架构面试:RPC原理的考查点
Posted 勾勾的Java宇宙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了架构面试:RPC原理的考查点相关的知识,希望对你有一定的参考价值。
上一篇文章中,我主要说的是 RPC 实践类的面试题,接下来说说,原理题考查哪些知识点。
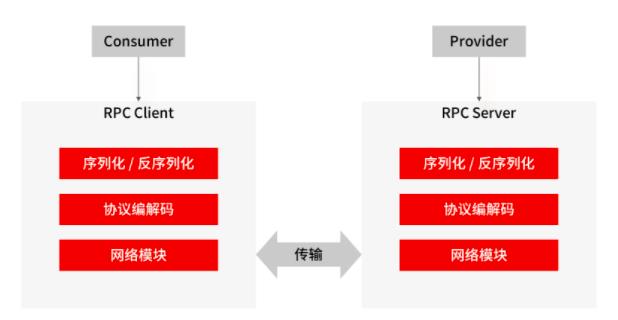
一次完整的 RPC 流程
调用方持续把请求参数对象序列化成二进制数据,经过 TCP 传输到服务提供方;
服务提供方从 TCP 通道里面接收到二进制数据;
根据 RPC 协议,服务提供方将二进制数据分割出不同的请求数据,经过反序列化将二进制数据逆向还原出请求对象,找到对应的实现类,完成真正的方法调用;
然后服务提供方再把执行结果序列化后,回写到对应的 TCP 通道里面;
调用方获取到应答的数据包后,再反序列化成应答对象。
如何选型序列化方式
RPC 的调用过程会涉及网络数据(二进制数据)的传输,从中延伸的问题是:如何选型序列化和反序列化方式?
常见的方式有以下几种。
JSON:Key-Value 结构的文本序列化框架,易用且应用最广泛,基于 HTTP 协议的 RPC 框架都会选择 JSON 序列化方式,但它的空间开销很大,在通信时需要更多的内存。
Hessian:一种紧凑的二进制序列化框架,在性能和体积上表现比较好。
Protobuf:Google 公司的序列化标准,序列化后体积相比 JSON、Hessian 还要小,兼容性也做得不错。
明确“常见的序列化方式”后,你就可以组织回答问题的逻辑了:考虑时间与空间开销,切勿忽略兼容性。
在大量并发请求下,如果序列化的速度慢,势必会增加请求和响应的时间(时间开销)。另外,如果序列化后的传输数据体积较大,也会使网络吞吐量下降(空间开销)。所以,你要先考虑这两点才能保证 RPC 框架的整体性能。
除此之外,在 RPC 迭代中,常常会因为序列化协议的兼容性问题使 RPC 框架不稳定,比如某个类型为集合类的入参服务调用者不能解析,某个类的一个属性不能正常调用......
当然还有安全性、易用性等指标,不过并不是 RPC 的关键指标。
总的来说,在面试时,你要综合考虑上述因素,总结出常用序列化协议的选型标准,比如首选 Hessian 与 Protobuf,因为它们在时间开销、空间开销、兼容性等关键指标上表现良好。
如何提升网络通信性能
如何提升 RPC 的网络通信性能,翻译一下就是:一个 RPC 框架如何选择高性能的网络编程 I/O 模型?
你首先要掌握网络编程中的五个 I/O 模型:
同步阻塞 I/O(BIO)
同步非阻塞 I/O
I/O 多路复用(NIO)
信号驱动
异步 I/O(AIO)
但在实际开发工作,最为常用的是 BIO 和 NIO(这两个 I/O 模型也是面试中面试官最常考查候选人的)。
为了让你更好地理解编程模型中这两个 I/O 模型典型的技术实现,我以 Java 程序例,编程写了一个简单的网络程序:
public class Biosever {
ServerSocket ss = new ServerSocket();
// 绑定端口 9090
ss.bind(new InetSocketAddress("localhost", 9090));
System.out.println("server started listening " + PORT);
try {
Socket s = null;
while (true) {
// 阻塞等待客户端发送连接请求
s = ss.accept();
new Thread(new ServerTaskThread(s)).start();
}
} catch (Exception e) {
// 省略代码...
} finally {
if (ss != null) {
ss.close();
ss = null;
}
}
public class ServerTaskThread implements Runnable {
// 省略代码...
while (true) {
// 阻塞等待客户端发请求过来
String readLine = in.readLine();
if (readLine == null) {
break;
}
// 省略代码...
}
// 省略代码...
}
这段代码的主要逻辑是:在服务端创建一个 ServerSocket 对象,绑定 9090 端口,然后启动运行,阻塞等待客户端发起连接请求,直到有客户端的连接发送过来后,accept() 方法返回。当有客户端的连接请求后,服务端会启动一个新线程 ServerTaskThread,用新创建的线程去处理当前用户的读写操作。
BIO 网络模型
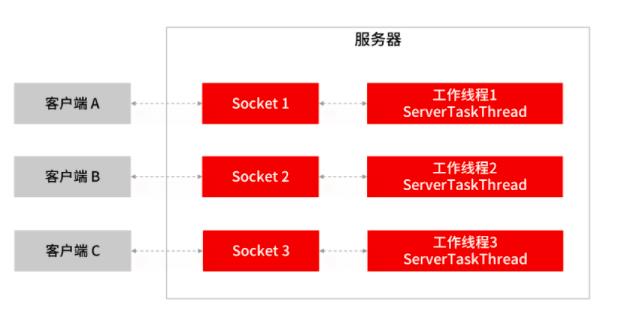
BIO 的网络模型中,每当客户端发送一个连接请求给服务端,服务端都会启动一个新的线程去处理客户端连接的读写操作,即每个 Socket 都对应一个独立的线程,客户端 Socket 和服务端工作线程的数量是 1 比 1,这会导致服务器的资源不够用,无法实现高并发下的网络开发。
所以 BIO 的网络模型只适用于 Socket 连接不多的场景,无法支撑几十甚至上百万的连接场景。
另外,BIO 模型有两处阻塞的地方。
服务端阻塞等待客户端发起连接。在第 11 行代码中,通过 serverSocket.accept() 方法服务端等待用户发连接请求过来。
连接成功后,工作线程阻塞读取客户端 Socket 发送数据。在第 27 行代码中,通过 in.readLine() 服务端从网络中读客户端发送过来的数据,这个地方也会阻塞。如果客户端已经和服务端建立了一个连接,但客户端迟迟不发送数据,那么服务端的 readLine() 操作会一直阻塞,造成资源浪费。
以上这些就是 BIO 网络模型的问题所在。
NIO 网络模型
那怎么解决 BIO 的问题呢?
答案是 NIO 网络模型。操作上是用一个线程处理多个连接,使得每一个工作线程都可以处理多个客户端的 Socket 请求,这样工作线程的利用率就能得到提升,所需的工作线程数量也随之减少。此时 NIO 的线程模型就变为 1 个工作线程对应多个客户端 Socket 的请求,这就是所谓的 I/O 多路复用。
顺着这个思路,我们继续深入思考:既然服务端的工作线程可以服务于多个客户端的连接请求,那么具体由哪个工作线程服务于哪个客户端请求呢?
这时就需要一个调度者去监控所有的客户端连接,比如当图中的客户端 A 的输入已经准备好后,就由这个调度者去通知服务端的工作线程,告诉它们由工作线程 1 去服务于客户端 A 的请求。这种思路就是 NIO 编程模型的基本原理,调度者就是 Selector 选择器。
由此可见,NIO 比 BIO 提高了服务端工作线程的利用率,并增加了一个调度者,来实现 Socket 连接与 Socket 数据读写之间的分离。
其他
在目前主流的 RPC 框架中,广泛使用的也是 I/O 多路复用模型,Linux 系统中的 select、poll、epoll 等系统调用都是 I/O 多路复用的机制。
在面试中,对于高级研发工程师的考查,还会有两个技术扩展考核点。
Reactor 模型(即反应堆模式),以及 Reactor 的 3 种线程模型,分别是单线程 Reactor 线程模型、多线程 Reactor 线程模型,以及主从 Reactor 线程模型
Java 中的高性能网络编程框架 Netty
可以这么说,在高性能网络编程中,大多数都是基于 Reactor 模式,其中最为典型的是 Java 的 Netty 框架,而 Reactor 模式是基于 I/O 多路复用的,所以,对于 Reactor 和 Netty 的考查也是避免不了的。因为相关资料很多,我就不展开了。
当然在实际工作中,一个产品级别的 RPC 框架的开发,还要具备如连接管理、负载均衡、请求路由、熔断降级、优雅关闭等高级功能的设计,虽然这些内容在面试中不要求你掌握,但是如果你了解是可以作为加分项的,例如连接管理就会涉及连接数的维护与服务心跳检测。
推荐阅读:
以上是关于架构面试:RPC原理的考查点的主要内容,如果未能解决你的问题,请参考以下文章