22 消费者从Master或Slave拉取消息的策略
Posted 鮀城小帅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了22 消费者从Master或Slave拉取消息的策略相关的知识,希望对你有一定的参考价值。
1.回顾Broker读写分离架构
在该架构中,刚开始消费者是连接到Master Broker机器去拉取消息的,然后如果Master Broker机器觉得自己负载比较高,就会告诉消费者机器,下次可以从Slave Broker机器去拉取。
2.CommitLog基于 OS Cache提升写性能的回顾
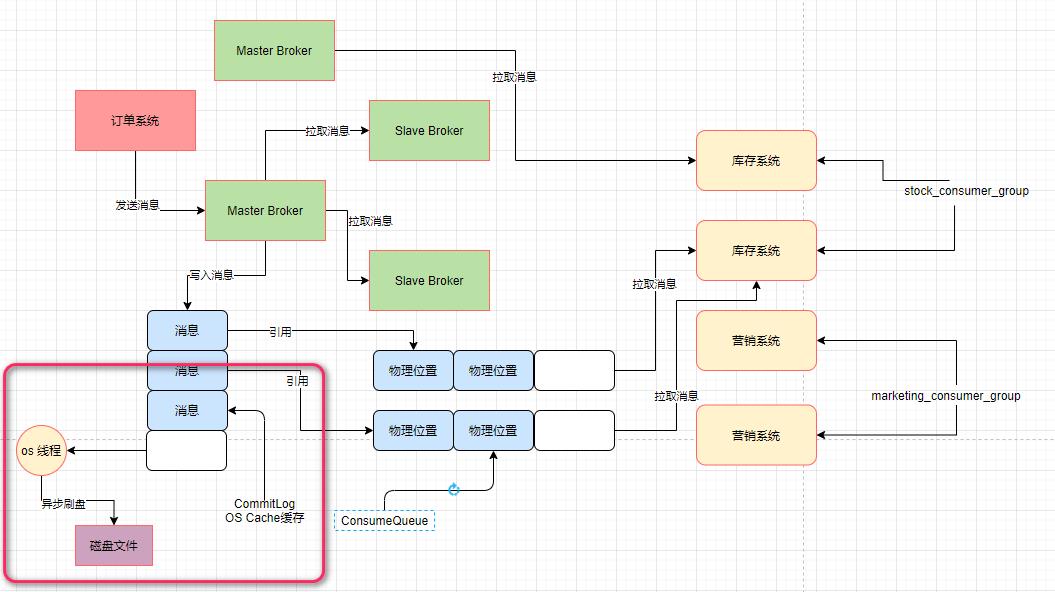
Broker收到一条消息,会写入CommitLog文件,但是会先把CommitLog文件中的数据写入os cache(操作系统管理的缓存)中去。
然后os自己有后台线程,过一段时间后会异步把os cache缓存中的commitLog文件数据刷入磁盘中去。
而依靠这个写入CommitLog时先进入os cache缓存,而不是直接进入磁盘的机制,就可以实现broker写CommitLog文件的性能是内存写级别的,这才能实现broker超高的消息接入吞吐量。
3.ConsumeQueue文件也是基于os cache的
实际上Broker对ConsumeQueue文件同样也是基于os cache来进行优化的。对于Broker机器的磁盘上的大量的ConsumeQueue文件,在写入的时候也都是优先进入os cache中的。
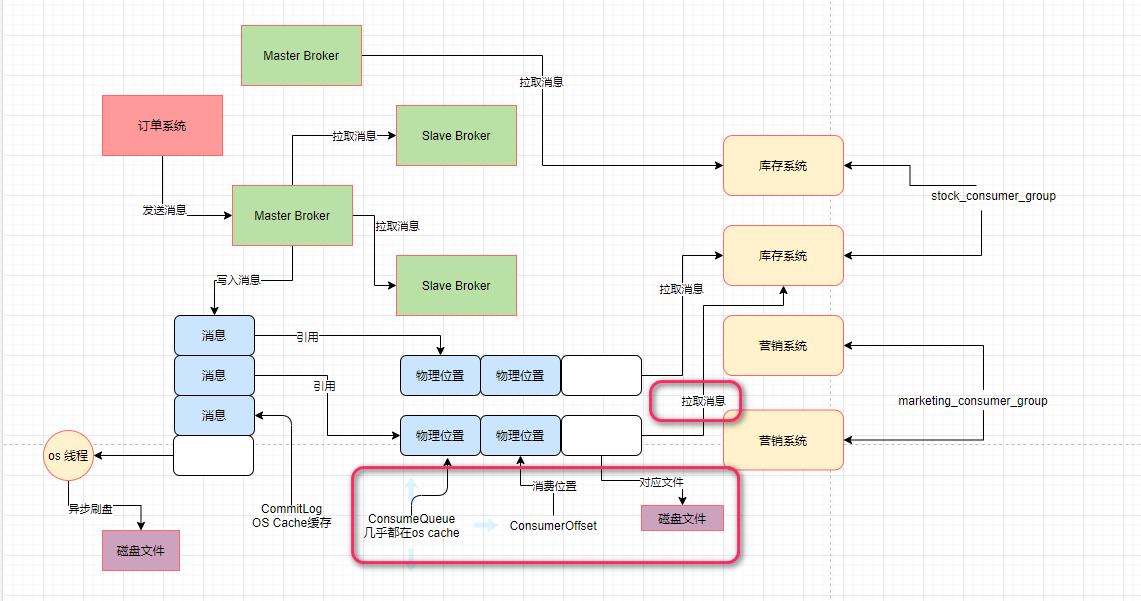
而且os自己有一个优化机制,就是读取一个磁盘文件的时候,它会自动把磁盘文件的一些数据缓存到os cache中。
在消费者机器拉取消息的时候,第一步大量的频繁读取ConsumeQueue文件,几乎可以说就是跟读内存里的数据的性能是一样的,通过这个就可以保证数据消费的高性能以及高吞吐。
4.消费时,CommitLog是基于os cache+磁盘一起读取的
当你拉取消息的时候,可以轻松从os cache里读取少量的ConsumeQueue文件里的offset,这个性能是极高的,但是当你去CommitLog文件里读取完整消息数据的时候,会有两种可能。
第一种可能,如果你读取的是那种刚刚写入CommitLog的数据,那么大概率他们还停留在os cache中,此时你可以顺利的直接从os cache里读取CommitLog中的数据,这个就是内存读取,性能很高。
第二种可能,你也行读取的是比较早之前写入CommitLog的数据,那些数据早就被刷入磁盘了,已经不在os cache里了,那么此时你就只能从磁盘上的文件里读取了,这个性能是比较差一些的。
5.场景解读——消费者什么时候会从os cache读?什么时候会从磁盘读?
如果你的消费者机器一直快速的在拉取和消费处理,紧紧的跟上了生产者写入broker的消息速率,那么你每次拉取几乎都是在拉取最近人家刚写入CommitLog的数据,那几乎都在os cache里。
但是如果broker的负载很高,导致你拉取消息的速度很慢,或者是你自己的消费者机器拉取到一批消息之后处理的时候性能很低,处理的速度很慢,这都会导致你跟不上生产者写入的速率。
场景解读
比如生产者写入10万条数据了,消费者才拉取2万条数据,此时有5万条最新的数据在os cache里,那么就有3万条还没拉取的数据是在磁盘里,那么当后续你再去拉取的时候,必然很大概率是从磁盘里读取早就刷入磁盘的3万条数据。
同样的,当前os cache里的5万条数据你还是回从磁盘里去读取的,因为当你再次来读取时,生产者又重新刷了一遍数据到磁盘。
6.Master Broker什么时候让你从Slave Broker拉取数据
假设master broker写入了10万条数据,但是消费者仅仅拉取了2万条数据,那么下次就从2万零1条数据开始拉取。总共还需要拉取8万条数据。
对于broker而已,它知道自己机器上的整体物理内存大小,也知道可用的最大空间占里面的比例,假设它只有10GB的os cache去放消息,最多可存储5万左右的消息。
当消费者第一次过来拉取消息后,它发现你还有8万条消息没有拉取,这个8万条消息它发现是大于10GB内存最多存放的5万条消息的,那么此时就说明,肯定有3万条消息目前是在磁盘上,不在os cache内存里的。
综上所述,broker会发现你很大概率会从磁盘里加载3万条消息出来。
而这种直接从磁盘加载消息的情况,broker认为自己作为master broker负载太高,导致没法及时的把消息给你。所以导致你拉取落后的进度比较多。它会告诉你,下次还是从slave broker去拉取吧!
总结:对比你当前没有拉取消息的数量和大小,以及最多可以存放在os cache内存里的消息的大小,如果你没拉取的消息超过了最大能使用的内存的量,那么说明你后续会频繁从磁盘加载数据,此时就让你从slave broker去加载数据了。
扩展:
(1)commitLog文件中消费过的消息就直接删掉了吗 ?
答:不会直接删除掉,会保留一定的天数后删除
(2)假如os cache缓存了几万条消息,这几万条消息是不是在磁盘中也已经有一份了,要不然宕机了岂不是这几万消息没了?如果这些消息缓存和磁盘存了两份,那ConsuerQueue中该条消息的偏移量地址是内存中的地址,还是磁盘中的地址?
答:commitLog先存储在os cache中然后进行异步刷盘操作,ConsumerQueue优先去os cache中根据offset来查找找不到再去磁盘中。
(3)消费者机器到底是跟少说机台Broker建立连接,还是跟所有Broker都建立连接?
答:消费者订阅的Topic中的MessageQueue分布在几个Broker上,就跟几个Broker建立连接。
(4)Kafka、RabbitMQ他们支持主从架构下的读写分离吗?支持Slave Broker的读取吗?为什么呢?
答:支持主从架构,Master主要负责写,Slave主要负责读。
(5)如果支持读写分离的话,会不会出现主从数据不一致的问题?比如有的数据刚刚到Master Broker和部分Slave Broker,但是你刚好是从哪个没有写入数据的Slave Broker去读取了?
答:会有这种情况,假如说一主二从,比如:Master、Slave0、Slave1三台机器,Master收到消息后将消息同步给两台Slave,等到半数Slave发送ACK时,Master就认为写入成功;
假如,Slave1写入成功了,而Slave0写入失败了,此时如果从Slave0上拉取消息就会有问题。关于这个问题,我的想法是,RocketMQ应该有某种机制:从Slave拉取时,会先判断下,该Slave是否为最新数据,如果不是,就从数据最新的Slave中拉取。
或许,也可能是从Master的offset来判断。
(6)在拉取到一批消息处理的时候,应该有哪些要点需要注意的?
答: ①尽量保证消费者和生产者的速率一直;②消费速度太慢,可以使用多线程处理;③多开几个消费者,加入说消费者和生产者的速率为1:4,那么可以使用4个消费者,一个生产者,来达到平衡。
以上是关于22 消费者从Master或Slave拉取消息的策略的主要内容,如果未能解决你的问题,请参考以下文章