pytorch-lightning入门—— 初了解
Posted Tina姐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pytorch-lightning入门—— 初了解相关的知识,希望对你有一定的参考价值。
最近PyTorch Lightning的风很大,来看看为啥它这么火🔥
本文主要大致了解一下pytorch-lighting是什么,优点是什么,代码的主要结构。具体细节和案例后面给出。
文章目录
1 什么是pytorch-lightning

pytorch-lighting(简称pl),它其实就是一个轻量级的PyTorch库,用于高性能人工智能研究的轻量级PyTorch包装器。缩放你的模型,而不是样板。
它可以清晰地抽象和自动化ML模型所附带的所有日常样板代码,允许您专注于实际的ML部分(这些也往往是最有趣的部分)。除了自动化样板代码外,Lightning还可以作为一种样式指南,用于构建干净且可复制的ML系统。
pytorch 和 pl 本质上代码是完全相同的。只不过pytorch需要自己造轮子(如model, dataloader, loss, train,test,checkpoint, save model等等都需要自己写),而pl 把这些模块都结构化了(类似keras)。
从下面的图片来看两者的区别

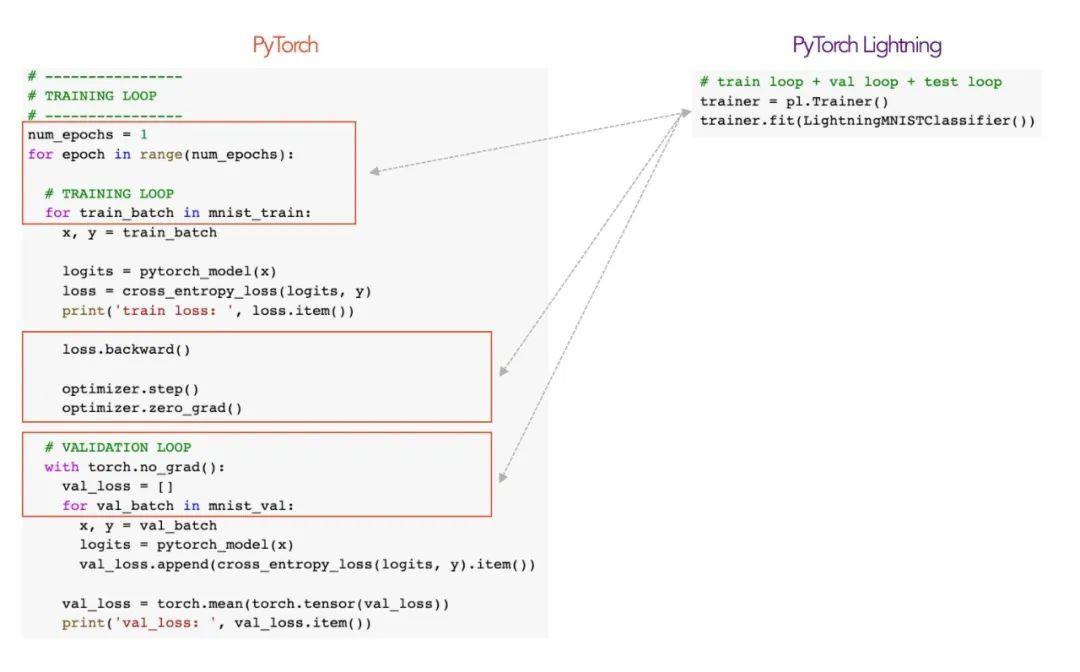
从上面我们可以发现 pl 的三个优势
- 通过抽象出样板工程代码,可以更容易地识别和理解ML代码。
- Lightning的统一结构使得在现有项目的基础上进行构建和理解变得非常容易。
- Lightning 自动化的代码是用经过全面测试、定期维护并遵循ML最佳实践的高质量代码构建的。
总结:Pytorch-lightning可以非常简洁得构建深度学习代码。但是其实大部分人用不到很多复杂得功能。而pl有时候包装得过于深了,用的时候稍微有一些不灵活。通常来说,在你的模型搭建好之后,大部分的功能都会被封装在一个叫trainer的类里面。一些比较麻烦但是需要的功能通常如下, 通过pl就可以很好的实现:
- 保存checkpoints
- 输出log信息
- resume training 即重载训练,我们希望可以接着上一次的epoch继续训练
- 记录模型训练的过程(通常使用tensorboard)
- 设置seed,即保证训练过程可以复制
2 如何将PyTorch代码组织到Lightning中
使用PyTorch Lightning组织代码可以使您的代码1:
- 保留所有灵活性(这全是纯PyTorch),但要删除大量样板
- 将研究代码与工程解耦,更具可读性
- 更容易复制
- 通过自动化大多数训练循环和棘手的工程设计,减少了容易出错的情况
- 可扩展到任何硬件而无需更改模型
官网提供了一个3分钟的python代码 转 pl 代码的对比视频,详细的介绍了每一个模块之间的对应关系。详情戳链接
视频部分截图如下:


2.1 安装 PyTorch Lightning
通过pip 安装
pip install pytorch-lightning
通过conda 安装
conda install pytorch-lightning -c conda-forge
安装在指定conda环境
conda activate my_env
pip install pytorch-lightning
安装后导入相关包
import os
import torch
from torch import nn
import torch.nn.functional as F
from torchvision import transforms
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader, random_split
import pytorch_lightning as pl
2.1 定义LightningModule
class LitAutoEncoder(pl.LightningModule):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 64),
nn.ReLU(),
nn.Linear(64, 3)
)
self.decoder = nn.Sequential(
nn.Linear(3, 64),
nn.ReLU(),
nn.Linear(64, 28*28)
)
def forward(self, x):
# in lightning, forward defines the prediction/inference actions
embedding = self.encoder(x)
return embedding
def training_step(self, batch, batch_idx):
# training_step defined the train loop.
# It is independent of forward
x, y = batch
x = x.view(x.size(0), -1)
z = self.encoder(x)
x_hat = self.decoder(z)
loss = F.mse_loss(x_hat, x)
# Logging to TensorBoard by default
self.log('train_loss', loss)
return loss
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)
return optimizer
def init(self): 定义网络架构(model);def forward(self, x):定义推理、预测的前向传播; def training_step(self, batch, batch_idx):定义train loop; def configure_optimizers(self): 定义优化器
因此,lightning module 定义的是一个系统而不是单纯的网络架构。
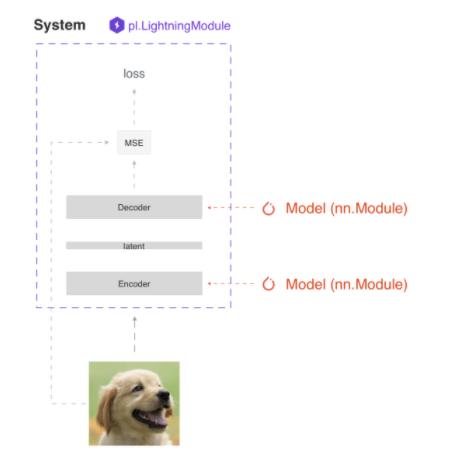
至于在这个系统中,针对不同的任务(如,Autoencoder,BERT,DQN,GAN,Image classifier,Seq2seq,SimCLR,VAE)具体怎么写,官网给出了不同的案例。(https://pytorch-lightning.readthedocs.io/en/latest/starter/new-project.html)
2.2 Fit with Lightning Trainer
对应的中文不知道怎么翻译贴切。意思就是把Trainer所需要的参数喂给它。
# init model
autoencoder = LitAutoEncoder()
# most basic trainer, uses good defaults (auto-tensorboard, checkpoints, logs, and more)
# trainer = pl.Trainer(gpus=8) (if you have GPUs)
trainer = pl.Trainer()
trainer.fit(autoencoder, train_loader)
这里的trainer.fit接收两个参数,包括model 和 dataloader. 然后它自己就开始训练~~~~
trainer是自动化的,包括:
- Epoch and batch iteration
- 自动调用 optimizer.step(), backward, zero_grad()
- 自动调用 .eval(), enabling/disabling grads
- 权重加载
- 保存日志到tensorboard
- 支持多-GPU
- TPU
- 支持AMP
部分参考链接
https://cloud.tencent.com/developer/article/1593703
https://pytorch-lightning.readthedocs.io/en/latest/starter/new-project.html
https://github.com/PyTorchLightning/pytorch-lightning

https://pytorch-lightning.readthedocs.io/en/latest/starter/new-project.html ↩︎
以上是关于pytorch-lightning入门—— 初了解的主要内容,如果未能解决你的问题,请参考以下文章