大数据之认识MapReduce
Posted Jeff、yuan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据之认识MapReduce相关的知识,希望对你有一定的参考价值。
认识MapReduce
什么是MapReduce?
- MapReduce 既是一个编程模型,又是一个计算框架。
- 模型是对事物共性的抽象,
编程模型就是对编程的共性的抽象, 最重要的共性就是:程序设计时,代码的抽象方式、组织方式或复用方式。大概是了解了 可以理解为MapReduce 就是一套抽象好的两个函数,一个是Map ,一个是Reduce。我们可以再这两个函数里面填充计算的业务逻辑。 - 将MapReduce分为Map和Reduce,Map就是将数据进行切分,Reduce就是将数据进行归类。MapReduce计算框架进行分类聚合,Reduce将分类聚合好的数据进行处理计算。
举个列子 统计海量词汇中重复的单词
-
普通的计算方式,那就运用Map进行统计,使用key放单词,value放count,遇到了就在value +1,但是这对于一个海量的数据,我们不可能全部加到内存中去做,没学过大数据的我想到的就是,分治的思想+ 外排序。这样的话岂不是很慢,一次一次的的从磁盘读取计算,这对于用户来说这也太痛苦了。那就是并发计算,通过多线程计算或者分布式(多进程)计算。
//随便写一个,不全 public static void main(String[] args) { String text = "Hello my brother"; Map<String, Integer> map = new HashMap<>(); String[] s = text.split(" "); for (int i = 0; i < s.length; i++) { map.put(s[i], map.containsKey(s[i])? map.get(s[i]) + 1 : 1); } } -
现在我们看一段MapReduce的计算的代码
public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } }- 我们仔细看下这段代码,其中的核心就是Map函数和reduce函数,map 函数的输入主要是一个 <Key, Value>对,在这个例子里,Value 是要统计的所有文本中的一行数据,Key 在一般计算中都不会用到。
- map 函数的计算过程是,将这行文本中的单词提取出来,针对每个单词输出一个 <word, 1> 这样的 <Key, Value>对。MapReduce 计算框架会将这些<word, 1> 收集起来,将相同的 word 放在一起,形成<word , <1,1,1,1,1,1,1…>>这样的 数据,然后将其输入给 reduce 函数。
我们看下大佬给的计算流程图:
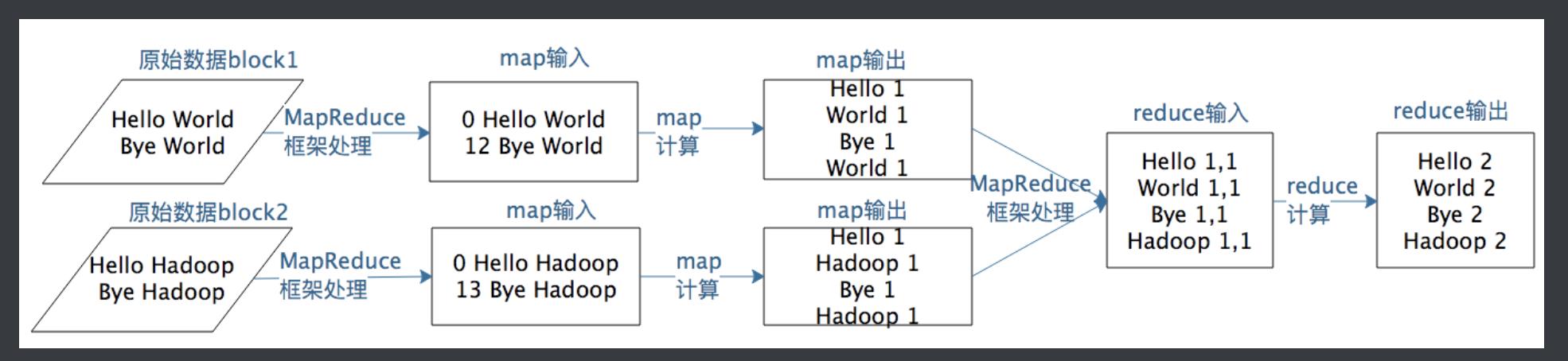
是不是很清楚了,有无数个数据页面,MapReduce框架将这些数据读取为一行一行的(其实这个读取为一行行的,对于一个通用的框架他怎么做能知道是读取为一行一行的呢?看样子也是自定义的),我们定义的Map函数分别放入Hash表中(其实 这块就可以放我们各种的抽象好的算法逻辑,比如树了等等)然后MapReudce框架将这些数据进行聚合起来,reduce对聚合好的数据进行
计算处理reduce输出计算好的数据,也就是<word,count>。
大概是理解了MapReduce,由于还没有真正的使用Mapreduce所以还不能有真正自己的见解。
通过上面的列子我们约就是映射到我们开头所说的,MapReduce 既是一个编程模型,又是一个计算框架。再结合例子:编程模型就是Reduce 和 Map 这两个通用函数。计算框架就是MapReduce的计算框架,我们的原始数据块需要MapReduce框架处理,这块就可以理解为MapReduce是一个框架(这块太抽象了,我在勉为其难的解释)。
Mapreduce的作用
我们只要遵循 MapReduce 编程模型编写业务处理逻辑代码(编写Map和Reduce里面的函数),就可以运行在 Hadoop 分布式集群上,无需关心分布式计算是如何完成的。也就是说,我们只需要关心业务逻辑,不用关心系统调用与运行环境,这和我们目前的主流开发方式是一致的。
其他人对MapReduce的理解
-
其实,MapReduce中的map在做select/scan,shuffle就是在做groupby,reduce在做aggregation。另外,reduce也用于实现join。
-
MapReduce 既是一个编程模型,又是一个计算框架。也就是说,开发人员必须基于 MapReduce 编程模型进行编程开发,然后将程序通过 MapReduce 计算框架分发到 Hadoop 集群中运行。我们先看一下作为编程模型的 MapReduce。
-
MapReduce 的编程模型,类似于函数式编程,按照这个模型写出的代码运行在hadoop集群,可以实现分布式计算的效果
大佬的思考: 模型是人们对一类事物的概括与抽象,可以帮助我们更好地理解事物的本质,更方便地解决问题。比如,数学公式是我们对物理与数学规律的抽象,地图和沙盘是我们对地理空间的抽象,软件架构图是软件工程师对软件系统的抽象。通过抽象,我们更容易把握事物的内在规律,而不是被纷繁复杂的事物表象所迷惑,更进一步深刻地认识这个世界。通过抽象,伽利略发现力是改变物体运动的原因,而不是使物体运动的原因,为全人类打开了现代科学的大门。这些年,我自己认识了很多优秀的人,他们各有所长、各有特点,但是无一例外都有个共同的特征,就是对事物的洞察力。他们能够穿透事物的层层迷雾,直指问题的核心和要害,不会犹豫和迷茫,轻松出手就搞定了其他人看起来无比艰难的事情。有时候光是看他们做事就能感受到一种美感,让人意醉神迷。这种洞察力就是来源于他们对事物的抽象能力,虽然我不知道这种能力缘何而来,但是见识了这种能力以后,我也非常渴望拥有对事物的抽象能力。所以在遇到问题的时候,我就会停下来思考:这个问题为什么会出现,它揭示出来背后的规律是什么,我应该如何做。甚至有时候会把这些优秀的人带入进思考:如果是戴老师、如果是潘大侠,他会如何看待、如何解决这个问题。通过这种不断地训练,虽然和那些最优秀的人相比还是有巨大的差距,但是仍然能够感受到自己的进步,这些小小的进步也会让自己产生大大的快乐,一种不荒废光阴、没有虚度此生的感觉。我希望你也能够不断训练自己,遇到问题的时候,停下来思考一下:这些现象背后的规律是什么。有时候并不需要多么艰深的思考,仅仅就是停一下,就会让你察觉到以前不曾注意到的一些情况,进而发现事物的深层规律。这就是洞察力。
我的思考: 能把一个复杂东西,进行抽象整理为一个通用的方法,函数或者显示的一个工具,其原因本质是首先你对这个事物是真的熟悉。能对其进行分层和归类(可以联想我们对业务逻辑的分层,包括DDD思想中的领域模型的创建,也就是一种抽象),我个人认为一切事物都有相同之处,这个相同之处也许在一个事物的最底层。也就想像我们java中的Object 在java中Object 就是一切事物的抽像。(瞎扯:其实我一直都想给Object对象中加一个函数叫verify()自我检验,虽然说只有有思想的事物才能自我校验,但是代码是人写的,我们赋予给他思想,可以让他自己校验,还有一方面是 我们终会有很多的校验逻辑,很烦,其实真确来说是再DTO有一个base inteface 又一个verify方法所有DTOresult 实现它都得拿到他的第一件事就是verify)。所以个人认为,提高抽象能力,也就是不断去了解和熟悉,提高对事物的认知,然后总结和思考其中的相似之处。最后在某个层面进行抽象。总而言之,一切的来源都是思考,深度思考。
以上是关于大数据之认识MapReduce的主要内容,如果未能解决你的问题,请参考以下文章