高频面试题-Java集合体系
Posted 墨家巨子@俏如来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高频面试题-Java集合体系相关的知识,希望对你有一定的参考价值。
Java中的集合体系
Java中的集合分为两大体系,一是继承于Collection接口的List和Set体系,List体系如:ArrayList,LinkedList,Set体系如:TreeSet,HashSet,二是继承于Map接口集合体系如:HashMap,TreeMap等。其中使用到多种数据结构:数组,链表,队列,Hash表等等。
1.Map继承体系
Map是一种key-value的存储结构,最大的有点在于查询效率高,继承体系如下:
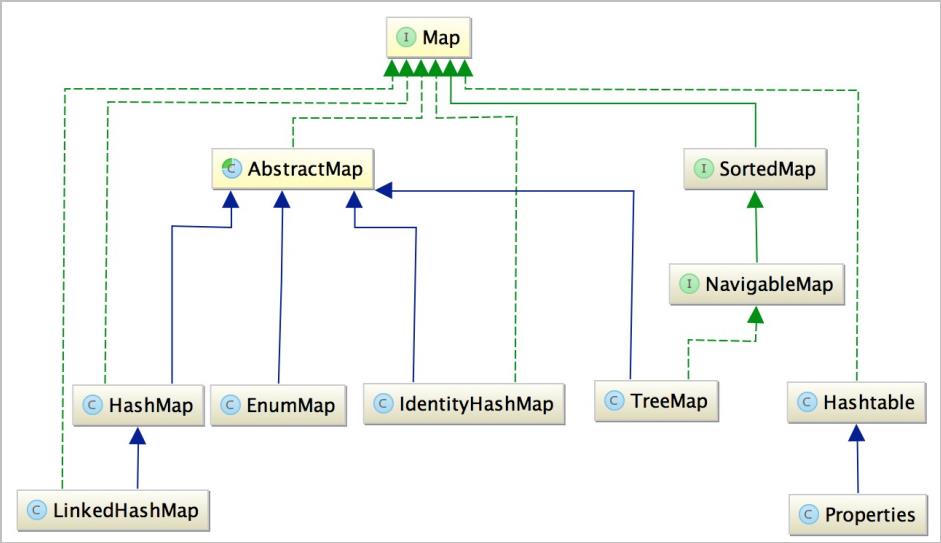
Map比较常用的有HashMap和LinkedHashMap,TreeMap。
1.1.LinkedHashMap
LinkedHashMap是在HashMap的基础上保证了元素的插入顺序,它是基于双向链表来实现的。见《HashMap底层原理》,LinkedHashMap 是继承于 HashMap 实现的一种集合,具有 HashMap 的特点外,它还是有序的。
LinkedHashMap源码如下:
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
{
//一个 LinkedHashMap.Entry 就是HashMap.Node
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;
//true 表示按照访问顺序,会把访问过的元素放在链表后面,放置顺序是访问的顺序
//false 表示按照插入顺序遍历
final boolean accessOrder;
//构造方法
public LinkedHashMap() {
super();
accessOrder = false;
}
LinkedHashMap中的一个 .Entry 就是HashMap的Node ,只不过LinkedHashMap的Entry中多出来了一个 before, after ,这个是用来保证Entry的插入顺序的。
对于 LinkedHashMap.Entry<K,V> head 和 LinkedHashMap.Entry<K,V> tail 则是用来表示链表的头节点和尾节点的。
具有默认初始容量(16)和加载因子(0.75)。并且设定了 accessOrder = false,表示默认按照插入顺序进行遍历。

LinkedHashMap中没有add方法以及remove方法等,直接调用的是HashMap中的方法,具体见HashMap。
1.2.TreeMap
TreeMap是基于红黑树实现,它默认情况下按照key的compareTo进行自然顺序升续排序,所以put的key需要实现Comparable接口,当然也可以在new TreeMap(Comparator)的时候指定Comparator进行排序。
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
{
/**
* The comparator used to maintain order in this tree map, or
* null if it uses the natural ordering of its keys.
*
* @serial
* 比较器
*/
private final Comparator<? super K> comparator;
//红黑树根节点
private transient Entry<K,V> root;
/**
节点数
* The number of entries in the tree
*/
private transient int size = 0;
/**
* The number of structural modifications to the tree.
*/
private transient int modCount = 0;
//通过构造器指定比较器
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
//红黑树种的每个节点类型
static final class Entry<K,V> implements Map.Entry<K,V> {
K key; //键
V value; //值
Entry<K,V> left; //左子树
Entry<K,V> right; //有子树
Entry<K,V> parent; //父节点
boolean color = BLACK; //颜色
...省略...
}
这里可以看到,TreeMap通过 Comparator 进行排序,当然可以通过构造器传入Comparator。添加元素方法如下:
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
//根节点为空,设置新添加的元素为根节点
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
//比较器
Comparator<? super K> cpr = comparator;
if (cpr != null) {
//比较器不为空,插入新的元素时,按照comparator实现的类进行排序
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
//如果比较器为空,按照key的自然顺序
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
//红黑树左旋,右旋操作
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
TreeMap添加元素如果有指定Comparator就按照Comparator排序,否则就使用key进行自然排序。
1.3.HashTable
HashTable与HashMap的区别是HashTable使用同步锁保证了线程安全,HashTable效率比较低使用较少,现在通常使用HashMap,在多线程环境下通常用CurrentHashMap来代替。
2.Collection继承体系:
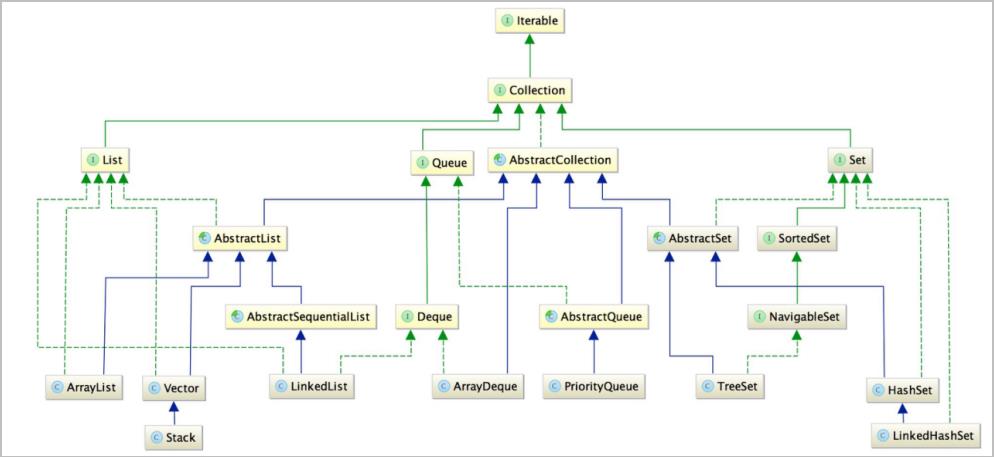
2.1.List体系
List集合体系中用的比较多的就是ArrayList和LinkedList,他们都拥有元素有序可重复的特点。ArrayList是基于数组实现,随机访问速度比较快,但是低于增删需要进行移位操作,性能比较慢。LinkedList底层基于链表来实现,增删比较快,但是随机访问比较慢,而Vector的方法加了同步锁,可以认为是ArrayList的线程安全版本,但是它是比较古老的一个类,现在用的也比较少。
2.2.Queue队列
Queue是基于队列的一种结构,它可以保证元素先进先出的特点,Deque是双端队列的实现,继承于Queue。LinkedList又是实现与Qeque双端队列,所以如果要使用队列,通常是直接使用LinkedList。PriorityQueue叫做优先队列,它的特点是为每个元素提供一个优先级,优先级高的元素会优先出队列(默认排序是自然排序,队头元素是最小元素,可以通过comparator比较器修改排序的比较方式)。
2.3.Set体系
Set体系包括TreeSet,HashSet,LinkedHashSet等等,Set的特点是不保证元素的插入顺序,而且不允许元素重复,这2点正好和List相反,Set使用hash方法和equals方法来判断元素是否重复,所以存储到Set中的元素需要复写这两个方法。
2.4.TreeSet
TreeSet是基于TreeMap的key实现的存储结构,add的元素就存储到TreeMap的key上,值全是一个Object对象。
另外它默认情况下使用的compareTo进行自然顺序升续排序,所以put的key需要实现Comparable接口,当然也可以在new TreeSet(Comparator)的时候指定Comparator进行排序。
TreeSet的源码:
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
/**
* The backing map.
* 这儿就是TreeSet底层用来存储元素的Map
*/
private transient NavigableMap<E,Object> m;
// Dummy value to associate with an Object in the backing Map
//这个是Map的值,元素存储在map的key上,值全都是 PRESENT
private static final Object PRESENT = new Object();
/**
* Constructs a set backed by the specified navigable map.
*/
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
/**
构造一个新的空树集,并根据其元素的自然顺序对其进行排序。
插入集合中的所有元素都必须实现Comparable接口
* Constructs a new, empty tree set, sorted according to the
* natural ordering of its elements. All elements inserted into
* the set must implement the {@link Comparable} interface.
* Furthermore, all such elements must be <i>mutually
* comparable</i>: {@code e1.compareTo(e2)} must not throw a
* {@code ClassCastException} for any elements {@code e1} and
* {@code e2} in the set. If the user attempts to add an element
* to the set that violates this constraint (for example, the user
* attempts to add a string element to a set whose elements are
* integers), the {@code add} call will throw a
* {@code ClassCastException}.
*/
public TreeSet() {
//new 一个TreeSet 底层就是new了一个TreeMap
this(new TreeMap<E,Object>());
}
TreeSet 添加一个元素,就是添加到TreeMap的key上
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
删除一个元素,就是从TreeMap中删除元素
public boolean remove(Object o) {
return m.remove(o)==PRESENT;
}
其他方法都是调用的map,不多赘述
2.5.HashSet
HashSet是基于HashMap的key实现的存储结构,支持的HashMap实例具有默认的初始容量(16)和负载因子(0.75),add的元素存储到HashMap的key上,值指向一个Object对象。由于底层使用到Hash表,所以HashSet是不会保证元素的插入顺序的。
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
//存储元素的HashMap
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
/**
构造一个新的空集; 支持的HashMap实例具有默认的初始容量(16)和负载因子(0.75)。
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
//这里创建一个HashMap
map = new HashMap<>();
}
存储一个元素,就是存储到HashMap的key上
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
删除一个元素就是从HashMap中删除
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
其他方法都是调用的map,不多赘述
2.6.LinkedHashSet
LinkedHashSet是基于链表和Hash表实现存储结构,它继承于HashSet,它的目的是在HashSet的基础上保证元素插入集合的顺序与输出顺序保持一致,LinkedHashSet 是由 LinkedHashMap 实现的集合,实例具有默认的初始容量(16)负载因子(0.75)。
LinkedHashSet源码
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
//初始容量 16,负载因子 0.75
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
上面的构造器调用的是其父类,即HashSet的方法构造方法:
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
添加元素
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
删除元素
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
所以从这里可以看出,LinkedHashSet的功能是由其父类HashSet来实现,而底层存储结构是基于LinkedHashMap的key来实现。
最后来个总结图:
| 集合 | 特点 | 说明 |
|---|---|---|
| List | 1. 有序,可重复2. 可以通过索引访问(下标) | 数组(ArrayList)或者链表(LinkedList)存储 |
| Set | 1. 无序,不重复 | 使用Map存储(HashSet - HashMap) |
| ArrayList | 1. 有序2. 随机访问快(下标)3. 插入,删除慢(移位) | 底层基于动态数组,内存连续,查询速度快,删除添加要移动数据,性能低下 |
| LinkedList | 1. 有序2. 查询慢3. 插入,删除快 | 双向链表,内存可以不连续,删除,添加快,查询慢 |
| Vector | 1. 有序2.线程安全(synchronized)ArrayList的前任 | 数组 , 同步锁保证安全性,性能低,不推荐用 |
| PriorityQueue | 1. 优先队列2. 默认最小的在前面,按照自然顺序排序 | 二叉小顶堆(二叉树) |
| TreeSet | 1. 可以保证元素排序(默认自然顺序,可定制)2. 是线程不安全3. 元素不重复(compareTo判断)4. 插入的元素必须实现Comparable接口5. 不允许放入null值 | 基于TreeMap的KeySet存储数据,使用红黑树实现需要排序时使用TreeSet |
| HashSet | 1. 线程不安全2. 元素不重复(通过hashCode和equals方法判断)3. 元素是无序的4. 只能放入一个null | 基于 HashMap 的KeySet储存数据,使用Hash表实现 性能高于TreeSet,优先使用它 |
| LinkedHasHSet extends HashSet | 1. 线程不安全2. 元素不重复3. 可以保证元素插入的顺序4. 迭代性能高于HashSet | 基于LinkHashMap存储数据,哈希表和双向链表 |
| HashMap | 1. 非线程安全 2. 基于哈希表实现3. 通过hashcode实现元素快速查找4. 元素无序5. 可以出现一个null键,多个null值 | 基于哈希表实现适用于在Map中插入、删除和定位元素 |
| TreeMap | 1. 非线程安全2. 基于红黑树实现 | 基于红黑树实现适用于按自然顺序或自定义顺序遍历键(key) |
| HashTable | 1. 线程安全的2. 性能低下3. 不能有null键和null值 | 哈希表实现,线程安全,性能低,已经不用了,多线程使用concurrentHashMap |
文章到这就结束了把,喜欢的话给个好评哟!!!
以上是关于高频面试题-Java集合体系的主要内容,如果未能解决你的问题,请参考以下文章