ciscn2021 ctf线上赛baby.bc wp(#超详细,带逆向新手走过一个又一个小坑)
Posted 漫小牛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ciscn2021 ctf线上赛baby.bc wp(#超详细,带逆向新手走过一个又一个小坑)相关的知识,希望对你有一定的参考价值。
文章目录
引言
这是ciscn2021中的一道Reverse题,将附件进行下载,名称为baby.bc,文件名为baby,表示这道题的内容与baby有关(baby一般是刚出生的小孩子,至少是5岁以下)。扩展名为bc,有可能不是二进制文件。最初下发这道题时,给的是一个存在问题的baby.bc文件,直到当天19点多在qq群中群发消息后,更新了baby.bc。由于没有关注qq群发消息,比赛时并没有解出这道题的flag,为了搞清楚这道题出问题的地方,赛后再向主办方索取更新后的baby.bc,也未能获得。我们权且用旧的baby.bc文件来写writeup,但这丝毫不影响相关知识点的讲解和flag的求解。
题目附件:
链接:https://pan.baidu.com/s/13TheaHB7XcbGnBp-M1N5Rg
提取码:k4pm
第一步、分析文件类型
1.可执行文件判断
使用Exeinfo PE查看文件的类型,该工具主要用来查看文件是否为可执行文件,是否为动态链接库,是否有壳以及运行的操作系统等等。具体情况见下图:
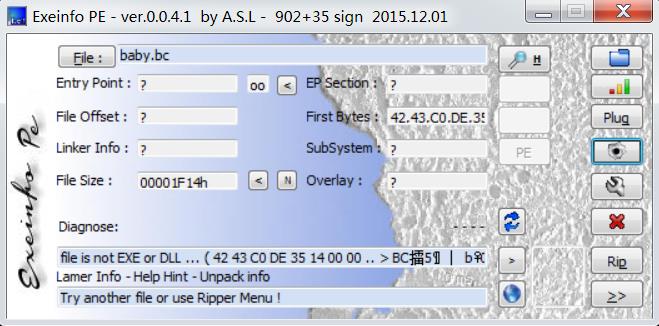
结果显示,该文件并非可执行文件。
2.继续分析文件类型
既然不是可执行文件,那么是否为源文件呢?用任意的文本编辑器打开该文件,见下图:

图中是大量的乱码,可知该文件也不是某种编程语言的源文件。
既不是二进制文件,也不是源文件,接下来应该如何继续分析该文件的文件类型呢?到这里也是很多新手所面临的第一个坑:接下来如何分析文件类型?
3.解决第一个坑-前奏
最通常的思路是拿百度看看以bc为扩展名的文件是什么文件?经过百度,我们可能会得到如下一些搜索结果:

既然百度到了这些可能的文件格式,那么,我们是否要沿着这种BT文件或Adobe Bridge的缓存文件进行分析呢?若打算对这些文件格式进行分析,就需要查找相关文档并对这些文件进行解析,并从文件的解析中找到flag。如果我们沿着这条路摸着黑走下去,将会渐渐的偏离主线和中心,那么除了这种思路,还有其他的思路分支吗?同时,带来的一个问题是,我们如何确定是选择亦或是抛弃当前的文件解析思路?我们先来解决第二个问题,请看下一小节。
4.reverse题的输入可能是什么?
为了解决第二个问题,即“我们如何确定是选择亦或是抛弃当前的文件解析思路?”,该问题的答案取决于文件是否符合reverse题型的输入,那么这个问题就等价的转化为“reverse题的输入可能是什么?”,首先想到的是二进制可执行文件(含动态链接库.dll和.so等),其次想到的是源文件,如.c。那么,除了以上两种最为典型的reverse输入外,还有其他文件格式吗?为了解决这个问题,需要简要插播一段儿编译器从源文件到可执行文件的过程,见下图:

为了省事儿,懒得重新画图了,这是我最近看的加州公立大学的一节老外的课,为什么搞ctf要研究compiler,尤其是compiler’s program analysis,including dataflow analysis,cfg analysis & pointer analysis(tail Front end),of course including optimizer。按ctf的行话来说,是reverse爸爸、pwn爷爷、misc儿子和web孙子,如果你懂上面的英文对应的关键技术,可以更为深入的搞自动化漏洞挖掘、污点分析、符号执行、程序切片等等,更为精确的程序分析有利于中后端优化和更为深入的漏洞解析,compiler(program analysis&optimizer)+pwn/reverse is definitely grandfather’s dad。
以上这幅图,给出了从源代码的x=ab+cd到一些load、add、store这些汇编的过程,很显然,除了我们刚才讨论的最前端的源码和接近可执行的汇编,还有很多IR,即中间表示,这些中间表示有可能是形如汇编的扁平化结构,也有可能是形如AST的结构,即抽象语法树。在源代码和可执行之间的IR可能存在很多级,如Open64中的IR就包括veri high whirl,high whirl,middle whirl,low whirl和very low whirl,而gcc则包括 GENERIC、GIMPLE和RTL,这些ir除了保存在编译器执行过程中的内存外,还可保存为中间文件。这里得出的结论是,compier的中间文件也可能是revserse题目的输入。那么现在我们再来回答“reverse题型的输入可能是什么?”这个问题,答案是:从源文件到二进制文件编译过程中所有可能的文件,如源文件.c、任何形式的ir、汇编.s、目标文件.obj、可执行文件elf等等。
5.继续解决第一个坑
沿着4的分析继续走,显然BT和ADOBE缓存这种文件跟compiler的source到binary之间的文件没有一毛钱的关系。那么,是不是到这里,我们就要调到坑里了(╥_╥)?到这里,该搬出来大家都知道却又用的不多的工具了,linux下的file。虽然,各种windows下的PE工具用的不亦乐乎,但有必要在解题过程中采用“多平台、多工具、多版本”的思维,权且称之为互补性原理:不同平台下相同工具,具有互补性;不同平台下功能相似的工具,具有互补性;同一工具的不同版本,具有互补性。
仅仅是使用了一个file命令,老鸟看了,显然会鄙视这种冠冕堂皇的包装,不扯了,直接给出跨过第一个坑的结果:
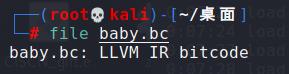
LLVM IR bitcode,某种形式的LLVM中间表示(如果不知道LLVM是编译器的就自己百度吧)。到这里,我们从baby.bc积累了第一条经验,经验一:reverse题目最可能的形式是二进制文件,其次是源文件和某种形式的IR。
第二步、明确分析的对象
1.确定“开始干”的优先级(二坑)
我们拿到了IR,面临了第二个坑:怎么分析这个IR?。在真正“开始干”之前,并不是直接开始分析我们拿到的文件,很多新手拿到IR文件后就直接解析IR格式,或者解析IR可以直接转换的格式,这种思路并不可取。那么,最关键的是要明确分析的对象是啥?这就看看IR可以转换为什么,以及这些转换后的东西又可以转换为什么吧。直接给图:
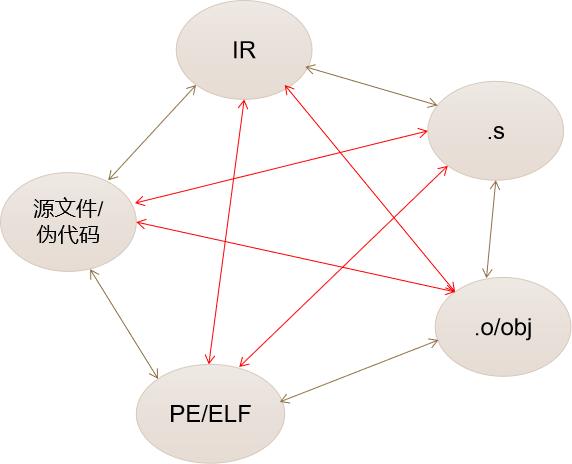
虽然画了个比较丑陋的图,但大家应该看的明白,大佬可以略过不要盯着细节,这幅图要告诉新手的是这一堆文件格式是可以相互转化的,只要拿到任何一个文件,就可以直接或间接的转换并得到其他所有的文件,换句话说,是一种“只拿了一把刀,就好像有了十八班兵器”的感觉,既然有个十八班兵器,问题就转化为这一节的标题,即“确定“开始干”的优先级?”。到这里,我们得到了第二条经验,经验二:源代码/伪代码具有最高的优先级,其次是汇编(PE、ELF、.o、.obj的机器码和汇编一一对应,不考虑),最后是IR。如果你是一个编译器的老程序员,也不建议直接分析各种层次的IR,IR包含了大量的中间信息,简洁度不但不如源文件,连汇编也比不了。
既然“开始干”的对象是源文件/伪代码,那么问题就转换为如何把LLVM的.bc转化为源码或伪代码。接着来看下一小节:
2.LLVM环境及代码转换
LLVM的安装可以参考https://zhuanlan.zhihu.com/p/102028114,说实话,这也是我第一次安装LLVM,安装方式有多种,如果不需要修改LLVM,可直接按编译好的二进制安装,或者使用包管理器进行安装,如进行源代码安装(wget http://release.llvm.org/9.0.0/llvm-9.0.0.src.tar.xz),需要cmake和make install,需要1-2个小时(呵呵,老鸟又开始鄙视了,工具都没准备好,还想着在24小时内编译LLVM环境)。
安装好后,就可以代码转换了,运行命令前,需要在命令行配置PATH路径,如export PATH="$PATH:/usr/local/llvm-9.0.0/bin"。
- 如果你想得到.s,可以执行命令:./llc baby.bc -o baby.s
- 如果你想得到.ll,可以执行命令:llvm-dis baby.bc -o baby.ll
- 如果你想得到可执行文件,可以执行命令:as baby.s
很多编译器可以从中间表示直接生成高级语言的c或fortran,如open64的whirl2c和whirl2f,但llvm是否支持从.ll文件或.bc文件到高级的.c呢?不多说,继续上图:
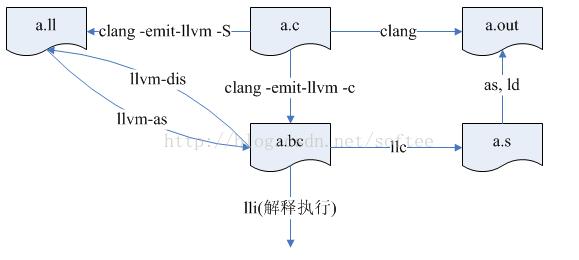
为了大家更清楚的看图,再归纳一下:
- a.c,源代码。
- a.bc,llvm的字节码的二进制形式。
- a.ll,llvm字节码的文本形式。
- a.s,机器汇编码表示的汇编文件。
- a.out,可执行的二进制文件。
既然从bc和ll无法到c,那么只能先生成可执行,再从ida到高级c的伪代码了。
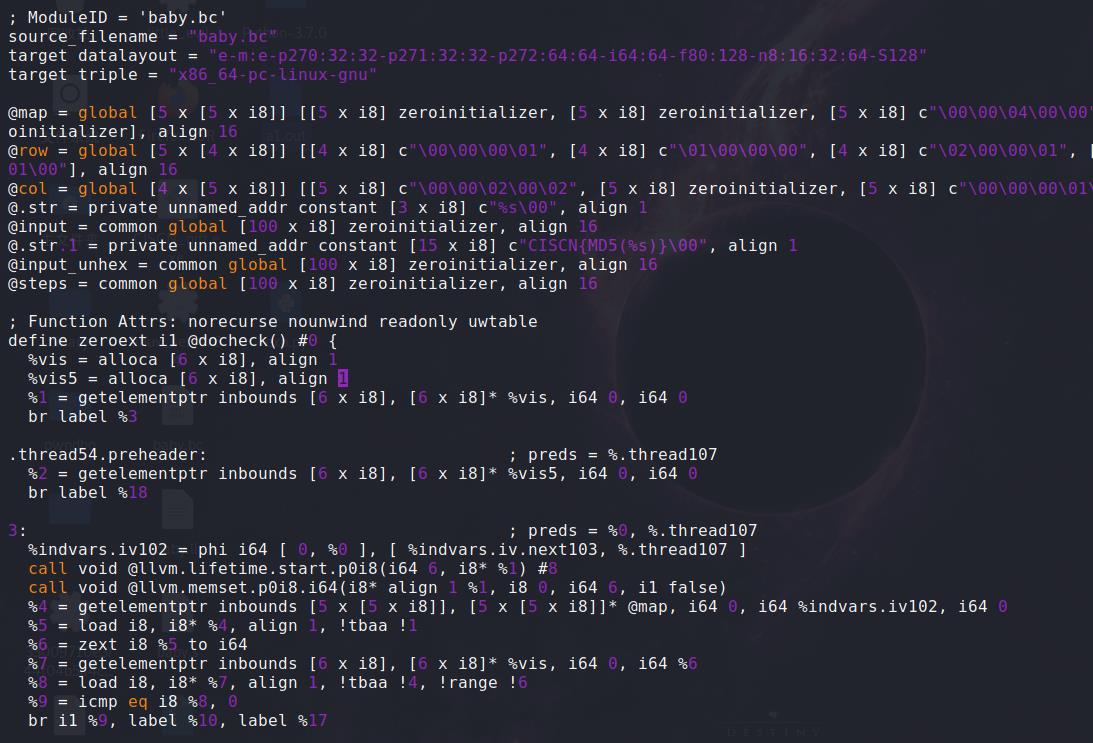
顺便看看不太好看懂的.ll字节码,除了常见搞编译的看着顺眼外,一般人可能更喜欢看.s和.c。
第三步、IDA静态分析
1.main函数
见注释:
int __cdecl main(int argc, const char **argv, const char **envp)
{
size_t v3; // rax
unsigned __int64 v4; // rcx
unsigned __int8 v5; // dl
_isoc99_scanf(&unk_595, input, envp);
if ( (unsigned int)strlen(input) == 25 ) // flag长度为25
{
if ( input[0] )
{
if ( (unsigned __int8)(input[0] - 48) > 5u )// 输入的第1个字符的ascii码不大于字符'5'
return 0;
v3 = strlen(input);
v4 = 1LL;
while ( v4 < v3 )
{
v5 = input[v4++] - 48;
if ( v5 > 5u ) // 输入的剩余24个字符的ascii码不大于字符'5'
return 0;
}
}
if ( (unsigned __int8)fill_number(input) && docheck() )// 需要两个函数返回为真
printf("CISCN{MD5(%s)}", input);
}
return 0;
}
直接看注释,不解释。
2.fill_number函数
见注释:
char __fastcall fill_number(__int64 a1)
{
char *v1; // rdi
__int64 i; // rax
char v3; // cl
char v4; // cl
char v5; // cl
char v6; // cl
char v7; // cl
v1 = (char *)(a1 + 4); // 向后偏移四个字符
for ( i = 0LL; i < 5; ++i )
{
v3 = *(v1 - 4); // 当前行第一个字符
if ( map[5 * i] ) // 既然名称是map,很可能是个二维数组
{ // 分析每一个if/else,map不为0时,当前的输入字符必须是'0';如果map为0,当前的map字符为输入字符的ascii码减去'0'的ascii码
if ( v3 != 48 )
return 0;
}
else
{
map[5 * i] = v3 - 48;
}
v4 = *(v1 - 3); // 当前行第二个字符
if ( map[5 * i + 1] )
{
if ( v4 != 48 )
return 0;
}
else
{
map[5 * i + 1] = v4 - 48;
}
v5 = *(v1 - 2); // 当前行第三个字符
if ( map[5 * i + 2] )
{
if ( v5 != 48 )
return 0;
}
else
{
map[5 * i + 2] = v5 - 48;
}
v6 = *(v1 - 1); // 当前行第四个字符
if ( map[5 * i + 3] )
{
if ( v6 != 48 )
return 0;
}
else
{
map[5 * i + 3] = v6 - 48;
}
v7 = *v1; // 当前行第五个字符
if ( map[5 * i + 4] )
{
if ( v7 != 48 )
return 0;
}
else
{
map[5 * i + 4] = v7 - 48;
}
v1 += 5;
}
return 1;
}
看一下map的初始值为:
unsigned char map[] =
{
0, 0, 0, 0, 0,
0, 0, 0, 0, 0,
0, 0, 4, 0, 0,
0, 0, 0, 3, 0,
0, 0, 0, 0, 0
};
再画一个更直观的表:
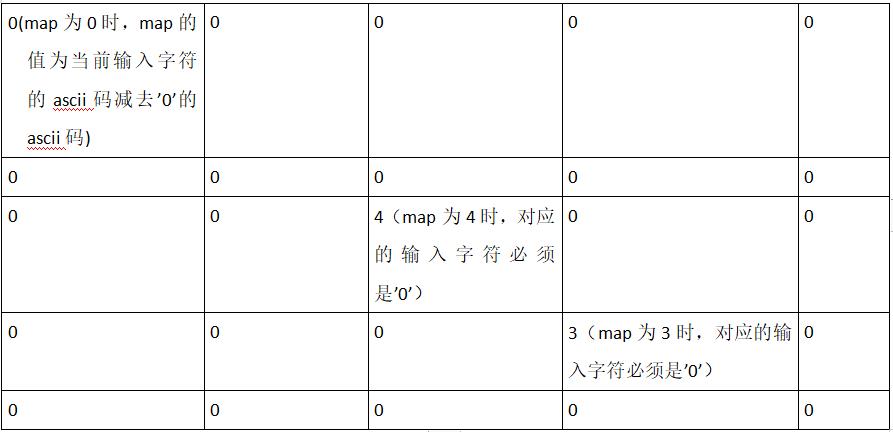
综上,fill_number函数的功能为:将5*5的map二维矩阵中的值为0时,转化为input字符对应的0-5,取值为0-5;不为0时,map值不变(map[2][2]=4,map[3][3]=3),且对应的输入值为字符’0’。
3.docheck函数
见注释:
char docheck()
{
__int64 v0; // rax
__int64 v1; // rcx
__int64 v2; // rcx
__int64 v3; // rcx
__int64 v4; // rcx
__int64 v5; // rax
__int64 v6; // rcx
__int64 v7; // rcx
__int64 v8; // rcx
__int64 v9; // rcx
__int64 v10; // rax
char v11; // cl
char v12; // cl
char v13; // cl
char v14; // cl
__int64 v15; // rcx
char result; // al
char v17; // al
char v18; // al
char v19; // al
char v20; // al
char v21; // al
int v22; // [rsp+0h] [rbp-10h]
__int16 v23; // [rsp+4h] [rbp-Ch]
int v24; // [rsp+8h] [rbp-8h]
__int16 v25; // [rsp+Ch] [rbp-4h]
v0 = 0LL;
while ( 1 )
{
v25 = 0;
v24 = 0;
v1 = (unsigned __int8)map[5 * v0]; // map二维数组中,每行不能有两个数相同
if ( *((_BYTE *)&v24 + v1) )
break;
*((_BYTE *)&v24 + v1) = 1;
v2 = (unsigned __int8)map[5 * v0 + 1];
if ( *((_BYTE *)&v24 + v2) )
break;
*((_BYTE *)&v24 + v2) = 1;
v3 = (unsigned __int8)map[5 * v0 + 2];
if ( *((_BYTE *)&v24 + v3) )
break;
*((_BYTE *)&v24 + v3) = 1;
v4 = (unsigned __int8)map[5 * v0 + 3];
if ( *((_BYTE *)&v24 + v4) )
break;
*((_BYTE *)&v24 + v4) = 1;
if ( *((_BYTE *)&v24 + (unsigned __int8)map[5 * v0 + 4]) )
break;
if ( ++v0 >= 5 )
{
v5 = 0LL;
while ( 1 )
{
v23 = 0;
v22 = 0;
v6 = (unsigned __int8)map[v5]; // map二维数组中,每列不能有两个数相同
if ( *((_BYTE *)&v22 + v6) )
break;
*((_BYTE *)&v22 + v6) = 1;
v7 = (unsigned __int8)map[v5 + 5];
if ( *((_BYTE *)&v22 + v7) )
break;
*((_BYTE *)&v22 + v7) = 1;
v8 = (unsigned __int8)map[v5 + 10];
if ( *((_BYTE *)&v22 + v8) )
break;
*((_BYTE *)&v22 + v8) = 1;
v9 = (unsigned __int8)map[v5 + 15];
if ( *((_BYTE *)&v22 + v9) )
break;
*((_BYTE *)&v22 + v9) = 1;
if ( *((_BYTE *)&v22 + (unsigned __int8)map[v5 + 20]) )
break;
if ( ++v5 >= 5 )
{
v10 = 0LL;
while ( 1 )
{
v11 = row[4 * v10]; // 根据row数组,添加了一些约束条件
if ( v11 == 2 )
{
if ( (unsigned __int8)map[5 * v10] > (unsigned __int8)map[5 * v10 + 1] )
return 0;
}
else if ( v11 == 1 && (unsigned __int8)map[5 * v10] < (unsigned __int8)map[5 * v10 + 1] )
{
return 0;
}
v12 = row[4 * v10 + 1];
if ( v12 == 1 )
{
if ( (unsigned __int8)map[5 * v10 + 1] < (unsigned __int8)map[5 * v10 + 2] )
return 0;
}
else if ( v12 == 2 && (unsigned __int8)map[5 * v10 + 1] > (unsigned __int8)map[5 * v10 + 2] )
{
return 0;
}
v13 = row[4 * v10 + 2];
if ( v13 == 2 )
{
if ( (unsigned __int8)map[5 * v10 + 2] > (unsigned __int8)map[5 * v10 + 3] )
return 0;
}
else if ( v13 == 1 && (unsigned __int8)map[5 * v10 + 2] < (unsigned __int8)map[5 * v10 + 3] )
{
return 0;
}
v14 = row[4 * v10 + 3];
if ( v14 == 2 )
{
if ( (unsigned __int8)map[5 * v10 + 3] > (unsigned __int8)map[5 * v10 + 4] )
return 0;
}
else if ( v14 == 1 && 以上是关于ciscn2021 ctf线上赛baby.bc wp(#超详细,带逆向新手走过一个又一个小坑)的主要内容,如果未能解决你的问题,请参考以下文章