第二关:爬虫HTML网页基础(附练习题)
Posted Python家庭
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第二关:爬虫HTML网页基础(附练习题)相关的知识,希望对你有一定的参考价值。
下面小编就整理了在编程中,比较常用的【爬虫html网页基础】入门到进阶的用法。
1. HTML是什么?
HTML(Hyper Text Markup Language)是用来描述网页的一种语言,也叫超文本标记语言 。它包括一系列标签,通过这些标签可以将网络上的文档格式统一。
1.1 查看网页的HTML代码
接下来,我们就来看看,每个漂亮的网页背后的HTML代码是怎样的,请一步一步跟着我操作。
【注:下面我们的示范,会用谷歌浏览器(Chrome)进行演示,火狐浏览器(Firefox)的操作方式是一样的。推荐你也使用这二者之一。】
先打开我们的参考网站:CSDN。https://www.csdn.net/
在网页任意空白地方点击鼠标右键,然后点击“显示网页源代码”。
你会看到,浏览器弹出了一个新的标签页:

没错,这就是HTML源代码了。
这样查看的好处是,整个网页的源代码都完整地呈现在你面前。坏处是,在大部分情况下,它都会经过压缩,导致结构不够清晰,你不太容易懂每行代码的含义。而且,源代码和网页分开在两个页面展示。
所以更多时候,我们会用这样一种方法:
在网页的空白处点击右键,然后选择“检查”(快捷方式是ctrl+shift+i)。
接着,你会看到一个新的界面——开发者工具栏:
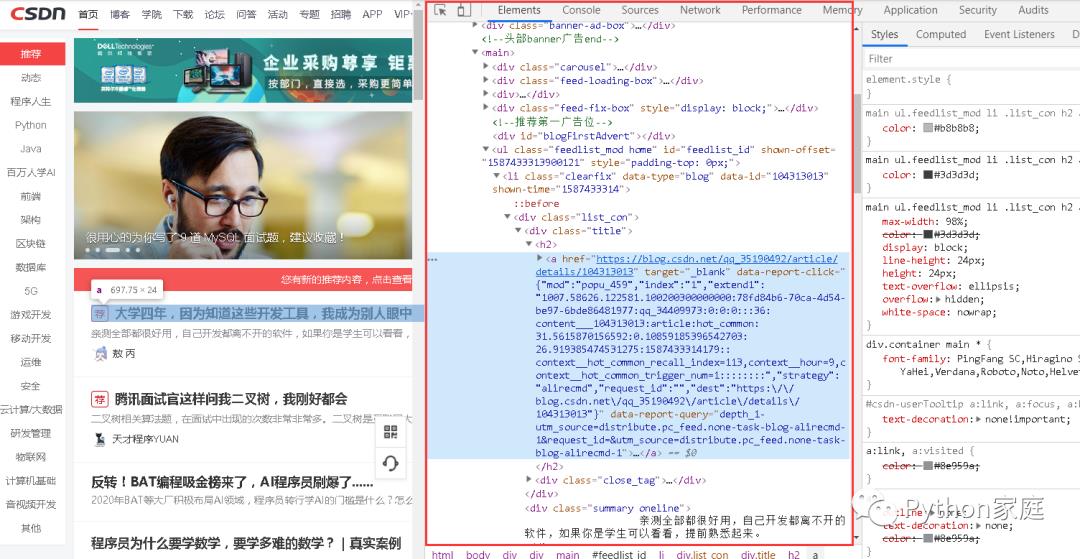
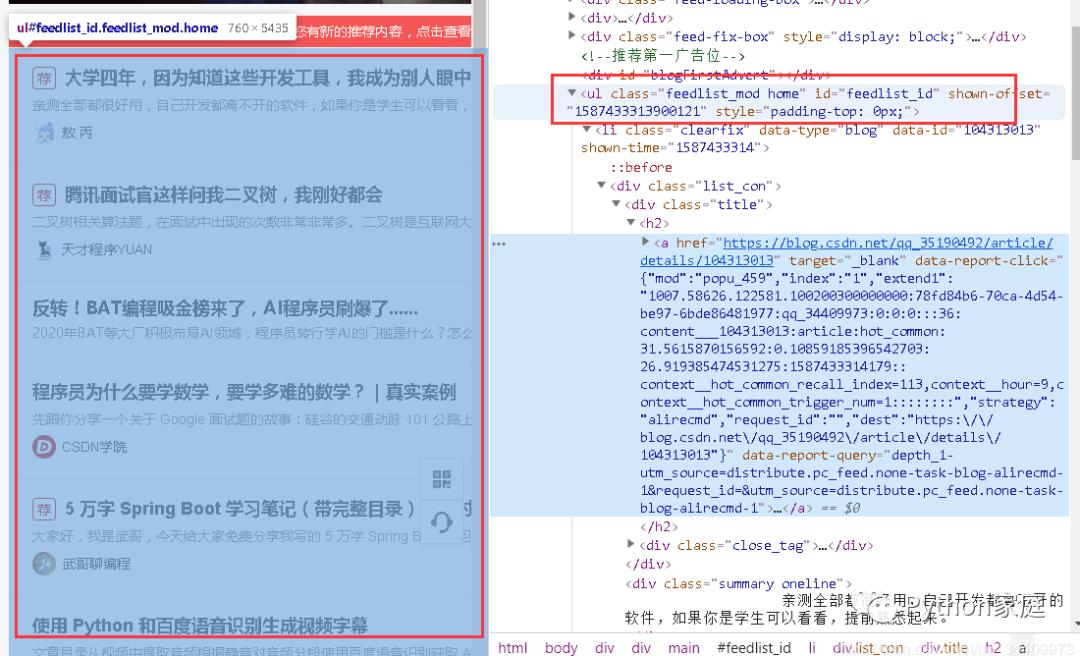
上图中标亮的部分就是网页的HTML代码。
将鼠标放在HTML源代码上,你会发现,左边网页上有一些内容会被标亮。这其实就是这行代码所描述的网页内容,它们一左一右,相互对应。
2. HTML 元素
回归我们的 HTML 正题,接下来我先展示一个简单的 HTML 例子:
<html><head><title>我的第一个网页</title></head><body>Hello,World</body></html>
上面的代码展示了一个最简单的 HTML 代码,可以看到很多夹在尖括号 <> 中间的字母,它们叫做 标签。
一般来说标签都是成对出现的,所以标签又分为 开始标签(比如 <title>)和 结束标签(比如 </title>)。开始标签、结束标签加上标签中间的内容就构成了 元素。
结束标签与开始标签十分相似,只是结束标签在元素名之前包含了一个斜杠 /,表示着元素的结束。初学者常常会忘记结束标签,这可能会产生一些奇怪的结果。
我们重新看一下最开始的 HTML 代码,它是由 html、head、title、body 这四个元素组成的。一般情况下,这四个是每个 HTML 文档都会有的元素。
我们一定要注意层级关系,不能错乱,像下面这样 <head> 和 <body> 交叉在一起是有问题的:
<html><head><title>我的第一个网页</title><body> # 包含住了<head>的结束标签</head>,错误的结构</head>Hello,World</body></html>
2.1 网页头
网页头,前面说过网页头中一般存放网页相关信息、加载样式和脚本等,我们来看一个例子:
<head><meta charset="utf-8" /><title>我的第一个网页</title><link rel="stylesheet" href="style.css" /><script src="script.js"></script></head>
<meta charset="utf-8" /> 定义了网页的编码方式,是 utf-8。当爬虫获取的数据乱码时,我们可以根据它来更正编码;<title>我的第一个网页</title> 指定了网页的标题,也就是浏览器标签栏中看到的标题;
剩下来的一个是加载样式文件的代码,一个是加载脚本文件的代码。对爬虫来说不必深入,了解一下即可。
或许你已经发现了,<meta charset="utf-8" /> 和前面说的需要有开始标签和结束标签不太一样,只有一个标签。别急,这个我们后面会说。
2.2 网页体
网页体,这个是爬虫要重点关注的,我们需要的数据都存放在里面。上面的示例代码中,为了简洁,直接在网页体内写了内容。但一般网页的网页体内会有很多其他的元素共同组成。后面我们会介绍一些比较常用的,不必着急。
3. HTML 常见元素
一篇结构清晰的文章都有标题和段落,HTML 网页也是如此。
HTML 提供了 6 个等级的标题,即 <h1>、<h2>、<h3>、<h4>、<h5>、<h6>,重要性依次递减,也就是说 <h1> 是最大的标题,<h6> 是最小的标题。
同时,在HTML 里段落使用的是 <p> 标签,超链接使用的是 <a> 标签,图片使用的是 <img> 标签。老师整理了一些常见的 HTML 元素,眼熟就好,之后的课程里都会这些元素打交道,慢慢就熟悉了。

你要重点关注的是,超链接使用的 <a> 标签和图片使用的 <img> 标签,这对我们后续的爬虫很有帮助。
3.1 自闭合元素和非自闭合元素
<meta charset="utf-8" /> # 属于自闭合标签 <.../>的格式<h1>hello world!</h1> # 非自闭合元素 <..>内容</..>格式非自闭合元素必须有开始和结束标签,而自闭合元素没有结束标签,/> 意味着这个元素的结束。非自闭合元素有被开始标签和结束标签包裹住的内容,而自闭合标签则没有元素内容,只有元素属性。元素属性是重点,我们后面再细说。
对于自闭合元素和非自闭合元素,你只需要知道有这两种写法即可。当你在别的网页源代码里看到这两种写法时,不要觉得陌生哦。
下图列出了常见的自闭合元素和非自闭合元素,了解一下即可:
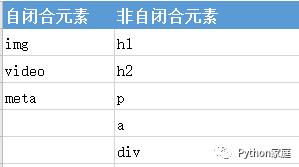
随着我们爬虫学习的深入,你会解析越来越多的网页,同时遇到越来越多的新元素,如果想知道某个标签的含义,比如 a 标签,去搜索引擎里搜索 html a 标签 自行学习即可。
4. 标签属性
HTML 元素可以通过设置属性来为元素提供更多信息。在爬虫中,我们经常通过这些属性去筛选、提取数据。
<a> 元素是我们常见的超链接,是 HTML 里非常重要的元素。它将一个个网页全都链接在一起,形成了互联网。如果没有 <a> 元素,你就无法从一个网页跳入另一个网页,这会让我们的网上冲浪变得非常糟糕!
<a href="www.baidu.com">百度一下</a># <a href="www.baidu.com">属于开始标签,</a>属于结束标签# href为属性名,www.baidu.com为属性值,用 = 连接# 百度一下属于浏览器呈现内容
可以看到,HTML 元素属性的语法是 属性名="属性值",且必须在开始标签中。HTML 元素可以拥有多个属性,用空格分隔开即可。
接下来我们把刚刚学会的 <a> 元素加到我们之前的 HTML 代码里。
<html><head><title>我的第一个网页</title></head><body><h1>Hello,World</h1><a href="www.baidu.com">百度一下</a></body></html>
上面的 HTML 代码会被浏览器渲染成下面这样的网页:
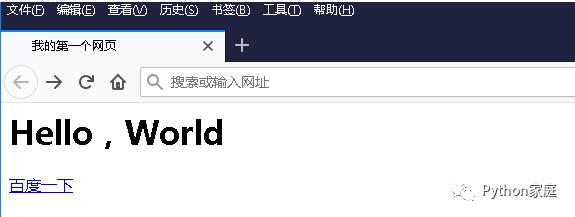
可以看到,元素内容是链接文字展示的内容。点击后便能跳转到对应 href 属性的定义的网页。
<img src="baidu.jpg"/>
现在,你了解了 <a> 元素的 href 属性和 <img> 元素的 src 属性。你肯定知道了之后写爬虫时从哪里获取网页链接和图片地址了吧!
除了 href 属性和 src 属性外,HTML 中还有两个很常用的属性——id 和 class。
id 和 class 都用于标识元素,是给 javascript 和 CSS 用的。因为爬虫中经常用到它们,因此这里简单的介绍一下。
id 是唯一标识,其值在整个网页里是唯一的。而 class 是一类标识,其值可以用在同一类所有的元素中。
你可以简单的理解为:id 是学号,class 是班级。学号是全学校唯一的,而班级里有很多的人。
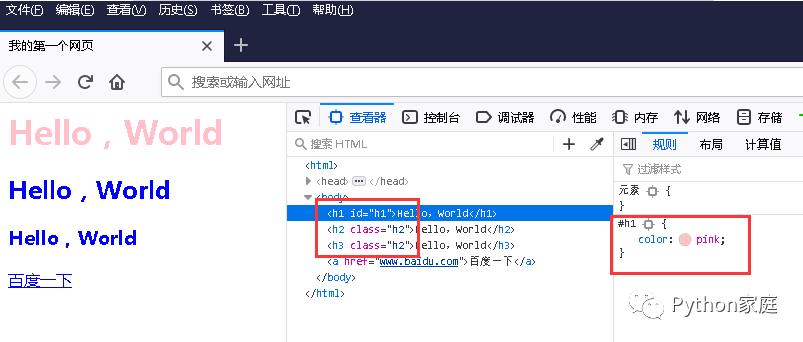
<html><head><title>我的第一个网页</title></head><style>#h1{color: pink;}.h2{color: blue;}</style><body><h1 id="h1">Hello,World</h1><h2 class="h2">Hello,World</h2><h3 class="h2">Hello,World</h3><a href="www.baidu.com">百度一下</a></body></html>
上面代码,我们把 id="h1" 和 class="h2" 属性加上去,注意喔 id 是唯一的,class可多个。
这里我们定义了一个 style 标签,style 属性标签可以用来定义网页文本的样式,比如字体大小、颜色、间距、对齐方式等等。
#h1 表示 id 的选择器,这样就可以对用了 id = "h1" 的标签设置样式了,这里我们设置了一个颜色为粉丝的字体颜色。
.h2 表示 class 的选择器,这样就可以对用了 class = "h2" 的标签统一设置样式了,这里我们设置了一个颜色为蓝色的字体颜色。
5. 运行Html文件到浏览器
这里我们介绍一下,对入门同学比较友好的编辑器:vs code。(官网即可下载)
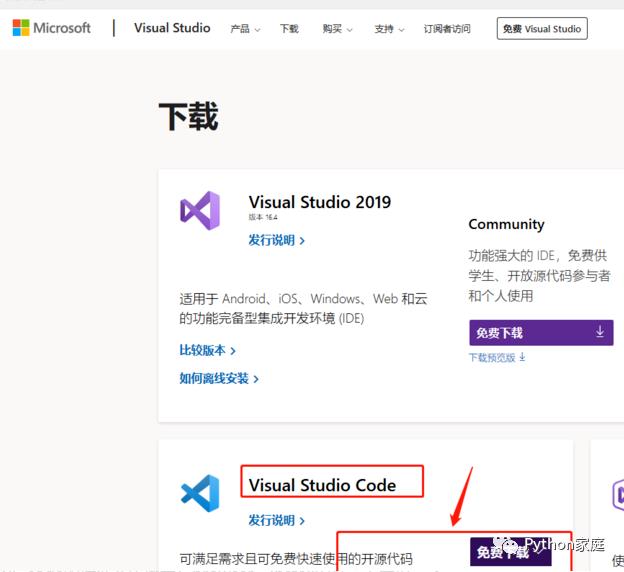
VS code的插件商店搜索:browser,Install安装一下就搞定了。
在新建的.html文件中,鼠标右键(注意是.html文件后缀,而不是.py文件后缀)
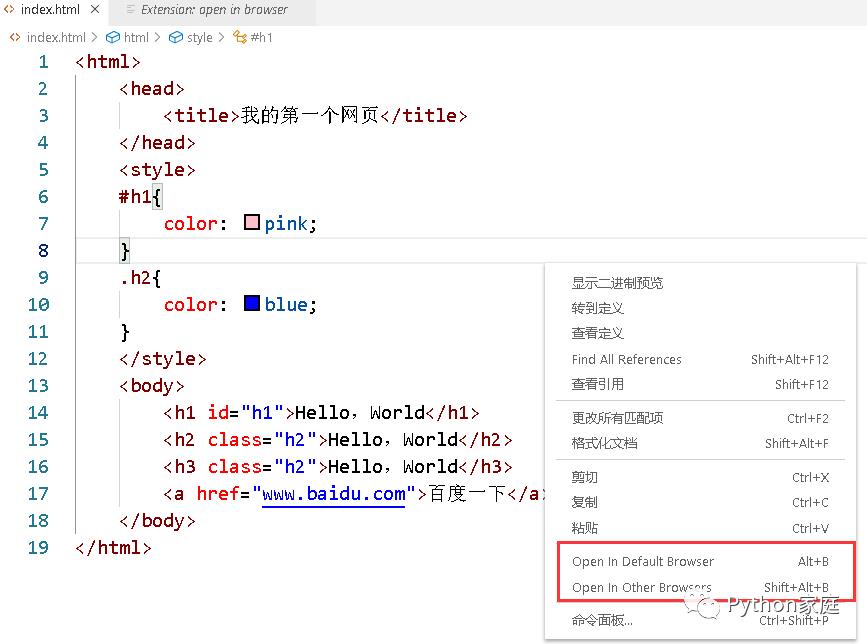
通过默认的浏览器运行文件,通过其他的浏览器运行文件也可以。
练习题
1. 网页文件的扩展名是什么?
A.txtB.jsonC.csvD.html
2. 下面关于属性的说法,错误的是?
A.<a> 标签的链接放在 src 属性里B.<a> 标签的链接放在 href 属性里C.<img> 标签的图片资源放在 src 属性里
3. 下列关于 HTML 的标签,说法错误的是?
A.HTML 的标签可以嵌套B.HTML 的标签都有 href 属性C.HTML 的标签分为闭合标签和非闭合标签
4. 下列关于 id 和 class 属性,说法正确的是?
A.class 和 id 不能同时存在开始标签内。B.id的属性选择器为"." , class的属性选择器"#"。C.id是唯一标识,其值在整个网页里是唯一的。D.class是唯一标识,其值在整个网页里是唯一的。
(完)
关注「Python家庭」一起轻松学Python




一起学Python
原创不易,点个 “在看” 分享吧
以上是关于第二关:爬虫HTML网页基础(附练习题)的主要内容,如果未能解决你的问题,请参考以下文章