效率倍增!12 个必知必会的 Python 数据处理技巧!
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了效率倍增!12 个必知必会的 Python 数据处理技巧!相关的知识,希望对你有一定的参考价值。
目前 Python 已经成为最受欢迎的程序设计语言之一。由于 Python 语言的简洁性、易读性以及可扩展性,用 Python 做科学计算的研究机构日益增多,很多知名大学已经采用 Python 来教授程序设计课程。
在日常工作中一些比较繁琐的数据处理逻辑,我们在 Python 中总能找到一些数据处理技巧,这些技巧节省我们大量的宝贵的时间并使自己的工作更简单。在这篇文章中,我将介绍我使用过的 23 个数据处理技巧,如果对你有所帮助,欢迎分享、点赞支持。
1、Pandas Cut and qcut
在pandas上,Cut命令可以创建等间距的箱子,但每个箱子中的采样频率不相等,qcut命令可以创建大小不等的箱子,但每个箱子中的采样频率相同,这两个函数在做特征工程分箱操作时是非常棒的技巧。
导入必要的库和数据:
import pandas as pd
import numpy as np
df_rollno = pd.DataFrame({'Roll No': np.random.randint(20, 55, 10)})
df_rollno
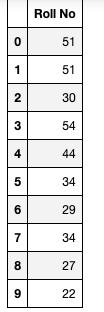
使用 cut 函数:
df_rollno['roll_no_bins'] = pd.cut(x=df_rollno['Roll No'], bins=[20, 40, 50, 60])
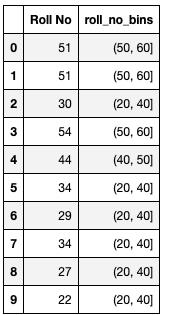
使用 qcut 函数:
pd.qcut(df_rollno['Roll No'], q=6)

2、并行操作
pandarallel 用于将计算分布到计算机上所有可用的CPU上,以显著提高速度。
安装 pandarallel
pip install pandarallel
导入必要的库
%load_ext autoreload
%autoreload 2
import pandas as pd
import time
from pandarallel import pandarallel
import math
import numpy as np
import random
from tqdm._tqdm_notebook import tqdm_notebook
tqdm_notebook.pandas()
初始化pandarallel
pandarallel.initialize(progress_bar=True)

df = pd.DataFrame({
'A' : [random.randint(8,15) for i in range(1,100000) ],
'B' : [random.randint(10,20) for i in range(1,100000) ]
})
def trigono(x):
return math.sin(x.A**2) + math.sin(x.B**2) + math.tan(x.A**2)
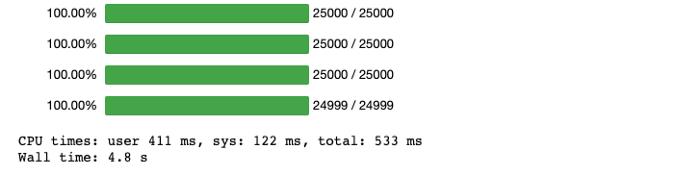
没有并行化
%%time
first = df.progress_apply(trigono, axis=1)

没有并行化
%%time
first_parallel = df.parallel_apply(trigono, axis=1)
3、将列表中列表转换为列表
导入必要库
import itertools
建立一个列表
nested_list = [['Naina'], ['Alex', 'Rhody'], ['Sharron', 'Avarto', 'Grace']]
只需一步即可完成,转换如下
converted_list = list(itertools.chain.from_iterable(nested_list))
print(converted_list)
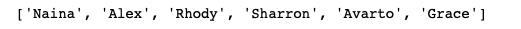
4、美化Dict
创建词典
l_dict = {'Student_ID': 4,'Student_name' : 'Naina', 'Class_Name': '12th' ,'Student_marks' : {'maths' : 92,
'science' : 95,
'computer science' : 100,
'English' : 91}
}
使用pprint美化字典
import pprint
pprint.pprint(l_dict)

5、反转字典
创建字典
l_dict = {'Person_Name':'Naina',
'Age' : 27,
'Profession' : 'Software Engineer'
}
反转字典
invert_dict = {values:keys for keys,values in l_dict.items()}
invert_dict

6、从文本中删除表情符号
Emoji_text = 'For example, 🤓🏃🏢 could mean “Iam running to work.”'
final_text=Emoji_text.encode('ascii', 'ignore').decode('ascii')
print("Raw tweet with Emoji:",Emoji_text)
print("Final tweet withput Emoji:",final_text)

7、Pandas Profiling
Profiling 用于从数据帧或数据表生成概要报告。
安装配置文件:
pip install pandas-profiling
生成报告
import pandas as pd
import pandas_profiling
Youtube_data = pd.read_csv('/Users/priyeshkucchu/Desktop/USvideos.csv')
profiling_report = pandas_profiling.ProfileReport(Youtube_data)
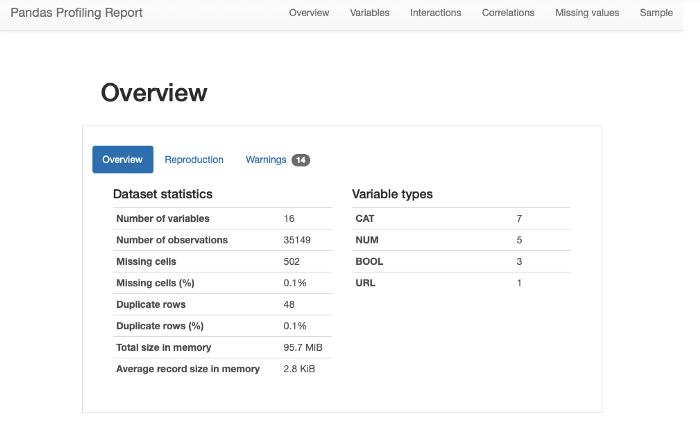

8、日期分析器
解析日期
import datetime
import dateutil.parser
input_date = '04th Dec 2020'
parsed_date = dateutil.parser.parse(input_date)
指定格式的输出日期:
op_date = datetime.datetime.strftime(parsed_date, '%Y-%m-%d')
print(op_date)
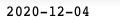
9、Unique
import pandas as pd
import numpy as np
crime_data = pd.read_csv("/Users/priyeshkucchu/Desktop/crime.csv",\\ engine='python')
crime_data.head()

在“DISTRICT”列中显示唯一值:
crime_data["DISTRICT"].unique()

10、从文本中提取电子邮件
import re
Enquiries_text = 'For any enquiries or feedback related to our product,\\service, marketing promotions or other general support \\ matters. contactus@samsung.com’'
使用正则表达式提取电子邮件:
re.findall(r"([\\w.-]+@[\\w.-]+)", Enquiries_text)

11、Crosstab
在Pandas中,此函数用于计算两个或多个因子的简单交叉表。
导入必要的库:
import pandas as pd
data = pd.read_csv('/Users/priyeshkucchu/Desktop/loan_train.csv',\\ index_col = 'Loan_ID')
pd.crosstab(data["Credit_History"],data["Self_Employed"],margins=True, normalize = False)
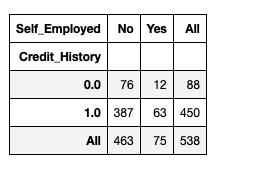
12、pivot table
在Pandas中,pivot table函数将数据帧作为输入,并执行分组操作,以提供数据的多维摘要。
数据展示
import pandas as pd
import numpy as np
loan = pd.read_csv('/Users/priyeshkucchu/Desktop/loan_train.csv', index_col = 'Loan_ID')
loan.head()
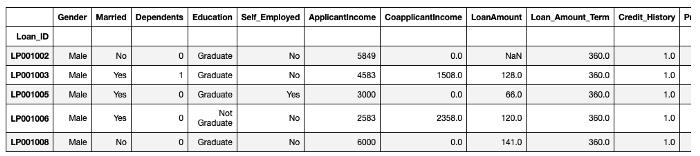
数据透视表
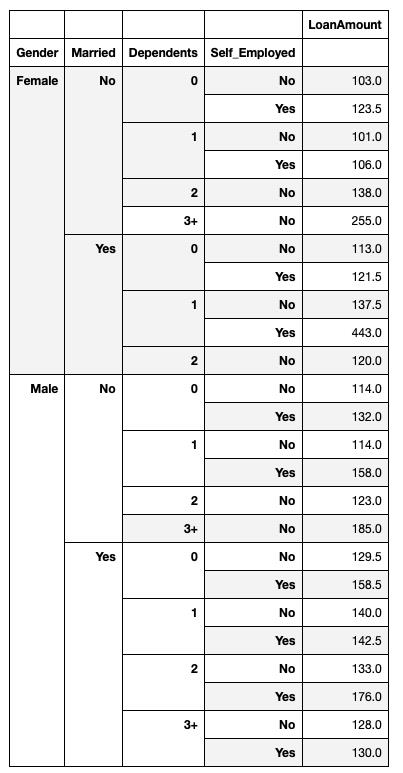
pivot = loan.pivot_table(values = ['LoanAmount'],index = ['Gender', 'Married','Dependents', 'Self_Employed'], aggfunc = np.median)
技术交流
欢迎转载、收藏本文,码字不易,有所收获点赞支持一下!
为方便进行学习交流,本号开通了技术交流群,添加方式如下:
直接添加小助手微信号:pythoner666,备注:CSDN+机器学习,或者按照如下方式(发送至微信,识别即可)添加均可!

以上是关于效率倍增!12 个必知必会的 Python 数据处理技巧!的主要内容,如果未能解决你的问题,请参考以下文章