图文详解大数据分布式文件系统HDFS—切片划分
Posted 老王家的喵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图文详解大数据分布式文件系统HDFS—切片划分相关的知识,希望对你有一定的参考价值。
背景
每个hdfs文件的一个切片对应一个MapReduce作业的一个map任务
那么文件的切片是怎么划分的呢?下面介绍其中一个InputFormat:TextInputFormat
作用
获取纯文本文件的逻辑切片
为每个逻辑切片创建基于行的读取器
读取器读取的内容是kv键值对,键是记录的偏移量,值是当前行文本内容
前提条件
文件内容为纯文本
hdfs的块大小默认为blockSize = 128M
在TextInputFormat前提下,计算得到的每个切片大小为splitSize = 128M
溢出阈值变量SPLIT_SLOP = 1.1(意思就是如果剩余待切分的文件长度 / splitSize < 1.1的话,那么就把剩下的文件长度当做一个逻辑切片看待,即使剩下的带切分的文件内容在2个块中存储)
切片获取
假设当前一个文本文件存储在hdfs上有N个块(不含副本块数)
前N-2个块每个块对应一个逻辑切片,如果第N-1和第N个块的大小之和除以splitSize小于等于1.1,则第N-1和第N个块被划分到一个逻辑切片中;如果第N-1和第N个块的大小之和除以splitSize大于1.1,则第N-1个块和第N个块分别对应一个逻辑切片
例:文件129M.txt是一个文件大小为129M的文件,因为blockSize为128M,因此该文件以使用了两个block存储,第一个block大小为128M,第二个block大小为1M
最开始时,文件剩余划分内容长度为129M,129M / splitSize = 1.007 < 1.1,因此该文件的第一个block和第二个block划分到一个切片了
因此该文件对应的切片数量为1
图示(未画出副本block)
例:文件150M.txt是一个文件大小为150M的文件,因为blockSize为128M,因此该文件以使用了两个block存储,第一个block大小为128M,第二个block大小为22M
最开始时,文件剩余划分内容长度为150M,150M / splitSize = 1.17 > 1.1,因此该文件的第一个block和第二个block分别对应一个切片
因此该文件对应的切片数量为2
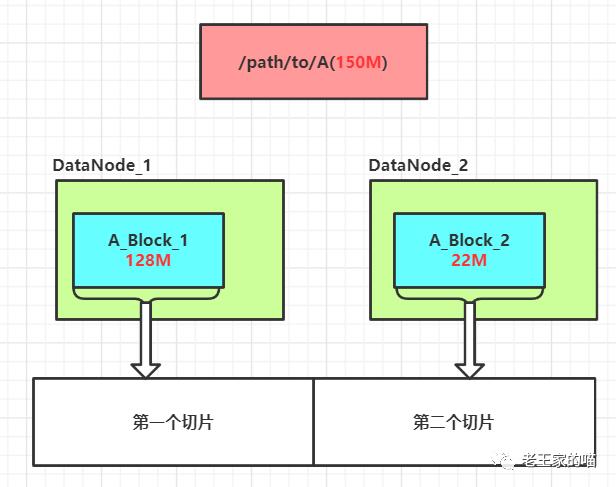
图示(未画出副本block)
代码片段
TextInputFormat获取文本文件切片源码
切片类关键属性
文件路径(文件逻辑路径)
起始偏移量
内容长度
这个起始偏移量所在数据块在哪些DataNode的磁盘上
这个数据块被缓存在哪些DataNode的内存中
切片类属性
例1:以文件大小为129M这个例子为例,该文件划分了一个切片(对应两个block),因此该切片的属性中起始偏移量start为0,内容长度length为129*1024*1024 = 135266304
例2:以上述切片例子中的第2例150M的文件为例,该例中有2个切片,第一个切片中包含该文件的第一个block,该block的大小为128M,因此该切片的属性起始偏移量start为0,内容长度length为128*1024*1024 = 134217728;第二个切片包含该文件的第二个block(内容只有22M),因此第二个切片的属性中起始偏移量start为(150-22)*1024*1024 = 134217728,内容长度length为22*1024*1024 = 23068672
以上就是TextInputFormat获取文本文件逻辑切片的过程了,后面介绍如何读取切片对应文件块的内容
这篇文章对你有用的话,点个关注呗
以上是关于图文详解大数据分布式文件系统HDFS—切片划分的主要内容,如果未能解决你的问题,请参考以下文章