P3-1 数据库连接池HikariCP
Posted java笔记123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了P3-1 数据库连接池HikariCP相关的知识,希望对你有一定的参考价值。
内容简介:数据库连接池的背景及springboot2整合HikariCP的原理
本文代码请点赞私信我(回复“代码P2”)获取链接:
背景:springboot2.4+HikariCP 3.4.5
一、背景
1.为什么需要数据库连接池
假如我们的服务器跟数据库没有部署在同一台机器,那么,服务器每次查询数据库都要先建立连接,一般都是TCP链接,建立连接就需要3次握手了,假设后台服务跟数据库的单程的访问时间需要10ms,那么光是建立连接就花了30ms,并且TCP还有慢启动的机制,实际上一次查询可能还不止1次TCP来回,查询效率就会大大降低。
为了解决上述问题,我们就需要维护一些长链接,这样就不用每次都去建立连接,毕竟建立连接除了占用时间,还需要一些其他的系统资源。另外,连接池让我们更加容易地管理,一方面是可以避免数据库资源都被某几个API占据,另一方面也可以避免资源泄露。
2.数据库连接池是什么
数据库连接池就是负责分配、管理和释放数据库的连接。在系统初始化的时候,在内存中开辟一片空间,将一定数量的数据库连接库作为对象存储在对象池里,并对外提供数据库连接的获取和归还方法。
数据库连接复用:重复使用现有的数据库长连接,可以避免连接频繁建立、关闭的开销。
统一的连接管理:释放空闲时间超过最大空闲时间的数据库连接,避免因为没有释放数据库连接而引起的数据库连接泄漏。
数据库原理图如下图所示
用户通过DataSource对象的getConnection()方法,获取一个连接。
(1)如果池中有连接,则直接将连接返回给用户
(2)如果没有连接,会调用Driver对象的connnect方法从数据库获取,拿到连接以后,可以将连接在池中放一份,然后将连接返回给调用方。连接需求方再次需要连接时,可以从池中获取,用完再还给池对象
3.HikariCP是什么
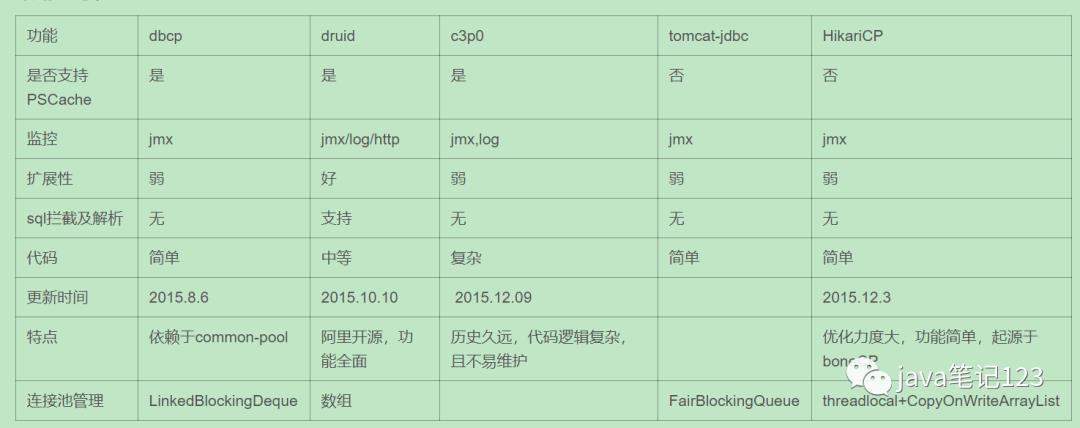
HikariCP是由日本程序员开源的一个高性能的 JDBC 连接池组件,代码非常轻量,并且速度非常的快。在HikariCP之前有一些较为稳定的数据库连接池如C3P0、Tomcat jdbc、BoneCP等,网上也有很多关于HikariCP、C3P0、Tomcat jdbc、BoneCP的性能比较和测试,在速度、稳定性方面,都证明了HikariCP的强大之处。测试结论就是
(1):性能方面 hikariCP>druid>tomcat-jdbc>dbcp>c3p0 。hikariCP的高性能得益于最大限度的避免锁竞争。
(2):druid功能最为全面,sql拦截等功能,统计数据较为全面,具有良好的扩展性。druid和hikariCP各有优劣,可根据情况选择,druid的介绍将会在下一篇博文中进行介绍。
(3):综合性能,扩展性等方面,可考虑使用druid或者hikariCP连接池。
下图为各连接池的性能对比
4.为什么HikariCP会那么快
(1)字节码精简:优化代码,直到编译后的字节码最少,使用第三方的Java字节码修改类库Javassist来生成委托实现动态代理.动态代理的实现在ProxyFactory类,速度更快,相比于JDK Proxy生成的字节码更少;
(2)优化代理和拦截器:减少代码,例如HikariCP的Statement proxy只有100行代码,只有BoneCP的十分之一;
(3)自定义数组类型(FastStatementList)代替ArrayList:避免ArrayList每次get()都要进行range check,避免调用remove()时的从头到尾的扫描(由于连接的特点是后获取连接的先释放)
(4)自定义集合类型(ConcurrentBag):提高并发读写的效率。
(5)针对连接中断的情况:比其他CP响应时间上有了极好的优化,响应时间为5S,会抛出SqlException异常,并且后续的getConnection()可以正常进行
(6)关于Connection的操作:另外在Java代码中,很多都是在使用完之后直接关闭连接,以前都是从头到尾遍历,来关闭对应的Connection,而HikariCP则是从尾部对Connection集合进行扫描,整体上来说,从尾部开始的性能更好一些。
5.HikariCP参数配置
Springboot2之后集成了hikariCP,使用 spring-boot-starter-jdbc 或 spring-boot-starter-data-jpa ,会自动添加对 HikariCP 的依赖,也就是说此时使用 HikariCP 。当然你也可以强制使用其它的连接池技术,可以通过在 application.properties 或 application.yml 中配置 spring.datasource.type 指定。
执行数据库操作之后可以在控制台上看出

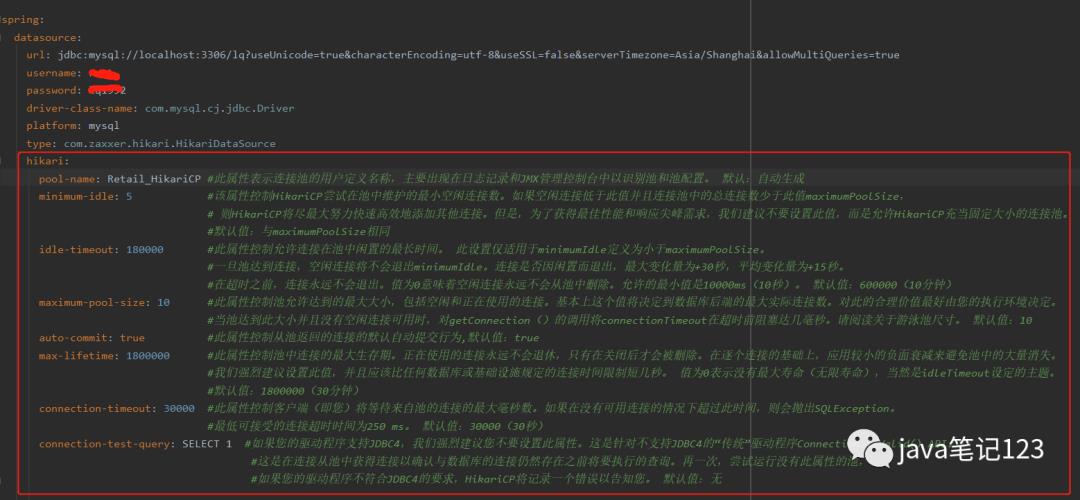
其他参数也可以在yaml文件中配置,如
pool-name
minimum-idle
idle-timeout
maximum-pool-size
auto-commit
max-lifetime
connection-timeout
connection-test-query
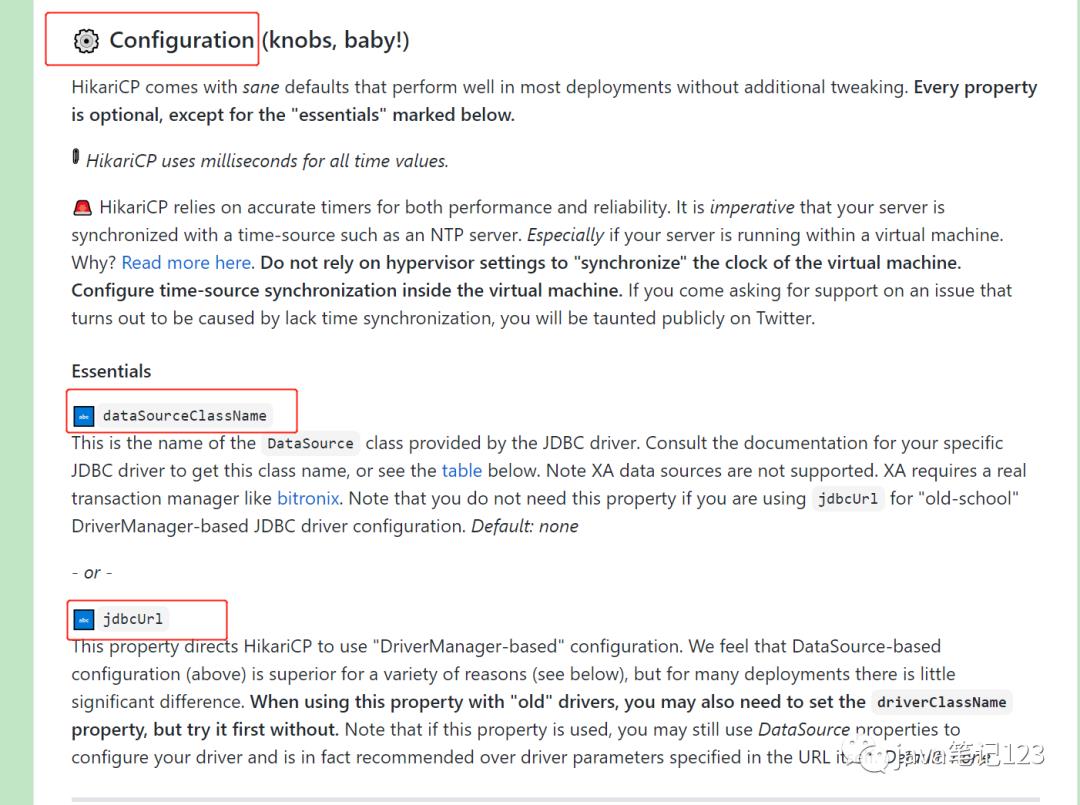
更多参数信息可参考官网信息
https://github.com/brettwooldridge/HikariCP#configuration-knobs-baby
二、源码分析
1-springboot是如何整合的HikariCP?
我们先看下包的依赖关系,从依赖图中可以看出,包spring-boot-starter-jdbc包含了两个包,一个是spring-jdbc(包含对Spring 对JDBC 数据访问进行封装的所有类),另一个就是HikariCP,也就说我们springboot2版本以上应用的pom文件中添加spring-boot-starter-jdbc这个包就可以使用HikariCP了(springboot2将HikariCP作为了默认的数据库连接池)
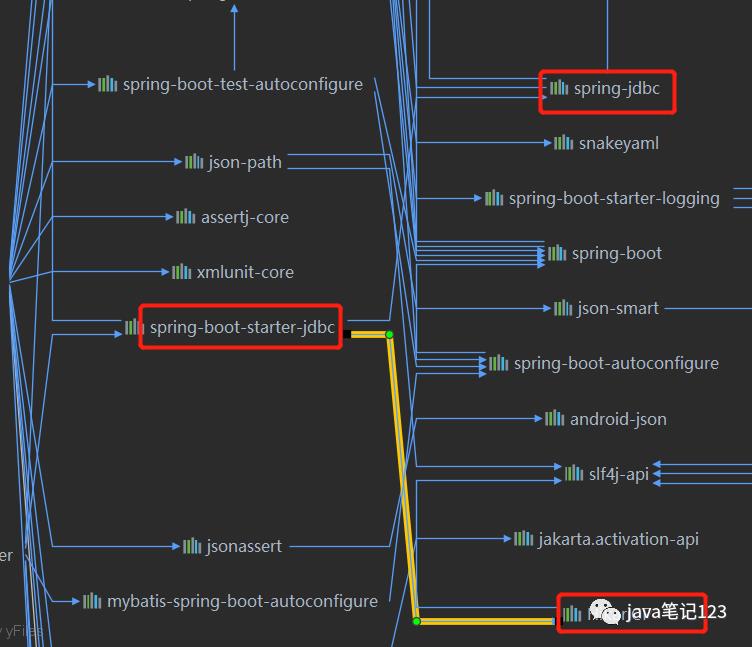
Spring Boot实现了自动加载DataSource及相关配置。Spring Boot启动后会调org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration。也就是说入口是DataSourceAutoConfiguration :
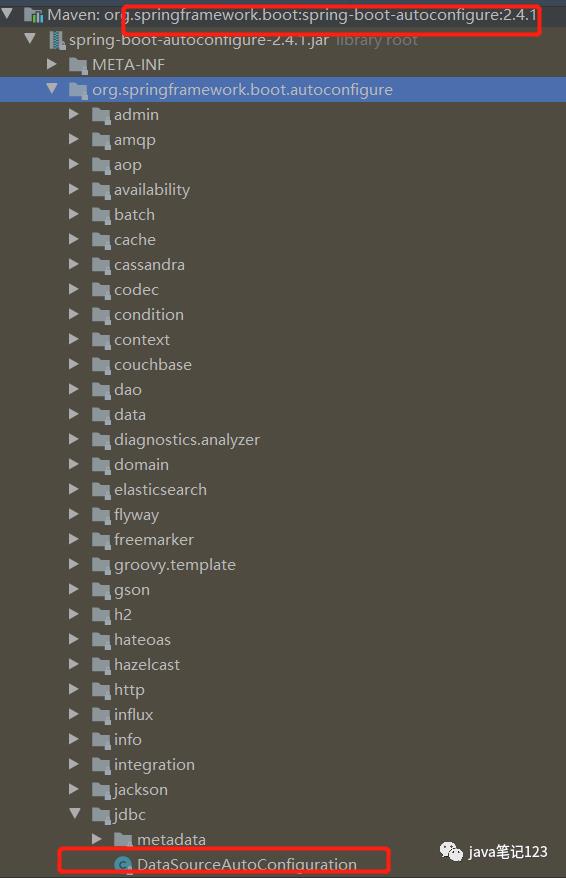
我们看下DataSourceAutoConfiguration这个类的源码
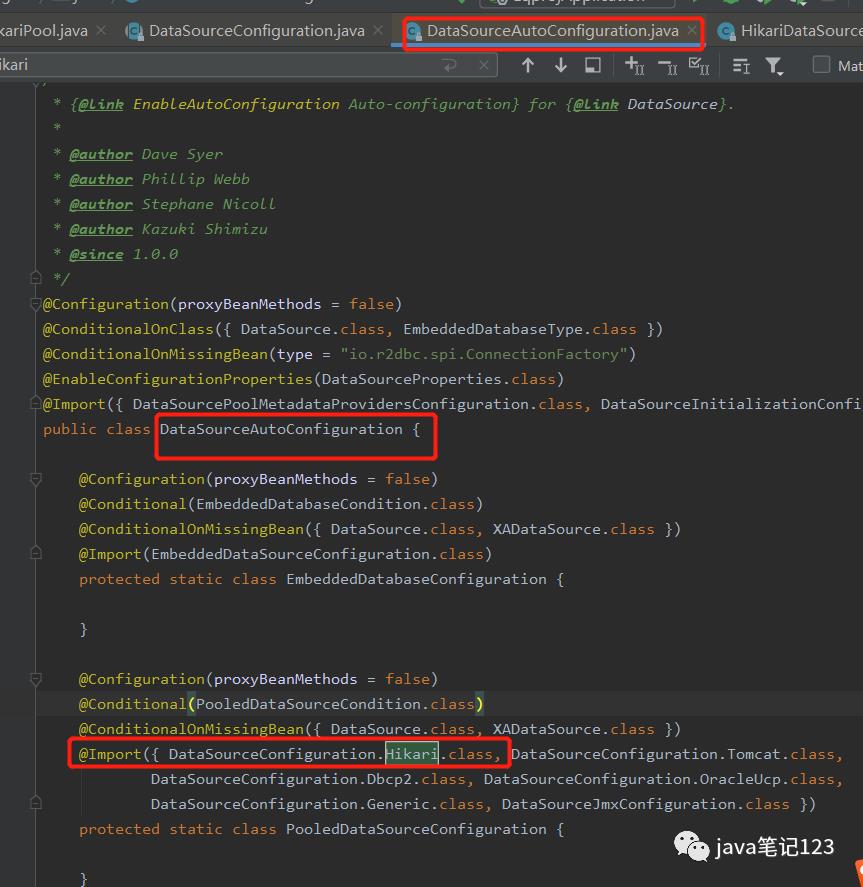
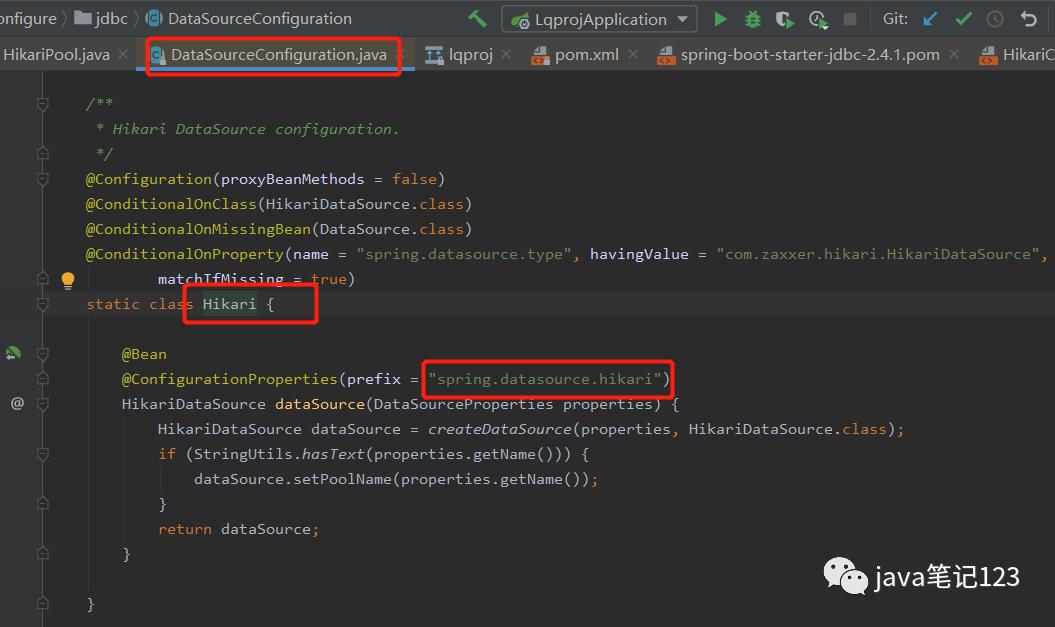
发现在DataSourceAutoConfiguration中引入了Hikari类,进去该类看一下,发现它通过 @Bean 方式创建了 com.zaxxer.hikari.HikariDataSource 并且通过@ConfigurationProperties(prefix = "spring.datasource.hikari") 方式自动把在 yaml文件中的配置的spring.datasource.hikari.* 相关的连接池配置信息注入到创建的HikariDataSource实例中。
 接下来我们慢慢分析
接下来我们慢慢分析
2-首先介绍下DataSourceAutoConfiguration类
我们看下DataSourceAutoConfiguration类的源码(更多DataSourceAutoConfiguration源码解析可参考https://blog.csdn.net/kangsa998/article/details/90231518)
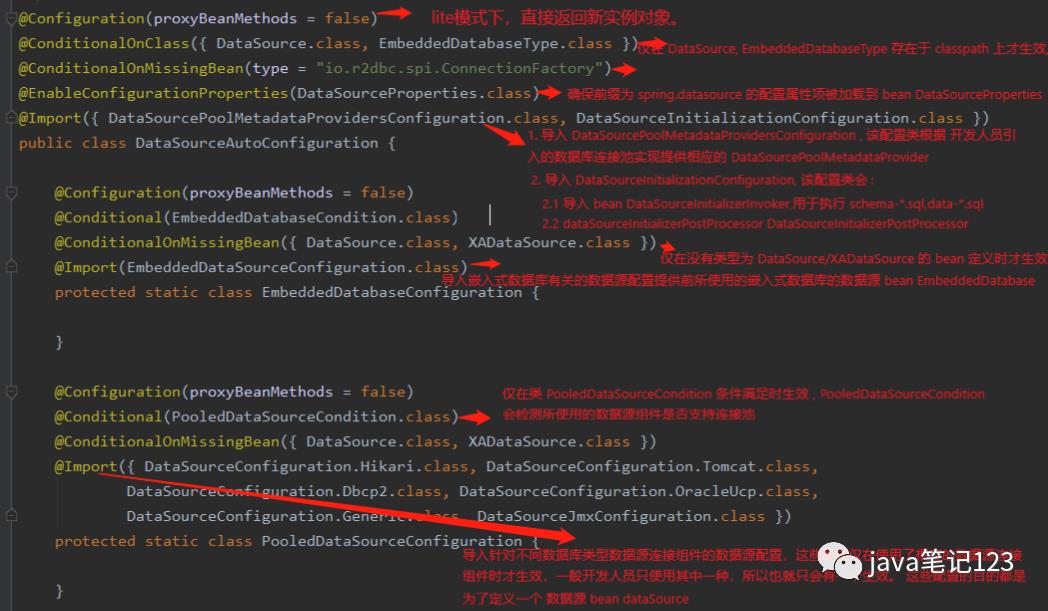
从源码可以看出DataSourceAutoConfiguration中有两个嵌套类EmbeddedDatabaseConfiguration和PooledDataSourceConfiguration。
(1)EmbeddedDatabaseConfiguration表示如果开发人员使用的是嵌入式数据库H2,Derby或者HSQL(从EmbeddedDatabaseType类可以看出),则会使用EmbeddedDataSourceConfiguration定义数据源bean
(2)PooledDataSourceConfiguration表示Spring Boot还支持一些实现Pool的DataSourceHikariDataSource是Spring Boot的默认选择(DataSourceBuilder中DATA_SOURCE_TYPE_NAMES[0] = com.zaxxer.hikari.HikariDataSource)。所以,当application.yml文件中做如下配置时,Spring Boot默认使用HikariDataSource数据库连接池。
接下来就介绍下DataSourceConfiguration 类
3-DataSourceConfiguration 类
DataSourceConfiguration是一个抽象类,其中包含五个DataSource configuration:Tomcat Pool、Hikari、DBCP、Oracle UCP、Generic这五个都是嵌套类,本文以Hikari为例进行介绍,看下Hikari类
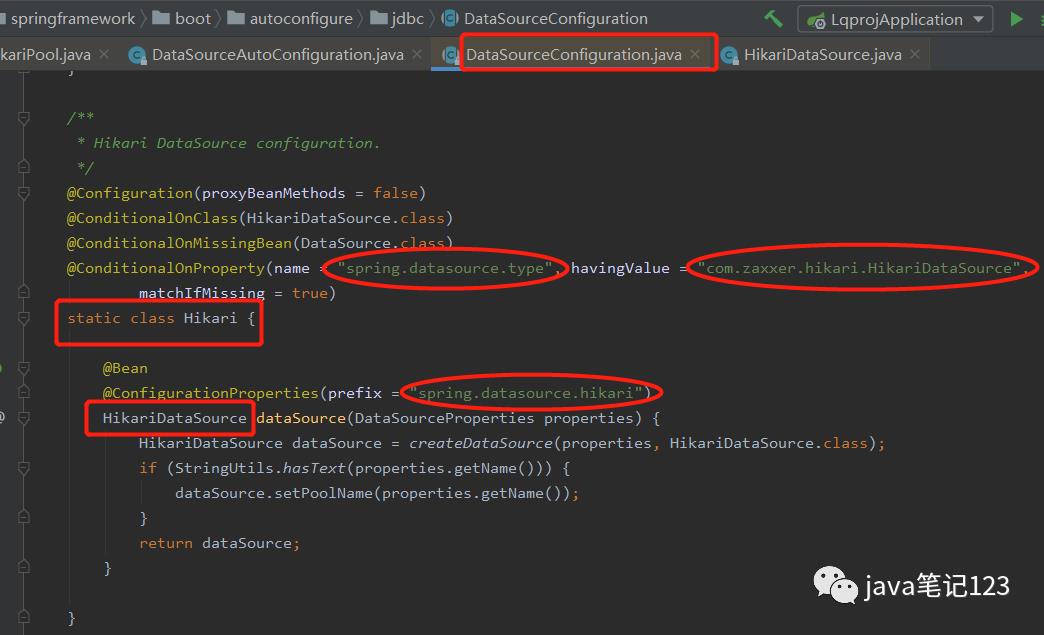
当application.yml文件中配置spring.datasource.type = com.zaxxer.hikari.HikariDataSource时,会使用HikariDataSource作为数据库连接池(springboot2中它已是默认选择,可以不写,其他类型需要写)。Hikari的配置信息主要从两个类中读取,一个是DataSourceProperties,另一个则是HikariDataSource的父类HikariConfig。


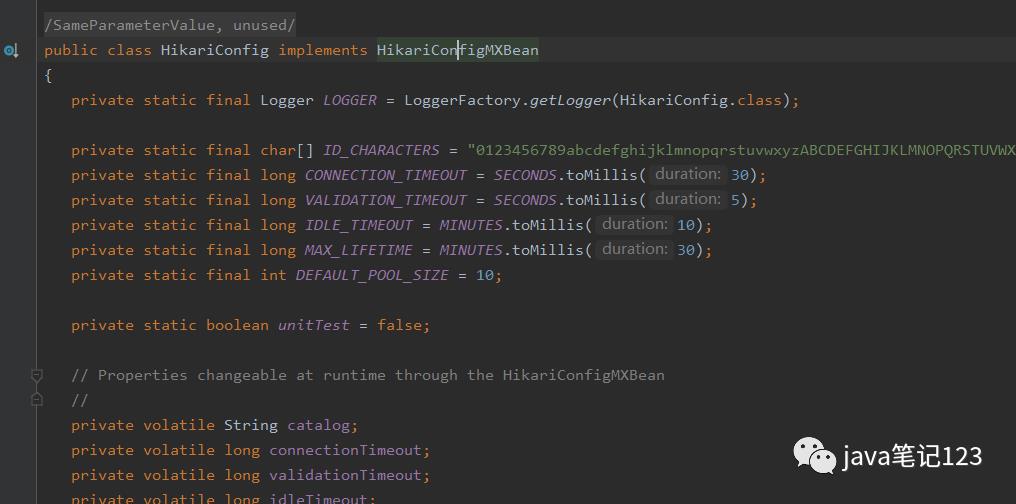
4-HikariDataSource类
接下来介绍下的将是重头戏---Hikari的核心类HikariDataSource
我们会发现属性里有两个HikariPool,
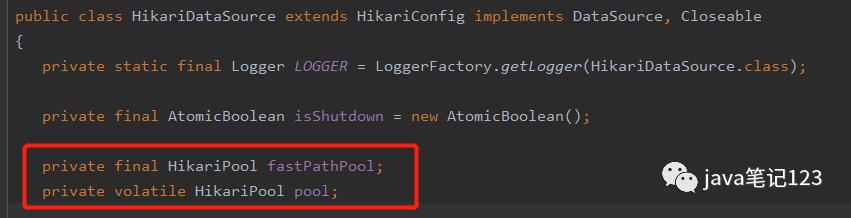
两个HikariPool的不同取值代表了不同的配置方式:
配置方式一:当通过无参构造new HikariDataSource()来创建HikariDataSource并手动 配置时,fastPathPool 为空,pool 不为空(在第一次 getConnectionI() 时初始化);
配置方式二:当通过有参构造new HikariDataSource(HikariConfig configuration)来创建HikariDataSource时,fastPathPool 和 pool 是非空且相同的;
两种方式源码如下所示:
要注意的是pool变量使用了volatile这个关键字,原因是new一个对象并不是一个原子操作,要经过以下步骤:给pool分配内存->调用构造函数初始化成员变量->将pool对象指向分配的内存(此步骤完成pool即为非空)
没有volatile关键字上面这3个步骤可能由于指令重排序令pool在多线程下未正确初始化即被使用则报错。volatile可禁止指令重排序,并强制本地线程去主存中读取pool变量。所以fastPathPool的效率会比pool要高,所以推荐使用HikariDataSource有参构造函数进行初始化。
HikariDataSource最重要的就是实现了DataSource接口的getConnection方法,在该方法中真正创建连接池(即第一次获取连接则去创建连接池))
主要流程如下:
(1)判断 当前的 dataSource 是否关闭,如果关闭 ,抛出异常
(2)判断fastPathPool 是否为null ,不为空,则返回fastPathPool.getConnection()
(3)判断当前的pool 是否为null ,如果为空, 初始化创建HikariPool对象,不为空 ,返回 result.getConnection()
好了,今天就先介绍这么多,下篇文章将会Hikari连接池的重头戏-HikariPool,这个类将会揭密Hikari连接池这么优秀的原因。
参考资料 :
https://github.com/brettwooldridge/HikariCP (官方文档)
https://www.jianshu.com/nb/46657191
https://www.jianshu.com/p/85953c751ace
https://www.toutiao.com/a6749802660993434125/
https://www.cnblogs.com/storml/p/8611388.html
https://www.cnblogs.com/jackion5/p/14193025.html
http://www.gzywkj.com/post/6985.html
https://blog.csdn.net/u013257767/article/details/106956244
以上是关于P3-1 数据库连接池HikariCP的主要内容,如果未能解决你的问题,请参考以下文章