高性能缓存 Caffeine 原理及实战
Posted 架构师社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高性能缓存 Caffeine 原理及实战相关的知识,希望对你有一定的参考价值。
一、简介
Caffeine 是基于Java 8 开发的、提供了近乎最佳命中率的高性能本地缓存组件,Spring5 开始不再支持 Guava Cache,改为使用 Caffeine。
下面是 Caffeine 官方测试报告。

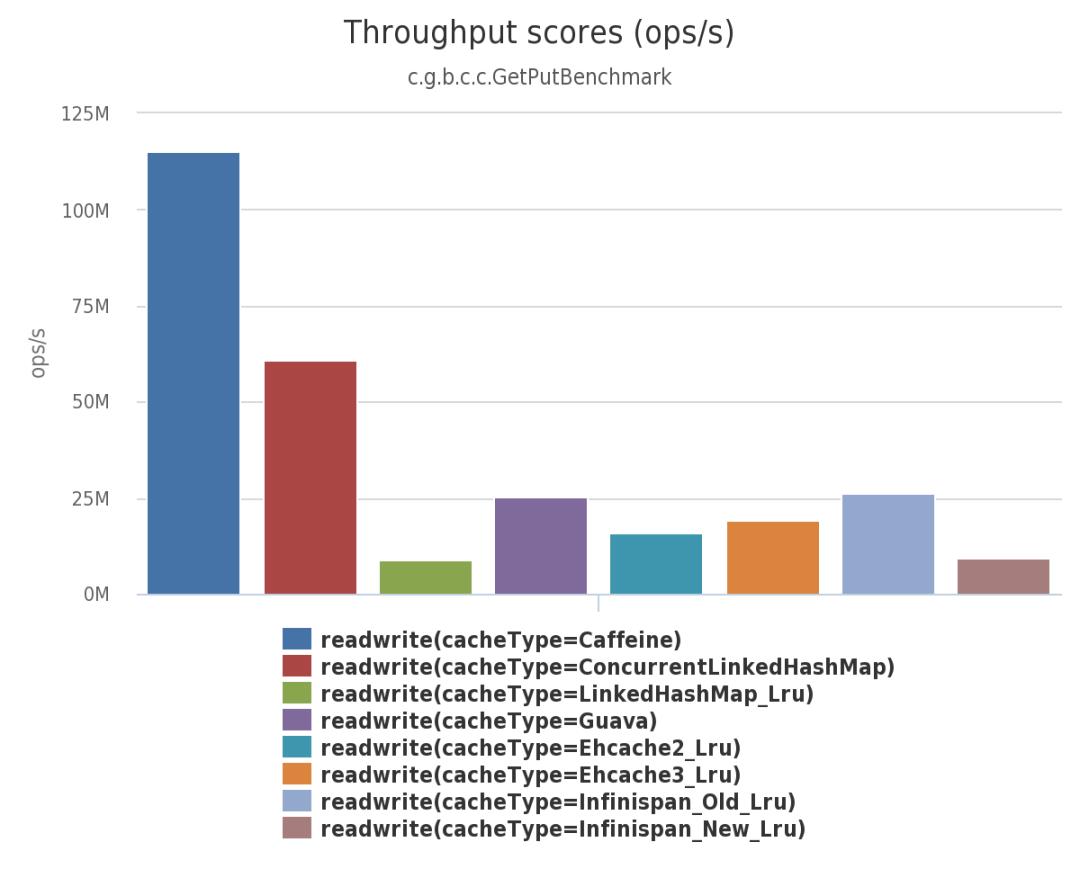
由上面三幅图可见:不管在并发读、并发写还是并发读写的场景下,Caffeine 的性能都大幅领先于其他本地开源缓存组件。
本文先介绍 Caffeine 实现原理,再讲解如何在项目中使用 Caffeine 。
二、Caffeine 原理
2.1 淘汰算法
2.1.1 常见算法
对于 Java 进程内缓存我们可以通过 HashMap 来实现。不过,Java 进程内存是有限的,不可能无限地往里面放缓存对象。这就需要有合适的算法辅助我们淘汰掉使用价值相对不高的对象,为新进的对象留有空间。常见的缓存淘汰算法有 FIFO、LRU、LFU。
FIFO(First In First Out):先进先出。它是优先淘汰掉最先缓存的数据、是最简单的淘汰算法。缺点是如果先缓存的数据使用频率比较高的话,那么该数据就不停地进进出出,因此它的缓存命中率比较低。
LRU(Least Recently Used):最近最久未使用。它是优先淘汰掉最久未访问到的数据。缺点是不能很好地应对偶然的突发流量。比如一个数据在一分钟内的前59秒访问很多次,而在最后1秒没有访问,但是有一批冷门数据在最后一秒进入缓存,那么热点数据就会被冲刷掉。
LFU(Least Frequently Used):最近最少频率使用。它是优先淘汰掉最不经常使用的数据,需要维护一个表示使用频率的字段。
主要有两个缺点:
一、如果访问频率比较高的话,频率字段会占据一定的空间;
二、无法合理更新新上的热点数据,比如某个歌手的老歌播放历史较多,新出的歌如果和老歌一起排序的话,就永无出头之日。
2.1.2 W-TinyLFU 算法
Caffeine 使用了 W-TinyLFU 算法,解决了 LRU 和LFU上述的缺点。W-TinyLFU 算法由论文《TinyLFU: A Highly Efficient Cache Admission Policy》提出。
它主要干了两件事:
一、采用 Count–Min Sketch 算法降低频率信息带来的内存消耗;
二、维护一个PK机制保障新上的热点数据能够缓存。
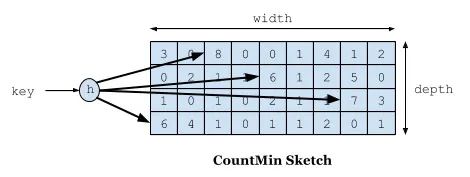
如下图所示,Count–Min Sketch 算法类似布隆过滤器 (Bloom filter)思想,对于频率统计我们其实不需要一个精确值。存储数据时,对key进行多次 hash 函数运算后,二维数组不同位置存储频率(Caffeine 实际实现的时候是用一维 long 型数组,每个 long 型数字切分成16份,每份4bit,默认15次为最高访问频率,每个key实际 hash 了四次,落在不同 long 型数字的16份中某个位置)。读取某个key的访问次数时,会比较所有位置上的频率值,取最小值返回。对于所有key的访问频率之和有个最大值,当达到最大值时,会进行reset即对各个缓存key的频率除以2。
如下图缓存访问频率存储主要分为两大部分,即 LRU 和 Segmented LRU 。新访问的数据会进入第一个 LRU,在 Caffeine 里叫 WindowDeque。当 WindowDeque 满时,会进入 Segmented LRU 中的 ProbationDeque,在后续被访问到时,它会被提升到 ProtectedDeque。当 ProtectedDeque 满时,会有数据降级到 ProbationDeque 。数据需要淘汰的时候,对 ProbationDeque 中的数据进行淘汰。具体淘汰机制:取ProbationDeque 中的队首和队尾进行 PK,队首数据是最先进入队列的,称为受害者,队尾的数据称为攻击者,比较两者 频率大小,大胜小汰。
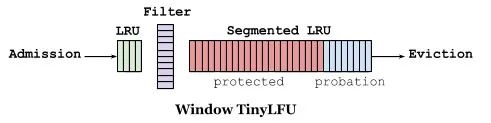
总的来说,通过 reset 衰减,避免历史热点数据由于频率值比较高一直淘汰不掉,并且通过对访问队列分成三段,这样避免了新加入的热点数据早早地被淘汰掉。
2.2 高性能读写
Caffeine 认为读操作是频繁的,写操作是偶尔的,读写都是异步线程更新频率信息。
2.2.1 读缓冲
传统的缓存实现将会为每个操作加锁,以便能够安全的对每个访问队列的元素进行排序。一种优化方案是将每个操作按序加入到缓冲区中进行批处理操作。读完把数据放到环形队列 RingBuffer 中,为了减少读并发,采用多个 RingBuffer,每个线程都有对应的 RingBuffer。环形队列是一个定长数组,提供高性能的能力并最大程度上减少了 GC所带来的性能开销。数据丢到队列之后就返回读取结果,类似于数据库的WAL机制,和ConcurrentHashMap 读取数据相比,仅仅多了把数据放到队列这一步。异步线程并发读取 RingBuffer 数组,更新访问信息,这边的线程池使用的是下文实战小节讲的 Caffeine 配置参数中的 executor。
2.2.2 写缓冲
与读缓冲类似,写缓冲是为了储存写事件。读缓冲中的事件主要是为了优化驱逐策略的命中率,因此读缓冲中的事件完整程度允许一定程度的有损。但是写缓冲并不允许数据的丢失,因此其必须实现为一个安全的队列。Caffeine 写是把数据放入MpscGrowableArrayQueue 阻塞队列中,它参考了JCTools里的MpscGrowableArrayQueue ,是针对 MPSC- 多生产者单消费者(Multi-Producer & Single-Consumer)场景的高性能实现。多个生产者同时并发地写入队列是线程安全的,但是同一时刻只允许一个消费者消费队列。
三、Caffeine 实战
3.1 配置参数
Caffeine 借鉴了Guava Cache 的设计思想,如果之前使用过 Guava Cache,那么Caffeine 很容易上手,只需要改变相应的类名就行。构造一个缓存 Cache 示例代码如下:
Cache cache = Caffeine.newBuilder().maximumSize(1000).expireAfterWrite(6, TimeUnit.MINUTES).softValues().build();Caffeine 类相当于建造者模式的 Builder 类,通过 Caffeine 类配置 Cache,配置一个Cache 有如下参数:
expireAfterWrite:写入间隔多久淘汰;
expireAfterAccess:最后访问后间隔多久淘汰;
refreshAfterWrite:写入后间隔多久刷新,该刷新是基于访问被动触发的,支持异步刷新和同步刷新,如果和 expireAfterWrite 组合使用,能够保证即使该缓存访问不到、也能在固定时间间隔后被淘汰,否则如果单独使用容易造成OOM;
expireAfter:自定义淘汰策略,该策略下 Caffeine 通过时间轮算法来实现不同key 的不同过期时间;
maximumSize:缓存 key 的最大个数;
weakKeys:key设置为弱引用,在 GC 时可以直接淘汰;
weakValues:value设置为弱引用,在 GC 时可以直接淘汰;
softValues:value设置为软引用,在内存溢出前可以直接淘汰;
executor:选择自定义的线程池,默认的线程池实现是 ForkJoinPool.commonPool();
maximumWeight:设置缓存最大权重;
weigher:设置具体key权重;
recordStats:缓存的统计数据,比如命中率等;
removalListener:缓存淘汰监听器;
writer:缓存写入、更新、淘汰的监听器。
3.2 项目实战
Caffeine 支持解析字符串参数,参照 Ehcache 的思想,可以把所有缓存项参数信息放入配置文件里面,比如有一个 caffeine.properties 配置文件,里面配置参数如下:
users=maximumSize=10000,expireAfterWrite=180s,softValuesgoods=maximumSize=10000,expireAfterWrite=180s,softValues
针对不同的缓存,解析配置文件,并加入 Cache 容器里面,代码如下:
public class CaffeineManager {private final ConcurrentMap<String, Cache> cacheMap = new ConcurrentHashMap<>(16);public void afterPropertiesSet() {String filePath = CaffeineManager.class.getClassLoader().getResource("").getPath() + File.separator + "config"+ File.separator + "caffeine.properties";Resource resource = new FileSystemResource(filePath);if (!resource.exists()) {return;}Properties props = new Properties();try (InputStream in = resource.getInputStream()) {props.load(in);Enumeration propNames = props.propertyNames();while (propNames.hasMoreElements()) {String caffeineKey = (String) propNames.nextElement();String caffeineSpec = props.getProperty(caffeineKey);CaffeineSpec spec = CaffeineSpec.parse(caffeineSpec);Caffeine caffeine = Caffeine.from(spec);Cache manualCache = caffeine.build();cacheMap.put(caffeineKey, manualCache);}}catch (IOException e) {log.error("Initialize Caffeine failed.", e);}}}
当然也可以把 caffeine.properties 里面的配置项放入配置中心,如果需要动态生效,可以通过如下方式:
//动态调整缓存容量cache.policy().eviction().ifPresent(eviction -> {eviction.setMaximum(2 * eviction.getMaximum());});//动态调整缓存有效时间cache.policy().expireAfterAccess().ifPresent(expiration -> ...);cache.policy().expireAfterWrite().ifPresent(expiration -> ...);cache.policy().expireVariably().ifPresent(expiration -> ...);cache.policy().refreshAfterWrite().ifPresent(expiration -> ...);
至于是否利用 Spring 的 EL 表达式通过注解的方式使用,仁者见仁智者见智,笔者主要考虑三点:
一、EL 表达式上手需要学习成本;
二、引入注解需要注意动态代理失效场景;
三、EL 表达式对于静态变量、静态类、静态方法支持不友好,需要写明类的全路径,不够简洁。
获取缓存时通过如下方式:
caffeineManager.getCache(cacheName).get(redisKey, value -> getTFromRedis(redisKey, targetClass, supplier));Caffeine 这种带有回源函数的 get 方法最终都是调用 ConcurrentHashMap 的 compute 方法,它能确保高并发场景下,如果对一个热点 key 进行回源时,单个进程内只有一个线程回源,其他都在阻塞。业务需要确保回源的方法耗时比较短,防止线程阻塞时间比较久,系统可用性下降。
笔者实际开发中用了 Caffeine 和 Redis 两级缓存。Caffeine 的 cache 缓存 key 和 Redis 里面一致,都是命名为 redisKey。targetClass 是返回对象类型,从 Redis 中获取字符串反序列化成实际对象时使用。supplier 是函数式接口,是缓存回源到数据库的业务逻辑。
getTFromRedis 方法实现如下:
private <T> T getTFromRedis(String redisKey, Class targetClass, Supplier supplier) {String data;T value;String redisValue = UUID.randomUUID().toString();if (tryGetDistributedLockWithRetry(redisKey + RedisKey.DISTRIBUTED_SUFFIX, redisValue, 30)) {try {data = getFromRedis(redisKey);if (StringUtils.isEmpty(data)) {value = (T) supplier.get();setToRedis(redisKey, JackSonParser.bean2Json(value));}else {value = json2Bean(targetClass, data);}}finally {releaseDistributedLock(redisKey + RedisKey.DISTRIBUTED_SUFFIX, redisValue);}}else {value = json2Bean(targetClass, getFromRedis(redisKey));}return value;}
由于回源都是从 mysql 查询,虽然 Caffeine 本身解决了进程内同一个 key 只有一个线程回源,需要注意多个业务节点的分布式情况下,如果 Redis 没有缓存值,并发回源时会穿透到 MySQL ,所以回源时加了分布式锁,保证只有一个节点回源。
注意一点:从本地缓存获取对象时,如果业务要对缓存对象做更新,需要深拷贝一份对象,不然并发场景下多个线程取值会相互影响。
笔者项目之前都是使用 Ehcache 作为本地缓存,切换成 Caffeine 后,涉及本地缓存的接口,同样 TPS 值时,CPU 使用率能降低 10% 左右,接口性能都有一定程度提升,最多的提升了 25%。上线后观察调用链,平均响应时间降低24%左右。
四、总结
Caffeine 是目前比较优秀的本地缓存解决方案,通过使用 W-TinyLFU 算法,实现了缓存高命中率、内存低消耗。如果之前使用过 Guava Cache,看下接口名基本就能上手。如果之前使用的是 Ehcache,笔者分享的使用方式可以作为参考。
五、参考文献
TinyLFU: A Highly Efficient Cache Admission Policy
Design Of A Modern Cache
Caffeine Github
以上是关于高性能缓存 Caffeine 原理及实战的主要内容,如果未能解决你的问题,请参考以下文章