pFedHN论文阅读笔记
Posted LeoJarvis
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pFedHN论文阅读笔记相关的知识,希望对你有一定的参考价值。
《Personalized Federated Learning using Hypernetworks》提出一种用于个性化联邦学习的方法“pFedHN” (personalized Federated HyperNetworks)。该方法通过训练中央超网络模型,实现跨客户端的参数共享,并为每个客户端生成独特的个性化模型。
该方法的创新点主要有以下两点:
1、该超网络具备较强的泛化能力,即便(a)新的客户端的数据分布不同于训练时的客户端,(b)新的客户端具备不同的计算性能(这使得不同客户端可以训练不同规模的模型。)
2、超网络的参数不需要传输,所以超网络的模型大小不影响通信成本。
pFedHN具体是啥?
pFedHN中的超网络是一个深度神经网络,可以同时学习一系列目标网络(各客户端的个性化模型参数)。如下图所示,其中h(;φ)表示由φ参数化的超网络,f(;θ)代表由θ参数化的目标网络。超网络位于服务器上,通过客户端描述符
v
i
v_i
vi初始化目标网络参数。
v
i
v_i
vi可以是客户端的可训练嵌入向量,也可以是固定的,前提是预先知道一个好的客户端representation。
子图b:给定
v
i
v_i
vi,超网络输出第i个客户端的模型参数
θ
i
θ_i
θi =
θ
i
(
φ
)
θ_i(φ)
θi(φ) = h(
v
i
v_i
vi;φ)。
子图a:超网络可以同时学习一系列个性化模型{ h(
v
i
v_i
vi;φ) | i ∈ [n]},通过目标网络反馈的
∆
θ
i
∆θ_i
∆θi (
θ
i
θ_i
θi 在客户端执行几轮本地更新后的变化量)更新
θ
i
θ_i
θi。
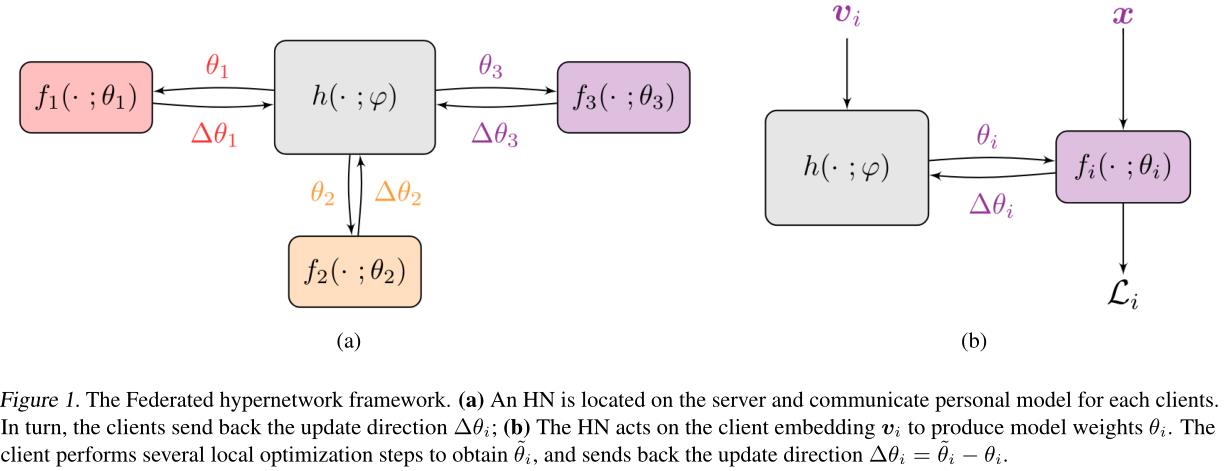
可以看出,pFedHN通过共享参数φ,实现跨客户端信息共享,并生成个性化模型。值得注意的是,服务器与客户端之间交换的信息只有目标模型的参数,通信代价只与目标模型的大小有关,所以服务器上的超网络可以是一个很大的网络,因为这并不影响通信效率。具体的算法流程如Algorithm 1所示

特殊情况——个性化分类器
在某些情况下,用单个超网络端到端地学习整个目标网络并不合适。例如,每个客户端解决一个完全独立的任务,拥有不同类别的数据,类似于多任务学习。这时让超网络来为每个客户端生成用于分类决策的层显得意义不大。
此时超网络应该训练每个目标网络的输出层,并生成每个目标网络中用于特征提取的层,该部分包含大多数可训练参数。
ω
i
ω_i
ωi表示客户端i的分类器参数。优化目标为
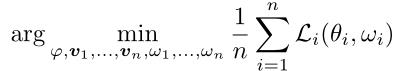
其中特征提取器
θ
i
θ_i
θi=h(
v
i
v_i
vi;φ),参数φ,
v
1
v_1
v1,…,
v
n
v_n
vn的更新如Algorithm 1,个性化参数
ω
i
ω_i
ωi的更新如下所示
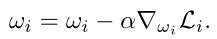
理论分析
这里设计挺多的数学推导、最大相似估计、高斯噪声等等理论知识,我还不太熟悉,这里就不展开了,有兴趣的可以具体看看论文里的分析。
实验分析
数据集和模型设置:CIFAR10, CI-FAR100, 和Omniglot三个图像分类数据
CIFAR10:每个客户端分配两个类别的数据,然后对于客户端 i 和类C,根据
a
i
,
c
a_{i,c}
ai,c~U(.4, .6)进行采样,并将类c按比例
a
i
,
c
a_{i,c}
ai,c/
Σ
j
Σ_j
Σja_{j,c}进行数据分配。客户端数量为10、50、100。使用基于LeNet的模型,两个卷积层和两个完全连接层。
CI-FAR100:每个客户端分配十个类别的数据,然后对于客户端 i 和类C,根据
a
i
,
c
a_{i,c}
ai,c~U(.4, .6)进行采样,并将类c按比例
a
i
,
c
a_{i,c}
ai,c/
Σ
j
Σ_j
Σja_{j,c}进行数据分配。客户端数量为10、50、100。使用基于LeNet的模型,两个卷积层和两个完全连接层。
Omniglot:Omniglot包含来自50个不同字母的1623个不同灰度手写字符(每个字符有20个样本)。每个字母表都有不同数量的字符。设置50个客户端,每个客户机分配一个字母表。这样一来每个客户端的数据量和数据类别都不同。使用基于LeNet的模型,四个卷积层和两个完全连接层。
评价指标:
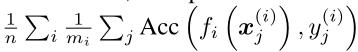
参与比较的八个方法
1、pFedHN
2、pFedHN-PC:pFedHN为每个客户端生成个性化分类器
3、Local:每个客户端不进行写作训练,仅根据自己的本地数据进行训练
4、FedAvg
5、Per-FedAvg:基于元学习的个性化联邦学习
6、pFedMe:添加了Moreau-envelopes loss的个性化联邦学习
7、 LG-FedAvg:基于局部特征提取和全局输出层的个性化联邦学习
8、FedPer :每个客户端在共享的特征提取器上学习个性化分类器。
训练设置
八个实验中的目标网络结构都相同,。超网络是一个简单的全连接神经网络,有三个隐藏层。大多是算法的训练过程限制为最多5000个服务器-客户机通信步骤。因为LG-FedAvg使用一个预训练的FedAvg模型,还需要额外的1000个通信步骤。对于“local”,每个客户机上执行2000个优化步骤。对于pFedHN,设置本地迭代次数K = 50,嵌入向量的维度为[1 + n/4],其中n为客户端数量。使用预先分配的验证集调整所有方法的超参数。
实验结果
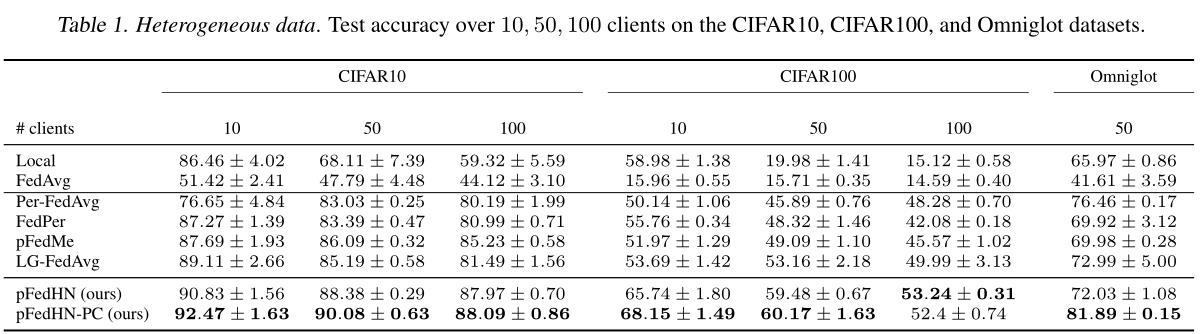
没有使用个性化联邦学习的local和FedAvg在大多数任务上的表现都很差,这体现了个性化联邦学习的重要性。
pFedHN相比于其他方法实现了2%-10%的精度提升。此外,在Omniglot数据集上,每个客户端都基于不同的学习任务(不同的字母),pFedHN-PC显示了显著的精度提升。
pFedHN与设备异构性
上面的实验分析是基于数据异构性和模型异构性,联邦学习中还有一种异构情况为设备异构型,源于不同设备的具有不同的计算性能、存储性能等。
由于pFedHN可以产生不同大小的目标网络,理论上可以很自然的应对这一问题。
文章做了具体的实验,根据上一个实验的划分方法,将75个客户端根据大小分为大中小三组,每组都有25个客户端。同一组的模型相同,不同组的模型参数量不同。
用pFedHN输出不同大小的目标网络与其他方法的结果进行对比,实验结果如下:
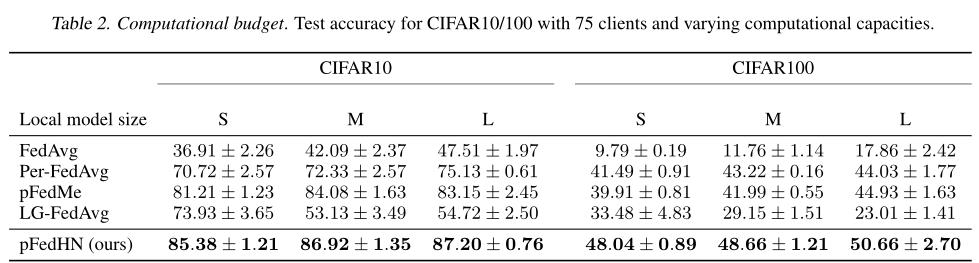
可以看出,pFedHN相对于其他方法具有4% ~ 8%的精度提升。说明该方法能在应对设备异构性问题的同时,保持较高的准确度。
总结
该文章提出了一种新的个性化联邦学习方法。通过训练一个中心超网络为每个客户端输出一个独特的个性化模型。文章通过大量的实验表明,模型的精度在异构性问题中有显著提高。
与之前的方法相比,该方法有几个优点:
1、由于该方法根据客户端的分布情况训练了一个统一模型,该模型可以很好的地泛化到新客户端,而不需要对中心模型进行再训练。
2、该方法通过产生不同规模的客户端模型,可以自然地处理设备异构型问题。
3、该方法将训练复杂度与通信复杂度解耦,因为传输给客户端的个性化模型比中心模型要小得多。
展望
首先,该架构提出了一个问题:模型的训练工作如何在中央模型与分布式客户端之间进行最佳方式分配。
其次,该架构对于新客户端的泛化问题有待进一步分析。
以上是关于pFedHN论文阅读笔记的主要内容,如果未能解决你的问题,请参考以下文章