漫画:Git 中的的数据结构和算法设计
Posted labuladong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了漫画:Git 中的的数据结构和算法设计相关的知识,希望对你有一定的参考价值。
大家好哇~ 欢迎来到波波和阿菌神奇的“科普”频道!
今天,我们为大家介绍程序员是如何怎么存档并管理文件版本的。
大家要做好心理准备,今天的“科普”稍有点点硬核,阿菌想从需求分析,产品设计,代码实现等全方位角度为大家“科普”,综合的东西较多,可能不太好看懂......
但内容应该还是有点点意思的,毕竟阿菌总是写一些乱七八糟的东西,如果暂时感觉难以消化可以考虑先收藏吖~
在开始之前,我们先为大家介绍一个概念,叫:版本管理。
阿菌这坏小子有时会想回到自己的过去,比如说回到小学时候的自己,回到初中时的自己,回到高中时的自己,或者回到大学前的自己,重读一次大学等等......
人生的每个阶段,我们都可以看成自己的一个版本,比如说小学版的阿菌,初中版的阿菌,高中版的阿菌,大学版的阿菌......
要是老天真的给我们每个阶段都存了档,那我们就可以回到过去的版本,重新开始了!
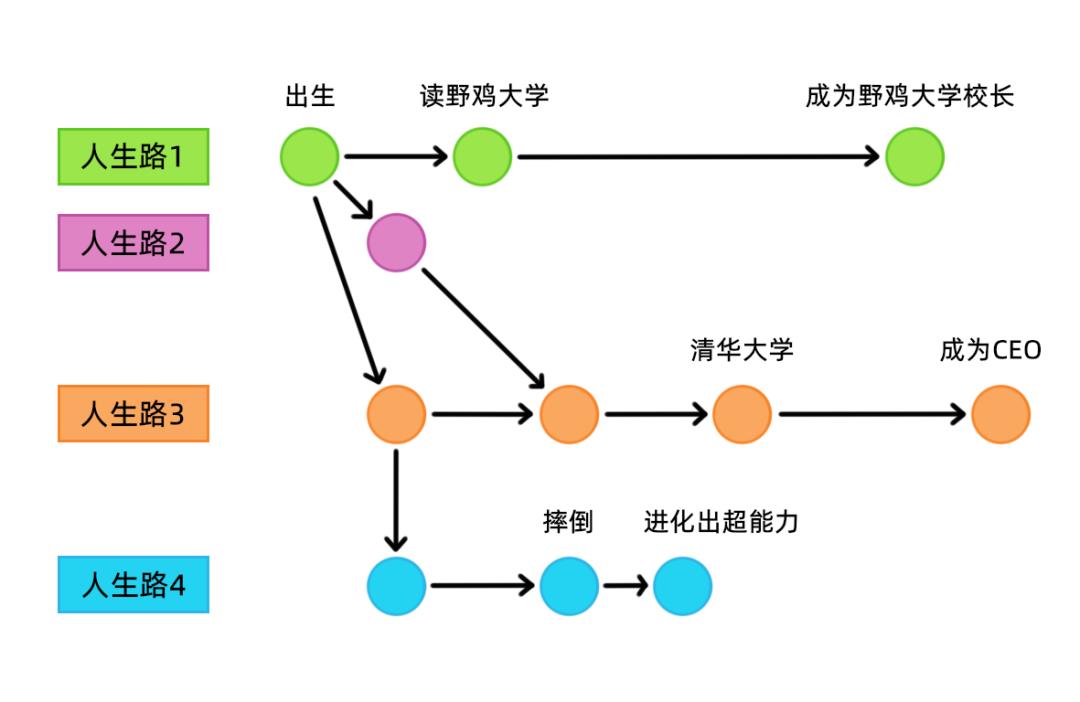
从旧版本发展出新的人生,或许我们的人生可以拥有好几条分支路线呢......
虽然目前看来不太现实,就算真的有得选,阿菌也绝不会回到过去的版本,因为阿菌不敢保证在另一条人生分支上,还能遇到波姐......
大家考虑以下场景:假设学院安排我们做一次毕业晚会宣传活动,既要有 PPT,又要有文稿,还得有海报。
于是我们高高兴兴地把全学院的本科生资料编写到了 PTT,文稿和海报里。
这个时候,学院说:怎么可以只有本科生的资料?研究生的相关资料也要加进去!
然后我们在现有的 PPT,文稿和海报里,加入了研究生的资料。
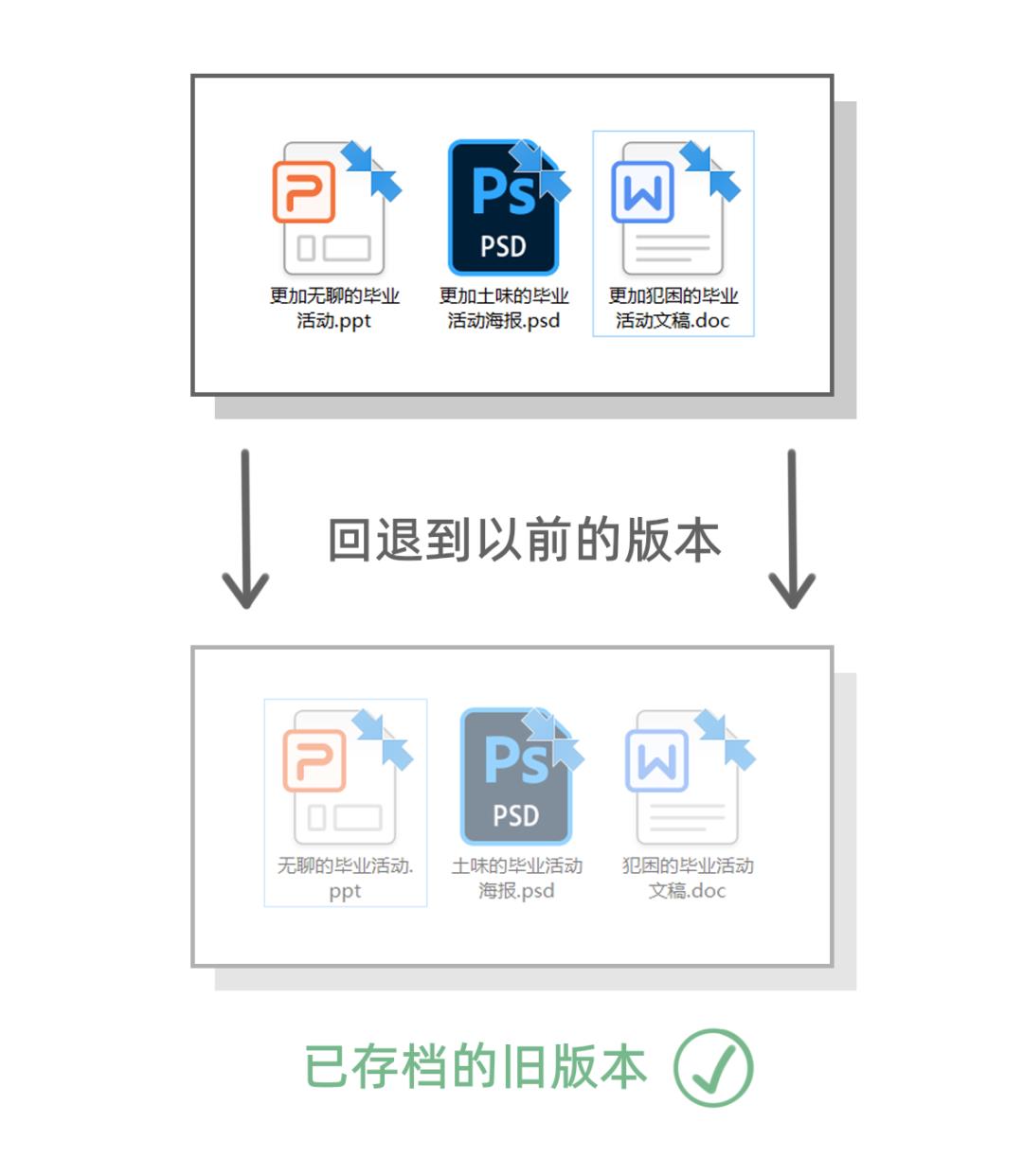
大家可能就傻眼了:我们已经在 PPT,文稿和海报里加了研究生的信息,而且已经和本科生的内容融合到了一起,这删起来也太麻烦了吧!!!
要是我们提前把本科生的策划资料保存为一个版本就好了,这样就能直接把本科生的版本交给学院,完成工作。
现在场景有了,痛点有了,接下来我们着手设计一款软件产品来解决这个问题(有同学会说,阿菌你扯淡,我每个版本复制一份就行啦,搞个软件出来干嘛?呃呃,坚持看完就懂啦,它不只存档这么简单哦。我们手动拷贝存档容易出现各种各样的问题,比如忘了存,忘了存在哪,存的顺序搞乱了等等......试过就会有体会哦)。
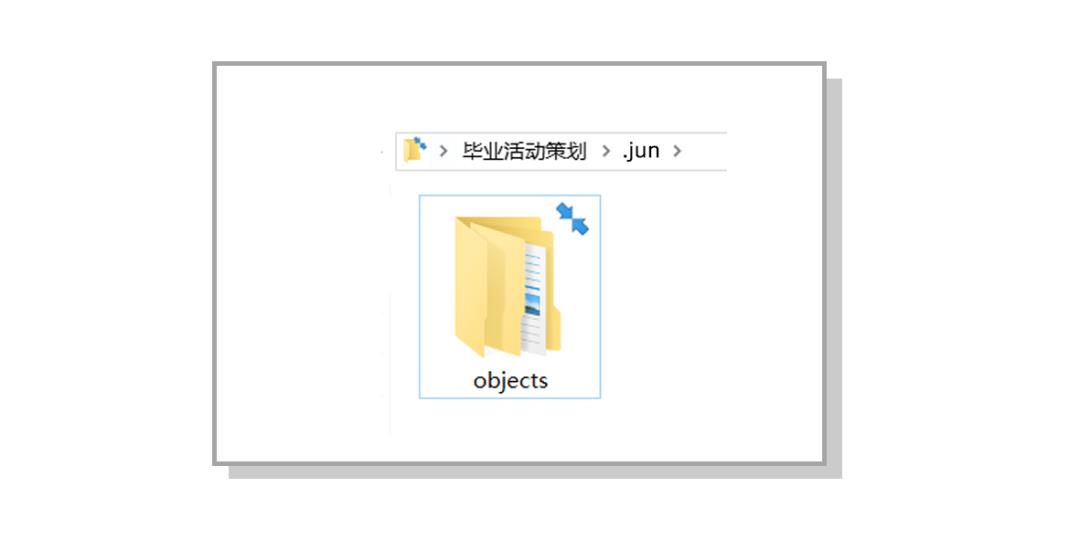
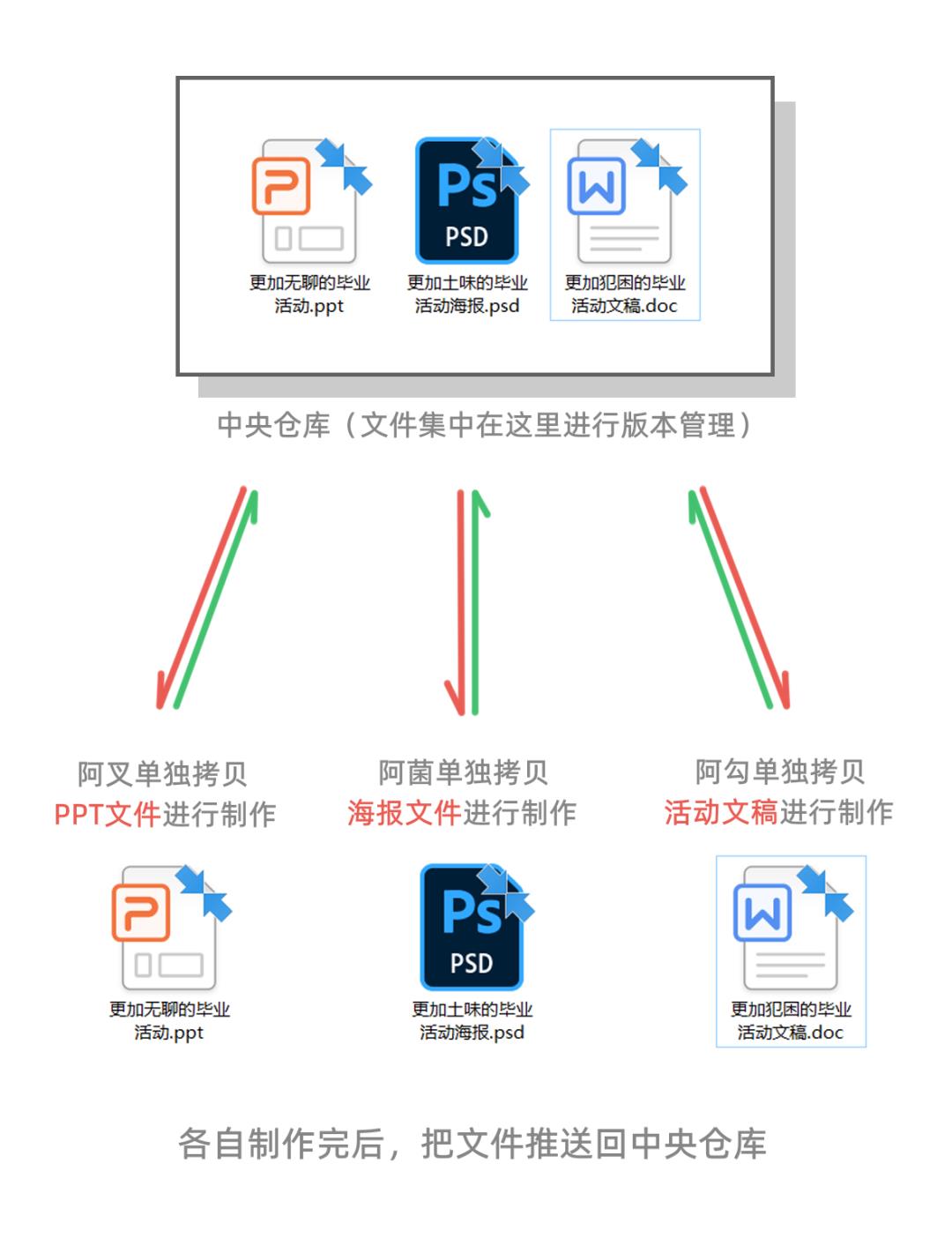
现在我们有一个文件夹,文件夹目录下有 PPT,文稿和海报,要不我们就在这里创建多一个文件夹用于存档吧!把名字起名为“.jun”就好啦!
现在我们创建好了一个“.jun”文件夹用于存放当前目录的版本信息,接下来我们要思考的是,该如何保存各个文件的版本?
在计算机领域,我们来到的环节应该叫设计底层数据结构,我们可以把“.jun”文件夹看成一个数据库,这个数据库会用来保存当前文件夹下文件的版本数据。
我们就把这些.doc、.psd、.ppt文件称为 object 吧!(反正也不知道叫什么好)我们在“.jun”文件夹下创建一个“objects”文件用于存放各个 object 的信息,这样,我们就有了一个 object 数据库了!
呃,听起来好像很厉害,其实阿菌只是创建了两个文件夹......
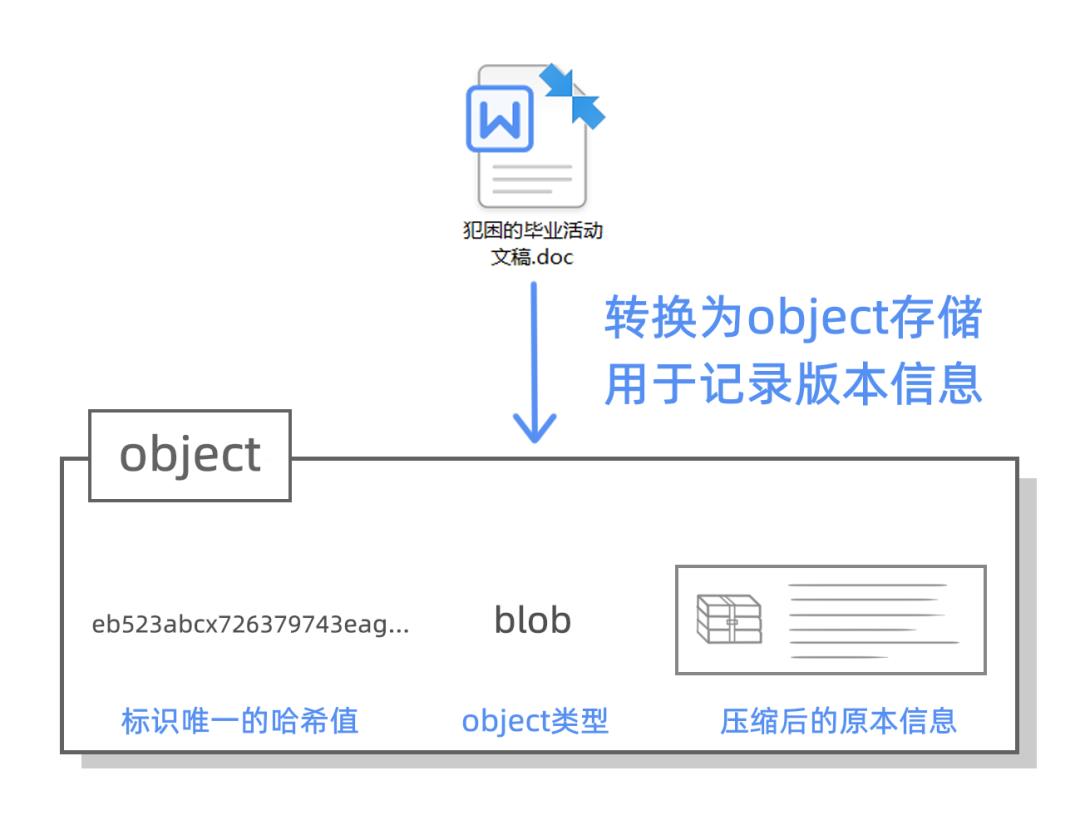
现在我们想想一个 object 该存些什么东西比较好,究竟什么东西才能精准定位一个文件的版本信息呢?
想来想去,不如这样吧,我们一个 object 至少得包含三个信息:
1. 文件的原本信息,我们PPT,WORD文档中的内容就叫原本信息,直接保存原本信息可能需要很大的空间(至少和这些文件本身一样大),我们可以先压缩,再保存。
2. object 的类型,考虑到我们当前文件夹下除了有 PPT,文稿和海报之外,以后还可能放新的文件或者新的文件夹,文件和文件夹都应该叫 object,只不过可以用不同的类型区分他们。(大家可以在这留个心眼,这是这款版本控制管理软件的精华部分,后面就知道啦)
3. 一串字符数字,我们起个专业点的名字叫哈希值,用于标识当前的 object,每个 object 都有独一无二的哈希值(其实就一串乱七八糟的数字字符,这样不容易重复)。
看到这里,大家可能会有疑惑:你们为啥一直在说怎么设计,我们更想知道的是,为什么这么设计?
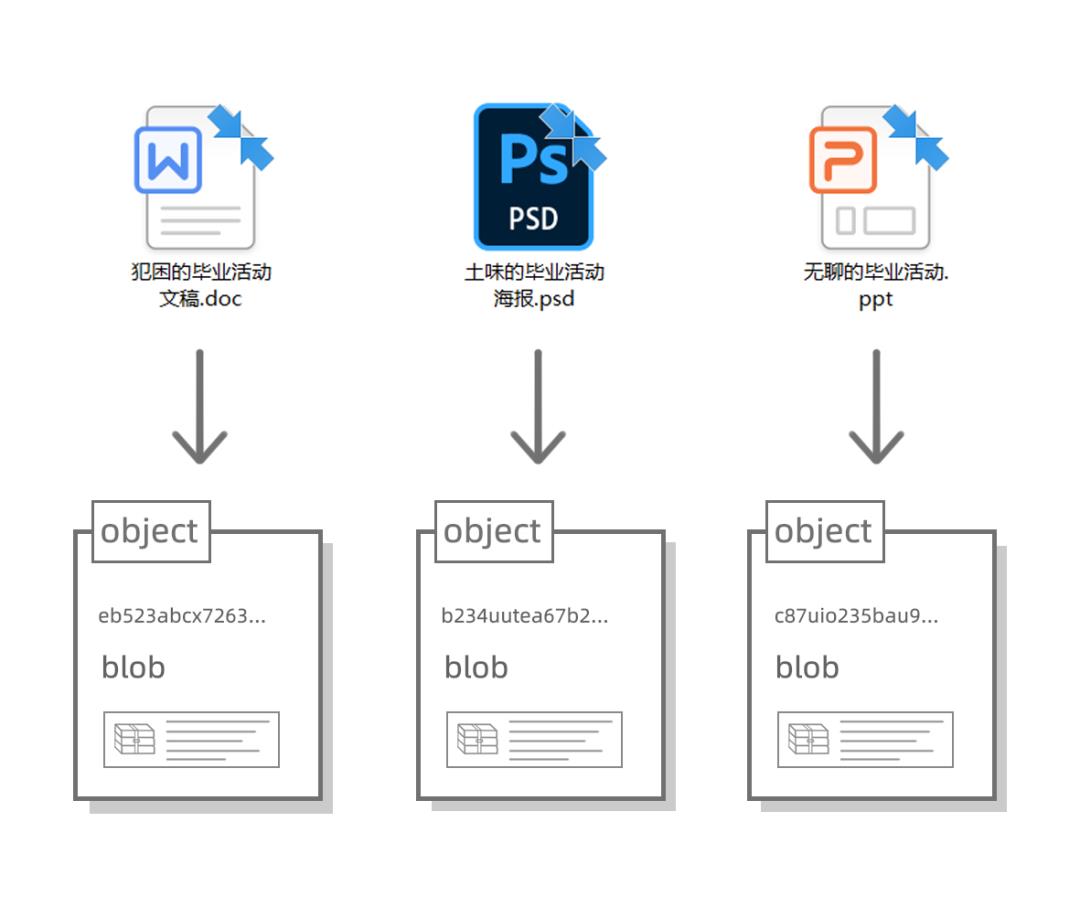
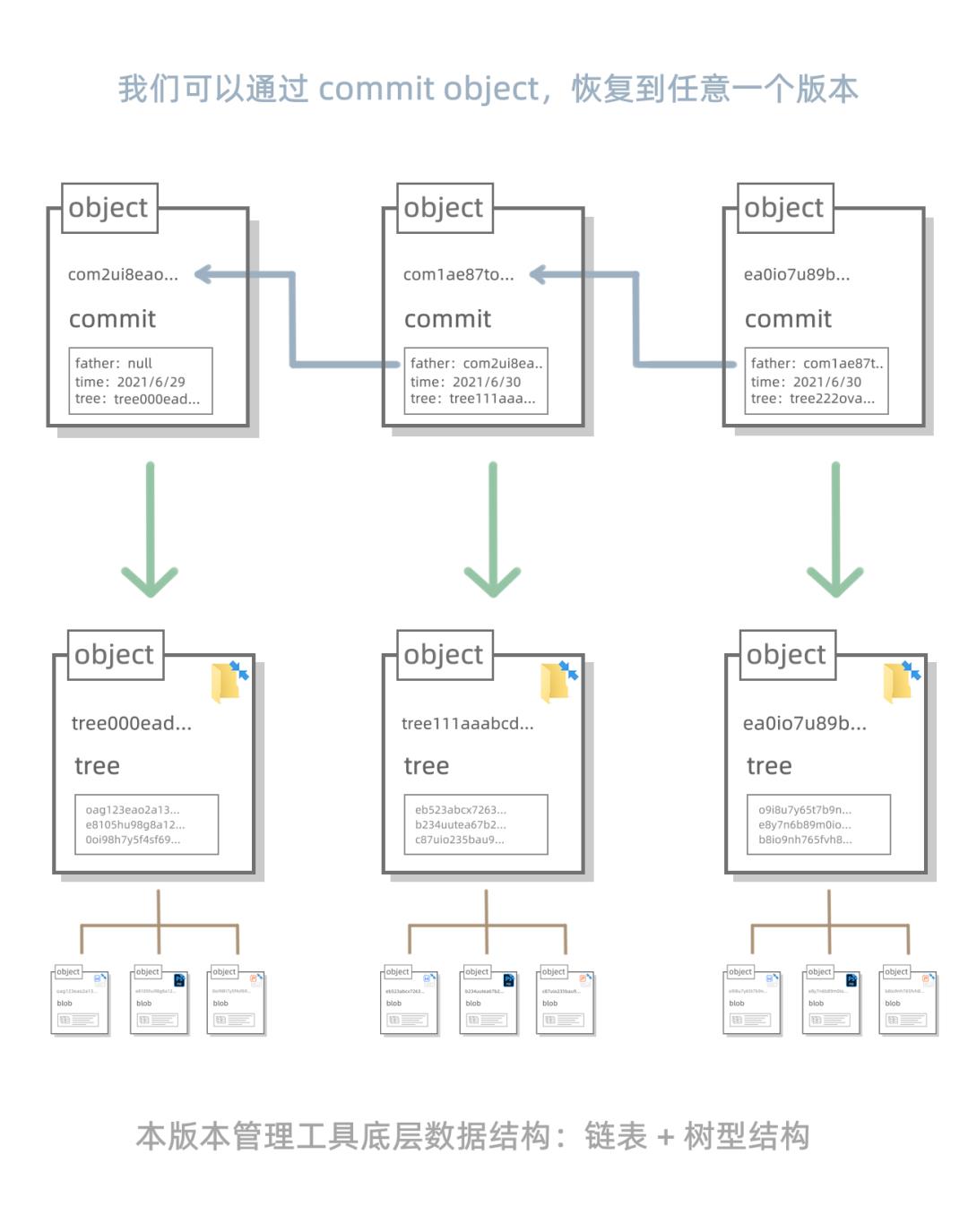
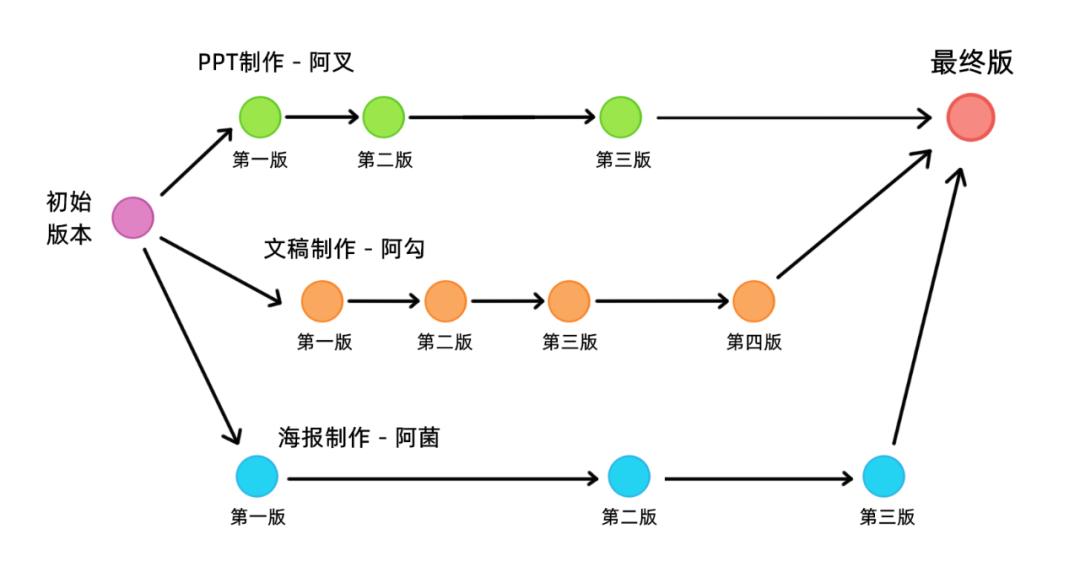
大家先看第一张图,当前文件夹下的 PPT,文稿和海报,我们可以分别用三个 object 表示:
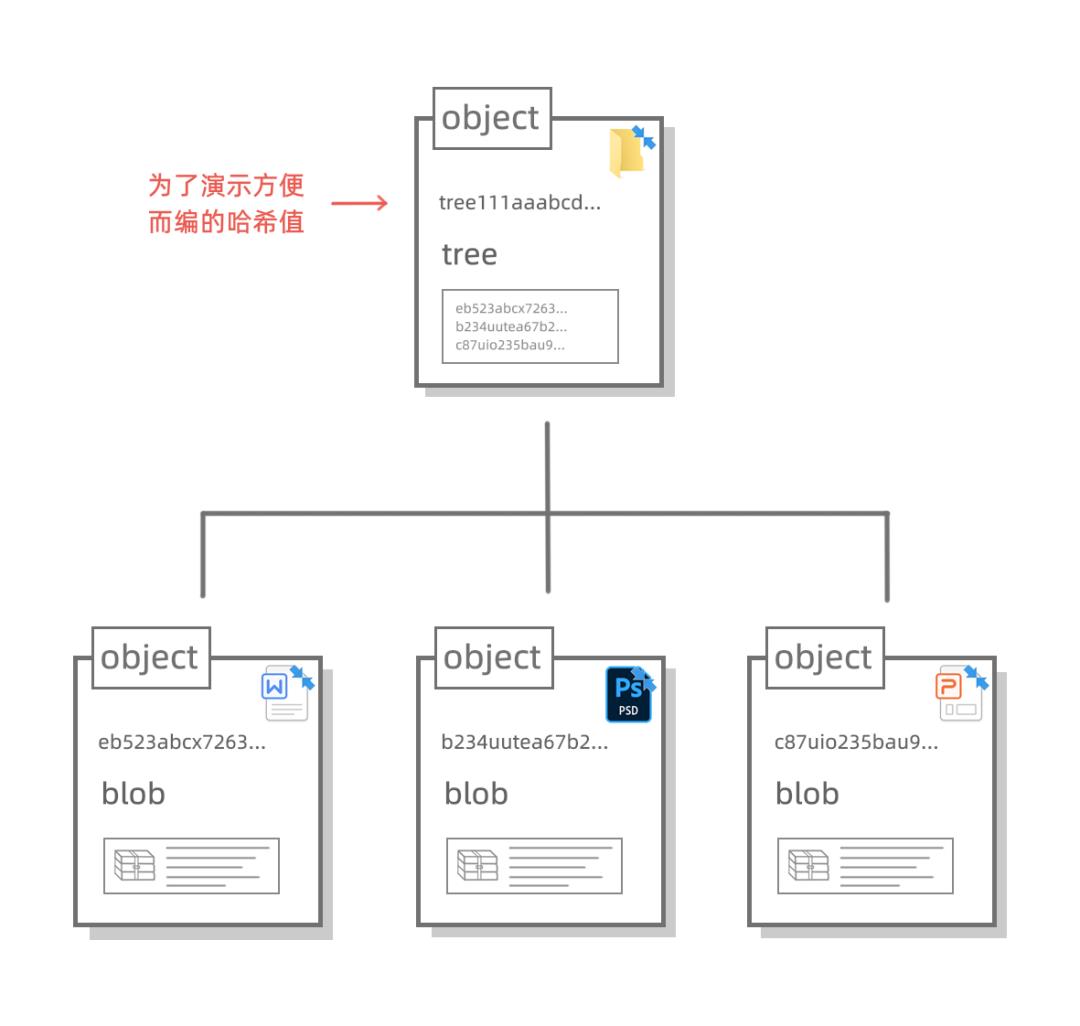
由于他们放在同一个目录下,于是我们可以用一个大的 object 来标记他们,我们把这个大 object 的类型定义为 tree(树干的感觉),这个 tree object 对等的就不是一个个文件了,而是一个文件夹:
细心的读者朋友会发现:咦?这个 tree object 貌似已经包含了当前文件夹下的所有文件信息,也就是说,这个 tree object 貌似已经可以记录当前文件夹的版本信息了!
我们可以通过这个 tree object 找到PPT,文稿和海报对应的 object 们,这些 object 保存有PPT,文稿和海报某个时间点的原信息,我们只要把这些信息解压出来,就能把文件夹恢复到曾经存档时候的样子了。
接下来的问题是:我们不会只保留一份存档,我们会保存很多份存档,如何才能把一系列存档组织起来呢?
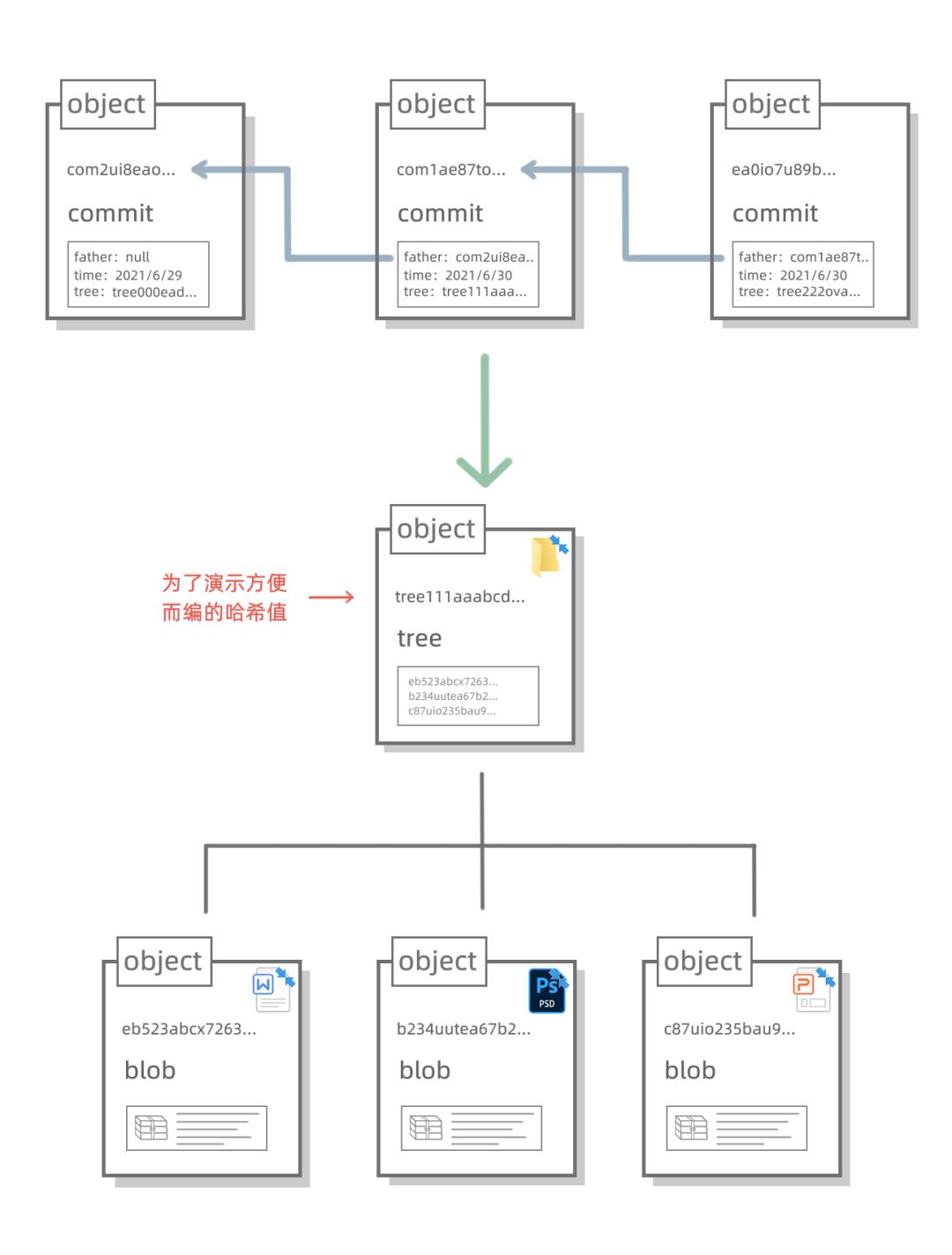
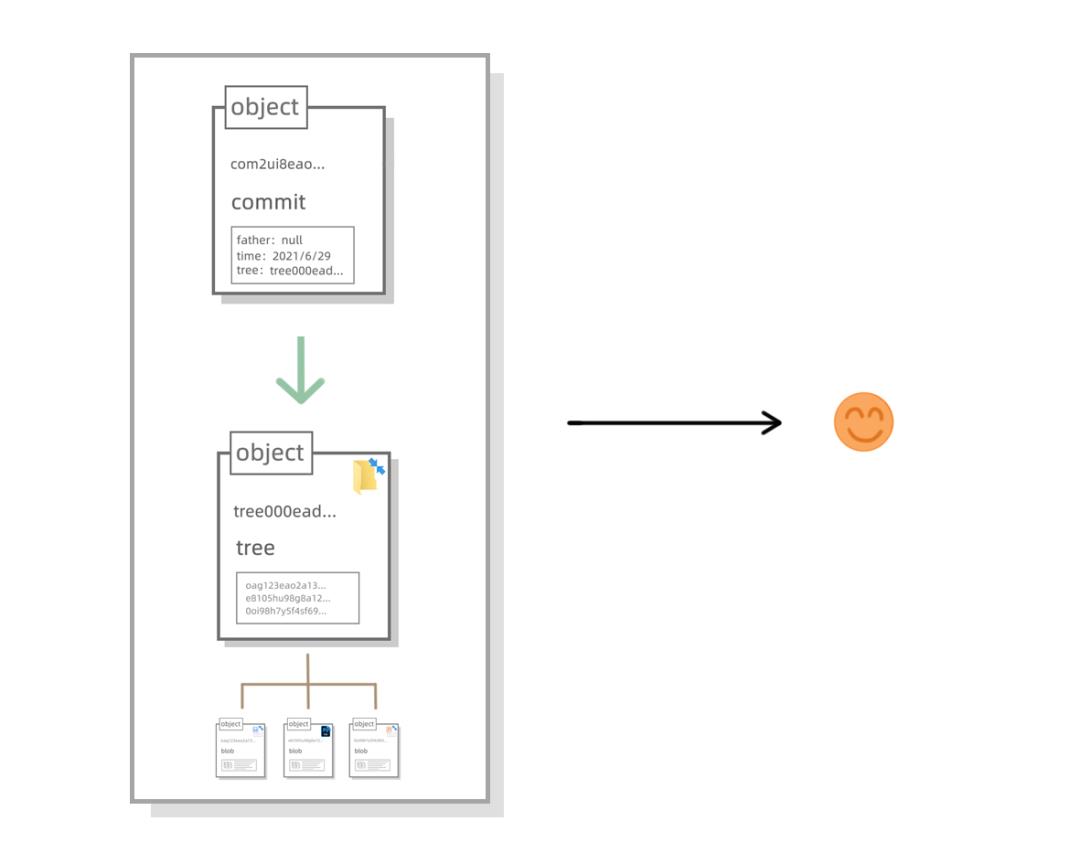
接下来我们引入一个新的 object 类型,我们叫起名叫 commit 类型好了,就是一个提交的意思。想要把存档串联起来,我们得加上一项参数,指明上一个 commit object 是谁,或许我们还可以加上时间等信息,这样一来,每一次提交就是一个版本:
上面这个图由于位置不够,画得不够直观,我们再画一个图,大家明白每个 commit object 都指向一个 tree object 就行了。也就是说:commit object 只是 tree object 的一层封装,虽然还原出一个文件夹过去的存档我们只需要 tree object,但封装成了 commit object 后,通过“father”这个属性,就能把一系列的存档连起来,而且还能盖上时间戳,这样整个存档记录就很清晰了。
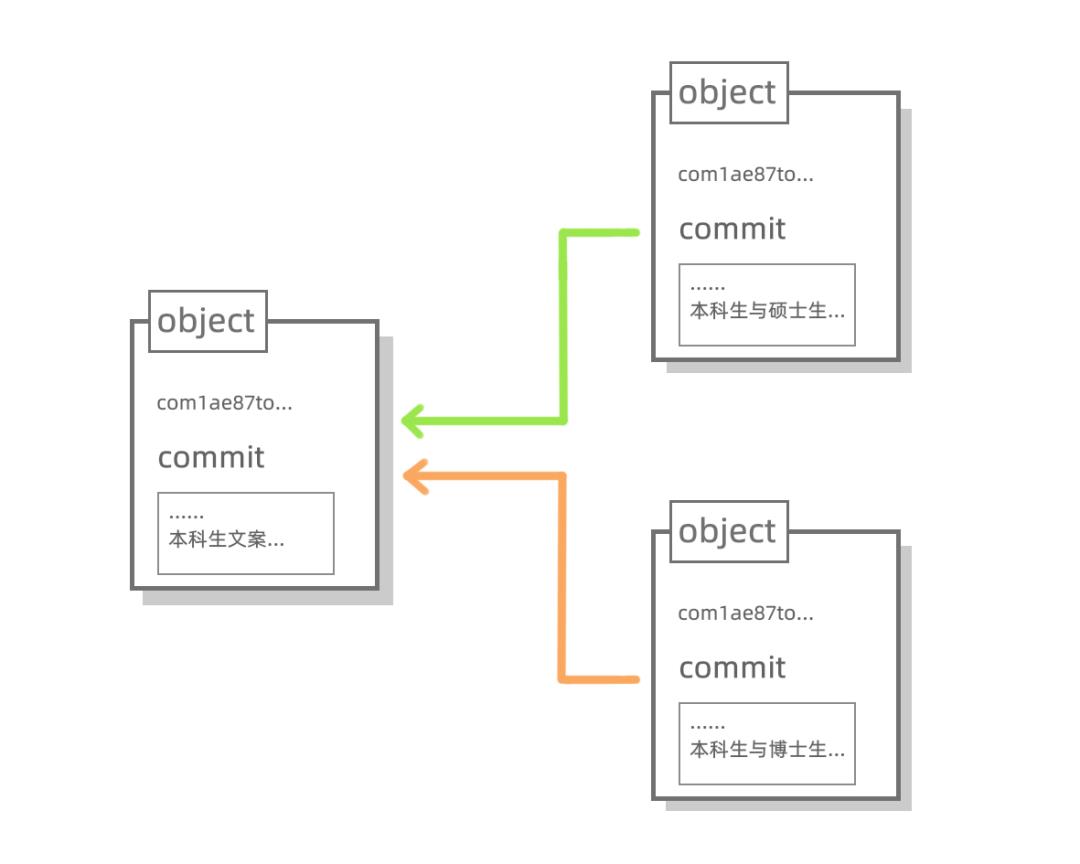
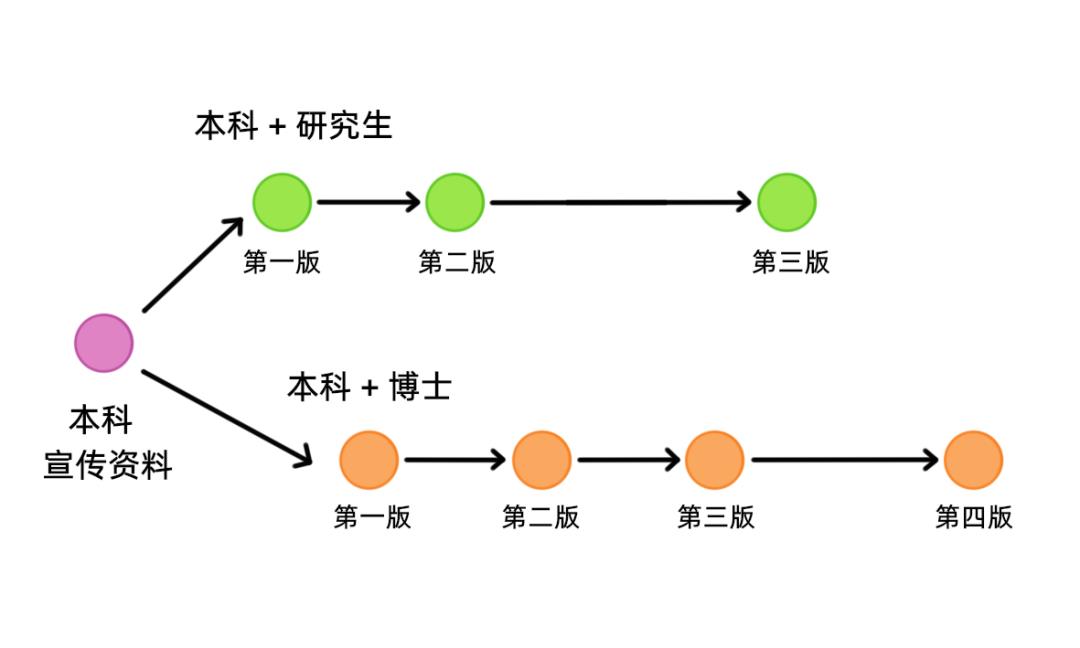
讲到这里不知道大家会不会冒出一些奇怪的想法,假设学院布下了两个任务:我们本科生,既要和研究生搞一次毕业联谊,又要和博士生搞一次毕业联谊,我们这套版本管理系统还能用上吗?(也只有阿菌才能想出这样奇奇怪怪的活动)
我们可以创建两个 commit object(两个新的存档),分别指向最开始保存了本科生资料的存档,然后我们就能分别在两个新的存档上干活啦,而且两个存档互不影响,可以继续在两个存档之后建立新的存档,就像下面这样:
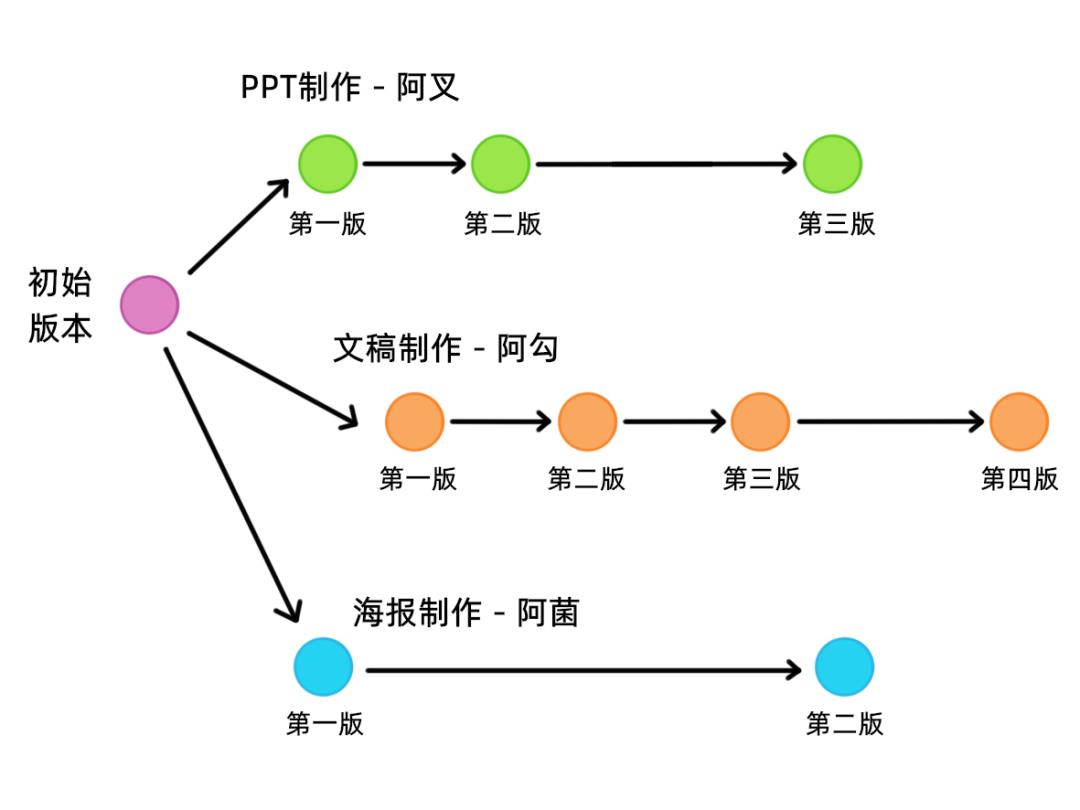
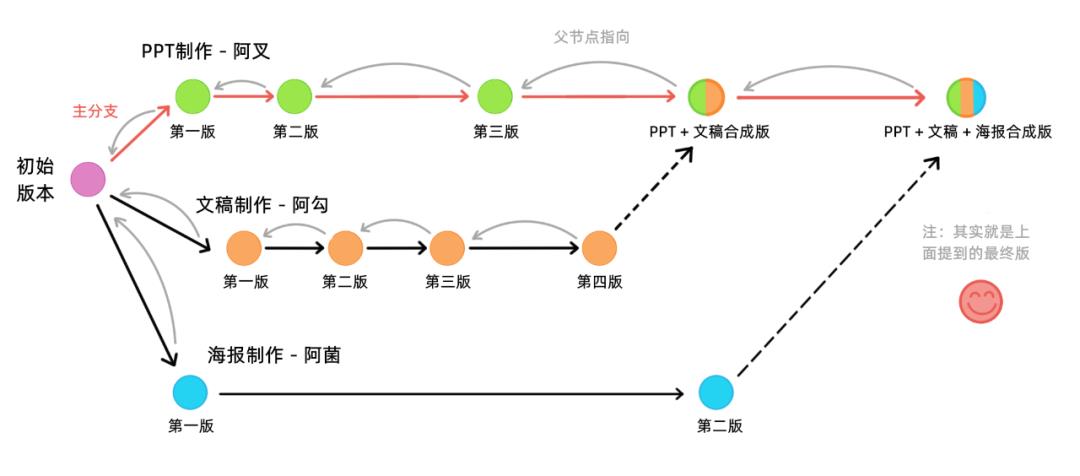
学院不再搞花样了,只要做好本科生的毕业活动策划就行。但是学院规定的时间很短,阿菌一个人做不完,他找来了他的同学阿叉和阿勾一起做,三个人分别负责PPT,文稿和海报。
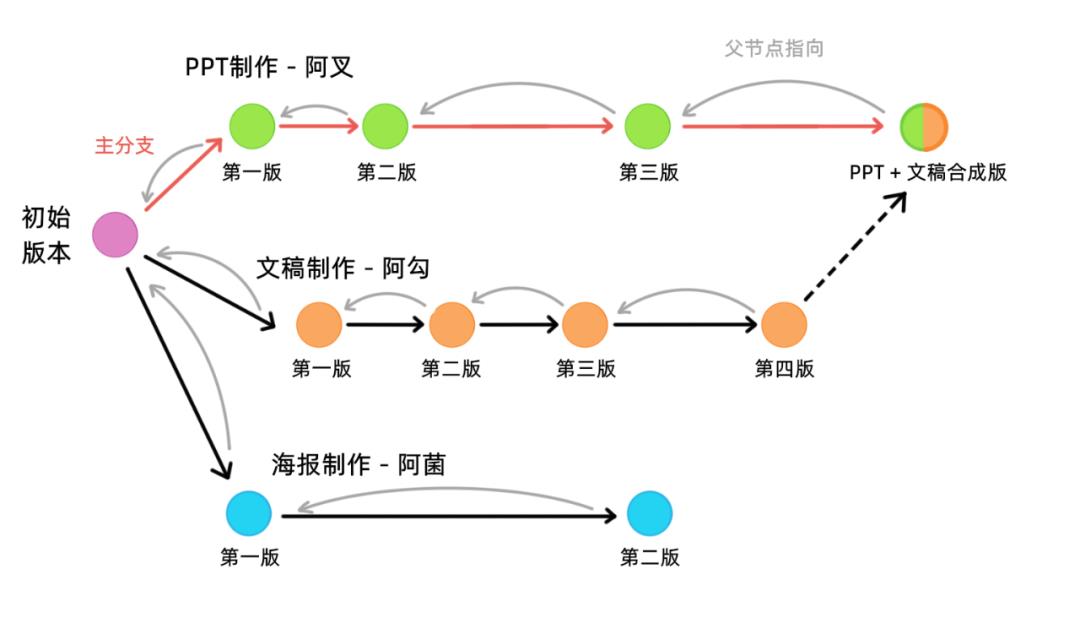
为了不影响最开始的版本,他们三个每人拉出来一条分支进行工作,每个工作阶段的内容照样进行版本管理:
可能有同学会问:阿菌,你设计的 commit object 不是有一个父指针么?每个父指针指向上一个 commit object,在上面的图里,最终版的父指针指向谁呀?貌似一共有三个父节点?
是这样的,有时候我们数据结构设计好了,最好就不要改了,遇到现有数据结构不能掌控的场景,我们就要设计处理流程,这就是所谓的“算法”吧......(毕竟增删改查某种程度也算是算法......)
我们总是说:软件 = 数据结构 + 算法,下面阿菌带大家还原这个处理流程的设计。
因为我们的 commit object 只能指向一个父节点,于是我们设计的合并流程是这样子的:最终的合并,交给一个人处理(站在一条分支上处理,假设叫它主分支)。
从上图可以看到,我们以阿叉制作PPT的分支作为主分支,把阿勾的分支内容合并到了阿叉的分支上,这样阿叉的分支就多出来一个合并节点,这个合并节点指向的是阿叉分支上的前一个节点,这样一来,PPT 和文稿内容就合并到主分支上了。
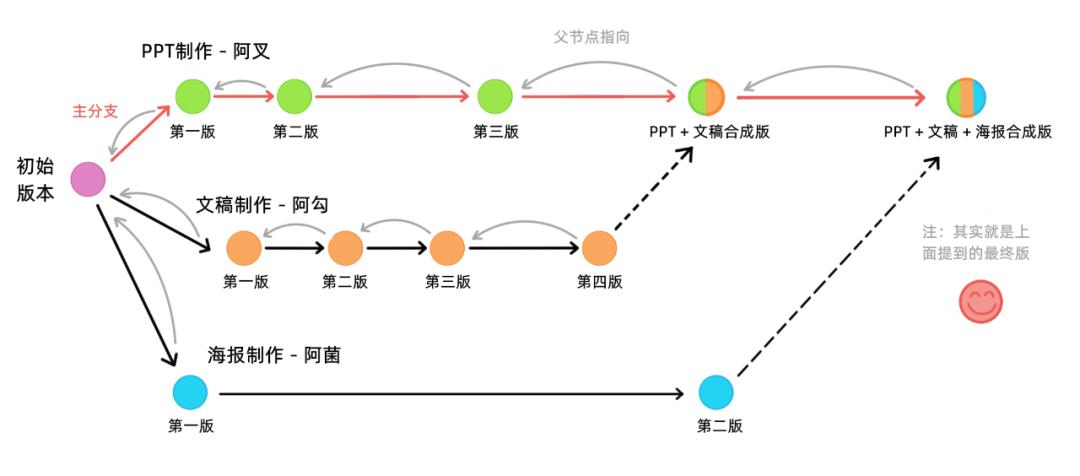
滴滴滴~ 下面我们把阿菌那坏小子制作的海报也合并上去:
这样一来,我们既没有破坏原来的数据结构,也没有破坏软件的设计:一个存档版本管理软件,我们可以在阿叉这条主分支上找到所有的内容。
当然阿菌这样的设计不太好,我们其实可以设计得更好,比如说单独抽出来一条主分支,阿叉,阿勾,阿菌制作各自内容的时候单独拉分支(一共四条分支),每个人都制作好了,再合并回主分支。这样
主分支就会非常干净利落
,而不是像现在这样,在主分支上,还能看到阿叉的各个版本......
呃呃,软件开发就是这样的啦,在摸索中不断总结最佳实践!
估计大家看着看着就能看出来啦:阿菌,你这讲的不是 Git 么?
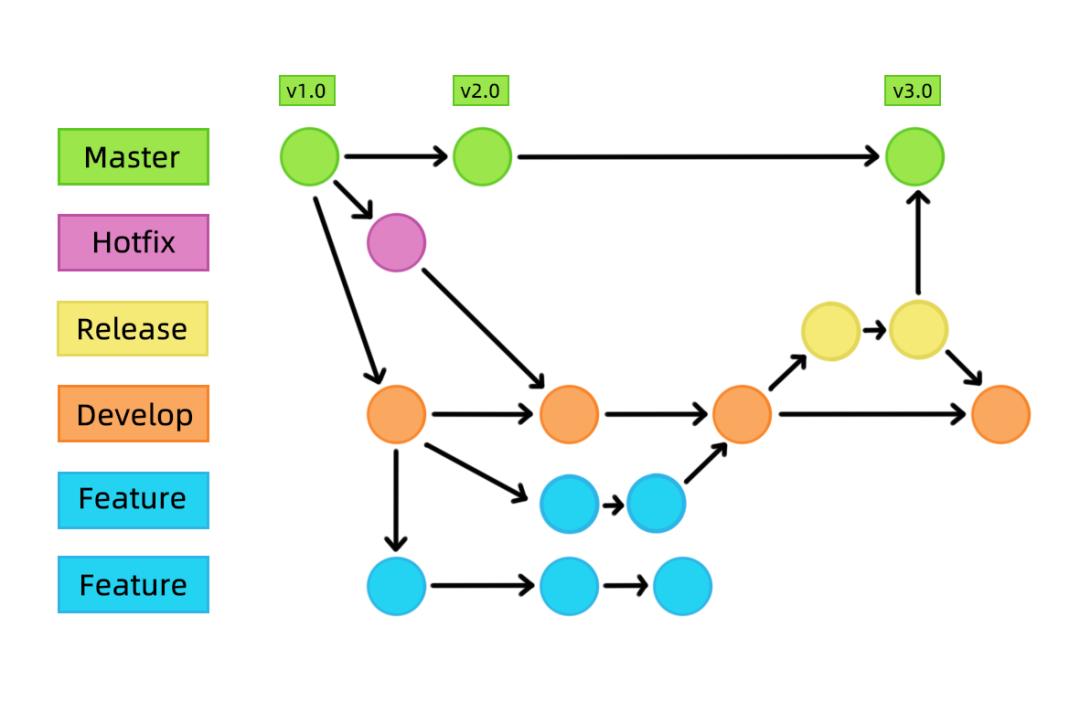
没错,阿菌今天介绍的就是一款叫 Git 的分布式版本控制软件-版本控制部分的底层设计原理,现在大多数程序员都是基于 Git 进行协同开发的。和上面例子不同的是,程序员写的是代码文件,而不是文稿和PPT。有时候一个功能往往会有好几个程序员开发,大家可以理解为分组开发。常见主流的协作流程会是这样的:
一、master 分支存储了正式发布的历史版本,是一个功能完整且随时可以发布到线上进行部署的可用分支。
二、Hotfix 分支是用来修复线上bug,快速打补丁的。
至于每个分支具体的用法,大家可以到网上搜索,根据阿菌的经验,
其实看了也没啥用。
只有真正到公司里参与到开发项目中,
才能真正领会到各个分支的意义。
今天介绍的内容,是 Git 这款软件最基本的原理,在搞清楚了这个的基础上使用 Git,会轻松很多。Git 的另一个重要的特色是:分布式。也就是说,它是用于多人(公司或团队)协同进行存档和版本控制的。
有位大神看了我们的文章后认为如果我们能讲讲分布式,那这篇文章会更加加分,那肯定没问题。
我们现代的程序员,写代码的时候上来就是用 Git,理所应当以为版本管理系统都是现在分布式的样子。殊不知,以前的版本管理系统都是集中式的。
我们先简单介绍一下什么叫集中式,还是用本文的案例:
像上图这样,有一个集中的地方管理所有文件,每个人开发只要拉取特定文件进行开发,这叫集中式开发。
-
效率。中央仓库出了问题,所有人都无法正常工作了,因为大家都依赖他拉取和推送文件。
-
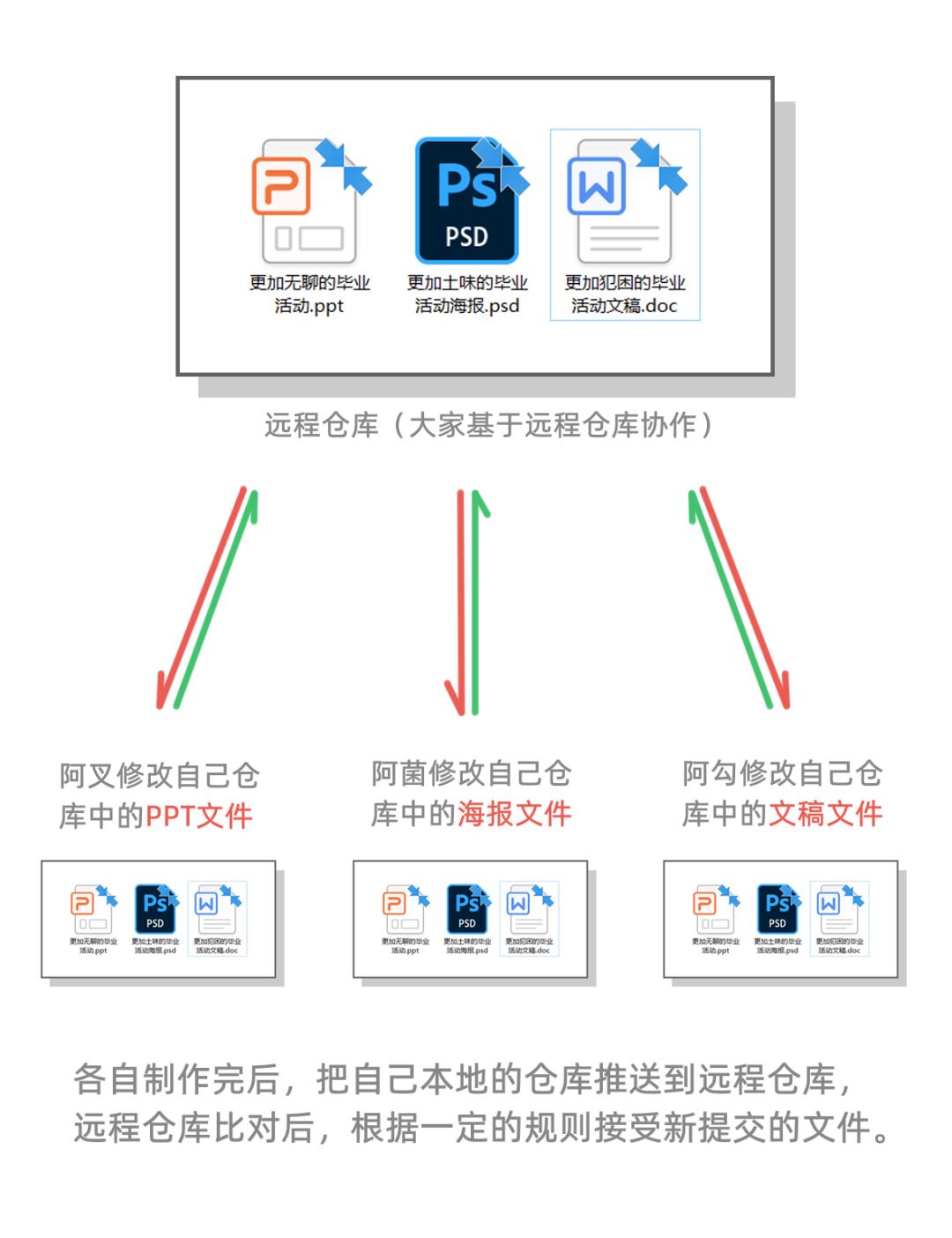
针对以上弊端,我们能想到的,最直接的处理方式是:每个人都保存一份仓库的拷贝。如下图所示:
有同学会问,欸,阿菌,那我还有必要学 SVN 那些集中式版本管理软件么?
当然不用,Git 的出现,已经完全颠覆了过去的集中式版本管理系统。SVN 的版本管理策略和 Git 还是有很大区别的,阿菌没有说
SVN 不好,大家要知道,这里涉及的原因很多。这是时代变化所引起的变革,以及大环境所需导致的变迁,不存在孰好孰坏的问题。
我们尝试开辟一个角度想(不一定对):在以前的年代,内存,磁盘,计算资源都是很宝贵的,当时的机器根本就不适宜支持我们在每台机器上,保存完整的工程文件存档,也不可能采用 Git 这种压缩保存整个文件原信息的策略(增量保存能省很多空间,代价是牺牲性能)。所以,使用 SVN 这样集中式的版本管理系统,或许是个很好的选择。
现在机器越来越好了,磁盘大,网络快,直接就能在每个人的机器上保存完整副本。更重要的是,
Git 本身的设计非常优良
,它站在 Linux 操作系统肩上发家(最初是因为想分布式开发 Linux 而创造的 Git),后来还发展出了 Github 这样的开源社区。慢慢地,大家都愿意迁移到 Git 上开发了。
再换一个角度:大家想想,如果一个工程真的非常非常庞大,单台机器不能拉取整个工程进行开发,集中式的版本控制无疑是更好的选择。
但是现在业界流行微服务,
系统的拆分解耦是大势所趋
,这也注定了大工程会被拆分成小工程。而体量小的工程,恰好非常适合使用分布式版本控制。
存在即合理,任何一项技术,我们在评价它时,都不能脱离时代背景和现实需求。
我们这篇文章不教操作,关于 Git 操作的文章,网上一抓一大把,各种奇技淫巧,应有尽有。
各位如果想自己玩出奇技淫巧,那就跟着阿菌一起深入数据结构探索原理吧,那些只教奇技淫巧的博客,通常都不怎么说原理,懂了原理才能更好地发掘奇技淫巧吖!
有同学可能会问:阿菌,原理懂了,但是不太能和操作对应起来,我们平时用 Git,就是一条 pull 和一条 push,两条指令走天下。分支我是懂了,但这些分布式操作我还不太懂,不太能联系起来。。。
阿菌实习时的导师,曾教给阿菌一个非常重要的学习方法:当我们看到一个没接触过的东西的时候,我们首先要想 —— 如果这个东西交给你来做,你会怎么实现?

阿菌看过一点点 Git 的源码,也翻过官方文档,但是不可能在这里把这些东西全倒出来,我们尝试引导大家一点点思考。(最终的深入精确学习,还是建议大家看源码文档,想要深入学一个东西,这苦是不得不吃的)
我们沿用这个图进行讲解,在看之前,大家务必先搞清楚 object 的底层数据结构,以及怎样把 object 串联起来形成分支。我们先回顾一下当时的总览图:
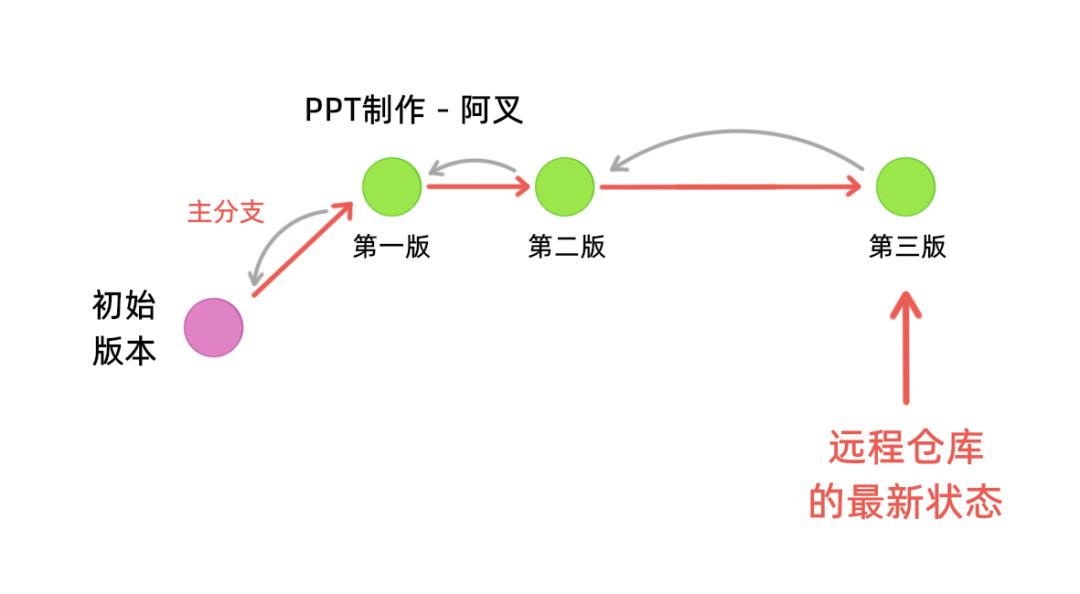
之前我们提到以阿叉作为主分支,是一个不太好的设计,但是不影响我们讲解,我们假设阿叉已经开发完了,远程仓库就是阿叉的仓库。
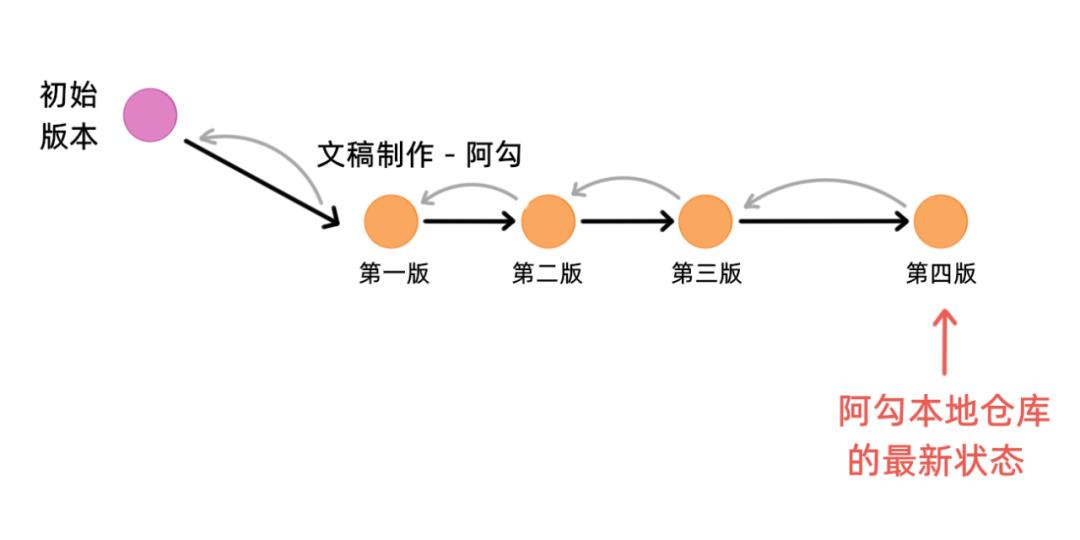
现在阿勾已经开发完了,阿勾会把他的本地仓库推送到远程仓库,阿勾的仓库是这样子的:
阿菌能猜到一些小伙伴看到这懵逼了,千万不能懵逼,一定要全文串联回忆,我们的版本管理软件,就是一条链表加树,这里的每个圈圈都是一个 commit object,他们是对应的,阿菌只是用一个小圈圈代替,以节省位置:
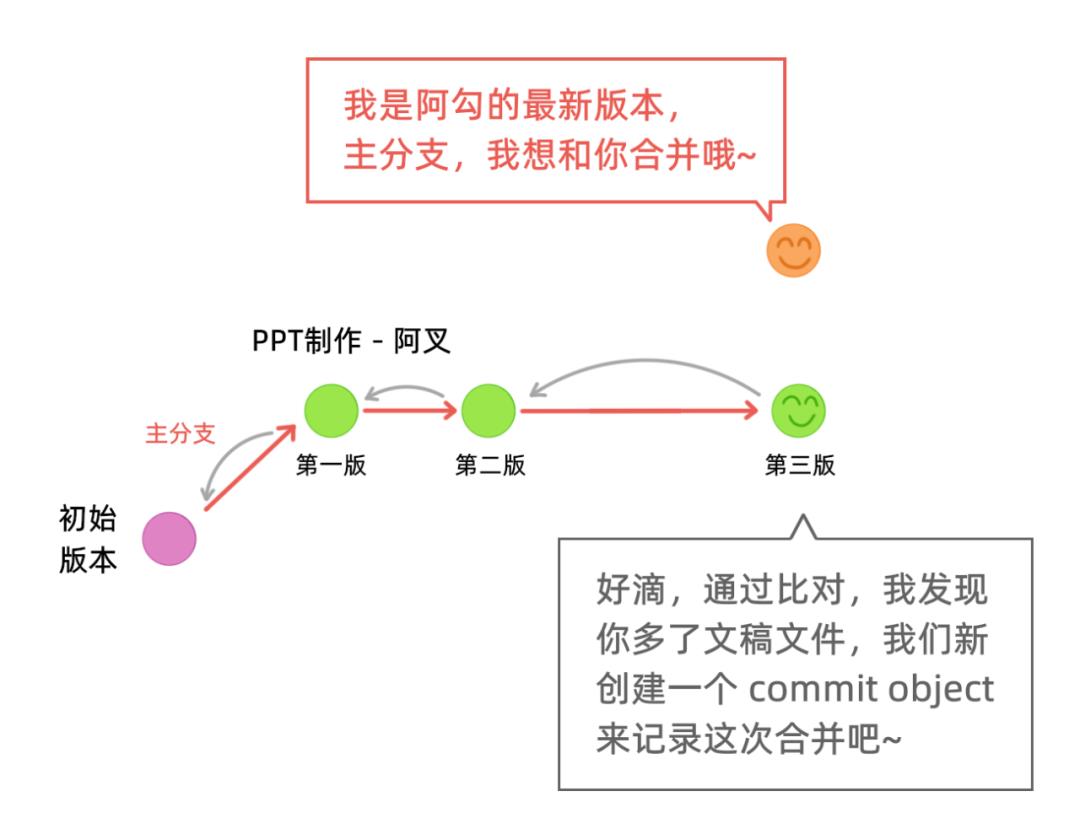
明白了这个之后,我们来看一下合并的流程,首先阿勾会把自己的本地仓库推送到远程仓库(主分支):
现在,大家明白,为什么合并分支会多出来一个提交了吧?
还有一些常用的指令,什么 rebase 吖,
不就是调整链表么?
不懂的话可以去刷刷算法题,打打基础。
不过,多人一起办公难免会遇到一些问题,比如说大家同时修改了一个文件,发生了冲突。但懂了原理后这都很好解决,大家沟通一下用谁修改的版本就好了,协商出一个不冲突的版本,然后合并就行。合并的原理上文已经提到啦,一通百通。
也正由于是多人协同办公,注定我们的软件要具备联网的能力,涉及许多网络交互,这是分布式软件必不可少滴内容。但大家要相信,最底层原理懂了,具体如何使用,如何与他人在网络中合作,那都是很简单的内容,学一个软件关键是要学透它的底层数据结构,学明白后,上层操作都会引刃而解的。
前两天我们发布了一篇文章,能帮助大家进一步深入学习并掌握 Git 的底层原理: 。
大家可以抽一个上午的时间跟着阿菌简单操作一下,毕竟 Talk is easy,想学会点东西,还是得动手实践。
阿菌是用 Go 语言写的,写得比较烂,有兴趣的同学用自己熟悉的语言写就好啦,毕竟写代码只是实现想法,撸起袖子加油干就好~
想了一下,下一篇技术类的科普或许可以给大家介绍一下爬虫,因为爬虫这个技能点容易延申到单机,集群,分布式这些听起来高大上的东西,我们会尽最大的努力带有兴趣的小伙伴入个门儿,有趣的理论加实践,学起来可带劲儿啦!
不想错过的同学们记得星标我们公众号哦,感谢大家的支持!