太香啦!只需一行Python代码就可以自动训练N个模型!
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了太香啦!只需一行Python代码就可以自动训练N个模型!相关的知识,希望对你有一定的参考价值。
自动化机器学习(Auto-ML)是指数据科学模型开发的管道组件自动化。AutoML 减少了数据科学家的工作量并加快了工作流程。AutoML 可用于自动化各种管道组件,包括数据理解,EDA,数据处理,模型训练,超参数调整等。
对于端到端机器学习项目,每个组件的复杂性取决于项目。我们知道市面上有很多的 AutoML 开源库可加快开发的速度。在本文中,我将分享一个非常棒的python工具库LazyPredict。
什么是LazyPredict?
LazyPredict是一个开源Python库,可自动执行模型训练管道并加快工作流程。LazyPredict可以为分类数据集训练约30个分类模型,为回归数据集训练约40个回归模型。
LazyPredict将返回经过训练的模型以及其性能指标,而无需编写太多代码。可以轻松比较每个模型的性能指标,并调整最佳模型以进一步提高性能。
安装
可以使用以下方法从PyPl库中安装LazyPredict:
pip install lazypredict
安装后,可以导入库以执行分类和回归模型的自动训练。
from lazypredict.Supervised import LazyRegressor, LazyClassifier
用法
LazyPredict 同时支持分类和回归问题,因此我将利用案例说明:波士顿住房(回归)和泰坦尼克号(分类)数据集用于LazyPredict库的演示。
分类任务
LazyPredict 的用法非常直观,类似于scikit-learn。 首先为分类任务创建一个估计器 LazyClassifier 的实例,可以通过自定义指标进行评估,默认情况下,每个模型都将根据准确性,ROC、AUC得分, F1-score进行评估。
在进行 lazypredict 模型训练之前,必须先读取数据集并进行处理,以使其适合训练。在进行特征工程并将数据拆分为训练测试数据之后,我们可以使用 LazyPredict 进行模型训练。
# LazyClassifier Instance and fiting data
cls= LazyClassifier(ignore_warnings=False, custom_metric=None)
models, predictions = cls.fit(X_train, X_test, y_train, y_test)
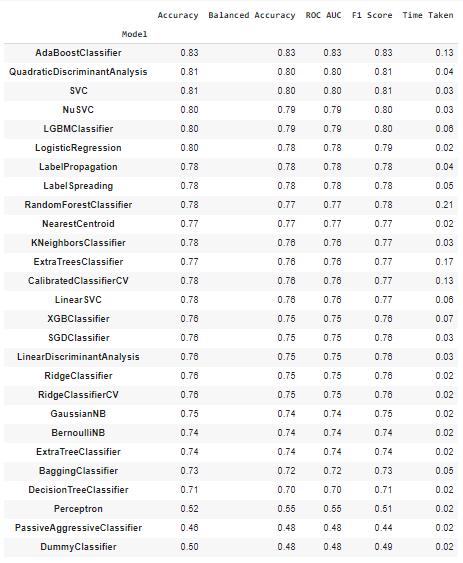
回归任务
与分类模型训练相似,LazyPredict附带了针对回归数据集的自动模型训练。该实现类似于分类任务,只是实例LazyRegressor有所更改。
reg = LazyRegressor(ignore_warnings=False, custom_metric=None)
models, predictions = reg.fit(X_train, X_test, y_train, y_test)
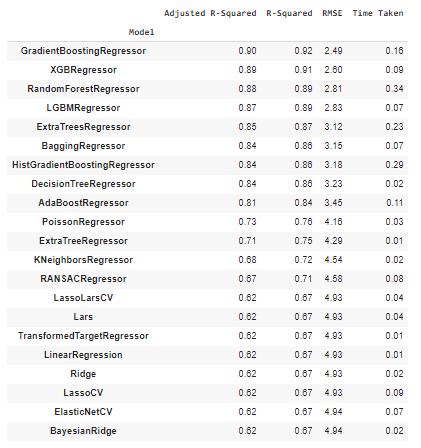
观察以上性能指标,AdaBoost分类器是分类任务的最佳表现模型,而GradientBoostingRegressor模型是回归任务的最佳表现模型。
完整版案例
分类
from lazypredict.Supervised import LazyClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
data = load_breast_cancer()
X = data.data
y= data.target
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=.5,random_state =123)
clf = LazyClassifier(verbose=0,ignore_warnings=True, custom_metric=None)
models,predictions = clf.fit(X_train, X_test, y_train, y_test)
print(models)
| Model | Accuracy | Balanced Accuracy | ROC AUC | F1 Score | Time Taken |
|:-------------------------------|-----------:|--------------------:|----------:|-----------:|-------------:|
| LinearSVC | 0.989474 | 0.987544 | 0.987544 | 0.989462 | 0.0150008 |
| SGDClassifier | 0.989474 | 0.987544 | 0.987544 | 0.989462 | 0.0109992 |
| MLPClassifier | 0.985965 | 0.986904 | 0.986904 | 0.985994 | 0.426 |
| Perceptron | 0.985965 | 0.984797 | 0.984797 | 0.985965 | 0.0120046 |
| LogisticRegression | 0.985965 | 0.98269 | 0.98269 | 0.985934 | 0.0200036 |
| LogisticRegressionCV | 0.985965 | 0.98269 | 0.98269 | 0.985934 | 0.262997 |
| SVC | 0.982456 | 0.979942 | 0.979942 | 0.982437 | 0.0140011 |
| CalibratedClassifierCV | 0.982456 | 0.975728 | 0.975728 | 0.982357 | 0.0350015 |
| PassiveAggressiveClassifier | 0.975439 | 0.974448 | 0.974448 | 0.975464 | 0.0130005 |
| LabelPropagation | 0.975439 | 0.974448 | 0.974448 | 0.975464 | 0.0429988 |
| LabelSpreading | 0.975439 | 0.974448 | 0.974448 | 0.975464 | 0.0310006 |
| RandomForestClassifier | 0.97193 | 0.969594 | 0.969594 | 0.97193 | 0.033 |
| GradientBoostingClassifier | 0.97193 | 0.967486 | 0.967486 | 0.971869 | 0.166998 |
| QuadraticDiscriminantAnalysis | 0.964912 | 0.966206 | 0.966206 | 0.965052 | 0.0119994 |
| HistGradientBoostingClassifier | 0.968421 | 0.964739 | 0.964739 | 0.968387 | 0.682003 |
| RidgeClassifierCV | 0.97193 | 0.963272 | 0.963272 | 0.971736 | 0.0130029 |
| RidgeClassifier | 0.968421 | 0.960525 | 0.960525 | 0.968242 | 0.0119977 |
| AdaBoostClassifier | 0.961404 | 0.959245 | 0.959245 | 0.961444 | 0.204998 |
| ExtraTreesClassifier | 0.961404 | 0.957138 | 0.957138 | 0.961362 | 0.0270066 |
| KNeighborsClassifier | 0.961404 | 0.95503 | 0.95503 | 0.961276 | 0.0560005 |
| BaggingClassifier | 0.947368 | 0.954577 | 0.954577 | 0.947882 | 0.0559971 |
| BernoulliNB | 0.950877 | 0.951003 | 0.951003 | 0.951072 | 0.0169988 |
| LinearDiscriminantAnalysis | 0.961404 | 0.950816 | 0.950816 | 0.961089 | 0.0199995 |
| GaussianNB | 0.954386 | 0.949536 | 0.949536 | 0.954337 | 0.0139935 |
| NuSVC | 0.954386 | 0.943215 | 0.943215 | 0.954014 | 0.019989 |
| DecisionTreeClassifier | 0.936842 | 0.933693 | 0.933693 | 0.936971 | 0.0170023 |
| NearestCentroid | 0.947368 | 0.933506 | 0.933506 | 0.946801 | 0.0160074 |
| ExtraTreeClassifier | 0.922807 | 0.912168 | 0.912168 | 0.922462 | 0.0109999 |
| CheckingClassifier | 0.361404 | 0.5 | 0.5 | 0.191879 | 0.0170043 |
| DummyClassifier | 0.512281 | 0.489598 | 0.489598 | 0.518924 | 0.0119965 |
回归
from lazypredict.Supervised import LazyRegressor
from sklearn import datasets
from sklearn.utils import shuffle
import numpy as np
boston = datasets.load_boston()
X, y = shuffle(boston.data, boston.target, random_state=13)
X = X.astype(np.float32)
offset = int(X.shape[0] * 0.9)
X_train, y_train = X[:offset], y[:offset]
X_test, y_test = X[offset:], y[offset:]
reg = LazyRegressor(verbose=0, ignore_warnings=False, custom_metric=None)
models, predictions = reg.fit(X_train, X_test, y_train, y_test)
print(models)
| Model | Adjusted R-Squared | R-Squared | RMSE | Time Taken |
|:------------------------------|-------------------:|----------:|------:|-----------:|
| SVR | 0.83 | 0.88 | 2.62 | 0.01 |
| BaggingRegressor | 0.83 | 0.88 | 2.63 | 0.03 |
| NuSVR | 0.82 | 0.86 | 2.76 | 0.03 |
| RandomForestRegressor | 0.81 | 0.86 | 2.78 | 0.21 |
| XGBRegressor | 0.81 | 0.86 | 2.79 | 0.06 |
| GradientBoostingRegressor | 0.81 | 0.86 | 2.84 | 0.11 |
| ExtraTreesRegressor | 0.79 | 0.84 | 2.98 | 0.12 |
| AdaBoostRegressor | 0.78 | 0.83 | 3.04 | 0.07 |
| HistGradientBoostingRegressor | 0.77 | 0.83 | 3.06 | 0.17 |
| PoissonRegressor | 0.77 | 0.83 | 3.11 | 0.01 |
| LGBMRegressor | 0.77 | 0.83 | 3.11 | 0.07 |
| KNeighborsRegressor | 0.77 | 0.83 | 3.12 | 0.01 |
| DecisionTreeRegressor | 0.65 | 0.74 | 3.79 | 0.01 |
| MLPRegressor | 0.65 | 0.74 | 3.80 | 1.63 |
| HuberRegressor | 0.64 | 0.74 | 3.84 | 0.01 |
| GammaRegressor | 0.64 | 0.73 | 3.88 | 0.01 |
| LinearSVR | 0.62 | 0.72 | 3.96 | 0.01 |
| RidgeCV | 0.62 | 0.72 | 3.97 | 0.01 |
| BayesianRidge | 0.62 | 0.72 | 3.97 | 0.01 |
| Ridge | 0.62 | 0.72 | 3.97 | 0.01 |
| TransformedTargetRegressor | 0.62 | 0.72 | 3.97 | 0.01 |
| LinearRegression | 0.62 | 0.72 | 3.97 | 0.01 |
| ElasticNetCV | 0.62 | 0.72 | 3.98 | 0.04 |
| LassoCV | 0.62 | 0.72 | 3.98 | 0.06 |
| LassoLarsIC | 0.62 | 0.72 | 3.98 | 0.01 |
| LassoLarsCV | 0.62 | 0.72 | 3.98 | 0.02 |
| Lars | 0.61 | 0.72 | 3.99 | 0.01 |
| LarsCV | 0.61 | 0.71 | 4.02 | 0.04 |
| SGDRegressor | 0.60 | 0.70 | 4.07 | 0.01 |
| TweedieRegressor | 0.59 | 0.70 | 4.12 | 0.01 |
| GeneralizedLinearRegressor | 0.59 | 0.70 | 4.12 | 0.01 |
| ElasticNet | 0.58 | 0.69 | 4.16 | 0.01 |
| Lasso | 0.54 | 0.66 | 4.35 | 0.02 |
| RANSACRegressor | 0.53 | 0.65 | 4.41 | 0.04 |
| OrthogonalMatchingPursuitCV | 0.45 | 0.59 | 4.78 | 0.02 |
| PassiveAggressiveRegressor | 0.37 | 0.54 | 5.09 | 0.01 |
| GaussianProcessRegressor | 0.23 | 0.43 | 5.65 | 0.03 |
| OrthogonalMatchingPursuit | 0.16 | 0.38 | 5.89 | 0.01 |
| ExtraTreeRegressor | 0.08 | 0.32 | 6.17 | 0.01 |
| DummyRegressor | -0.38 | -0.02 | 7.56 | 0.01 |
| LassoLars | -0.38 | -0.02 | 7.56 | 0.01 |
| KernelRidge | -11.50 | -8.25 | 22.74 | 0.01 |
结论
在本文中,我们讨论了LazyPredict库的实现,该库可以在几行Python代码中训练大约70个分类和回归模型。 这是一个非常方便的工具,因为它提供了模型执行的总体情况,并且可以比较每个模型的性能。
每个模型都使用其默认参数进行训练,因为它不执行超参数调整。选择性能最佳的模型后,开发人员可以调整模型以进一步提高性能。
技术交流
欢迎转载、收藏本文,码字不易,有所收获点赞支持一下!
为方便进行学习交流,本号开通了技术交流群,添加方式如下:
直接添加小助手微信号:pythoner666,备注:CSDN+python,或者按照如下方式添加均可!

以上是关于太香啦!只需一行Python代码就可以自动训练N个模型!的主要内容,如果未能解决你的问题,请参考以下文章
弃繁就简!这个工具包只需一行代码就可以搞定 Python 日志!
只需几行 Python 代码,dabl 即可实现数据处理分析和 ML 自动化!