4-1 Python常用内置算法与数据结构常考题
Posted WinvenChang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了4-1 Python常用内置算法与数据结构常考题相关的知识,希望对你有一定的参考价值。
一、你使用过哪些常用内置算法和数据结构
仔细回想一下你用过哪些内置的算法数据结构?
1.sorted
2.dict/list/set/tuple…
3.问题:想的不全或者压根没了解和使用过
| 数据结构/算法 | 语言内置 | 内置库 |
|---|---|---|
| 线性结构 | list(列表)/tuple(元组) | array(数组,不常用)/collecions.namedtuple |
| 链式结构 | collections.deque(双端队列) | |
| 字典结构 | dict(字典) | collections.Counter(计数器)/OrderedDict(有序字典) |
| 集合结构 | set(集合)/fronzenset(不可变集合) | |
| 排序算法 | sorted | |
| 二分算法 | bisect模块 | |
| 堆算法 | heapq模块 | |
| 缓存算法 | functools.lru_cache(Least Recent Used, python3) |
二、有用过collections模块吗
collections模块提供了一些内置数据结构的扩展
| 方法名 | 解释 |
|---|---|
namedtuple() | factory function for creating tuple subclasses with named fields |
deque | list-like container with fast appends and pops on either end |
Counter | dict subclass for counting hashable objecs |
OrderedDict | dict subclass that remembers the order entries were added |
defaultdict | dict subclass that calls a factory function to supply missing values |
namedtuple代码示例:
import collections
Point = collections.namedtuple('Point', 'x, y')
p = Point(1, 2)
print(p.x) # 1
print(p.y) # 2
print(p[0]) # 1
print(p[1]) # 2
print(p[2]) # IndexError: tuple index out of range
print(p.x == p[0]) # True
说明:namedtuple让tuple属性可读
deque代码示例:
import collections
de = collections.deque()
de.append(1) # 往右边添加值
de.appendleft(0) # 往左边添加值
print(de) # deque([0, 1])
de.pop() # 1 取右边的值
de.popleft() # 0 取左边的值
说明:deque可以方便地实现queue/stack
Counter代码示例:
import collections
c = collections.Count('abcab)
print(c) # Counter({'a': 2, 'b': 2, 'c': 1})
print(c['a']) # 2
print(c.most_common()) # [('a', 2), ('b', 2), ('c', 1)] 从大到小获取每一个的数量
说明:需要计数器的地方使用Counter
OrderedDict代码示例:
import collections
od = collections.OrderedDict()
od['c'] = 'c'
od['a'] = 'a'
od['b'] = 'b'
print(list(od.keys()) # ['c', 'a', 'b']
说明:
OrderedDict的key顺序是第一次插入的顺序。
使用OrderedDict还可以实现LRUCache。
defaultdict代码示例:
import collections
dd = collections.defaultdict(int)
print(dd['a']) # 0 当不存在时,会返回一个默认值,因为上面定义的 int 类型,所以默认值为 0
dd['b'] += 1
print(dd) # defaultdict(int, {'a': 0, 'b': 1})
说明:defaultdict是带有默认值的字典
三、Python dict底层结构
dict底层使用的是哈希表
1.为了支持快速查找使用了哈希表作为底层结构
2.哈希表平均查找时间复杂度O(1)
3.CPython解释器使用二次探查解决哈希冲突问题
注意:哈希冲突和扩容是常考题
解决哈希冲突通常有两种:
1)、链接法
2)、探查法:分为线性探查和二次探查等
四、Python list/tuple区别
list VS tuple
1.都是线性结构,支持下标访问
2.list是可变对象,tuple是不可变对象
3.list没没作为字典的 key,tuple可以(可变对象不可 hash)
注意,如何tuple里包含list,则里面这个list是可以改变的
代码示例:
t = ([1, 2], 3, 4)
t[0].append(5)
print(t) # ([1, 2, 5], 3, 4)
保存的引用不可变指的是:你没法替换掉这个对象,但是如果对应那个本身是一个可变对象,是可以修改这个引用指向的可变对象的。
五、什么是 LRUCache?
Least-Recently-Used替换掉最近最少使用的对象
1.缓存剔除策略,当缓存空间不够用的时候需要一种方式剔除key
2.常见的有 LRU, LFU等
3.LRU通过使用一个循环双端队列不断把最新访问的key放到表头实现
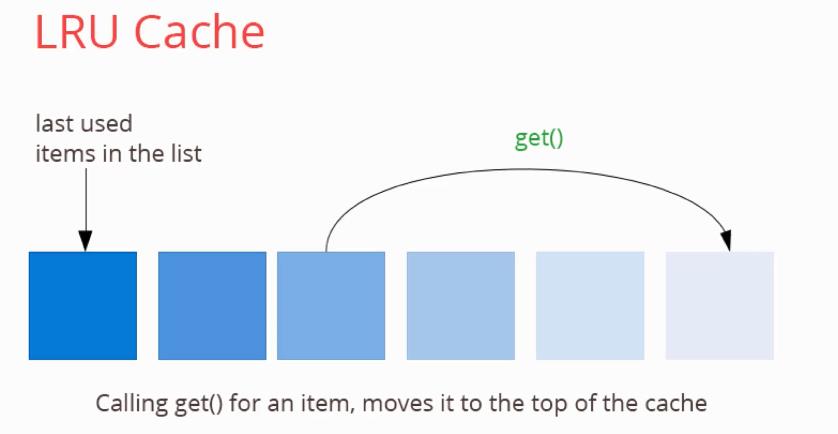
六、如何实现LRUCache
字典用来缓存,循环双端链表用来记录访问顺序
1.利用Python内置的dict + collections.OrderedDict实现
2.dict用来当做 k/v键值对的缓存
3.OrderedDict用来实现更新最近访问的 key
代码示例:
from collections import OrderedDict
class LRUCache:
def __init__(self, capacity=128):
self.od = OrderedDict()
self.capacity = capacity # 最大容量
def get(self, key): # 每次访问更新最新使用的 key
if key in self.od:
val = self.od[key]
self.od.move_to_end(key) # 移动元素到表头
return val
else:
return -1
def put(self, key, value): # 更新 key/value
if key in self.od:
del self.od[key]
self.od[key] = value # 更新 key 到表头,所以上一句要先删除这个key里的value
else: # insert
self.od[key] = value
# 判断当前容量是否已经满了
if len(self.od) > self.capacity:
self.od.popitem(last=False) # 删除最早的 key/value
请大家自己实现LRUCache,并编写单元测试
以上是关于4-1 Python常用内置算法与数据结构常考题的主要内容,如果未能解决你的问题,请参考以下文章