精选文章|RocketMQ源码分析
Posted 得物技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了精选文章|RocketMQ源码分析相关的知识,希望对你有一定的参考价值。
RocketMQ源码分析
概要
本文主要做了RocketMQ4.8版本的源码主流程分析。
一二三四五节介绍文件存储部分。
六七节介绍消息生产流程,包含client端和server端。
八节介绍消息消费流程。
九节介绍了传统的主从消息复制模式。
最后一节介绍了相对较新的基于raft的dleger模式消息处理流程。
一.存储设计
RocketMQ主要的存储文件包括Comitlog文件、ConsumeQueue文件、IndexFile文件。
RocketMQ将所有主题的消息存储在同一个文件中。但由于消息中间件一般是基于主题进行订阅,这样做不方便按照消息主题检索消息。
为了方便消息消费,RocketMQ引入了ConsumeQueue消息队列文件,每个Topic包含多个ConsumeQueue,每一个ConsumeQueue有一个文件。该文件可以看成是Commitlog关于消息消费的“索引”。
此外还有IndexFile索引文件,主要就是为了加速消息的检索,根据消息的属性快速从Commitlog文件中检索消息。
CommitLog:消息存储文件,所有Topic的消息都存储在CommitLog文件中。
ConsumeQueue:消息消费队列,消息到达CommitLog文件后,将异步转发到ConsumeQueue,供消费者消费。
IndexFile:消息索引文件,主要存储消息Key与Offset(消息在CommitLog中的偏移)的对应关系。
二. 存储文件组织
RocketMQ通过使用内存映射文件来提高IO访问性能,无论是CommitLog、ConsumeQueue还是IndexFile,单个文件都被设计为固定长度,如果一个文件写满以后再创建一个新文件,文件名就是该文件第一条消息对应的全局物理偏移量。
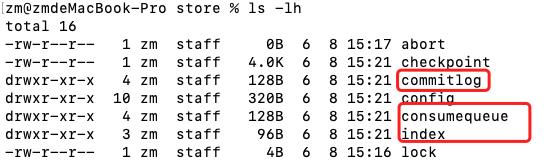
以下为commitlog实际文件截图:

存储目录
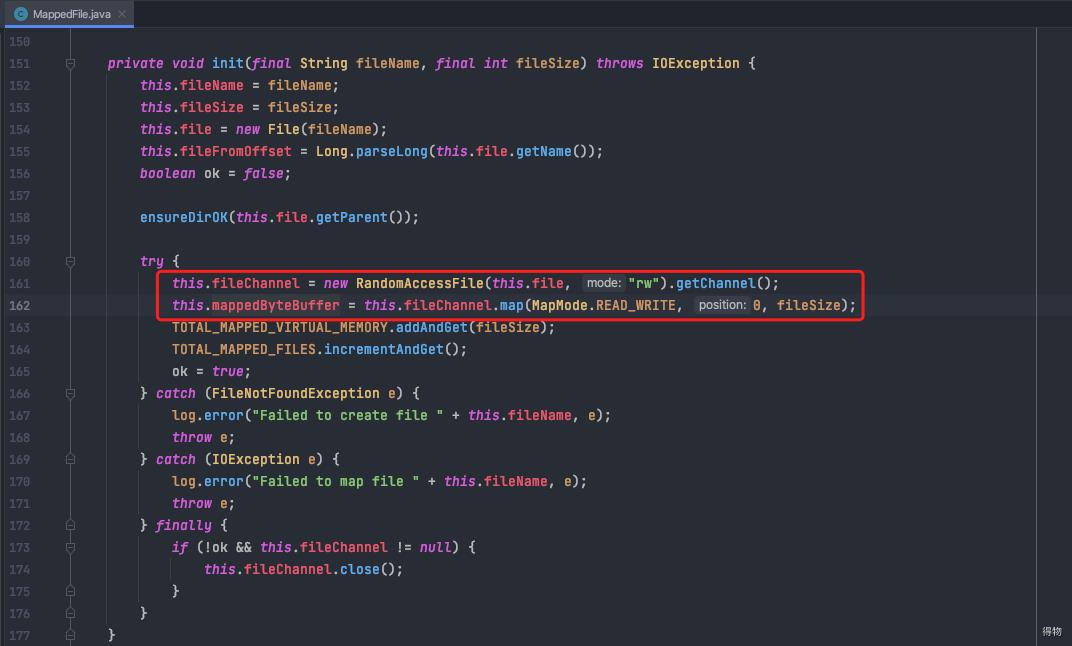
RocketMQ使用MappedFile、MappedFileQueue来封装存储文件。
MappedFile文件映射使用方式如下:
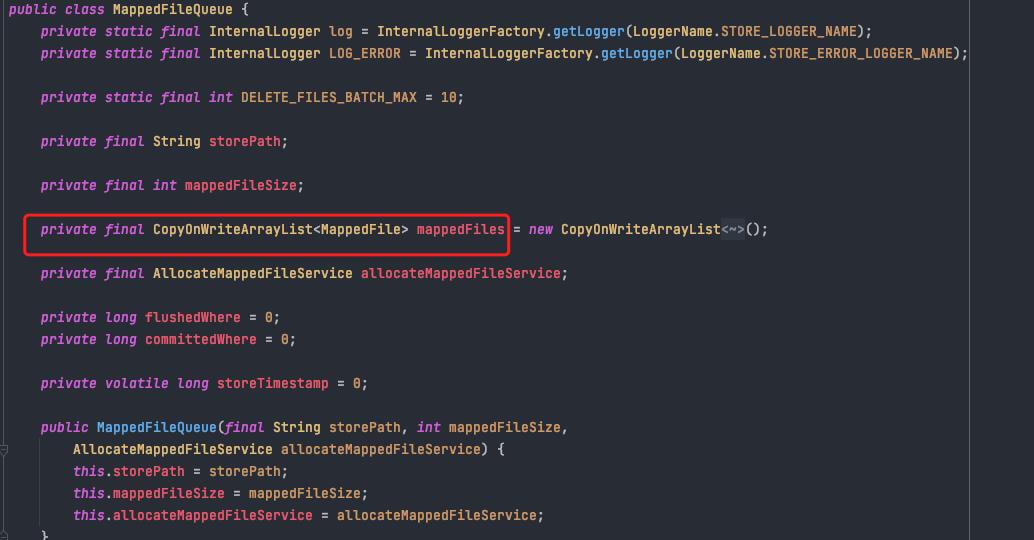
MappedFileQueue是MappedFile的管理容器,也是对存储目录的封装,例如CommitLog文件的存储路径${ROCKET_HOME}/store/commitlog/,该目录下会存在多个内存映射文件(MappedFile)。
逻辑关系

数据结构
三.存储文件格式
3.1 Commitlog文件格式

我们来看下按照这种格式来查找指定消息的逻辑。
根据offset查找消息。
根据offset定位到文件
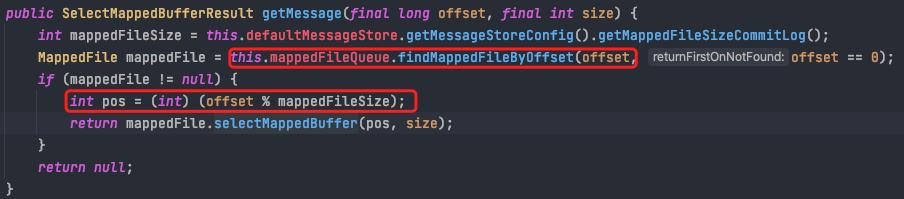
用offset与文件长度取余得到在文件内的偏移量,从该偏移量读取size长度的内容返回即可
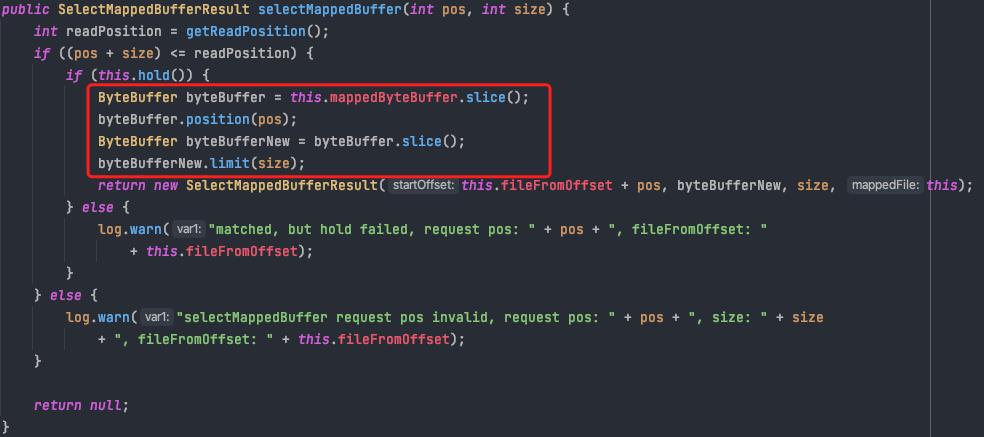
3.2 Consumequeue文件格式
为了加速ConsumeQueue消息条目的检索,每一个Consumequeue条目不会存储消息的全量信息,其存储格式如图:

ConsumeQueue即为Commitlog文件的索引文件,其构建机制是当消息存储到Commitlog文件后,由专门的线程转发消息,从而构建ConsumeQueue。
如下图,将consumeQueue想象成一个元素大小为20字节的大数组的话,startIndex就是这个数组的索引,而真正在文件中查找的时候则需要换算成文件内的字节偏移量(直接乘20)。
以下为根据消费者消费的逻辑偏移量查找consumeQueue条目的逻辑。
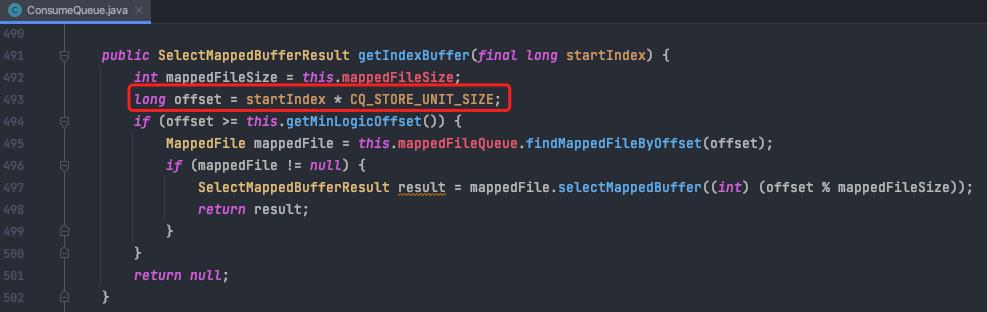
四.消费队列文件的实时更新
ConsumeQueue、IndexFile都是基于CommitLog文件构建的,当生产者提交的消息存储在Commitlog文件中时,ConsumeQueue文件需要及时更新,否则消息无法及时被消费。
RocketMQ通过开启一个线程ReputMessageServcie来实时读取CommitLog文件新增内容,使用reputFromOffset来标记已经追踪到的位置。
主要流程如下:
从当前记录已追踪到的位置reputFromOffset开始读取commitLog数据
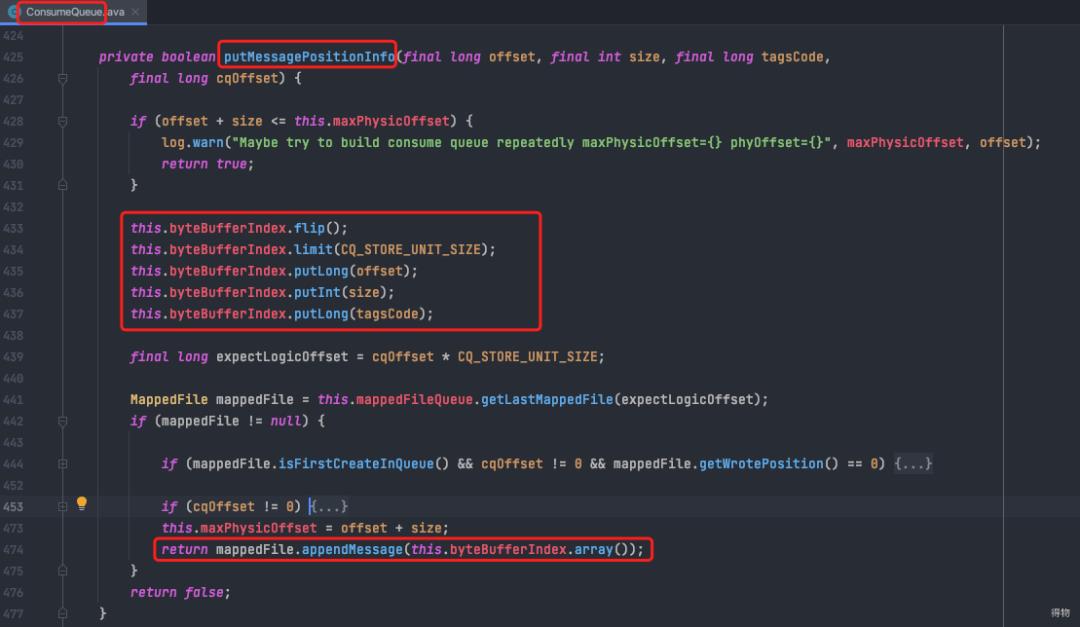
将读取到的buffer解析成携带关键信息的DispatchRequest(包含commitLogOffset,msgSize,tagsCode等consumeQueue的必要信息,以用来构建consumeQueue)
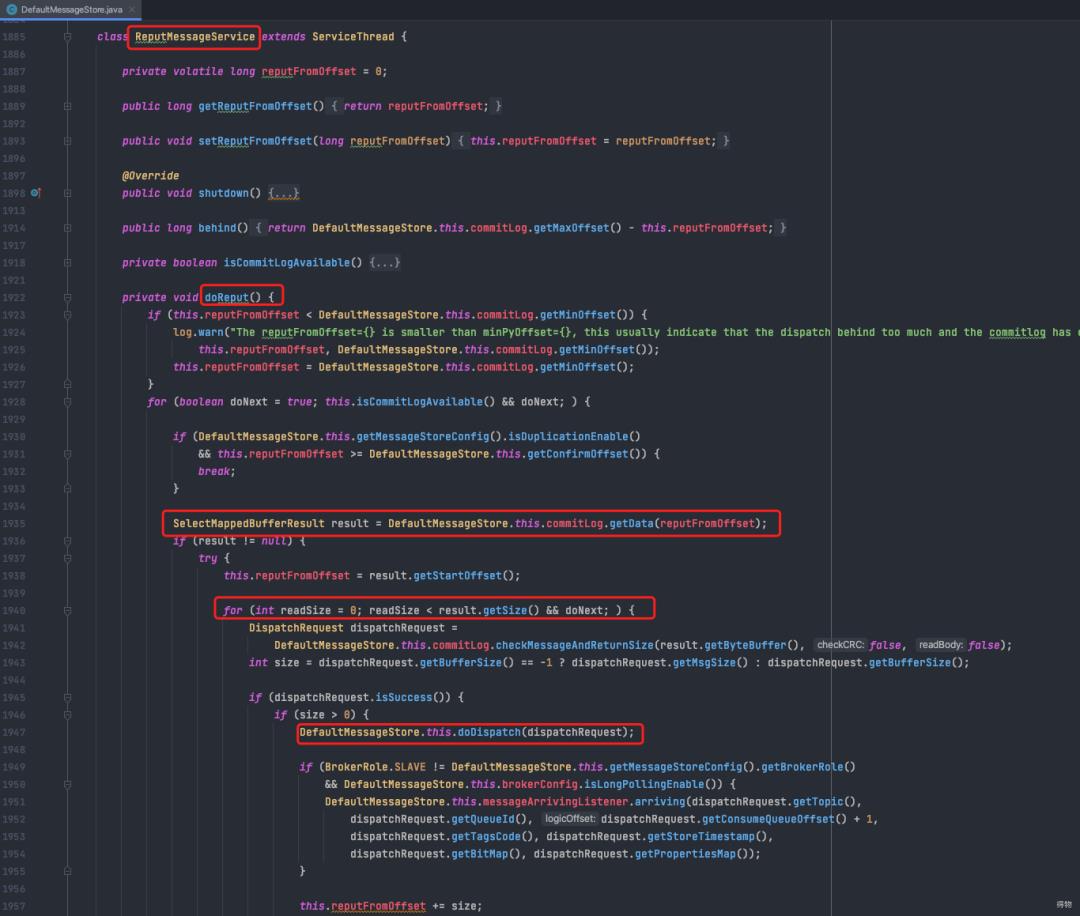
doDispatch方法最终会调用putMessagePositionInfo方法,将读取到的信息存入consumeQueue对应文件。
五.文件刷盘机制
RocketMQ的存储与读写基于内存映射机制(MappedByteBuffer),消息存储时首先将消息追加到内存,再根据配置的刷盘策略在一定时间进行刷写磁盘。
如果是同步刷盘,消息追加到内存后,将同步调用MappedByteBuffer的force()方法。
如果是异步刷盘,在消息追加到内存后立刻返回给发送端。
RocketMQ使用一个单独的线程按照某一个设定的频率执行刷盘。通过在broker配置文件中配置flushDiskType来设定刷盘方式,可选值为ASYNC_FLUSH(异步刷盘)、SYNC_FLUSH(同步刷盘),默认为异步刷盘。
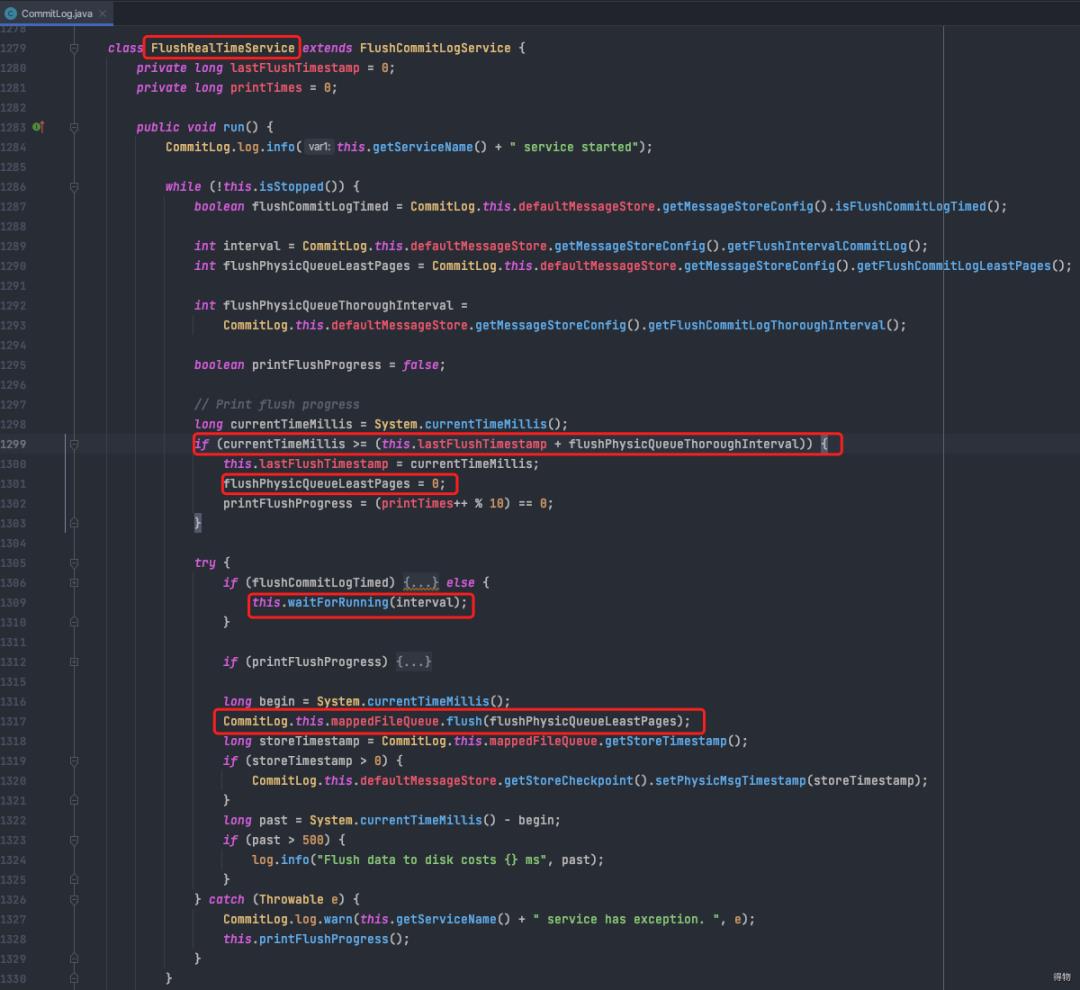
参数解析:
flushIntervalCommitLog:FlushRealTimeService线程任务运行间隔(默认500ms)。
flushPhysicQueueLeastPages:一次刷写任务至少包含的页数,如果脏页数量不足,小于该参数配置的值,将忽略本次刷写任务,默认4页。
flushPhysicQueueThoroughInterval:两次真实刷写任务最大间隔,默认10s。
注:每间隔10S会把flushPhysicQueueLeastPages强制设置为0,意为强制刷盘,无论脏页数量是否达到。
5.1 异步刷盘主流程
单线程死循环,每间隔500ms调用一次flush方法。
flush方法的入参是一次刷写任务至少包含的页数, 如果脏页页数不足,则啥都不做。
flush方法最终会走到 mappedByteBuffer.force()方法。
注:force方法详解
1. jdk 源码中显示force方法最终会调用msync系统调用,并传入MS_SYNC标志位。
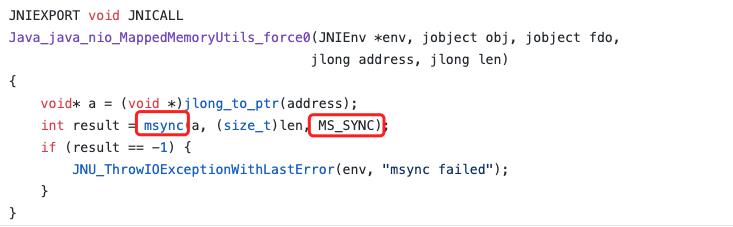
2. MS_SYNC标志位的含义为同步等待刷盘结果。

六.消息生产 client端流程
生产者消息发送流程主要的步骤:校验消息、查找路由、消息发送(包含异常处理机制)。
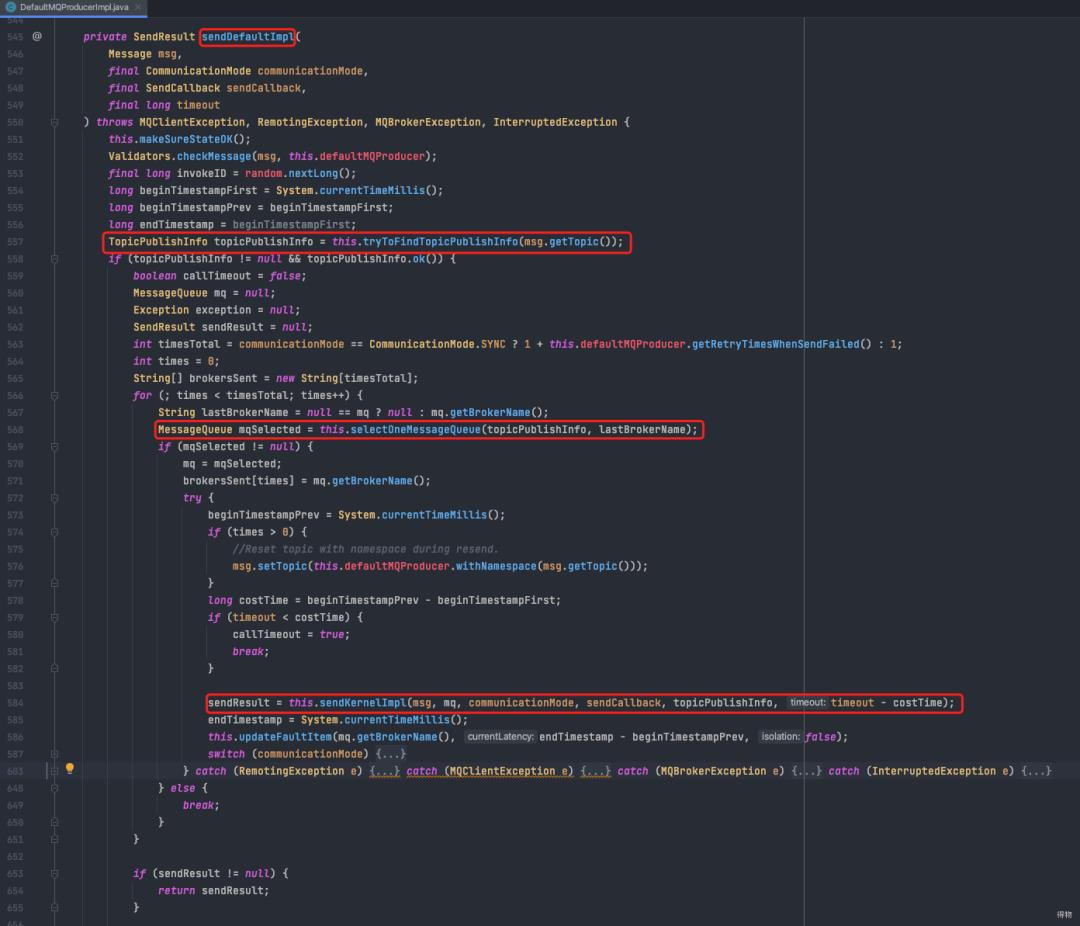
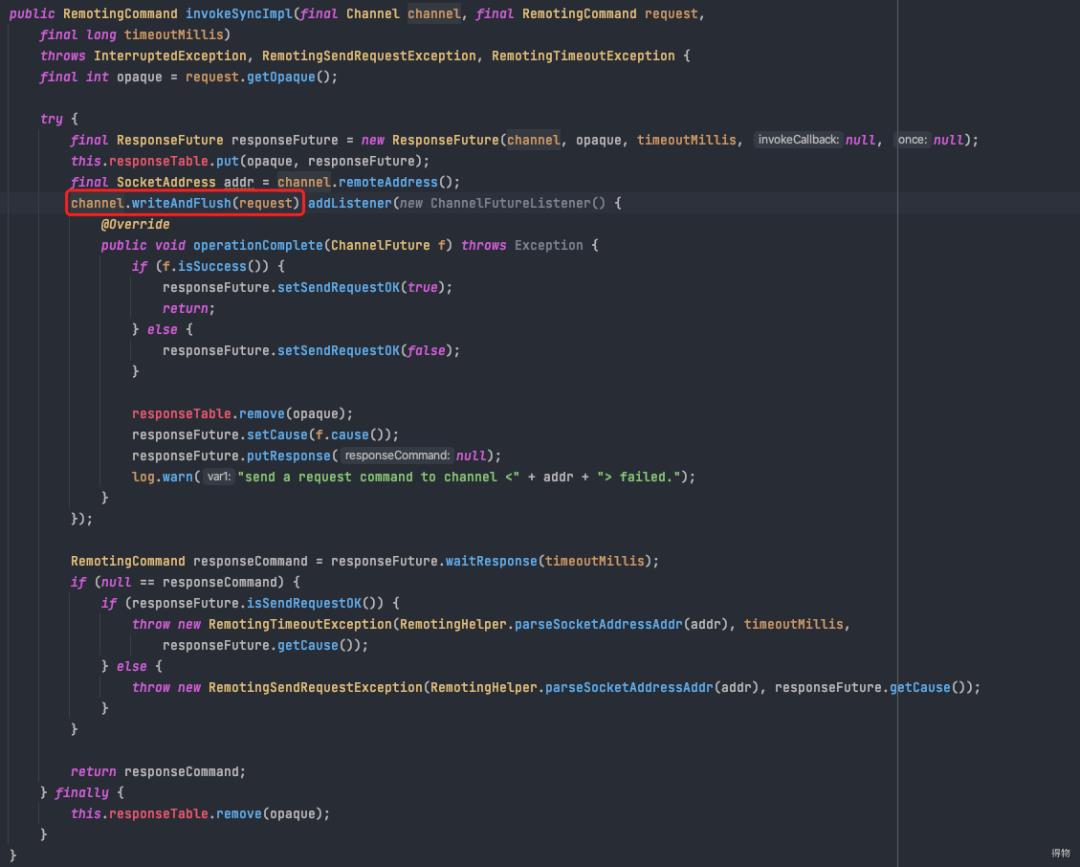
6.1 消息生产总流程
获取topic路由信息
根据策略选择一个messageQueue进行消息发送,默认使用轮询策略
调用sendKernelImpl方法发送消息,如果发送失败,默认最多重试三次
sendKernelImpl 会调用到mqClient,使用netty发送请求给mq broker
注:
1. 路由信息既指定topic共有多少队列,这些队列分布在哪些broker节点上,方便发送消息时选择具体的broker节点发送rpc请求。
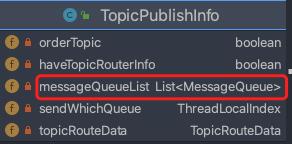
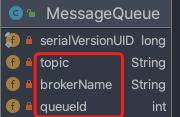
2. 路由信息数据结构如下:
6.2 消息发送路由选择详解
获取路由信息
如果本地缓存中包含指定topic的路由信息,则直接返回;
如本地map中不包含指定topic的路由信息,则发送rpc请求到nameserver获取。
消息队列选择
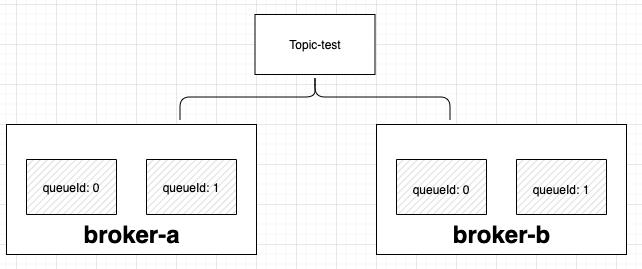
查询到的路由信息(队列分布信息)结构如下图。
选择策略默认使用轮询模式,依次来做消息发送的负载均衡。

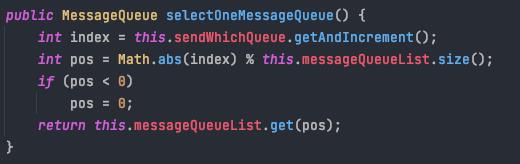
七.消息生产 broker端流程
消息存储代码入口:org.apache.rocketmq.store.DefaultMessageStore#asyncPutMessage。
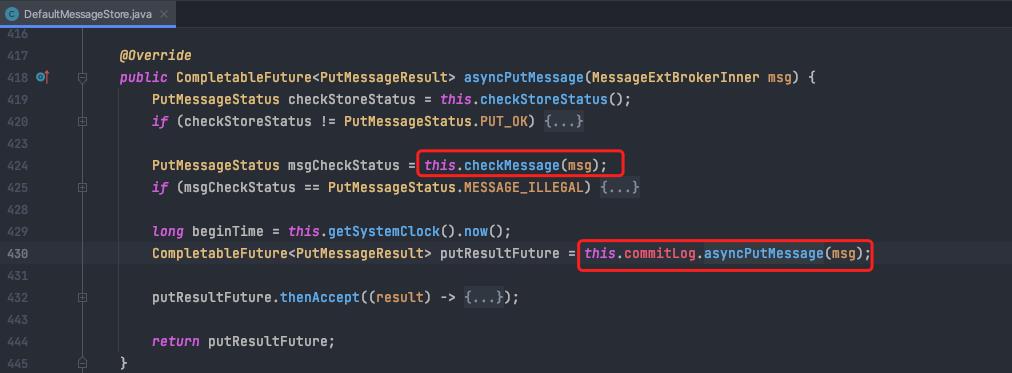
检查消息合法性
调用CommitLog类的putMessage方法
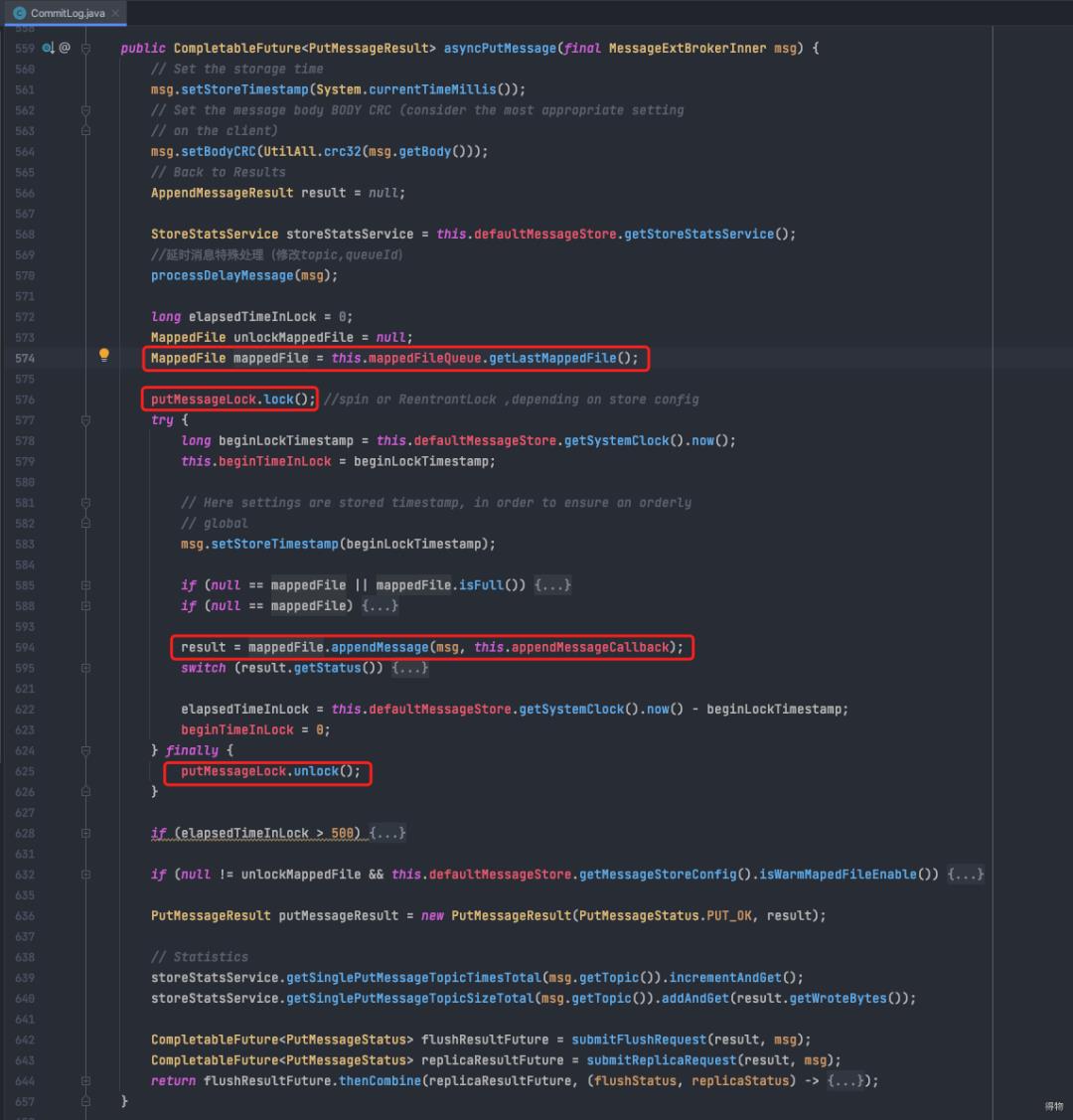
展开CommitLog类的putMessage
获取当前可以写入的Commitlog文件
put之前先上独占锁
调用MappedFile#appendMessage方法
finally块中解锁
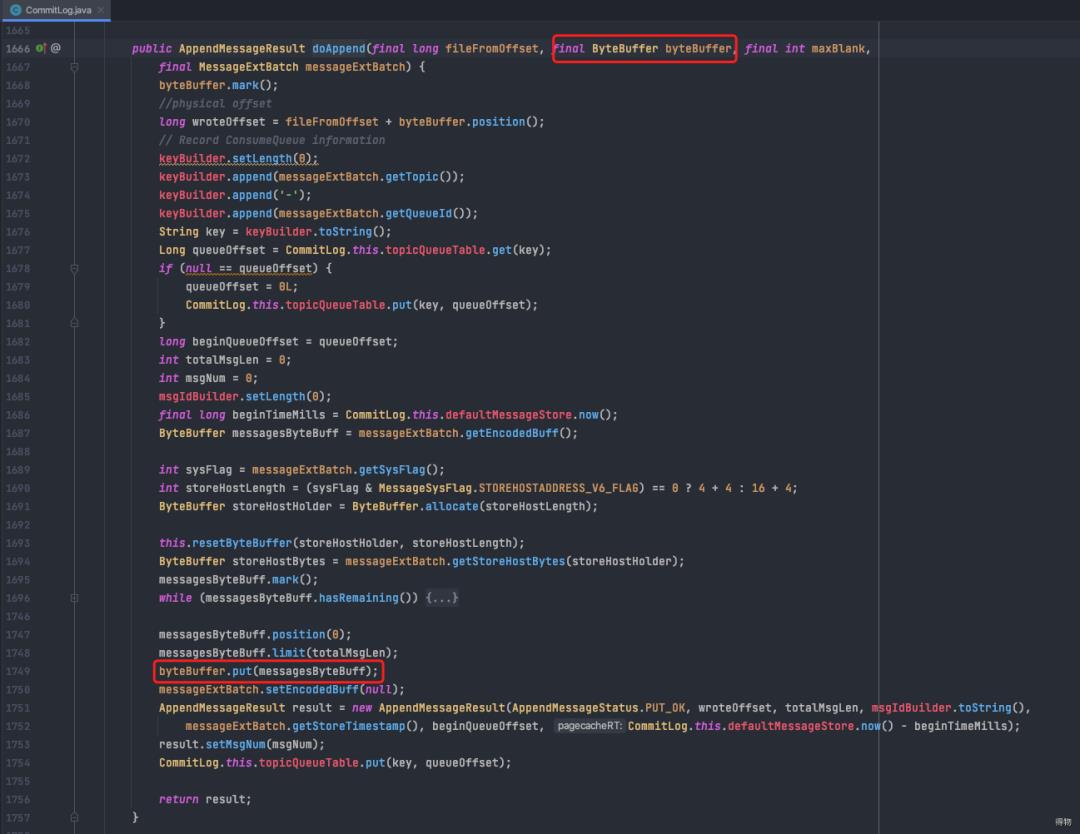
4. 展开MappedFile#appendMessage(核心就是调用MappedByteBuffer.put)
八.消费者消费
消息消费以组的模式开展,一个消费组内可以包含多个消费者,每一个消费组可订阅多个主题,消费组之间有集群模式与广播模式两种消费模式。
集群模式,Topic下的同一条消息只允许被其中一个消费者消费。
广播模式,Topic下的同一条消息将被集群内的所有消费者消费一次。
集群模式下,多个消费者如何对消息队列进行负载呢?消息队列负载机制遵循的原则:一个消息队列同一时间只允许被一个消费者消费,一个消费者可以消费多个消息队列。
8.1 客户端消息拉取
RocketMQ使用一个单独的线程PullMessageService来负责消息的拉取。
a.从pullRequestQueue中获取一个PullRequest(消息拉取任务),如果pullRequestQueue为空,则线程将阻塞,直到有拉取任务被放入。
b.调用pullMessage方法处理拿到的PullRequest进行消息拉取,PullRequest包含将要消费的messageQueue信息。
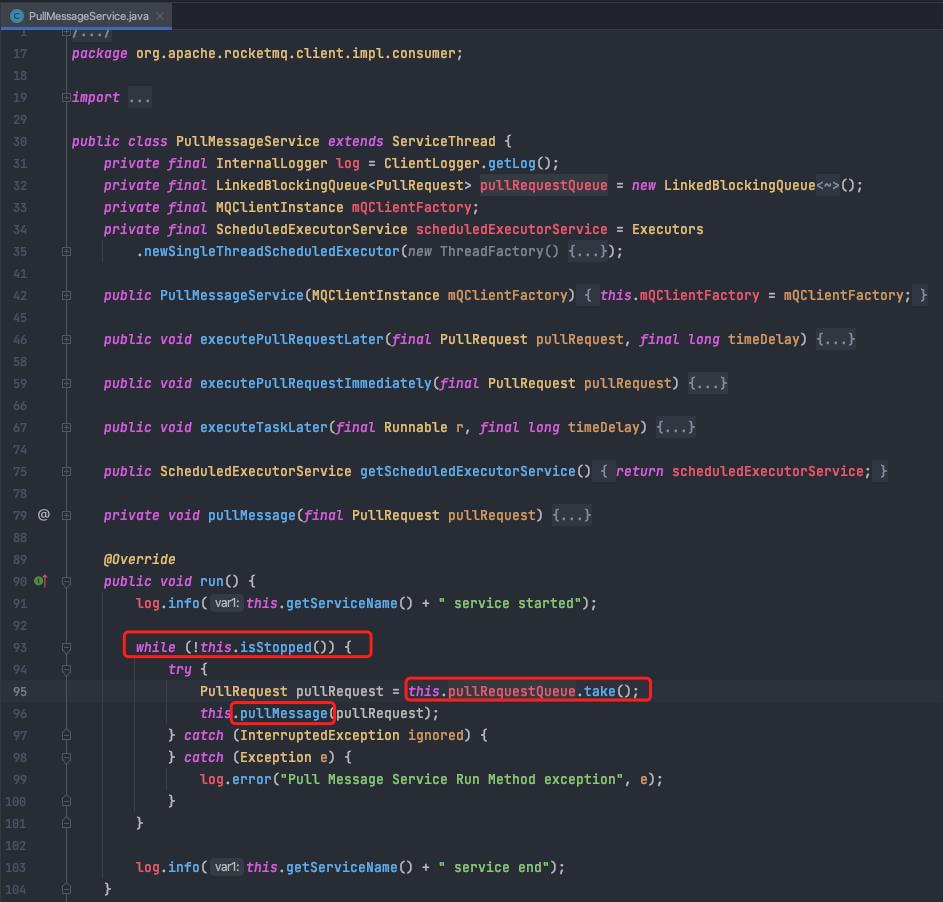
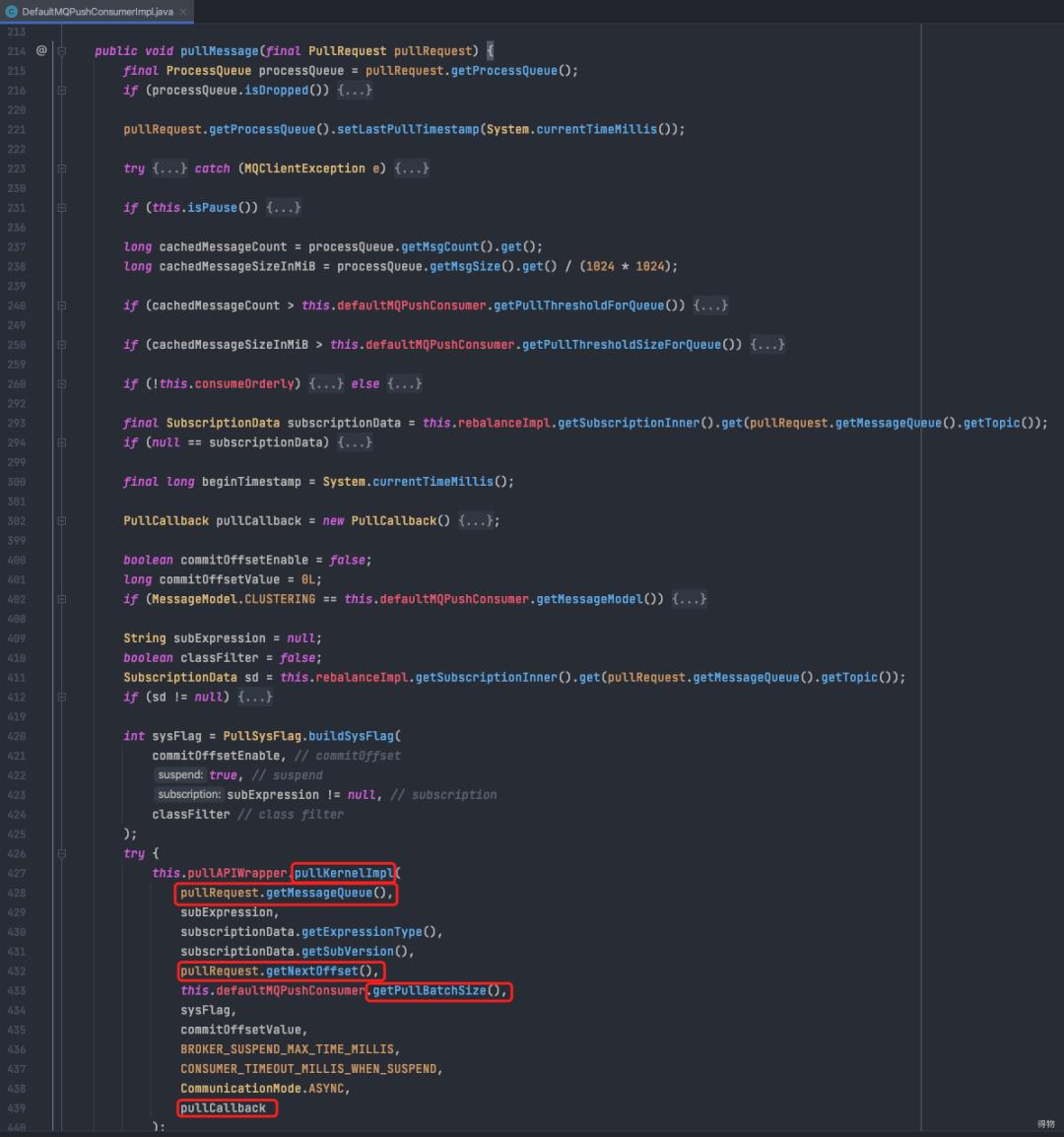
c. 调用pullKernelImpl,传入需要拉取的具体队列、offset、maxNums,拉取完成后需要执行的回调。
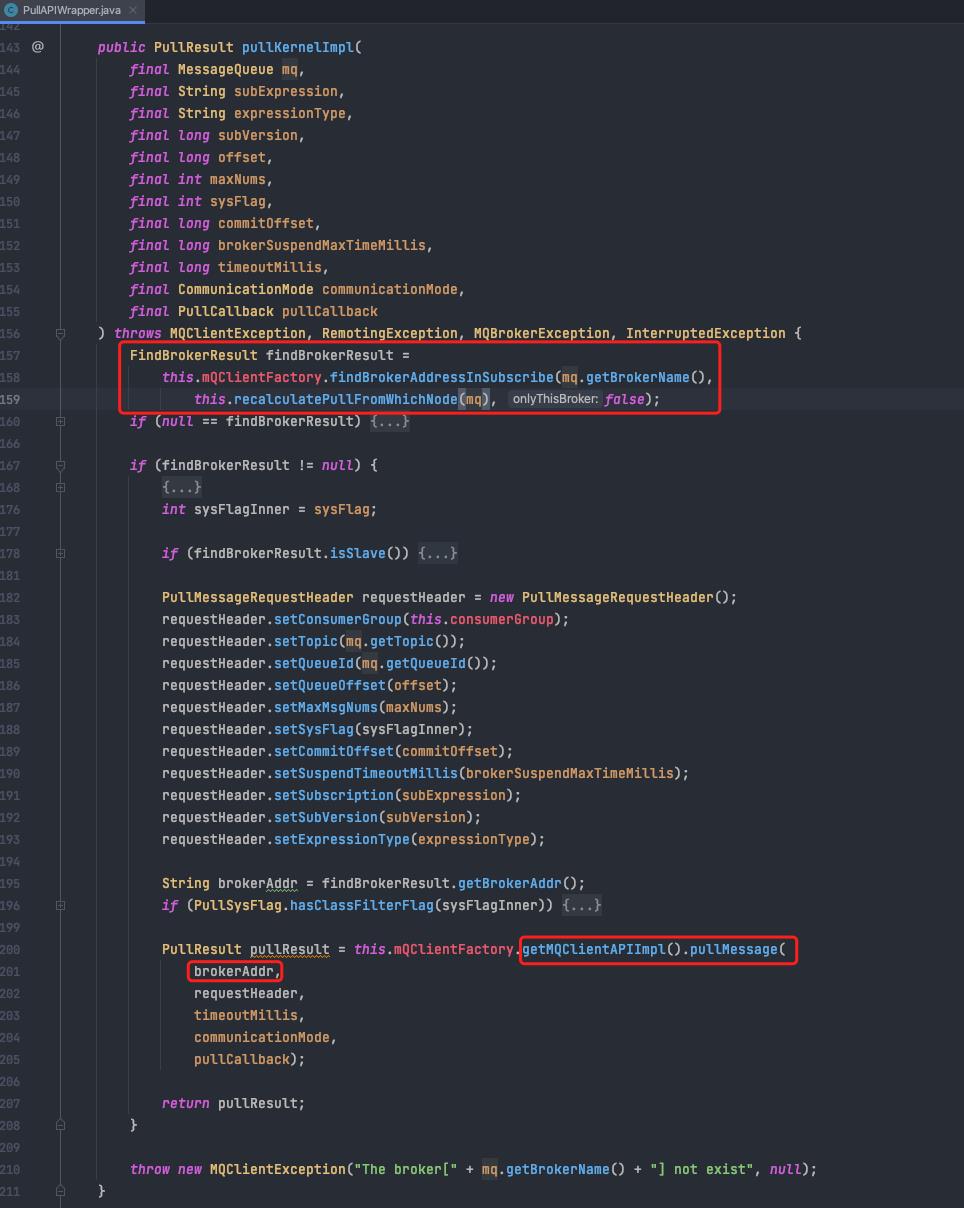
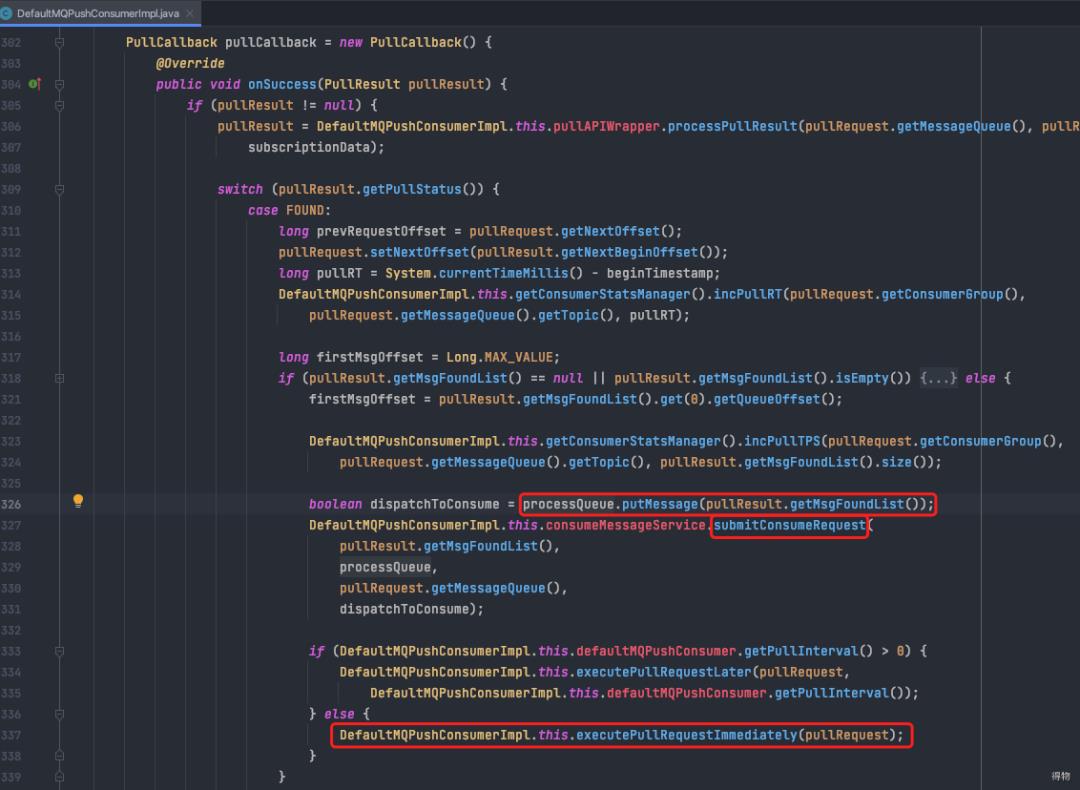
e. 收到响应,执行回调。
将foundList(收到的消息列表)放入processQueue。
调用submitConsumeRequest处理收到的消息体(实际上是将拉取到的消息丢入线程池,做异步化处理)。
将pullRequest重新放回pullRequestQueue,启动下一次pull流程。
注:下图312行,pullRequest的nextOffseet已更新,所以下次拉取的时候会从新的offset开始拉取。
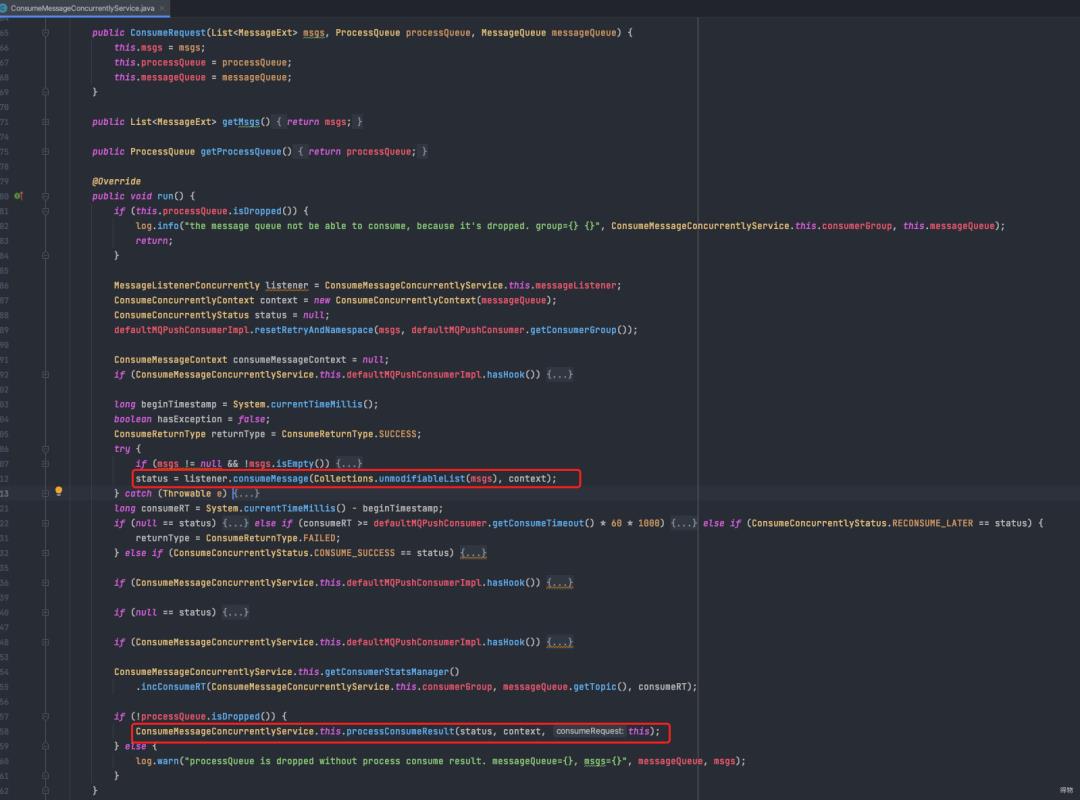
f. submitConsumeRequest处理流程最终会走到ConsumeRequest的run方法
调用业务方注册的listener
在processConsumeResult中处理消息消费Result、消费失败重试等逻辑
8.2 服务端处理消息拉取
入口在PullMessageProcessor#processRequest,该方法核心是DefaultMessageStore#getMessage。
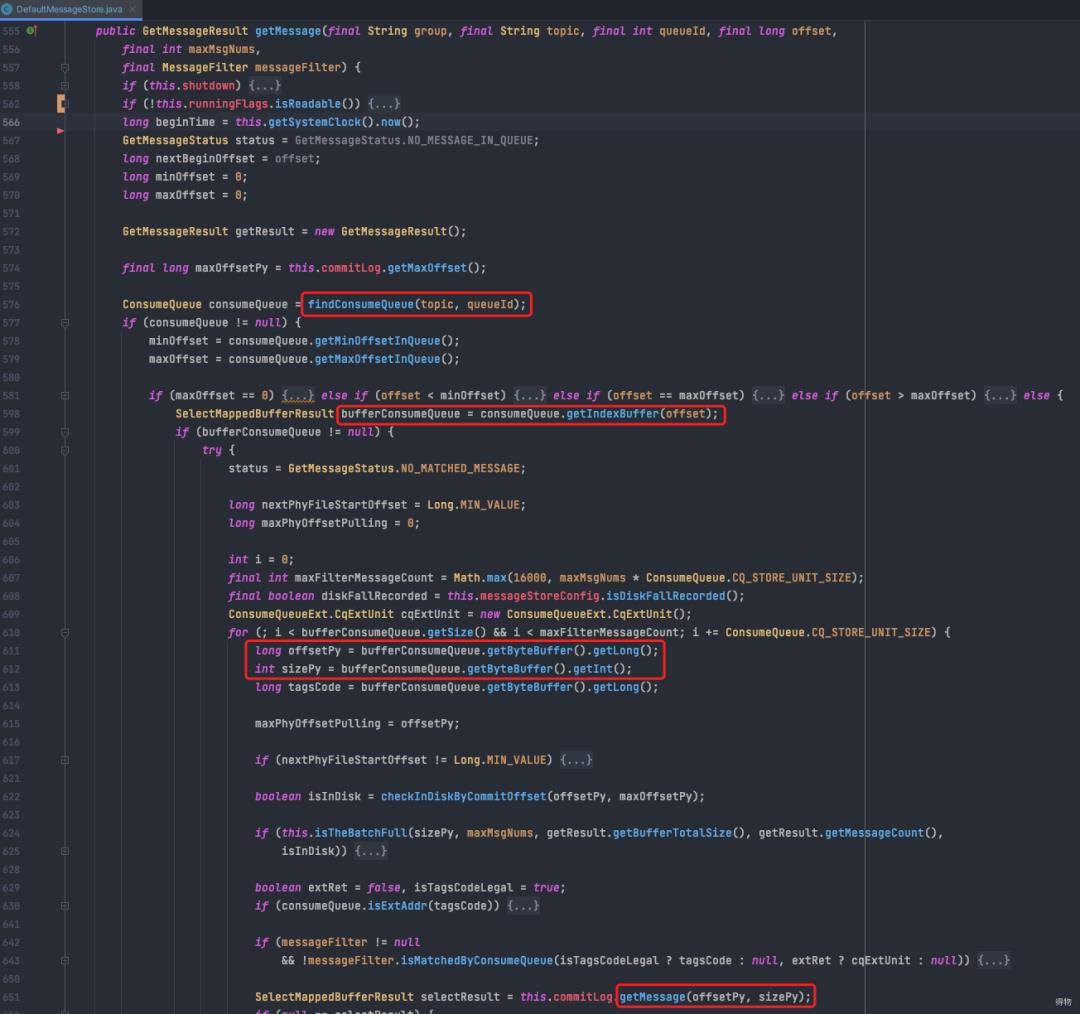
展开DefaultMessageStore#getMessage方法,传入topic、queueId、offset、maxMsgNum。
根据topic,queueId确定consumeQueue文件。
从找到的consumeQueue文件指定offset位置找到第一条‘索引’,读出对应在commitLog中的offset以及size。
用上述读取到的offset和size从commitLog中读到目标消息(此处有相对较多的随机读取)。
依次循环,直到消息数量达到maxMsgNum。
九. 主从同步(HA)机制
为了提高消息消费的高可用性,避免Broker发生单点故障引起存储在Broker上的消息无法及时消费甚至丢失,RocketMQ引入了Broker主备机制。
即消息消费到达主服务器后需要将消息同步到消息从服务器,如果主服务器Broker宕机后,消息消费者可以从从服务器拉取消息。
9.1 RocketMQ HA的实现原理
master启动,并在特定端口上监听slave的连接。
slave主动连接master,master接收客户端的连接,并建立相关TCP连接。
slave主动向master发送待拉取消息偏移量,master解析请求并返回消息给从服务器。
slave保存消息并继续发送新的消息同步请求。
具体实现(HAService)
master启动,并在特定端口上监听从服务器的连接。
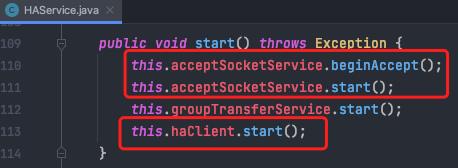
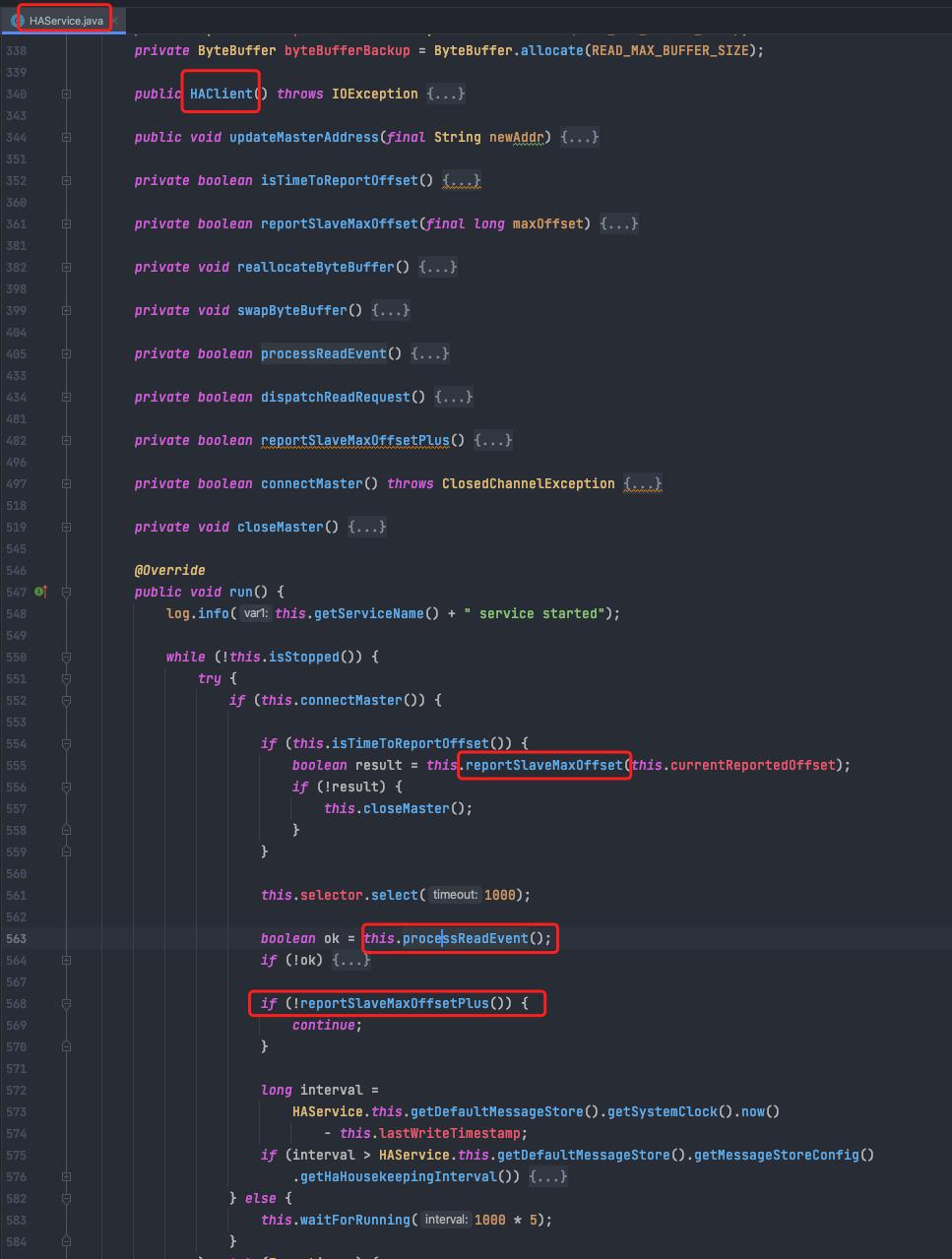
slave启动主动连接master(connectMaster)
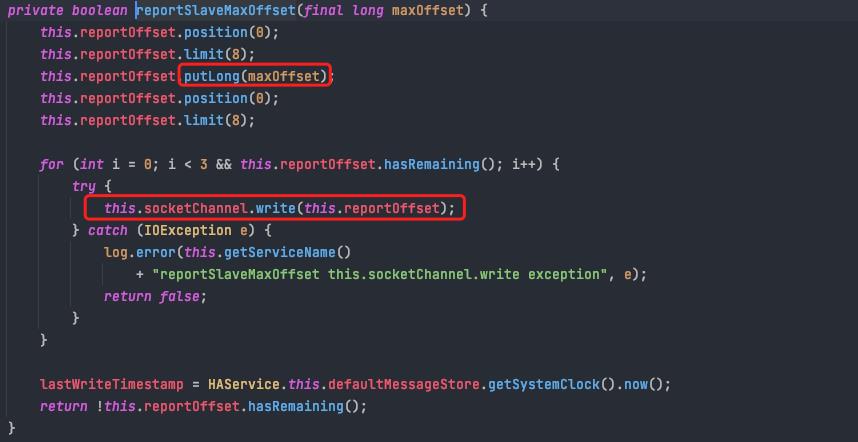
slave默认固定每隔5s向master会报当前拉取到的消息偏移量(reportSlaveMaxOffset)
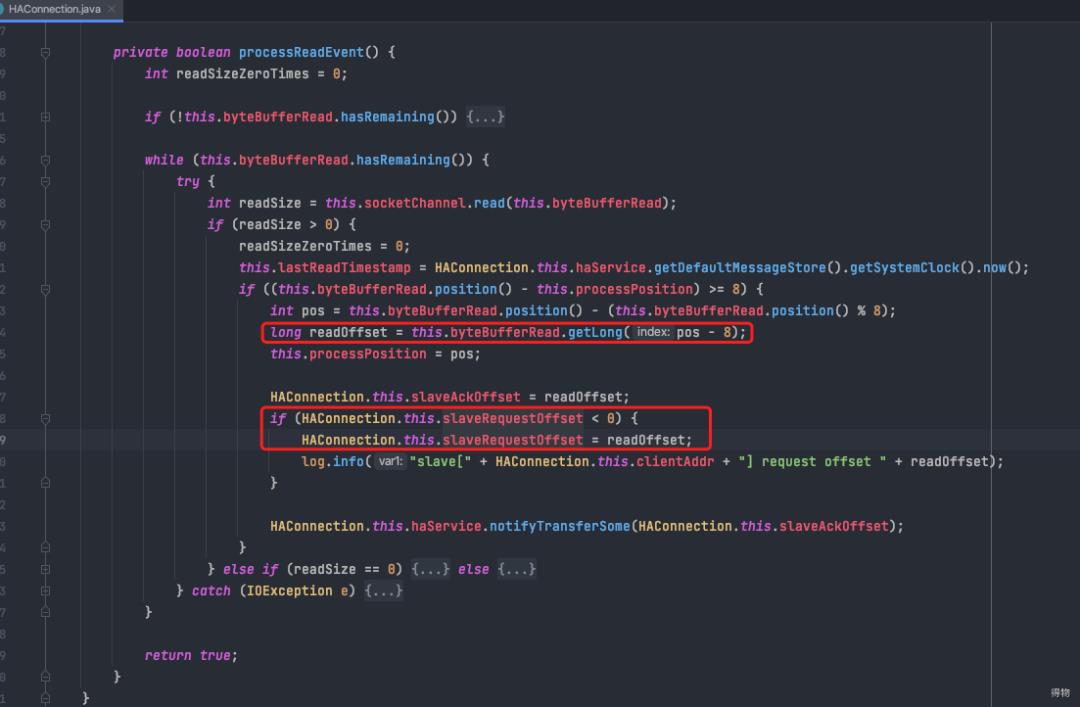
处理master发过来的消息副本(processReadEvent)
继续发送将要拉取的 消息偏移量,等到master响应(reportSlaveMaxOffsetPlus)
部分步骤详解
slave -> master请求详解
内容很简单,只有将要拉取的offset
master 处理 slave请求详解
读取要拉取的offset
更新slaveAckOffset,用于主从同步复制消息时及时响应给slave
如果是初次收到slave请求,更新slaveRequestOffset
master发送header给slave(调用transferData)(包含接下来将要发送的offset)
master从本地commitLog中查询指定offset处的消息,填充进入selectMappedBufferResult
master调用transferData写出刚才查到的mq消息给到slave节点
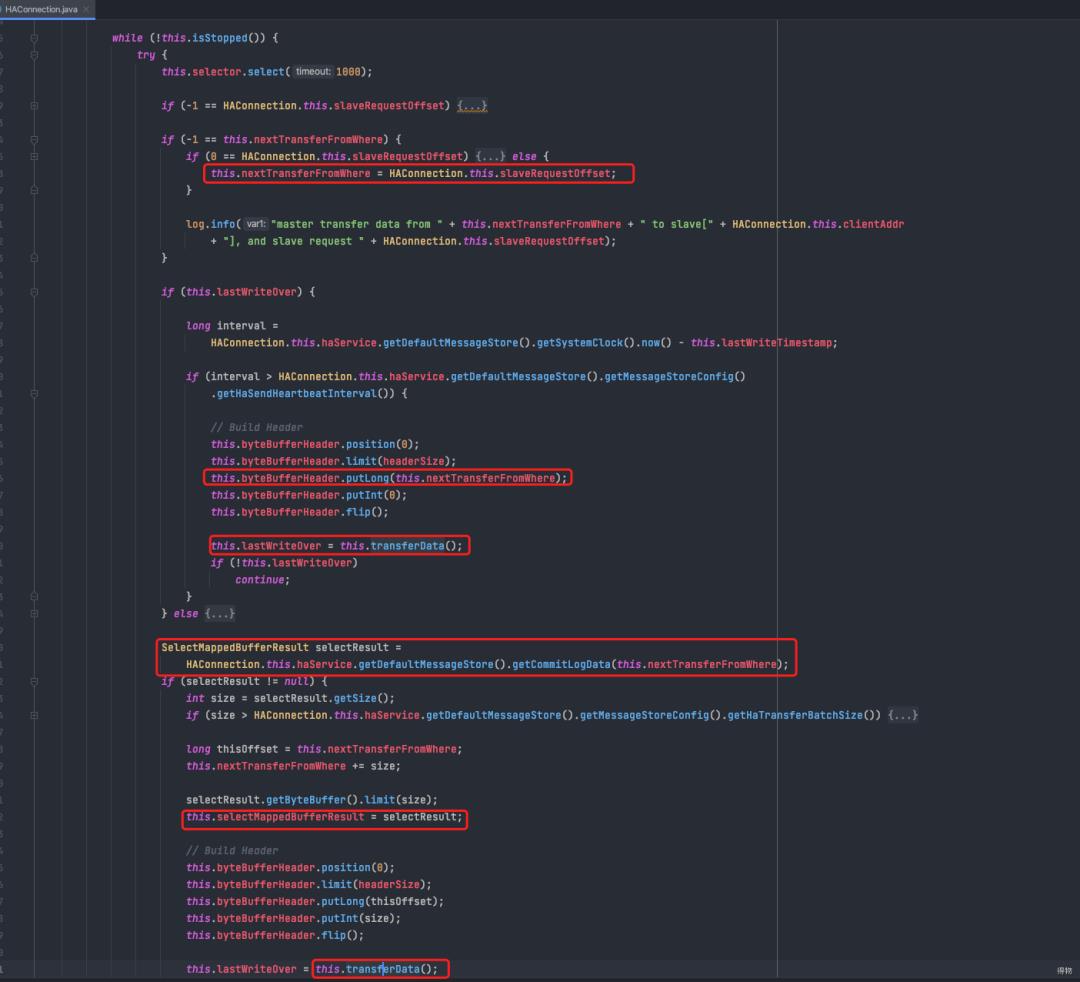
由于上述流程更新了nextTransferFromWhere,之后就可以不断循环,发送消息给到slave。
十.Dledger模式
从4.5版本开始,rocket引入了一种新的高可用机制,即rocketMq的Dleger模式。
Dleger模式遵从Raft协议http://thesecretlivesofdata.com/raft/
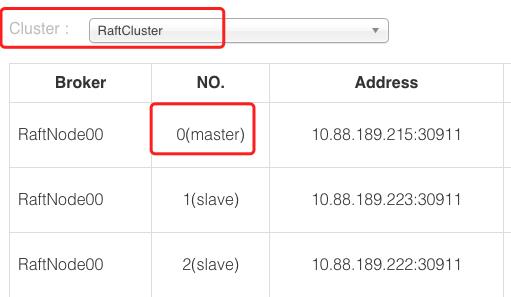
我们以一个集群三台机器为例(包含一主两从)。
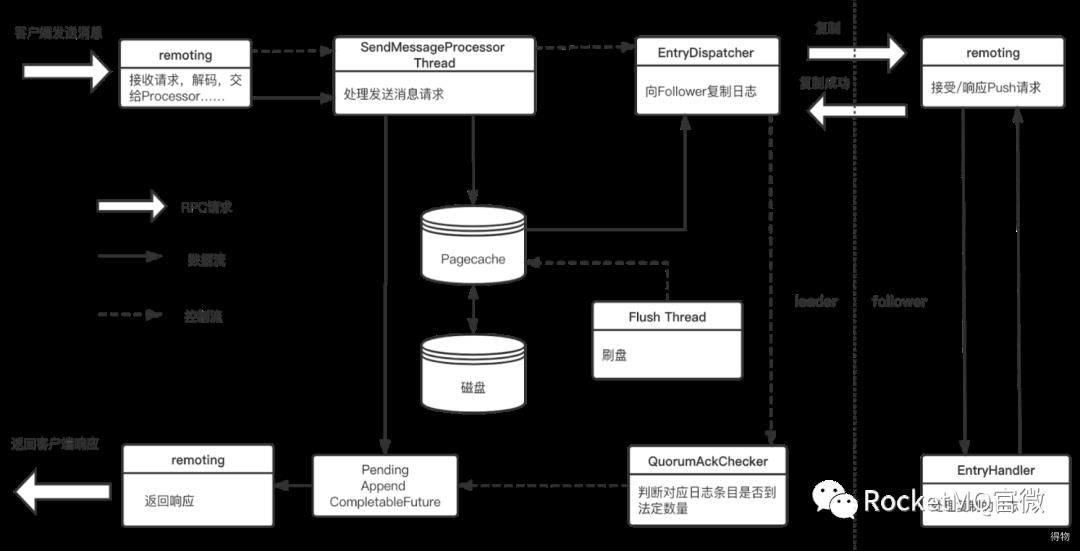
10.1 dleger的不同之处
引入dledger后,broker端处理消息发送的流程略有不同:
commitLog存储实现类换成了DledgerCommitLog,核心方法也从mappedFile.appendMessage换成了dLedgerServer.handleAppend,也就是说核心方法不再是把消息put进mappedByteBuffer就ok了。
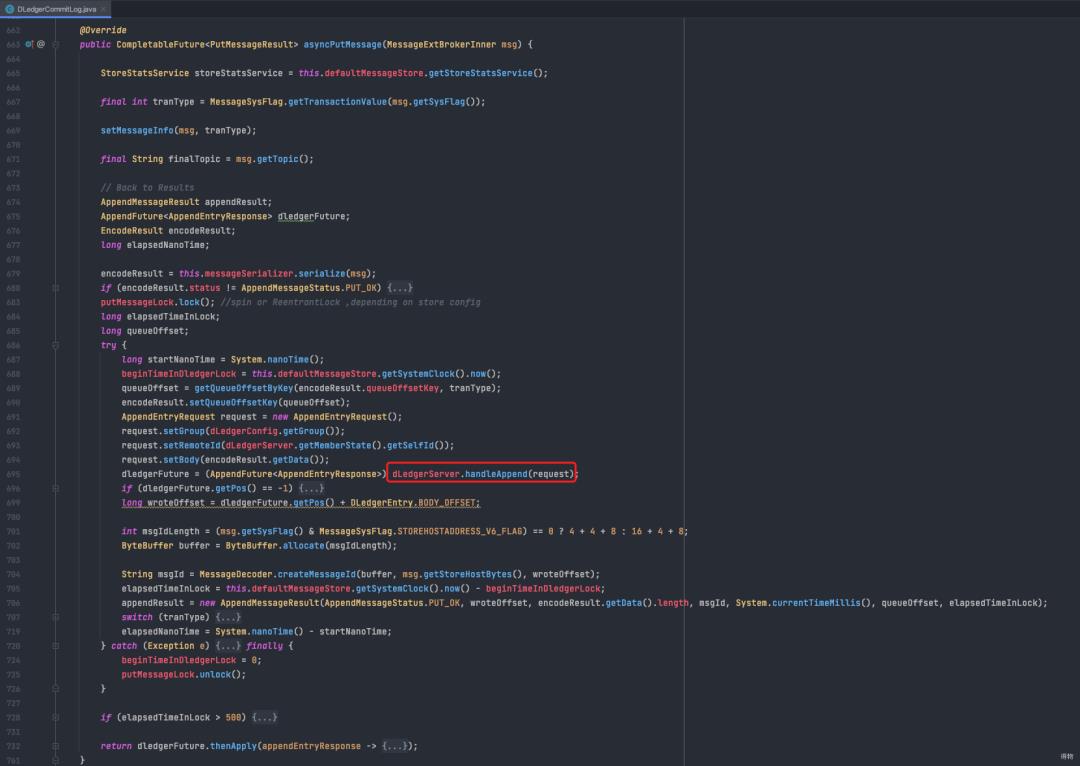
10.2 dLedger消息存储主流程
剖析下dLedgerServer.handleAppend:
判断从节点是不是压力太大响应太慢,如果是则直接拒绝producer发过来的请求
因为理论上三节点组成的cluster至少要有一个从节点响应成功消息才算正常落地。
如果两个从节点都响应慢,则master也无法接口请求,只能报错。
如果从节点正常,则存入master本地的mappedByteBuffer(dLedgerStore.appendAsLeader)。
将刚存入本地的消息 交给dLedgerEntryPusher来负责发送给slave,并等待从节点的响应(waitAck)。
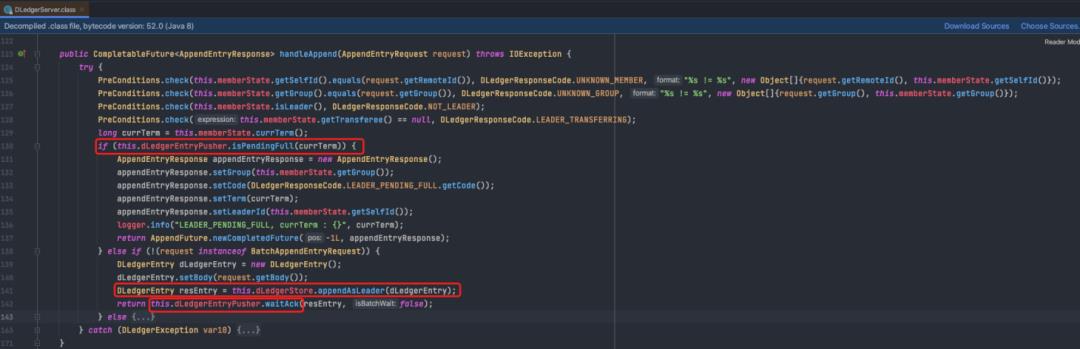
详解下waitAck:
核心就一条,把msg在commitLog中的索引以及对应的future放入一个map。
注:方便slave响应回来之后,根据响应的index,调用对应index的future,以发送响应给到producer,表示消息发送成功。
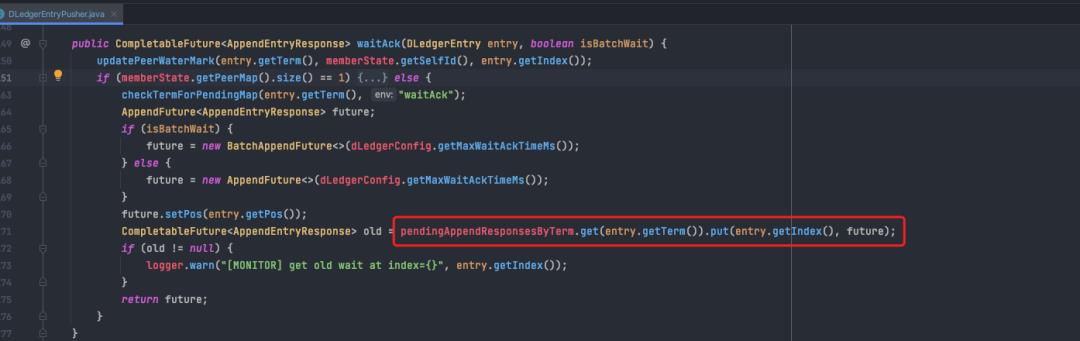
10.3 消息从master到 slave的复制流程
master启动时同时启动了2个dispatcher,各自对应一个slave节点。
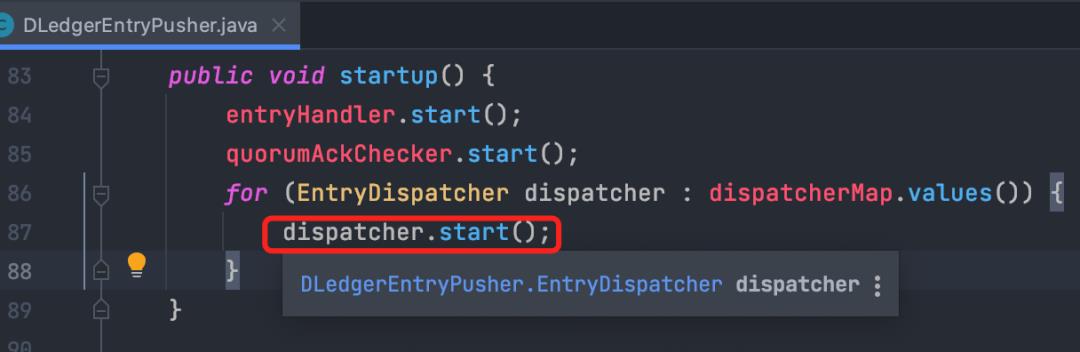
在dispatcher的主方法中,循环调用doAppend方法,不断复制消息发送到slave。
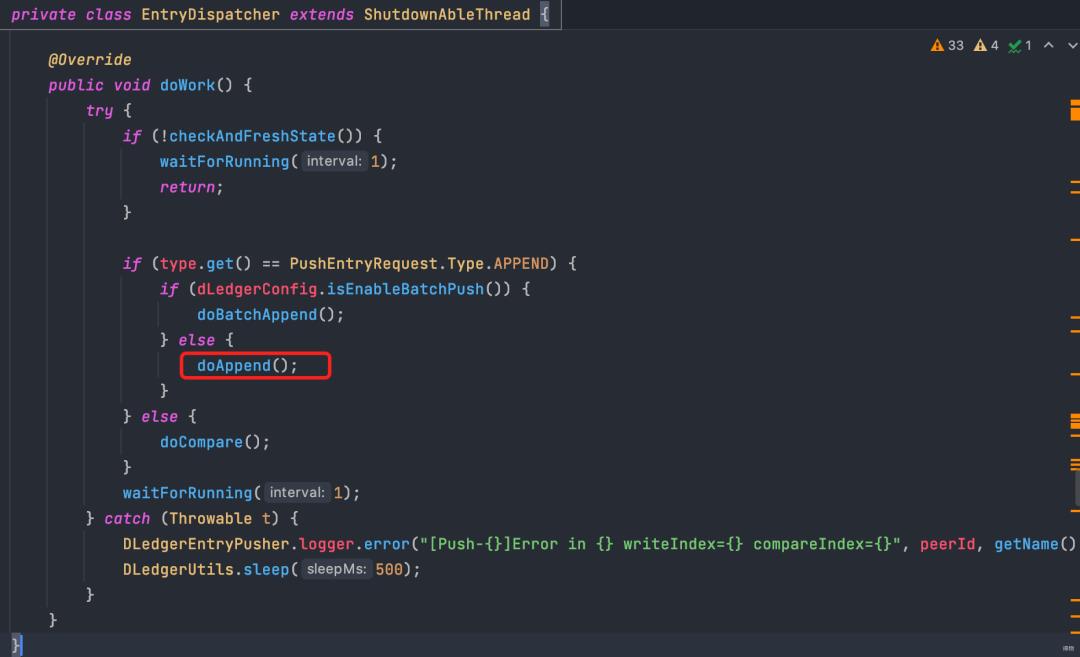
doAppend负责根据当前已经到达的位置writeIndex,查询并发送消息到从节点(doAppendInner),并更新writeIndex,循环往复。
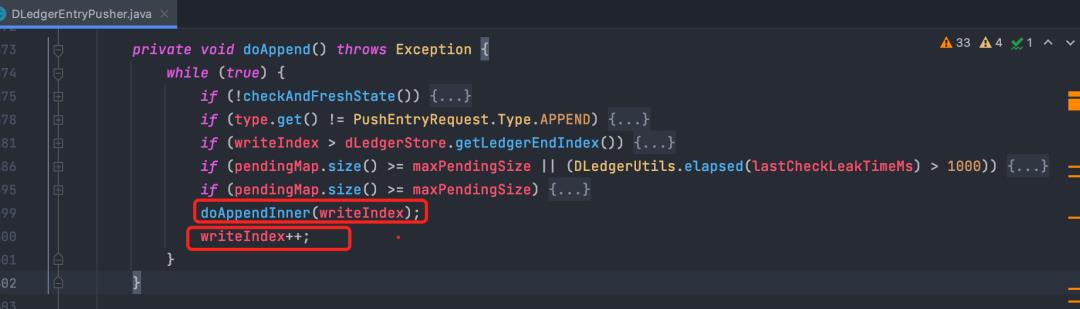
doAppendInner 先查询index位置的消息,再rpc push消息到从节点。
在从节点ack回调中,更新对应从节点所达到的水位(updatePeerWaterMark)。
注:水位即对应从节点已经追加到的index位置。
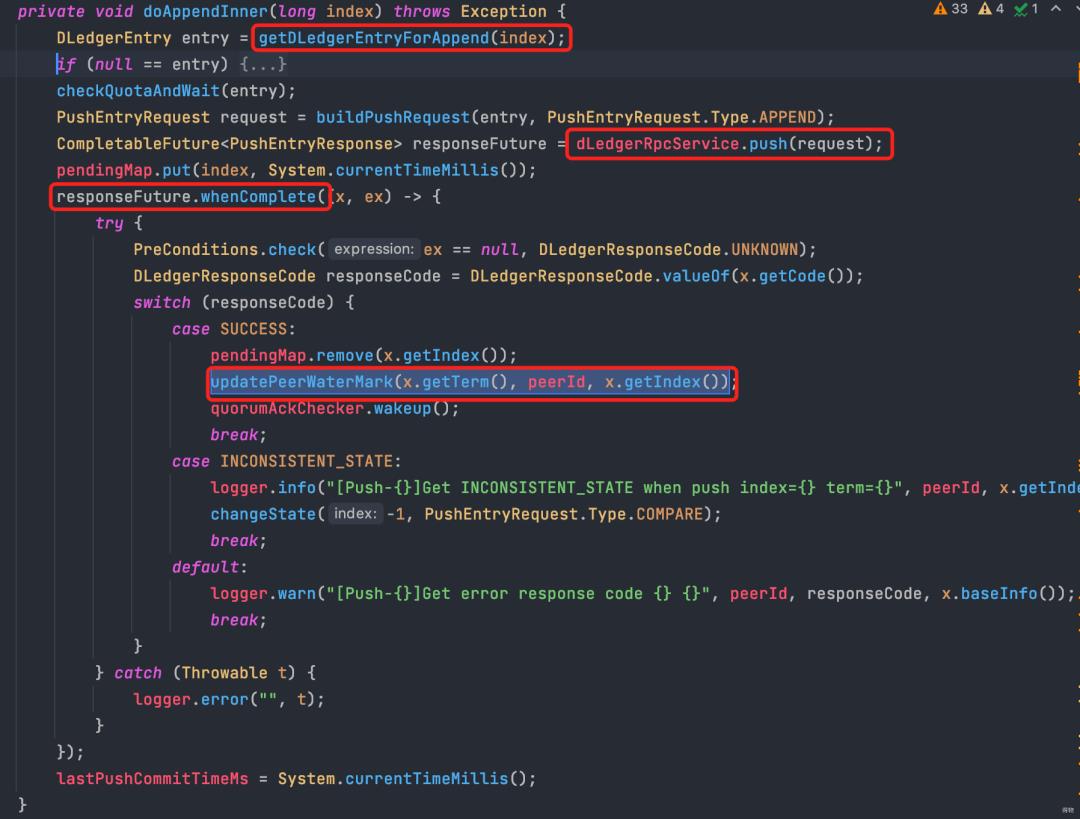
更新水位时,peerid为从节点的id,三个节点的水位信息统一放在peerWaterMarksByTerm。
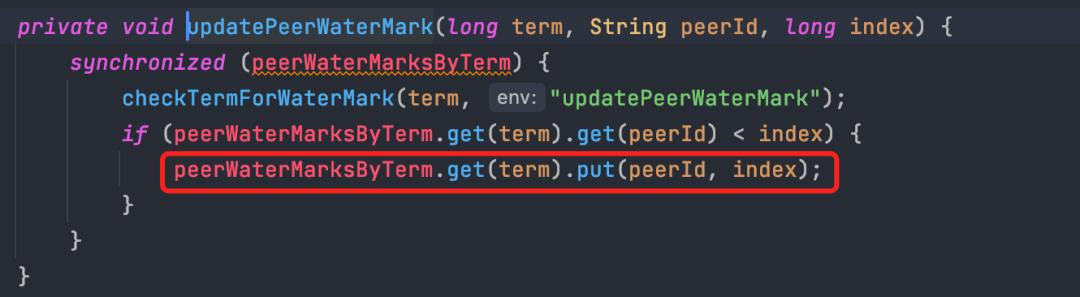
master-> slave push消息,收到响应后更新水位,就是这段的总结。
10.4 消息复制成功后及时响应producer
消息复制成功后及时响应producer,以表示消息发送成功。
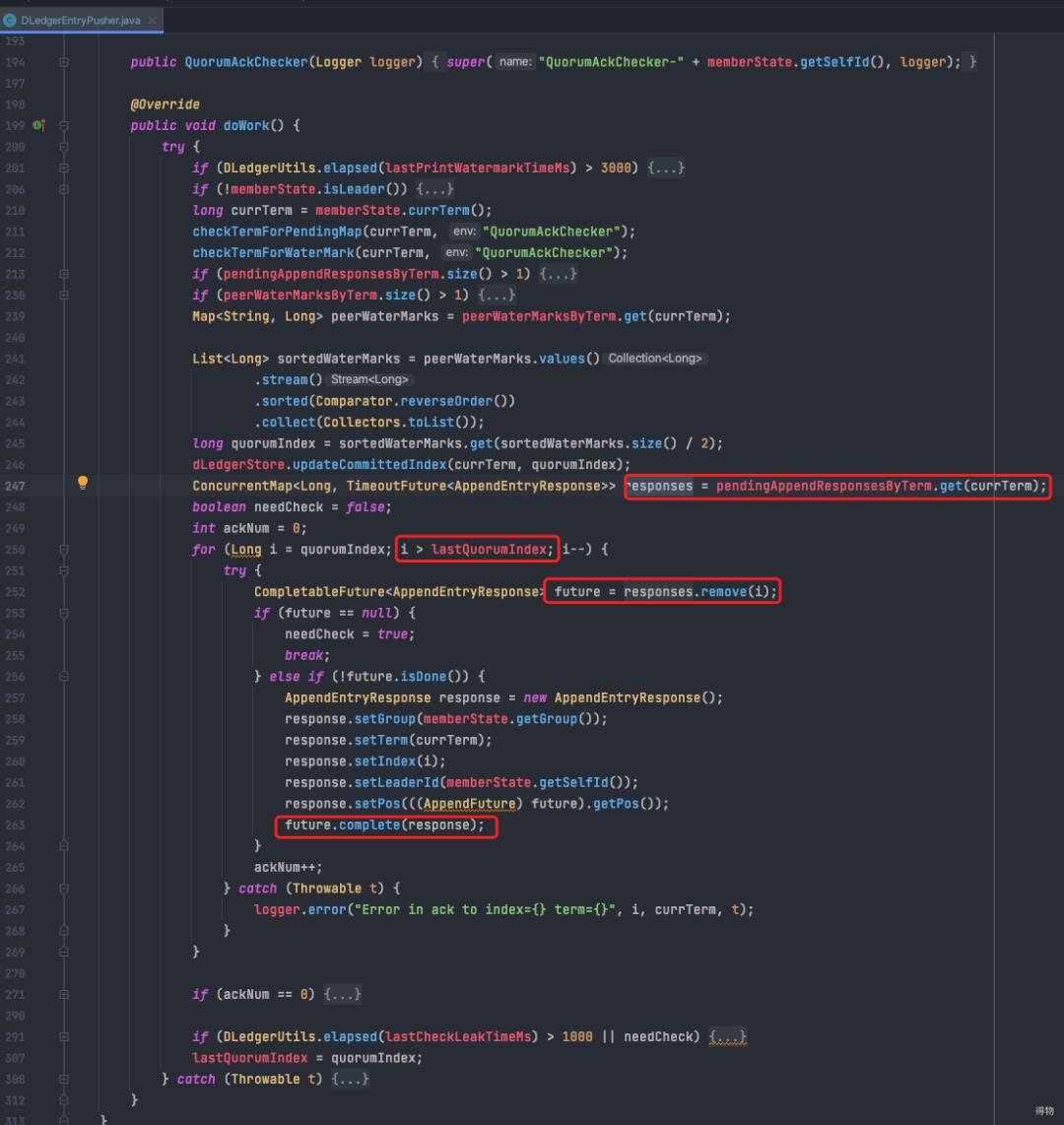
master启动时同样启动了一个QuorumAckChecker线程。
QuorumAckChecker主方法中进行水位(peerWaterMarksByTerm)的处理。
checker计算水位map中的数据,算出当前多数节点(两个节点就够了)已经达到的水位(quorumIndex),标志着这些消息已经收到slave的ack,低于这个水位的消息全部都可以给producer响应了。
注:举例子:
master append到了index 5,slave 1到了 4, slave 2 到了 3,则quorumIndex计算为4。
处理的内容很简单,从pendingResponse的map中找出低于共识水位(quorumIndex)的消息发送response给到producer(调用future.complete)。
这个future正是上边消息发送流程写完master本地后放入pendingResponse这个map的。
至此整个producer的请求,响应流程已经结束。

关注得物技术,携手走向技术的云端
文|zmm
以上是关于精选文章|RocketMQ源码分析的主要内容,如果未能解决你的问题,请参考以下文章
RocketMQ基础概念剖析,并分析一下Producer的底层源码