每个数据科学家都应该知道的十大终端命令
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了每个数据科学家都应该知道的十大终端命令相关的知识,希望对你有一定的参考价值。
IT界的每个人都应该知道终端(Terminal)的基本知识,数据科学家也不例外。有时,终端是你的全部,尤其是在将模型和数据管道部署到远程机器时。
今天我们将介绍一些基本的数据收集、探索和聚合—所有这些都是通过shell完成的。如果你使用的是Linux或Mac,那么接下来就不会有任何问题,但是Windows用户应该在继续之前下载一个终端仿真器。
让我们开始吧!
1、wget
wget实用程序用于从远程服务器下载文件。你可以用它来下载数据集,只要你知道网址,可以使用wget命令下载它,我以如下url为例:
https://raw.githubusercontent.com/jbrownlee/Datasets/master/airline-passengers.csv
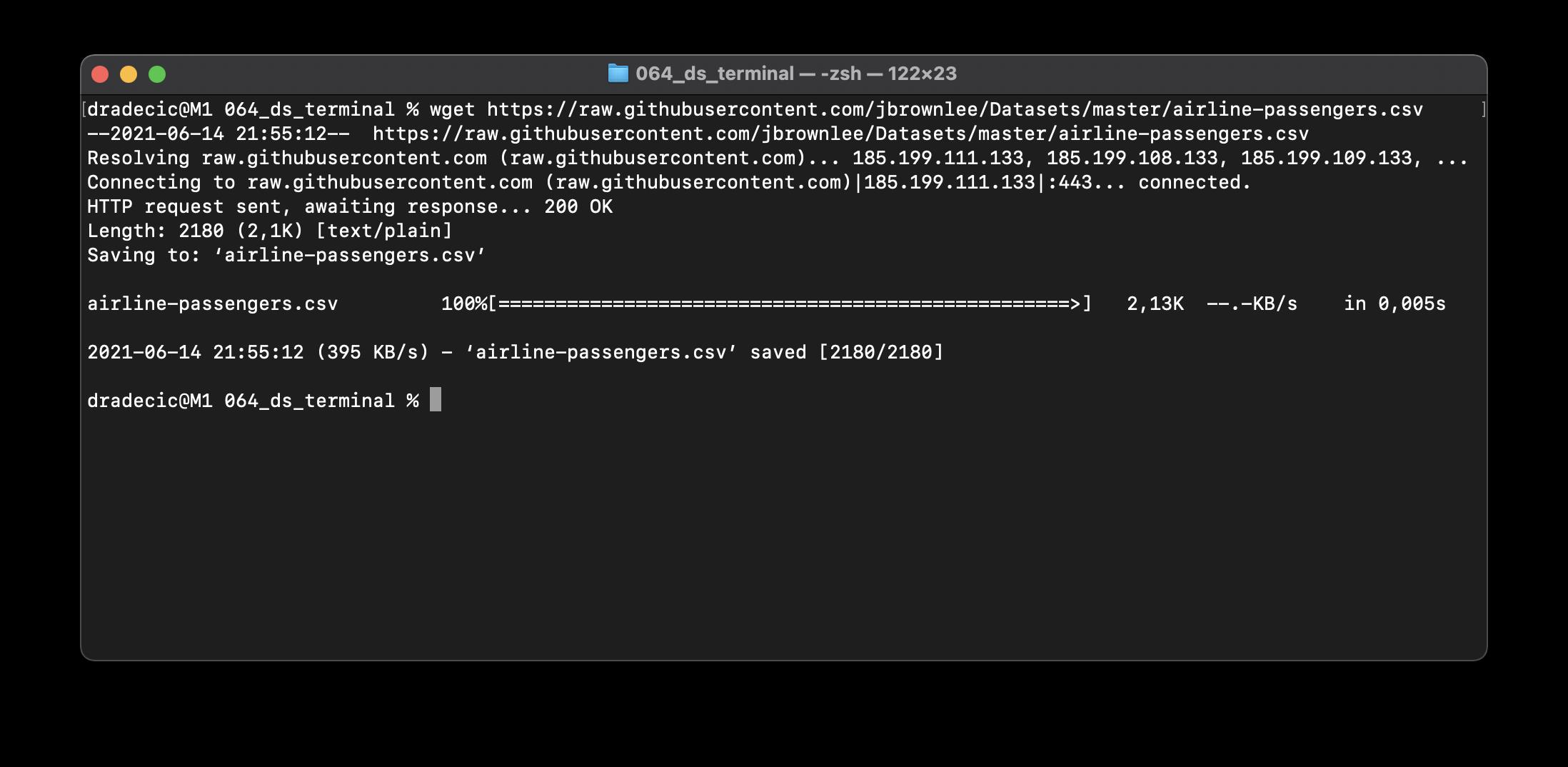
如果你在Mac上,默认情况下wget不可用,请从终端执行brew install wget进行安装。数据集现在已经下载,让我们继续一些基本的探索。
2、head
如果你是Python用户,这会让您感到熟悉。否则,head命令用于打印文件的前N行。默认打印10行:

如果你想要一个不同的数字,比如说3,你可以使用-n参数。完整的命令是:
head -n 3 airline-passengers.csv
3、tail
tail命令与head命令非常相似,但它将打印最后N行。默认打印10行:
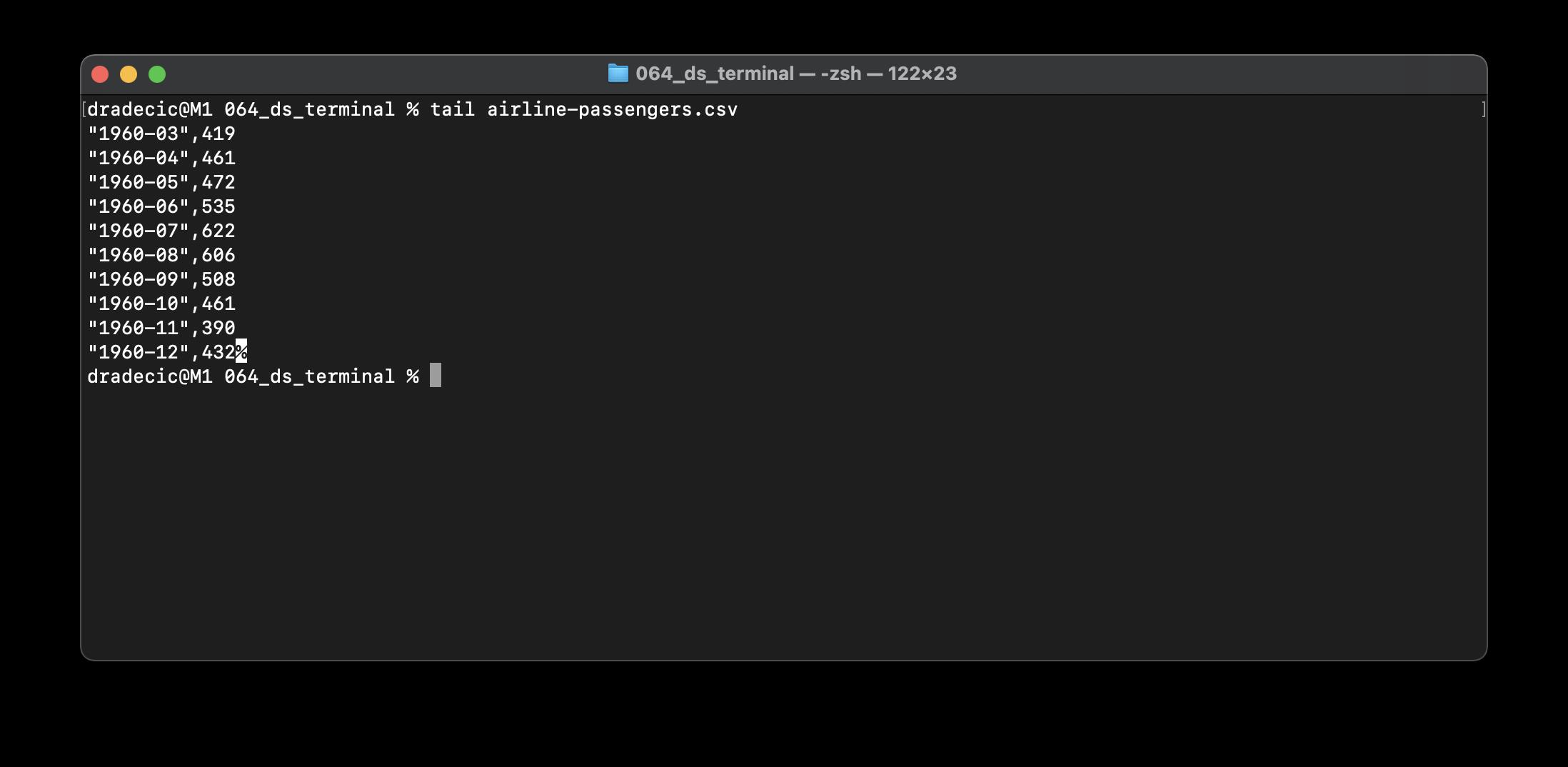
与head一样,还可以使用-n参数指定要打印的行数。我们现在已经介绍了基础知识,所以让我们继续讲一些更有趣的内容。
4、wc
有时你想知道文件中有多少个数据点。不需要打开它并手动滚动到底部。一个简单的命令可以为您节省一些时间:
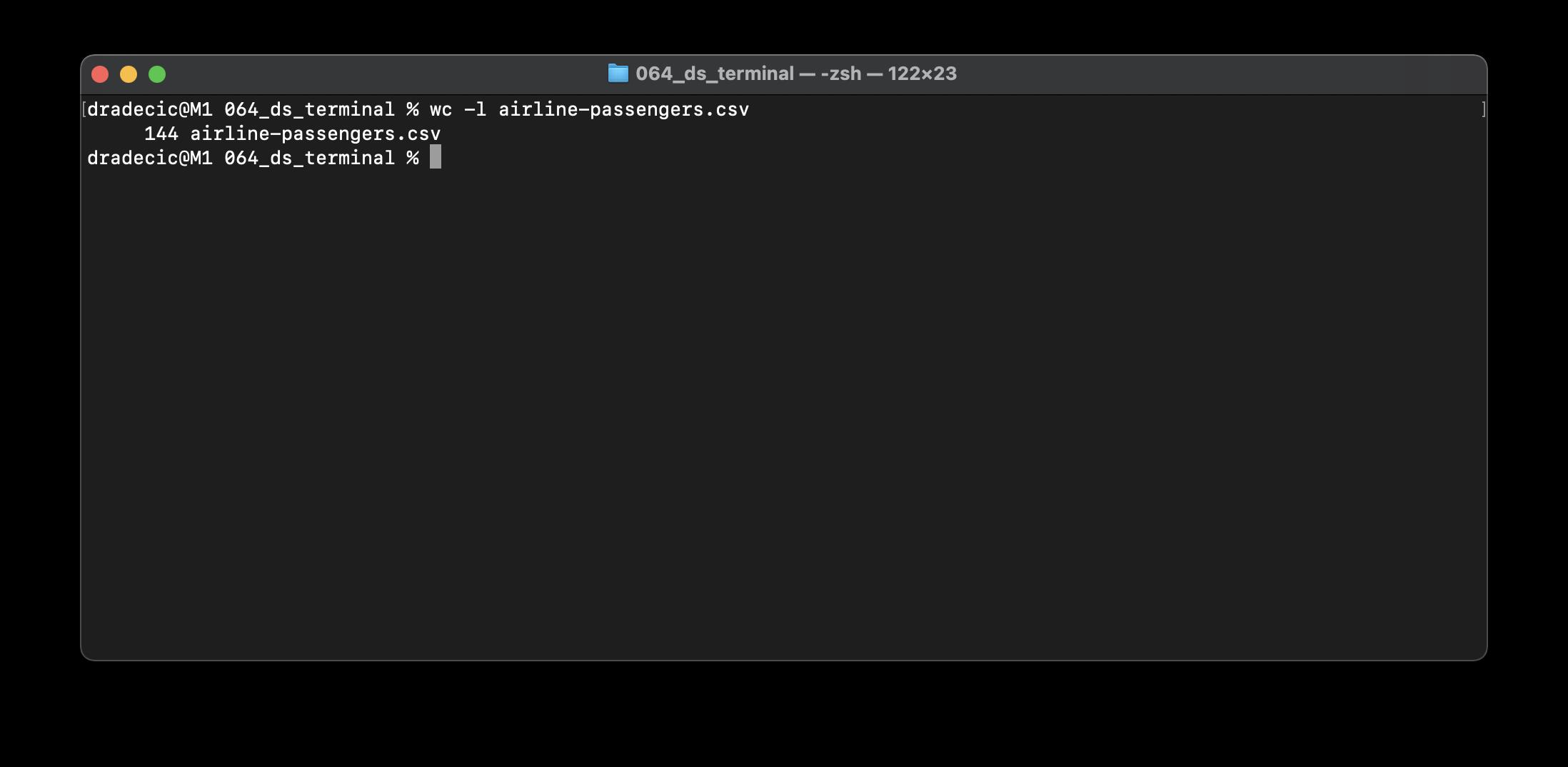
总之,airline-passengers.csv文件包含144行。
5、grep
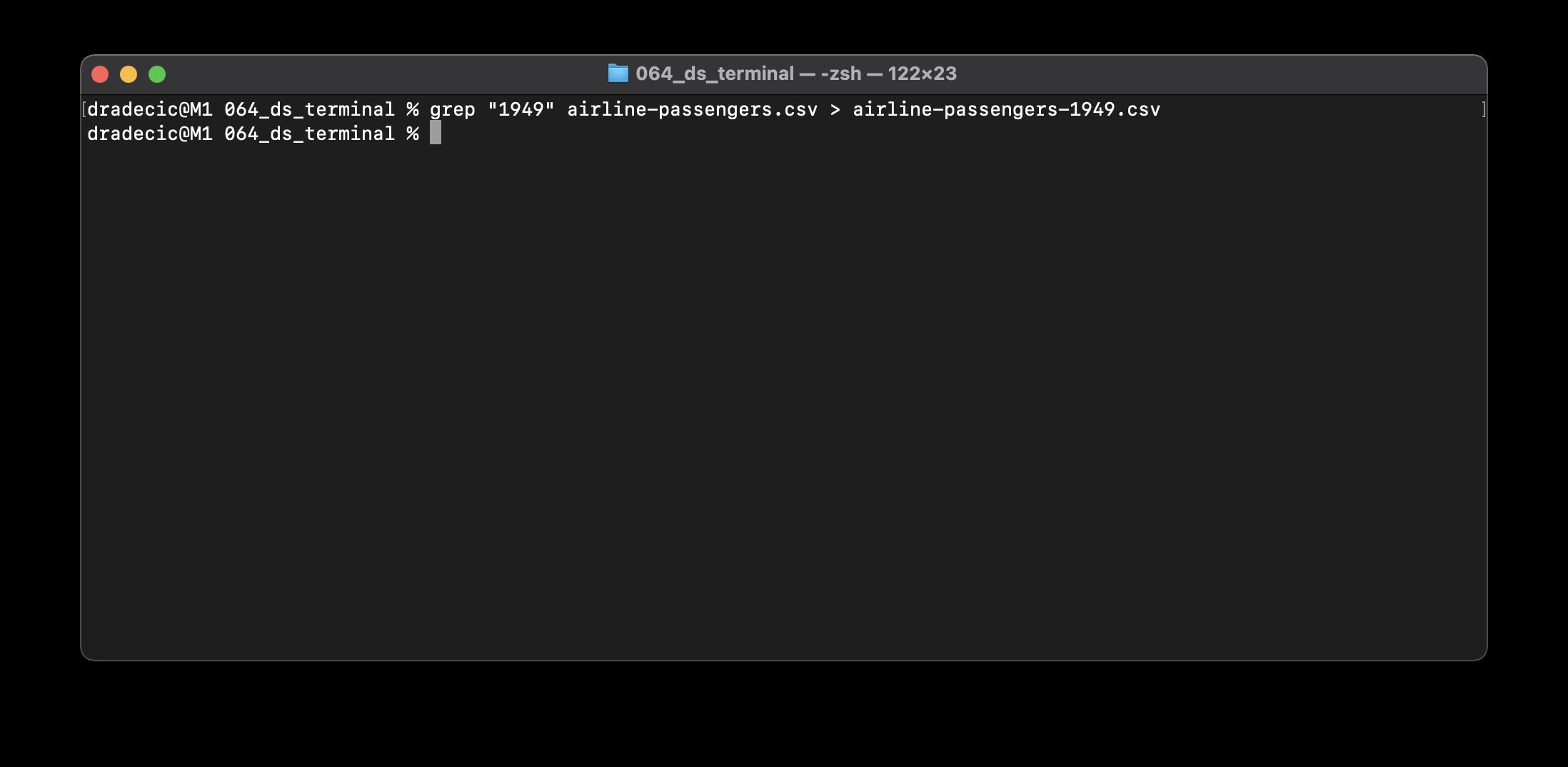
此命令用于处理文本,可以匹配字符串和正则表达式。我们将使用它只提取包含字符串“1949”的行。这是一个简单的数据集,所以我们不会有任何问题。默认情况下,grep命令将打印结果,但我们可以将其保存到另一个CSV文件:
6、cat
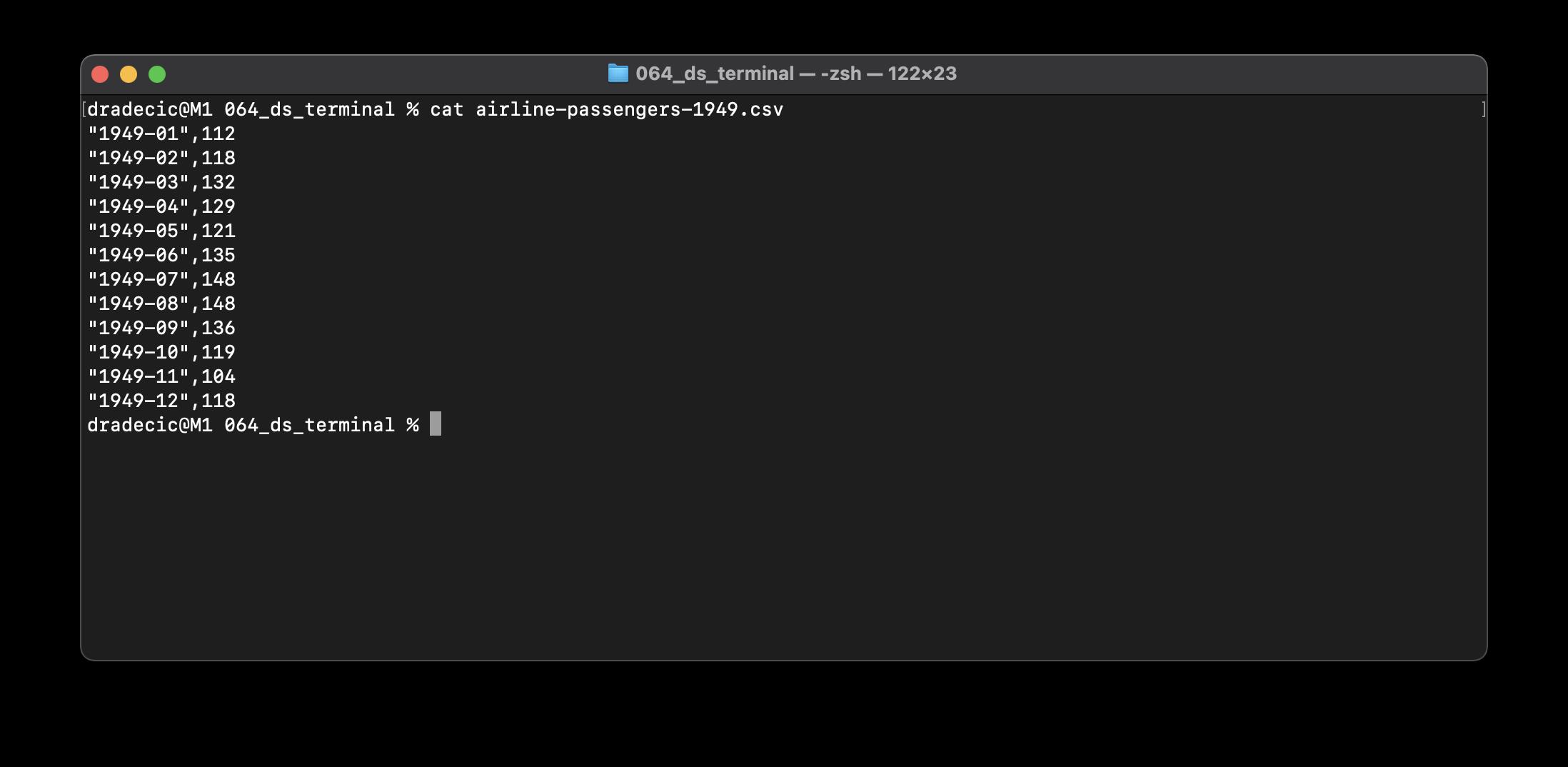
为了验证上一个操作是否成功,我们可以使用cat命令。它用于将整个文件打印到shell。你也可以用它来组合文件和更多,但这是另一个时间的主题。
现在,让我们打印整个文件。数据是按月汇总的,因此总共应该有12行:
7、find
你可以使用find命令搜索文件和文件夹。例如,执行以下命令将当前目录(由点指定)中的所有CSV文件打印到shell:
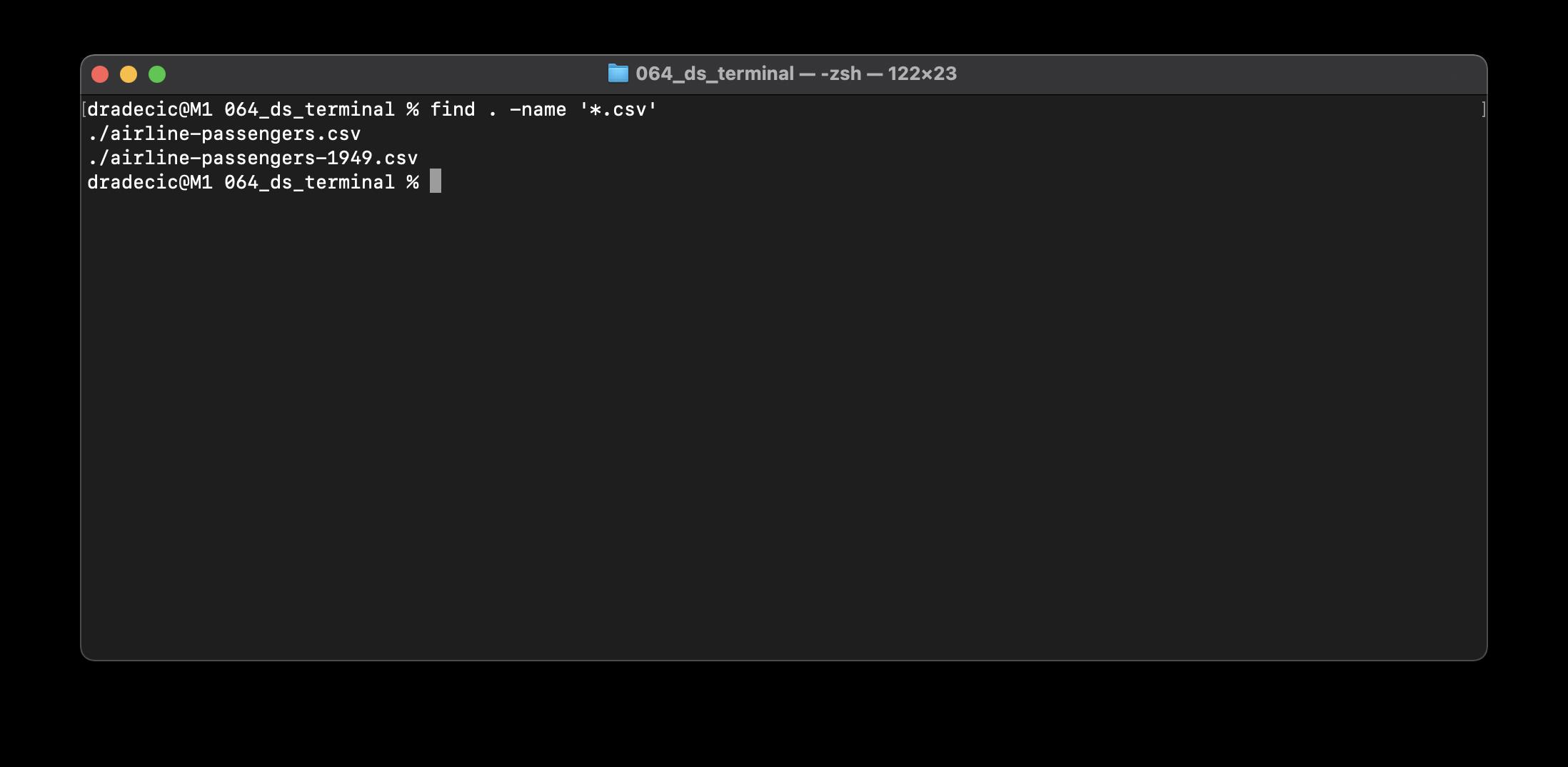
星号(*)表示文件名无关紧要,只要它以“.csv”结尾。
8、sort
顾名思义,sort命令可用于按某种标准对文件内容进行排序。例如,以下命令按乘客数量升序对数据集进行排序:
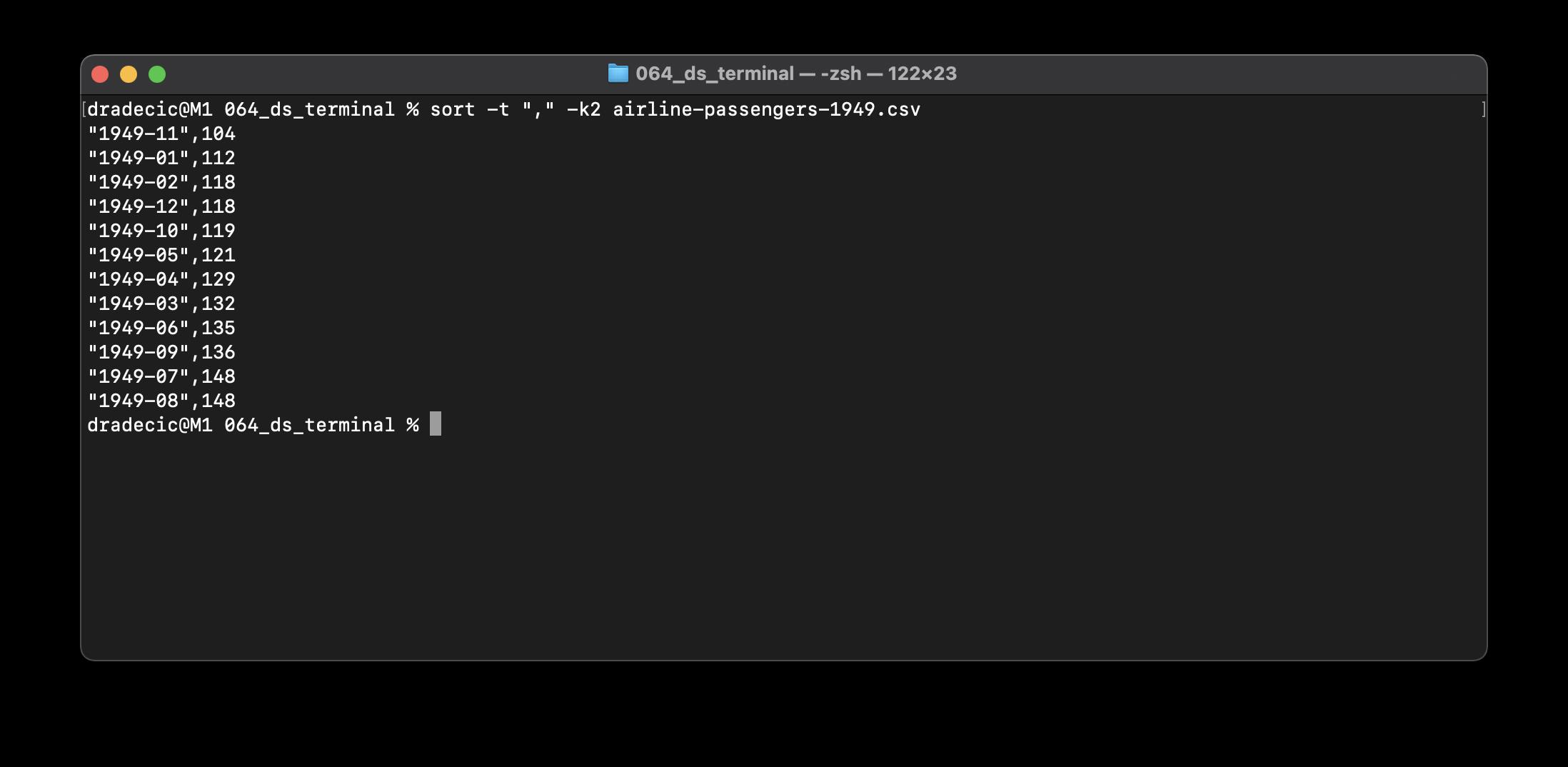
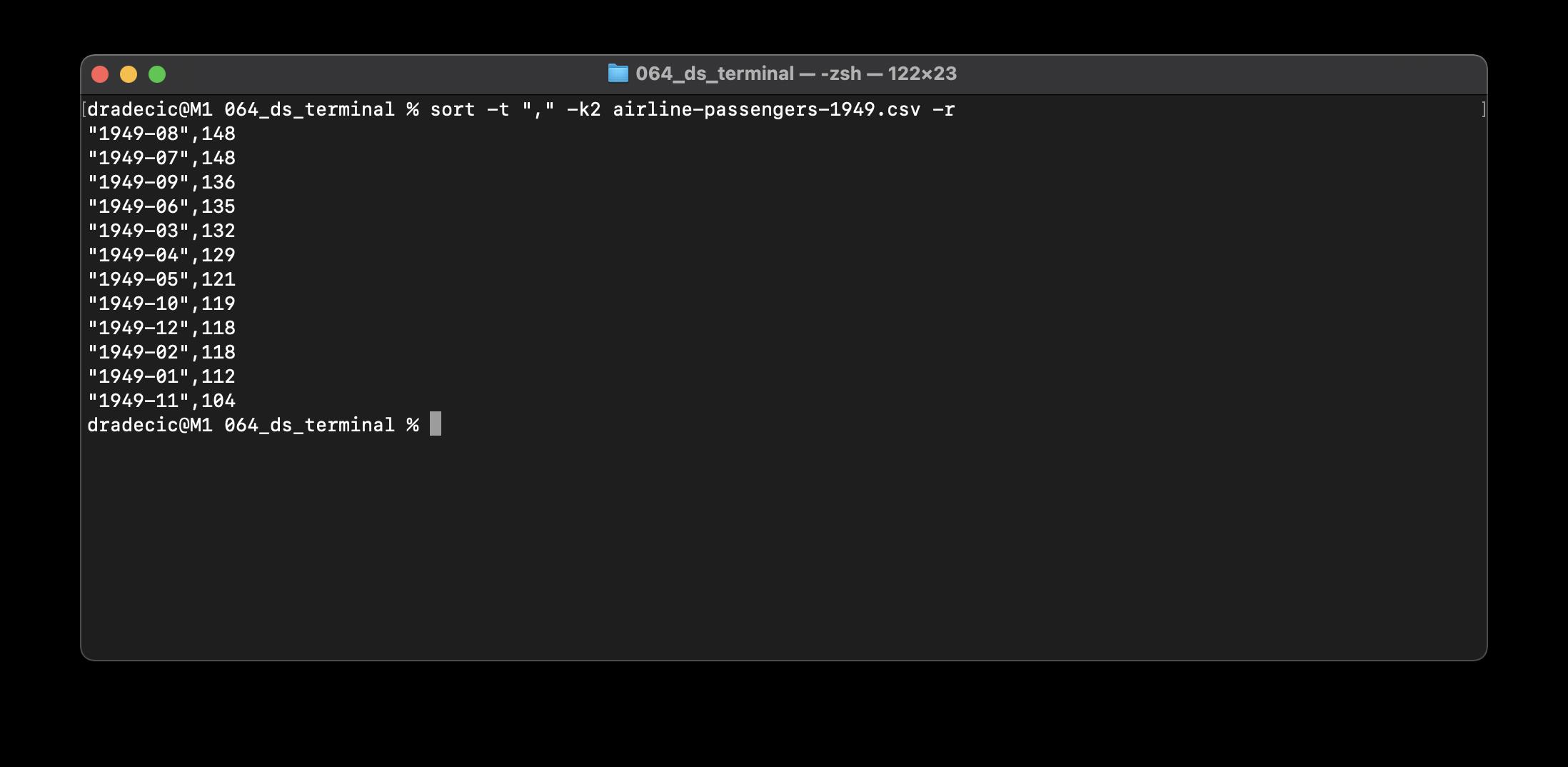
-k2参数指定对第二列进行排序。如果要按降序对文件排序,可以指定一个附加的-r参数:
9、nano
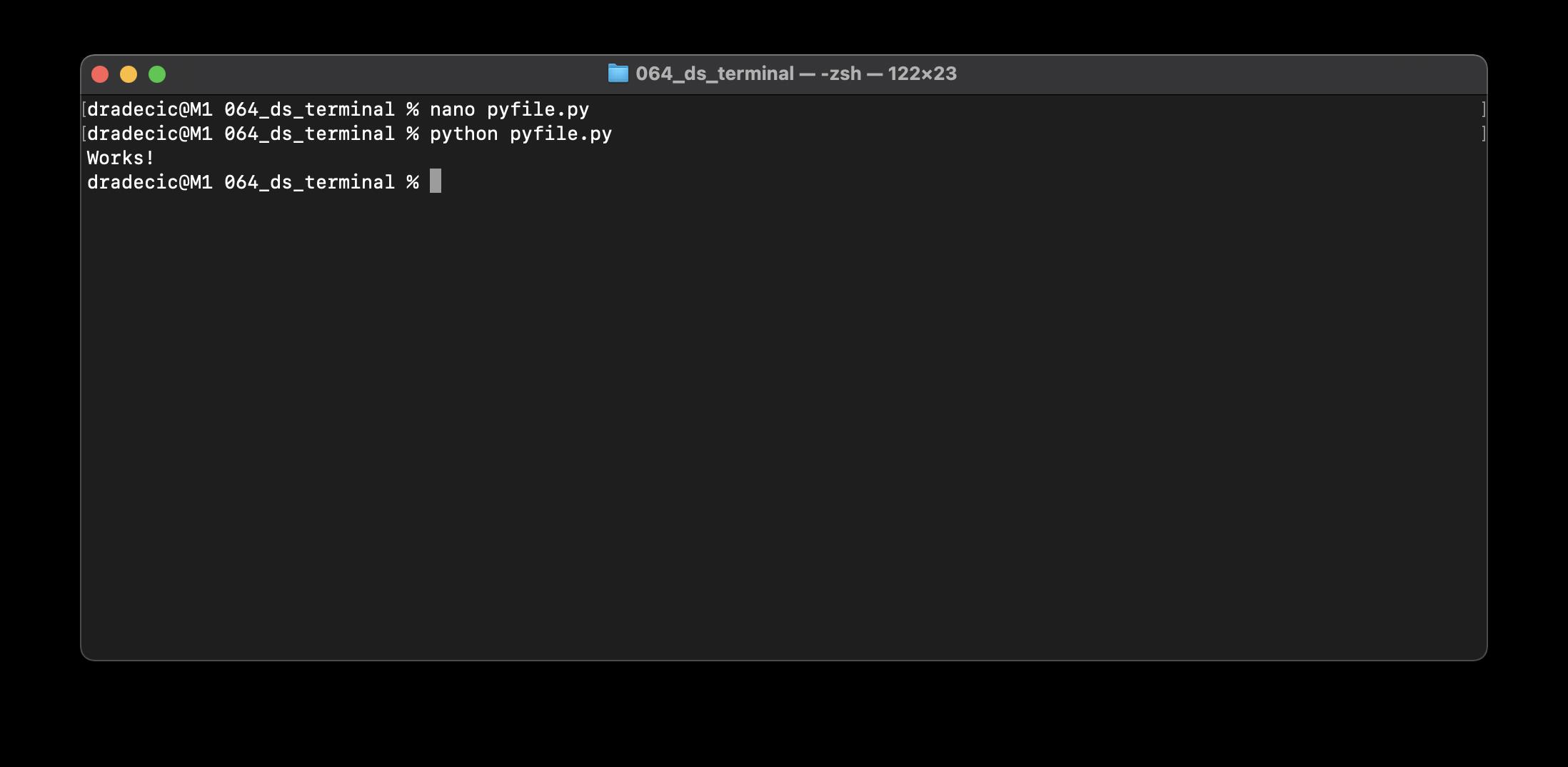
虽然技术上不是shell命令,但执行它会打开Nano编辑器。下面是如何创建Python文件:
nano pyfile.py
在这里,让我们编写一些简单的Python代码:

您可以在编辑器中编写任何Python代码,并进行对于简单终端命令来说过于复杂的分析。完成后,可以运行Python文件:
10、Variables
让我们用Variables来结束今天的文章。例如,当文件路径变长时,或者您需要多次使用它们时,它们可以派上用场。
下面是如何声明两个字符串变量并使用mv命令将airline-passengers-1949.csv文件重命名为new.csv:
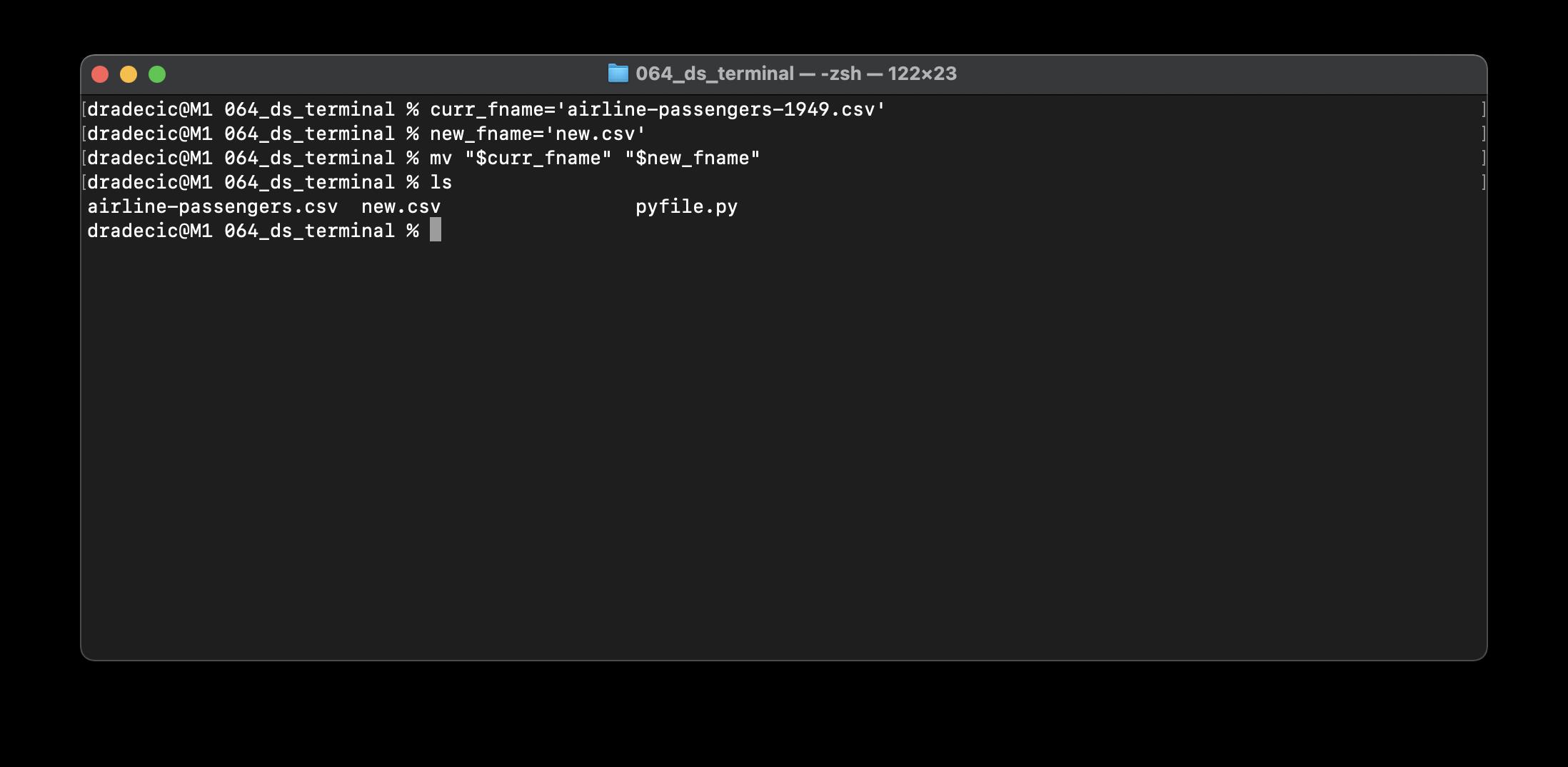
ls命令用于列出目录中的文件,如我们所见,重命名操作成功。
技术交流
欢迎转载、收藏本文,码字不易,有所收获点赞支持一下!
为方便进行学习交流,本号开通了技术交流群,添加方式如下:
直接添加小助手微信号:pythoner666,备注:CSDN+机器学习,或者按照如下方式(发送至微信,识别即可)添加均可!

以上是关于每个数据科学家都应该知道的十大终端命令的主要内容,如果未能解决你的问题,请参考以下文章