PyTorch深度学习实践入门01
Posted 云才哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch深度学习实践入门01相关的知识,希望对你有一定的参考价值。
文章目录
基于PyTorch的两层神经网络
提示:在计算神经网络的层数时,只计算具有计算能力的层,而输入层只是将数据进行输入,无计算过程,所以层数:隐藏层层数+1个输出层。所以在此文中两层即一层隐藏层和一层输出层。
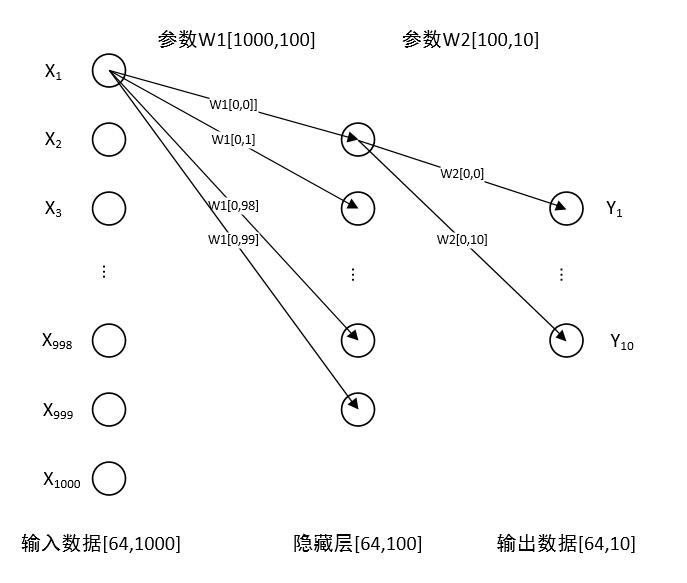
本案例中实现的两层神经网络如下图所示:其中输入X为1000维的向量,输出Y为10维的向量。而中间隐藏层的神经元个数为100。
一、基于numpy的两层神经网络实现:
为显示出PyTorch框架在深度学习上的便利,本文首先使用numpy最原始的方法实现一下神经网络。
import numpy as np
# N(输入数据数量); D_in(输入数据维度);
# H(隐藏神经元个数); D_out(输出维度).
N, D_in, H, D_out = 64, 1000, 100, 10
# 创建训练集
x = np.random.randn(N, D_in)
y = np.random.randn(N, D_out)
# 初始化权重向量
w1 = np.random.randn(D_in, H) # w1为输入数据到隐藏层的计算参数
w2 = np.random.randn(H, D_out) # w2为隐藏层到输出数据的计算参数
learning_rate = 1e-6 #设置模型的学习速率
for t in range(500): #设置梯度下降的次数为500
# Forward pass: compute predicted y
h = x.dot(w1)
h_relu = np.maximum(h, 0) #使用relu激活函数,为解决非线性函数拟合问题
y_pred = h_relu.dot(w2)
# 定义损失函数,计算损失(该处使用方差来计算计算损失)
loss = np.square(y_pred - y).sum()
print(t, loss)
# Backward 计算梯度
# loss = (y_pred - y) ** 2,梯度下降的目的是要使得损失尽可能小
# loss = f(w1,w2) #梯度下降求梯度时,参数为变量,损失为因变量,由此需要根据链式法则来求w1和w2的梯度。
grad_y_pred = 2.0 * (y_pred - y) #根据方差损失函数的梯度公式求取梯度
grad_w2 = h_relu.T.dot(grad_y_pred)
grad_h_relu = grad_y_pred.dot(w2.T)
grad_h = grad_h_relu.copy()
grad_h[h < 0] = 0
grad_w1 = x.T.dot(grad_h)
# 根据梯度和学习速率,更新参数。
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
二、基于PyTorch的两层神经网络实现:
为显示出PyTorch框架的一些内置功能模块在深度学习上的遍历,以及方便入门理解PyTorch原理,先使用PyTorch最原始的方法实现一下神经网络。
PyTorch的一个重要功能就是autograd,也就是说只要定义了forward pass(前向神经网络),计算了loss之后,PyTorch可以自动求导计算模型所有参数的梯度。
一个PyTorch的Tensor表示计算图中的一个节点。如果x是一个Tensor并且x.requires_grad=True那么x.grad是另一个储存着x当前梯度(相对于一个scalar,常常是loss)的向量。
import torch
dtype = torch.float
device = torch.device("cpu")
# device = torch.device("cuda:0") # Uncomment this to run on GPU
# N 是 batch size; D_in 是 input dimension;
# H 是 hidden dimension; D_out 是 output dimension.
N, D_in, H, D_out = 64, 1000, 100, 10
# 创建随机的Tensor来保存输入和输出
# 设定requires_grad=False表示在反向传播的时候我们不需要计算gradient
x = torch.randn(N, D_in, device=device, dtype=dtype)
y = torch.randn(N, D_out, device=device, dtype=dtype)
# 创建随机的Tensor和权重。
# 设置requires_grad=True表示我们希望反向传播的时候计算Tensor的gradient
w1 = torch.randn(D_in, H, device=device, dtype=dtype, requires_grad=True)
w2 = torch.randn(H, D_out, device=device, dtype=dtype, requires_grad=True)
learning_rate = 1e-6
for t in range(500):
# Forward pass: compute predicted y
h = x.mm(w1) # 在PyTorch中mm函数用来计算两个举证的乘积
h_relu = h.clamp(min=0) # tensor.clamp用来夹值,即不再指定[min,max]范围内的值置零,否则保持不变。
y_pred = h_relu.mm(w2)
# 通过前向传播计算loss
# loss是一个形状为(1,)的Tensor
# loss.item()可以给我们返回一个loss的scalar
loss = (y_pred - y).pow(2).sum()
print(t, loss.item())
"""
梯度优化实现方式一,于上方numpy的优化实现方式相同
# Backprop to compute gradients of w1 and w2 with respect to loss
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.t().mm(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.t())
grad_h = grad_h_relu.clone()
grad_h[h < 0] = 0
grad_w1 = x.t().mm(grad_h)
# Update weights using gradient descent
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
"""
"""
方式二:使用PyTorch自带的方向传播方式
"""
# PyTorch给我们提供了autograd的方法做反向传播。如果一个Tensor的requires_grad=True,
# backward会自动计算loss相对于每个Tensor的gradient。在backward之后,
# w1.grad和w2.grad会包含两个loss相对于两个Tensor的gradient信息。
loss.backward()
# 我们可以手动做gradient descent(后面我们会介绍自动的方法)。
# 用torch.no_grad()包含以下statements,因为w1和w2都是requires_grad=True,
# 但是在更新weights之后我们并不需要再做autograd。
# 另一种方法是在weight.data和weight.grad.data上做操作,这样就不会对grad产生影响。
# tensor.data会我们一个tensor,这个tensor和原来的tensor指向相同的内存空间,
# 但是不会记录计算图的历史。
with torch.no_grad():
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
# Manually zero the gradients after updating weights
w1.grad.zero_()
w2.grad.zero_()
三、使用nn库实现两层神经网络
使用PyTorch中nn这个库来构建网络。 用PyTorch autograd来构建计算图和计算gradients, 然后PyTorch会帮我们自动计算gradient。使用optim这个包来帮助我们更新参数。 optim这个package提供了各种不同的模型优化方法,包括SGD+momentum, RMSProp, Adam等等。
import torch
import numpy as np
# N(输入数据数量); D_in(输入数据维度);
# H(隐藏神经元个数); D_out(输出维度).
N, D_in, H, D_out = 64, 1000, 100, 10
# 创建训练集
x = np.random.randn(N, D_in)
y = np.random.randn(N, D_out)
# 定义模型网络结构,使用的是Sequential模型结构
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out),
)
# 定义损失函数
loss_fn = torch.nn.MSELoss(reduction='sum')
#设置学习速率
learning_rate = 1e-4
# 使用optim在更新参数,(可以设置下降方式)此处使用的是Adam优化算法
# 注意使用优化算法时需要将模型的参数和学习速率传入给优化算法
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
for t in range(500): # 定义下降次数为500
# Forward pass: 创建对象时会自动调用对象的forward函数
y_pred = model(x) #返回的就是预测的y值(即跑完nn库定义的网络图得到的结果)
# 计算损失.
loss = loss_fn(y_pred, y)
print(t, loss.item())
# PyTorch默认会对梯度值进行累加,所以进行反向传播计算梯度时,需要使用zero_grad()函数将梯度置零
optimizer.zero_grad()
# Backward pass: 反向传播计算梯度
loss.backward()
# 通过optimizer对象调用step函数更新参数
optimizer.step()
四、自定义nn Modules实现两层神经网络
定义一个模型,这个模型继承自nn.Module类。如果需要定义一个比Sequential模型更加复杂的模型,就需要定义nn.Module模型。
import torch
class TwoLayerNet(torch.nn.Module):
def __init__(self, D_in, H, D_out):
"""
初始化函数中需要
1、调用父类nn.Module的初始化函数
2、定义当前网络结构各层间参数(即整个网络结构计算图)
"""
super(TwoLayerNet, self).__init__()
self.linear1 = torch.nn.Linear(D_in, H)
self.linear2 = torch.nn.Linear(H, D_out)
def forward(self, x):
# 定义当前模型的forward函数
h_relu = self.linear1(x).clamp(min=0)
y_pred = self.linear2(h_relu)
return y_pred
# N(输入数据数量); D_in(输入数据维度);
# H(隐藏神经元个数); D_out(输出维度).
N, D_in, H, D_out = 64, 1000, 100, 10
# 创建训练集
x = np.random.randn(N, D_in)
y = np.random.randn(N, D_out)
# 实例化模型结构类,定义模型
model = TwoLayerNet(D_in, H, D_out)
# 使用交叉熵来衡量损失
criterion = torch.nn.MSELoss(reduction='sum')
# 使用SGD优化算法
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4)
for t in range(500):
# Forward pass: Compute predicted y by passing x to the model
y_pred = model(x)
# Compute and print loss
loss = criterion(y_pred, y)
print(t, loss.item())
# Zero gradients, perform a backward pass, and update the weights.
optimizer.zero_grad()
loss.backward()
optimizer.step()
总结
PyTorch框架在深度学习构建模型以及计算上非常便利。可以使用一些已经定义好的功能模块来提高编程效率。
- PyTorch的一个重要功能就是autograd,tensor.backward()可以自动进行反向传播计算梯度值(需要计算梯度值的tensor在定义时需要指定requires_grad=True),得到的梯度值则保存在tensor.grad属性中。
- 可以使用PyTorch中nn这个库来构建网络
- 使用optim这个包来帮助我们更新参数,而且可以使用不同的优化算法。
- 可以自定义nn.Module类实现自己需要的模型
- PyTorch默认会对梯度进行累加,所以在调用backward函数时,需要先使用model.zero_grad()来将梯度置零。
以上是关于PyTorch深度学习实践入门01的主要内容,如果未能解决你的问题,请参考以下文章