框架篇:分布式全局唯一ID
Posted cscw0521
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了框架篇:分布式全局唯一ID相关的知识,希望对你有一定的参考价值。
前言
每一次HTTP请求,数据库的事务的执行,我们追踪代码执行的过程中,需要一个唯一值和这些业务操作相关联,对于单机的系统,可以用数据库的自增ID或者时间戳加一个在本机递增值,即可实现唯一值。但在分布式,又该如何实现唯一性的ID
- 分布式ID的特性
- 数据库自增的ID
- Redis分布式ID
- Zookeeper分布式ID
- 全局唯一UUID的优缺点
- Twitter的雪花算法生成分布式ID
关注公众号,一起交流,微信搜一搜: 潜行前行
github地址,感谢star
分布式ID的特性
- 全局唯一性,必须性
- 幂等性,如果是根据某些信息生成,则需要保障幂等性
- 注意安全性,ID里隐藏一些信息,不能被猜出来,也不能被猜出来 ID 如何生成
- 趋势递增性,在查询比较时,可以判断业务操作的时间顺序
数据库自增的ID
- 实现简单,ID单调自增,数值类型查询速度快,但是单点DB存在宕机风险,无法扛住高并发场景
CREATE TABLE FLIGHT_ORDER (
id int(11) unsigned NOT NULL auto_increment, #自增ID
PRIMARY KEY (id),
) ENGINE=innodb;
集群下如何保证数据库ID的唯一性
- 当随着业务发展,服务拓展到多台的大集群时,为了解决单点数据库的压力,数据库也会相应的变成一个集群,那如何保证集群下数据库ID的唯一性
- 每一台数据库实例都设置一个起始值和增长步长
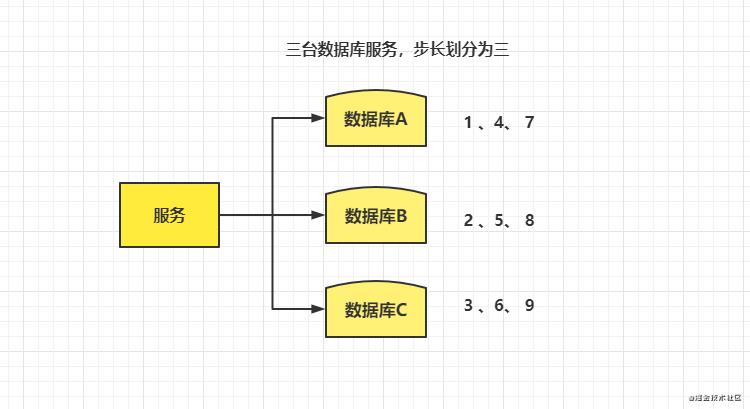
- 缺点:不利于后续扩容,如果后续需要扩容还需要人工介入修改 起始值和增长步长
Redis 分布式ID
- 假如系统有亿万的数据,依靠数据库的自增ID在分表分库之后,需要人工修改每台数据库实例,扩容性差,维护性不好
基于Redis INCR 命令生成分布式全局唯一ID
- 服务向redis获取Id,ID则和数据库解耦,可以解决ID和分表分库的问题,而且redis比数据库性能更快,可以支撑集群服务并发获取ID的需求
- redis的INCR命令具备了 INCR AND GET 的原子操作;redis是单进程单线程架构,INCR 命令不会出现 ID 重复
@Autowired
private StringRedisTemplate stringRedisTemplate;
private static final String ID_KEY = "id_good_order";
public Long incrementId() {
return stringRedisTemplate.opsForValue().increment(ID_KEY);
}
HINCRBY 命令
- 实际上,为了存储序列号的更多相关信息,可以使用了 Redis 的 Hash 数据结构,Redis 同样为 Hash 提供 HINCRBY 命令来实现 “INCR AND GET” 原子操作
//KEY_NAME 是 hash结构对应的Key,FIELD_NAME 是hash结构的字段,INCR_BY_NUMBER是增量值
redis 127.0.0.1:6379> HINCRBY KEY_NAME FIELD_NAME INCR_BY_NUMBER
宕机序列号恢复问题
- redis是内存数据库,在没有开启RDB或AOF持久化的情况下,一旦宕机ID数据将会有丢失。即便开启了RDB持久化,由于最近一次快照时间和最新一条 HINCRBY 命令的时间有可能存在时间差,宕机后通过RDB快照恢复数据集会发生ID取值重复的情况
- redis宕机序列号恢复方案
- 利用关系型数据库来记录一个短时内 最大可取序列号 MAX_ID,从redis获取ID时只能取小于 MAX_ID 的序列号
- 为了计算最大值,需要一个定时任务定期计算ID消费速度RATE,存于redis。当客户端取得 CUR_ID、RATE 和 MAX_ID,则根据 ID 消费速度 RATE 计算 CUR_ID 是否逼近MAX_ID,如果是则更新数据库的MAX_ID
Zookeeper 分布式ID
- 利用zookeeper的持久性有序节点,可以实现自增的分布式ID,而且zookeeper是个高可用的集群服务,提交成功的消息具有持久性,因此不怕机器宕机问题,或者单机问题
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.2.0</version>
</dependency>
- 示例
RetryPolicy retryPolicy = new ExponentialBackoffRetry(500, 3);
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("localhost:2181")
.connectionTimeoutMs(5000)
.sessionTimeoutMs(5000)
.retryPolicy(retryPolicy)
.build();
client.start();
String sequenceName = "root/sequence/distributedId";
DistributedAtomicLong distAtomicLong = new DistributedAtomicLong(client, sequenceName, retryPolicy);
//使用DistributedAtomicLong生成自增序列
public Long sequence() throws Exception {
AtomicValue<Long> sequence = this.distAtomicLong.increment();
if (sequence.succeeded()) {
return sequence.postValue();
} else {
return null;
}
}
UUID的优缺点
- 基于数据库,redis,zookeeper的分布式ID都高度依赖一个外部服务,对于某些场景,假如不存在这些外部服务又该怎么生成分布式的ID
- JDK里自带一个唯一性的ID的生成器,具有全球唯一性,这就是UUID,不过它是串无意义的字符串,存储性能差,查询也很耗时,对于订单系统,不适合作为唯一ID,常见优化方案为转化为两个uint64整数存储或者 折半存储(折半后不能保证唯一性)
- 但对于日志系统,或只是为了作为数据里可以唯一识别序列号的关联属性时,可以用UUID
String uuid = UUID.randomUUID().toString().replaceAll("-","");
Twitter 的雪花算法生成分布式ID
- 和UUID一样,雪花算法并不依赖外部服务
- 雪花算法时 Twitter 公司内部分布式项目采用的ID生成算法,广受国内公司好评。不依赖第三方服务,效率高
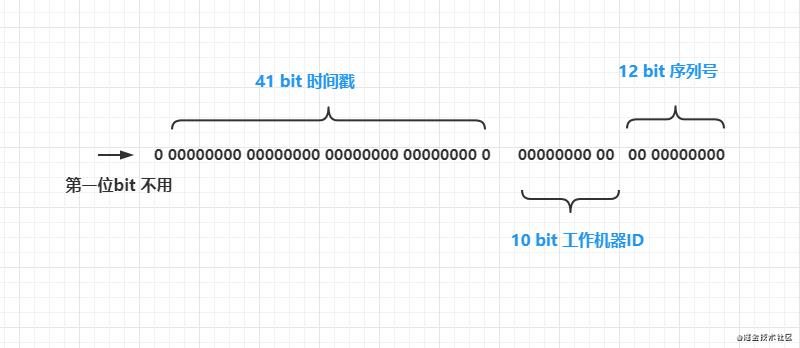
- Snowflake ID组成结构:正数位(占1比特)+ 时间戳(占41比特)+ 机器ID(占5比特)+ 数据中心(占5比特)+ 自增值(占12比特),总共64比特组成的一个Long类型。
1:第一个bit位(1bit):Java中long的最高位是符号位代表正负,正数是0,负数是1,一般生成ID都为正数,所以默认为0。
2:时间戳部分(41bit):毫秒级的时间,不建议存当前时间戳,而是用(当前时间戳 - 固定开始时间戳)的差值,可以使产生的ID从更小的值开始
3:工作机器id(10bit):也被叫做workId,这个可以灵活配置,机房或者机器号组合都可以。
4:序列号部分(12bit),自增值支持同一毫秒内同一个节点可以生成4096个ID
//Twitter的SnowFlake算法,使用SnowFlake算法生成一个整数
public class SnowFlakeShortUrl {
//起始的时间戳
static long START_TIMESTAMP = 1624698370256L;
//每一部分占用的位数
static long SEQUENCE_BIT = 12; //序列号占用的位数
static long MACHINE_BIT = 5; //机器标识占用的位数
static long DATA_CENTER_BIT = 5; //数据中心占用的位数
//每一部分的最大值
static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
static long MAX_DATA_CENTER_NUM = -1L ^ (-1L << DATA_CENTER_BIT);
//每一部分向左的位移
static long MACHINE_LEFT = SEQUENCE_BIT;
static long DATA_CENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
static long TIMESTAMP_LEFT = DATA_CENTER_LEFT + DATA_CENTER_BIT;
//dataCenterId + machineId 等于10bit工作机器ID
private long dataCenterId; //数据中心
private long machineId; //机器标识
private volatile long sequence = 0L; //序列号
private volatile long lastTimeStamp = -1L; //上一次时间戳
private volatile long l currTimeStamp = -1L; //当前时间戳
private long getNextMill() {
long mill = System.currentTimeMillis();
while (mill <= lastTimeStamp) mill = System.currentTimeMillis();
return mill;
}
//根据指定的数据中心ID和机器标志ID生成指定的序列号
public SnowFlakeShortUrl(long dataCenterId, long machineId) {
Assert.isTrue(dataCenterId >=0 && dataCenterId <= MAX_DATA_CENTER_NUM,"dataCenterId is illegal!");
Assert.isTrue(machineId >= 0 || machineId <= MAX_MACHINE_NUM,"machineId is illegal!");
this.dataCenterId = dataCenterId;
this.machineId = machineId;
}
//生成下一个ID
public synchronized long nextId() {
currTimeStamp = System.currentTimeMillis();
Assert.isTrue(currTimeStamp >= lastTimeStamp,"Clock moved backwards");
if (currTimeStamp == lastTimeStamp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
if (sequence == 0L) { //同一毫秒的序列数已经达到最大,获取下一个毫秒
currTimeStamp = getNextMill();
}
} else {
sequence = 0L; //不同毫秒内,序列号置为0
}
lastTimeStamp = currTimeStamp;
return (currTimeStamp - START_TIMESTAMP) << TIMESTAMP_LEFT //时间戳部分
| dataCenterId << DATA_CENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
}
public static void main(String[] args) {
SnowFlakeShortUrl snowFlake = new SnowFlakeShortUrl(10, 4);
for (int i = 0; i < (1 << 12); i++) {
//10进制
System.out.println(snowFlake.nextId());
}
}
}
欢迎指正文中错误
参考文章
以上是关于框架篇:分布式全局唯一ID的主要内容,如果未能解决你的问题,请参考以下文章