],strides=(2,2),padding='same')
bn3 = tf.layers.batch_normalization(conv3,training=istrain)
active3 = tf.nn.leaky_relu(bn3) # [none,16,16,64]
# out layer
conv4 = tf.layers.conv2d_transpose(active3,self.img_c,[4,4],strides=(2,2),padding="same")
out = tf.nn.sigmoid(conv4) # (0,1) [None,32,32,1]
return out
def _init_train_methods(self):
"""
初始化训练方法:梯度下降方法,Session初始化,损失函数。
:return: NONE
"""
self.D_loss_real =tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=self.real_logis,labels=tf.ones_like(self.real_logis))
)
self.D_loss_fake = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=self.gen_logis,labels=tf.zeros_like(self.gen_logis))
)
self.D_loss = self.D_loss_real +self.D_loss_fake
self.G_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=self.gen_logis,labels=tf.ones_like(self.gen_logis))
)
total_vars = tf.trainable_variables()
d_vars =[var for var in total_vars if var.name.startswith('discriminator')]
g_vars = [var for var in total_vars if var.name.startswith('generator')]
self.D_trainer = tf.train.AdamOptimizer(learning_rate=self.lr).minimize(
self.D_loss,var_list=d_vars
)
self.G_trainer = tf.train.AdamOptimizer(learning_rate=self.lr).minimize(
self.G_loss,var_list = g_vars
)
self.sess = tf.InteractiveSession()
self.sess.run(tf.global_variables_initializer())
self.saver = tf.train.Saver(max_to_keep=1)
def gen_data(self, label, save_path="out/CGAN_MNIST/test.png"):
"""
生成数字图像
:param label:数字标签
:param save_path: 保存路劲
:return: 图像数组 numpy
"""
batch_noise = np.random.normal(0,1,(25,1,1,self.noise_dim))
print(np.argmax(label,axis=1))
samples = self.sess.run(self.gen_out,feed_dict={self.gen_x:batch_noise,self.label:label,self.isTrain:True})
# [25,32,32,1] ---->[25,32,32]
samples =np.reshape(samples,[-1,32,32])
fig = self.plot(samples)
if not os.path.exists('out/CGAN_MNIST/'):
os.makedirs('out/CGAN_MNIST/')
plt.savefig(save_path)
plt.close(fig)
return samples
def train(self, batch_size=64, itrs=100000, save_time=1000):
"""
训练模型方法
:param batch_size:批量采样大小
:param itrs: 迭代次数
:param save_time: 保存模型周期
:return: NONE
"""
# 读取数据
data = dh.load_mnist_resize()
start_time = time.time()
test_y = data['label'][0:25]
for i in range(itrs):
#随机采样数据
mask = np.random.choice(data['data'].shape[0],batch_size,replace=True)
batch_x = data['data'][mask]
batch_y = data['label'][mask]
batch_noise = np.random.normal(0,1,(batch_size,1,1,self.noise_dim))
#训练判别器
_,D_loss_curr =self.sess.run([self.D_trainer,self.D_loss],feed_dict={
self.x:batch_x,self.gen_x:batch_noise,self.label:batch_y,self.isTrain:True
})
#训练生成器
batch_noise = np.random.normal(0,1,[batch_size,1,1,self.noise_dim])
_,G_loss_curr = self.sess.run([self.G_trainer,self.G_loss],feed_dict={
self.gen_x:batch_noise,self.label:batch_y,self.isTrain:True
})
if i%save_time ==0:
self.gen_data(label=test_y,save_path='out/CGAN_MNIST/'+str(i).zfill(6)+".png")
print("i:",i," D_loss:",D_loss_curr," G_loss",G_loss_curr)
self.save()
end_time = time.time()
time_loss = end_time-start_time
print("训练时间:",int(time_loss),"秒")
start_time =time.time()
self.sess.close()
def save(self, path="model/CGAN_MNIST/"):
"""
保存模型
:param path:保存路径
:return: NONE
"""
self.saver.save(self.sess,save_path=path)
def restore(self, path='model/CGAN_MNIST/'):
"""
恢复模型
:param path:模型保存路径
:return: NONE
"""
self.saver.restore(sess=self.sess,save_path=path)
def plot(self, smaples):
"""
绘制5*5图片
:param smaple: numpy数组
:return: 绘制图像
"""
fig = plt.figure(figsize=(5,5))
gs = gridspec.GridSpec(5,5)
gs.