压测引发的思考——高并发用同步还是异步好?
Posted Jeff、yuan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了压测引发的思考——高并发用同步还是异步好?相关的知识,希望对你有一定的参考价值。
高并发用同步好还是异步好?
背景
最近616大促,公司的服务需要进行压力测试,使用了公司自己的压测平台。对生产机器进行了摘流量压测。由于服务都是查询的接口,也算是很好压测的。这篇文章大概描述压测过程过程,主要是压测出的问题的解决以及对ForkJoinPool学习和了解。
(标题党???????)
为什么要进行压测
- 电商促销 ,这个肯定要对现有服务的流量预估,峰值可以抗到多少QPS 。是否需要在促销前加机器,是否需要加机器内存等。
- 是否当有高并发的时候会有明显的性能bug问题,在促销前进行性能优化,不在物理层面优化 ,在软件(代码)层面优化的空间
如何进行压测
- 因为是公司内存的压测平台,相对还是比较自动化的
- 大概描述一下压测的流程:
- 选定压测接口
- 抓取线上流量。(随机抓取)
- 选择压力机器,选择目标机器
- 创建测试任务
- 摘目标压测机器的线上流量,不能影响线上的用户(很重要 )
- 参数设定,根据以往机器是的性能表现,设置开始并发量,以及并发持续的时间,和增长速度。
压测结果(这里的QPS数值是非真实的数值)
- 单台机器峰值QPS在3W左右,cpu使用率是75左右。出现大量的超时(其实QP1000,10%的逐渐增加)
- 二次结果:初始值给3000QPS直接给爆掉了。线程被用尽,触发了框架中的ThreadDump
- [] [INFO] [ThreadDumpThread-0] [ThreadDumpper] >>> [666-INFO] msg= “Osp-Common-Business-Thread2” Id=2wqw302 WAITING at sun.misc.Unsafe.park(Native Method) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175) at java.util.concurrent.CompletableFuture$Signaller.block(CompletableFuture.java:1693) at java.util.concurrent.ForkJoinPool.managedBlock(ForkJoinPool.java:3323) at java.util.concurrent.CompletableFuture.waitingGet(CompletableFuture.java:1729) at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1895) at com.vip.sc.ai.ap.cache.local.CaffeineCacheService.getSync(CaffeineCacheService.java:148) at
结果分析
- 首先是符合我们的压测目标
- 但是出现了QPS突然猛增,出现机器线程被打爆的情况.
问题排查
-
由于框架内部会直接触发打出了线程栈信息,所以很快就排查出来了
-
其中有出现park自旋。用于挂起当前线程,如果许可可用,会立马返回,并消费掉许可。(ok那也就是有很多线程多挂起了,导致整个项目线程耗尽)
-
由于我们使用了CaffeineCache中的异步获取内存中的数据,而这个数据使用的是ComplatableFuture来实现异步的。并且在我们使用的异步的时候没有指定适合我们并发场景的线程池。
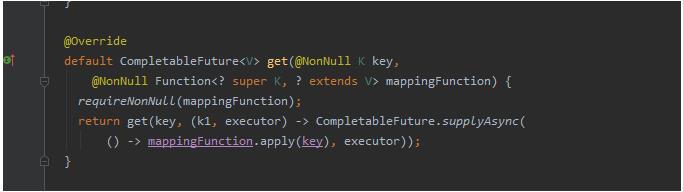
-
其实这也就引出了另一个问题那就是使用CompletableFuture异步的实现,还有在CaffeineCache中的使用,从上面的源码来看,我们的在传进来的Function并没有指定对应的线程池,所以就选用了默认线程池,是什么线程池呢,ForkJoinPool( @author Doug Lea)

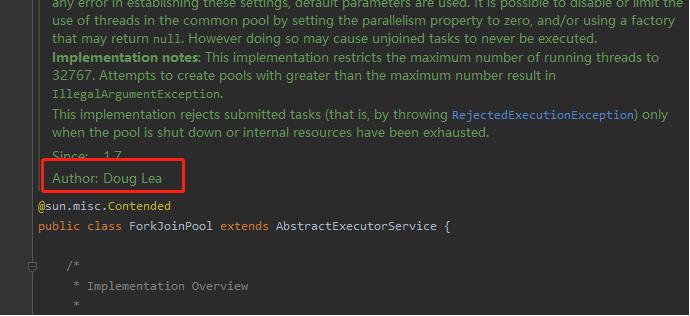
- 那我们就得看看这个线程池是如何工作的呢? 和我们平时使用的线程池的区别在哪里呢? 尤其是commonPool
/**
* 返回公共池实例。这个池是静态构建的;它的运行状态不受尝试 {@link shutdown} 或 {@link shutdownNow} 的
* 影响。但是,此池和任何正在进行的处理都会在程序 {@link Systemexit} 后自动终止。
* 任何依赖异步任务处理在程序终
* 止之前完成的程序都应该在退出之前调用 {@code commonPool().}
*{@link awaitQuiescence awaitQuiescence}。 @return 公共池实例 @since 1.8
*/
public static ForkJoinPool commonPool() {
// assert common != null : "static init error";
return common;
}
- 官方文档:
-
ForkJoinPool与其他类型的ExecutorService主要区别在于采用 工作窃取:池中的所有线程都尝试查找并执行提交给池和/或由其他活动任务创建的任务(如果不存在,则最终阻塞等待工作)。当大多数任务产生其他子任务时(大多数ForkJoinTasks 也是如此),以及当许多小任务从外部客户端提交到池时,这可以实现高效处理。尤其是在构造函数中将 asyncMode设置为 true 时,ForkJoinPools 也可能适用于从未加入的事件样式任务。 -
静态
commonPool()是可用的并且适用于大多数应用程序。公共池由未明确提交到指定池的任何 ForkJoinTask 使用。使用公共池通常会减少资源使用(其线程在不使用期间缓慢回收,并在后续使用时恢复)。 -
默认线程池的使用
/** * Creates and returns the common pool, respecting user settings * specified via system properties. */ private static ForkJoinPool makeCommonPool() { final ForkJoinWorkerThreadFactory commonPoolForkJoinWorkerThreadFactory = new CommonPoolForkJoinWorkerThreadFactory(); int parallelism = -1; ForkJoinWorkerThreadFactory factory = null; UncaughtExceptionHandler handler = null; try { // ignore exceptions in accessing/parsing properties String pp = System.getProperty ("java.util.concurrent.ForkJoinPool.common.parallelism"); String fp = System.getProperty ("java.util.concurrent.ForkJoinPool.common.threadFactory"); String hp = System.getProperty ("java.util.concurrent.ForkJoinPool.common.exceptionHandler"); if (pp != null) parallelism = Integer.parseInt(pp); if (fp != null) factory = ((ForkJoinWorkerThreadFactory)ClassLoader. getSystemClassLoader().loadClass(fp).newInstance()); if (hp != null) handler = ((UncaughtExceptionHandler)ClassLoader. getSystemClassLoader().loadClass(hp).newInstance()); } catch (Exception ignore) { } if (factory == null) { if (System.getSecurityManager() == null) factory = commonPoolForkJoinWorkerThreadFactory; else // use security-managed default factory = new InnocuousForkJoinWorkerThreadFactory(); } if (parallelism < 0 && // default 1 less than #cores (parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0) parallelism = 1; if (parallelism > MAX_CAP) parallelism = MAX_CAP; return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE, "ForkJoinPool.commonPool-worker-"); }
- 这是上面参数设置对应的构造函数
/**
* Creates a {@code ForkJoinPool} with the given parameters, without
* any security checks or parameter validation. Invoked directly by
* makeCommonPool.
*/
private ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
int mode,
String workerNamePrefix) {
this.workerNamePrefix = workerNamePrefix;
this.factory = factory;
this.ueh = handler;
this.config = (parallelism & SMASK) | mode;
long np = (long)(-parallelism); // offset ctl counts
this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);
}
- 参数解读
-
parallelism:并行度( the parallelism level),默认情况下跟我们机器的cpu个数保持一致,使用 Runtime.getRuntime().availableProcessors()可以得到我们机器运行时可用的CPU个数
-
factory:创建新线程的工厂( the factory for creating new threads)。默认情况下使用ForkJoinWorkerThreadFactory defaultForkJoinWorkerThreadFactory。
-
handler:线程异常情况下的处理器,该处理器在线程执行任务时由于某些无法预料到的错误而导致任务线程中断时进行一些处理,默认情况为null。
-
asyncMode:这个参数要注意,在ForkJoinPool中,每一个工作线程都有一个独立的任务队列,asyncMode表示工作线程内的任务队列是采用何种方式进行调度,可以是先进先出FIFO,也可以是后进先出LIFO。如果为true,则线程池中的工作线程则使用先进先出方式进行任务调度,默认情况下是false。
ForkJoinPool 有一个 Async Mode ,效果是工作线程在处理本地任务时也使用 FIFO 顺序**。这种模式下的 ForkJoinPool 更接近于是一个消息队列,而不是用来处理递归式的任务。**(无边界队列)
-
看了上面这么多的参数解读,我们并没有看到他有像我们常使用的线程池中的拒绝策略,还有最大线程数,这些指标。他就只是有一个并发度,也就是创建的最大线程数和核心线程数是相等的,那他是如何耗尽应用的线程的呢??
-
首先我们发起的异步调用,没有问题,这个时候主线程会直接个get ,这个就有问题了呀。因为主线get不到拿不到结果,核心线程也就那几个,很多都进入和ForkJoinPool的无界队列,主线程直接通过park自旋挂起了,当还有流量继续进来的时候,也是异步发起获取内存中的数据,但是之前还有任务没有执行完继续等,这玩意就GG了。直接打爆了。太刺激了!!
最终解决方案
- 简单粗暴: 异步改同步。这也就契合我们文章的主题了。高并发我们到底用同步还是异步呀。乱了,有点乱了。稳住,我们慢慢思考分析。同步一条路走下去,因为我们大都是内存操作,所以整个流程都很快。再结合上面出问题的地方是首先用了异步(起线程池,)再着对主线立马进行get获取这就是致命的地方。获取的时候会通过线程挂起等待的。所以没有必要使用再起线程池,最终还是会阻塞等待异步结果的。
- 设置线程池,想了想这玩意还真没办法搞,真的就没必要搞,因为主线程会阻塞等待获取结果的。
- 高并发使用异步还是同步,这个真的需要具体问题具体对待了。高并发场景下起线程的异步千万不敢乱用。
参考
https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ForkJoinPool.html#commonPool–
https://juejin.cn/post/6844903729380982797
https://www.cnblogs.com/minikobe/p/11930282.html
以上是关于压测引发的思考——高并发用同步还是异步好?的主要内容,如果未能解决你的问题,请参考以下文章
高并发由InterruptedException异常引发的思考
高并发由InterruptedException异常引发的思考
高并发由InterruptedException异常引发的思考