联邦学习中的数据异构性问题综述
Posted LeoJarvis
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了联邦学习中的数据异构性问题综述相关的知识,希望对你有一定的参考价值。
摘要
联邦学习中的数据异构性问题主要是由参与训练的各客户端的数据虽独立分布但不服从同一采样方法(Non-IID)所导致的,这一问题也导致模型精度的严重下降。如何缓解Non-IID带来的不利影响目前仍是一个开放性的问题。
目前已经有很多算法可以应用于这一问题的处理上,但由于这些算法的实验都是基于不同的Non-IID场景,我们没办法系统地、直观地理解这些算法的优缺点。
为了能对各算法的性能进行一个比较,《Federated Learning on Non-IID Data Silos: An Experimental Study》这篇文章为Non-IID数据的划分策略提出了一个基准——NIID-Bench,NIID-Bench提供了全面的划分策略和数据集来覆盖不同的Non-IID场景,文章还对几种算法进行了系统的比较,并讨论了机器学习在分布式数据中存在的问题及其未来的研究方向。
数据划分策略
数据划分策略具体需要讨论两个问题:
第一:数据集是使用真实世界的Non-IID数据集还是合成数据集。
第二:如何设计全面的Non-IID场景。
该文章提出了一种名为“NIID-Bench”的划分策略,对于这两个问题,NIID-Bench做了如下处理:
对于第一个问题,NIID-Bench选择通过将真实数据集划分为多个较小的子集来合成分布式Non-IID数据集。与使用真实的联邦数据集相比,采用划分策略有以下优点:
首先,真实联邦数据集中的不平衡程度通常很难评估,但划分策略可以很容易地量化和控制局部数据的不平衡程度。
其次,划分策略可以设置不同数量的参与者来模拟不同的场景,而真实的联邦数据集的数据资源通常是固定的。
最后,由于数据规则和隐私问题,适用于训练的真实联邦数据集可能不是公开的。在现有广泛使用的公共数据集上开发划分策略显得更加灵活,这些数据集已经有大量集中的训练知识作为参考,并且可以模拟不同的Non-IID场景。
对于第二个问题,具体的划分策略参考《Advances and Open Problems in Federated Learning》这篇文章中对Non-IID场景的分类。
简单来讲,该文章总结了Non-IID数据分布的五种不同情况:(1)标签分布倾斜;(2)特征分布倾斜;(3)标签相同但特征不同;(4)特征相同但标签不同;(5)数量倾斜。五种情况具体的含义可以看我之前的这篇文章
这里第三种情况主要与纵向FL有关(各方样本id相同,但特征不同,eg:对于同一个id,银行有他的贷款信息,超市有他的购物信息)。文章中关注的是横向FL(各方特征空间相同,但拥有不同的样本id,eg:每个银行都有客户的贷款信息,但不同地方的银行客户群体不同)。第四种情况在大多数联邦学习中并不会遇到。因此,本文将标签分布倾斜、特征分布倾斜和数量倾斜视为可能存在的Non-IID数据分布情况并对每种场景进行数据模拟。
针对每种情况的数据模拟方法
标签分布倾斜
文章模拟了两种标签分布倾斜的场景,基于数量的标签不平衡和基于分布的标签不平衡。
基于数量的标签不平衡:
每个客户端的数据样本中,标签的种类是固定的。文章引入了一个通用的划分策略来设置每个客户端的标签数量。假设每个客户端的数据样本只有K个不同的标签。首先随机分配K个不同的标签id给每个客户端。然后,对于每个标签的样本,我们将它们随机平均地分配给拥有该标签的客户端。这样,每个用户的标签数量是固定的,不同用户的样本之间没有重叠。后面用#C = K来表示这种划分策略。
基于分布的标签不平衡:
每个标签都根据狄利克雷分布给每个用户分配一定比例的该标签的样本。具体而言,根据
p
k
p_k
pk~
D
i
r
N
Dir_N
DirN(β)进行采样,并将标签K的比例为
p
k
,
j
p_{k,j}
pk,j的样本分配给用户j。其中Dir(.)代表狄利克雷分布,参数β > 0。这种方法的优点是可以通过β的大小调整不平衡程度。β越小越不平衡。下图为β= 0.5时,该划分策略在MNIST数据集的应用。每个矩形中的值是一个用户某个标签的数据样本数量。后面用
p
k
p_k
pk~Dir(β)来表示这种划分策略。
特征分布倾斜
文章模拟了三种特征分布倾斜的场景,基于噪声的特征不平衡、合成特征不平衡和real-world特征不平衡。
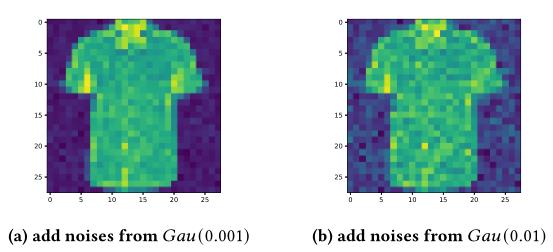
基于噪声的特征不平衡:
首先将整个数据集随机平均地分成多个部分作为用户的本地数据。对每个用户的本地数据集添加不同程度的高斯噪声,以实现不同的特征分布。具体来说,给定用户的噪声等级σ,我们为用户
p
i
p_i
pi添加噪声X~Gau(σ·i/N)。其中 Gau(σ·i/N)是均值为0,方差为σ·i/N的高斯分布。可以通过改变σ增加用户之间的特征差异。下图是FMNIST数据集上基于噪声的特征不平衡的示例。后面用使用X~Gau(σ)来表示这种划分策略。
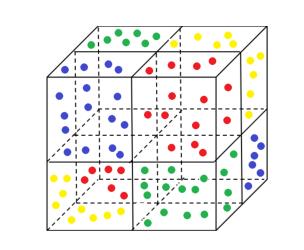
合成特征不平衡:
文章中构建一个名为FCUBE的合成特征不平衡联邦数据集。假设数据点的分布是一个三维立方体(
x
1
x_1
x1、
x
2
x_2
x2、
x
3
x_3
x3)。如下图所示,用平面
x
1
x_1
x1= 0、
x
2
x_2
x2= 0和
x
3
x_3
x3= 0将立方体分成8个部分。然后将关于点(0,0,0)对称的两个部分分配给每个用户。看图说话:上面四个立方体中的数据点的标签是0,下面四个立方体中的数据点的标签是1。一共有八个立方体,有四种颜色。颜色相同的数据点被分配给一个用户。这样,在标签仍然平衡的情况下,各用户之间的特征分布是不同的。
real-world特征不平衡:
EMNIST数据集收集来自不同作者的手写字符/数字。根据不同作者将数据集划分成不同的子集并分配给每个客户端。由于不同作者的字迹不同(笔画宽度、斜度等),在不同客户端之间便有了天然的特征分布不平衡。这个联邦数据集名为FEMNIST。
数量倾斜
在数量不平衡的情况下,本地数据集| D i D_i Di|的大小因客户端而异。像基于分布的标签不平衡设置一样,我们使用狄利克雷分布将不同数量的数据样本分配给每一方。我们按 q~ D i r N Dir_N DirN(β) 进行采样,并将总数据样本中比例为 q j q_j qj的部分分配给客户端 p j p_j pj。参数β可用于控制数量倾斜程度。后面用q~Dir(β)来表示这种划分策略。
实验结果
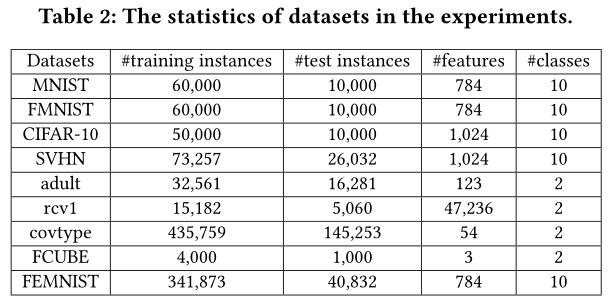
为了研究现有FL算法在非理想数据设置上的有效性,文章将四个算法(FedAvg,FedProx,SCAFFOLD和 FedNova)在九个公共数据集上进行了广泛的实验,包括六个图像数据集(即MNIST、CIFAR-10 、FMNIST 、SVHN、FCUBE、FEMMIST)和三个表格数据集(即adult、rcv1和covtype)。表二总结了数据集的统计数据。
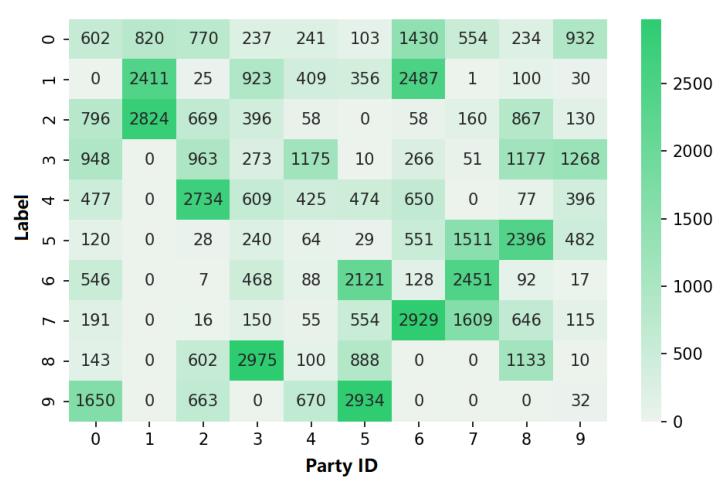
使用测试数据集中的top-1准确度作为度量标准来比较所研究的算法。所有的算法运行相同的轮数。四个算法在不同Non-IID场景中的准确度如下表所示:
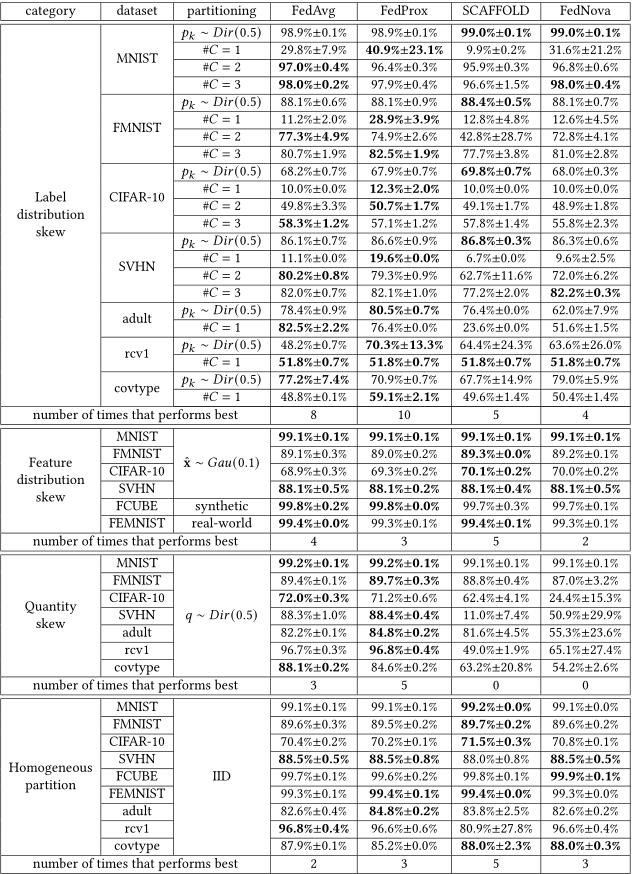
实验发现
一、对不同的Non-IID场景比较发现:在所有Non-IID场景中,标签分布倾斜对FL算法的准确性影响最大。
二、对四个不同的算法性能的比较发现:没有哪个算法在任何场景中的表现都比其他算法好。
三、对不同数据集的比较发现:在Non-IID环境下,CIFS-10和表格数据集是具有挑战性的任务。在大多数Non-IID环境下,MNIST是一个简单的任务,所研究的算法表现都差不多。
四、对本地更新的鲁棒性比较发现:本地更新的迭代次数对现有算法的准确性有很大影响,最优迭代次数对Non-IID分布非常敏感,不同的场景有不同的最优迭代次数。
五、对不同batch size的比较发现:本地数据的异质性似乎不会影响batch size的选择。
六、对不同模型结构的比较发现:以batch normalization layers的简单平均来实现聚合在Non-IID中具有不稳定性。虽然本地batch normalization layers可以很好地处理本地分布,但由这些层的简单平均实现的聚合可能无法捕捉全局分布的统计数据,而且会导致更多的不稳定性。
七、对可扩展性的比较发现:如果限制只有部分客户端参与训练,SCAFFOLD无法有效工作,而其他FL算法在训练过程中的精度也非常不稳定。
对未来研究方向的讨论
关于数据管理
一、Integration with learned database systems
二、Light-weight data techniques for profiling non-IID data
不同的Non-IID分布对FL算法的精度和稳定性有很大的影响。因此,在进行联邦学习前,如果我们能事先知道其Non-IID分布,将会很有帮助。实现方法例如数据采样,sketching,在元数据中使用Non-IID分布等
三、Non-IID resistant sampling for partial participation
相对于随机抽样,根据参与者的数据分布特征进行选择性抽样可以显著提高训练稳定性。其中一个灵感来自于 the skew resistant data techniques,它可以潜在地扩展到“部分参与”的FL训练。
四、the skew resistant data techniques
虽然在FL中没有原始数据的传输,但模型仍可能因为受到推理攻击而泄漏训练数据的敏感信息。因此,差分隐私保护等技术对于保护本地数据非常有用。如何在保证差分隐私保护的同时降低精度损失是一个具有挑战性的研究方向。
五、Query on Federated Databases
考虑到隐私问题,联邦数据库的构建也是一项挑战。一方面,如何将联邦数据库上的SQL查询与机器学习相结合是一个重要的问题。另一方面,如何在支持联邦数据库的查询和学习的同时保护数据的隐私也亟待研究。
关于联邦学习设计
一、A Party with a Single Label
上述实验表明,如果每个客户端都只有一个标签的数据,那么FL算法的准确性将会非常差。这种场景似乎不现实。然而,它在实际中确有许多应用。例如,我们可以使用FL来训练speaker识别模型,而每个移动设备只有其单个用户的声音数据。
二、Fast Training
为了提高训练速度,文章建议可以从以下两个方向进行研究。
一个可能的解决方案是开发只有几轮的通信高效的FL算法。
另一个可能的方法是开发快速初始化方法,实现在减少训练轮数的同时具备相同准确性的FL。
三、Automated Parameter Tuning for FL
在FL中,本地更新的次数是一个重要的参数。一种传统的方法是开发对局部更新具有鲁棒性的方法,另一种是设计有效的参数调优方法。《Federated Bayesian optimization via Thompson sampling》这篇文章研究了贝叶斯优化,可以用来寻找hyper-parameters。
四、Towards Robust Algorithms against Different Non-IID Set-
tings:
为不同的Non-IID场景开发一个健壮的算法。这可能需要先研究不同Non-IID场景中FL的共同特征。
五、Aggregation of Heterogeneous Batch Normalization
实验发现中第六点表明,对batch normalization layers的简单平均而实现的聚合并非好主意。由于各参与方的batch normalization记录了本地数据分布的统计数据,因此不同参与方的批标准化层之间也存在异构性。对不同参与方的batch normalization layers进行简单平均,再发送回各参与方,各参与方可能无法捕获本地数据分布。《Siloed Federated Learning for Multi-Centric Histopathology Datasets》这篇文章提出,不考虑统计数据(即平均值和方差),只对学习到的参数进行平均。针对深度学习中特定层的更专门的设计亦待研究。
以上是关于联邦学习中的数据异构性问题综述的主要内容,如果未能解决你的问题,请参考以下文章