记一次datax hdfswriter的踩坑记(上传文件到hdfs的坑)
Posted 果汁华
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次datax hdfswriter的踩坑记(上传文件到hdfs的坑)相关的知识,希望对你有一定的参考价值。
写这个文档的初衷是方便后人在使用datax同步hdfs的时候及时脱坑,毕竟本人花了不少时间一步一步才排查出来的,在google、github、stackoverflow目前没有完整排坑文档(大部分只是到设置dfs.client.use.datanode.hostname这一步)。
背景是需要把数据从mysql同步到hdfs中,采用的工具是datax。
1、拿到myql和hdfs的连接信息,写好job config文件,运行datax。
直接报错:
Caused by: org.apache.hadoop.ipc.RemoteException(java.io.IOException):
File/warehouse/tablespace/managed/hive/tanzy.db/orders__0194bb05_7775_40ef_93f5_8c33f
c9f564c/test__1ad30f50_4135_4011_802d_1d147c751c09 could only be written to 0 of the 1 minReplication nodes.
There are 3 datanode(s) running and 3 node(s) are excluded in this operation.不慌不慌,google、github和stackoverflow在手。
直接给出我们的分析结果:
NameNode节点存放的是文件目录,也就是文件夹、文件名称。
本地可以通过公网访问 NameNode,所以可以进行文件夹的创建,当上传文件需要写入数据到DataNode时,
NameNode 和DataNode 是通过局域网进行通信,NameNode返回地址为 DataNode 的私有 IP,本地无法访问。
简单好吧,解决办法有两个步骤哦:
-
返回的IP地址无法返回公网IP,只能
返回主机名,通过主机名与公网地址的映射便可以访问到DataNode节点,问题将解决。
我在Ambari中设置hdfs的属性:dfs.client.use.datanode.hostname。当然大家也可以直接在服务器上修改Custom hdfs-site 文件,重启一下。添加如下属性

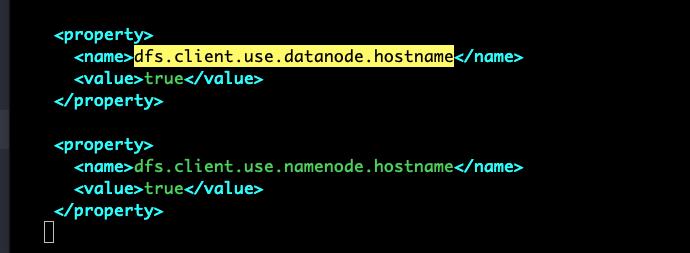
-
找到运维同学帮忙开几个公网,本地配置一下/etc/hosts

上述两个都准备就绪,重新运行 datax  。
。
报错:
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.SafeModeException):
Cannot create file/warehouse/tablespace/managed/hive/tanzy.db/orders__9f906df9_0445_4d87_9c57_cb3f8dfc7b36/test__47b4850b_0f42_4aa2_9484_62f61fa8f83c.
Name node is in safe mode.简单,开启非安全模式,同样修改hdfs 配置文件,重启。
再次运行。又又又报错了:
还是报错:
Caused by: org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /warehouse/tablespace/managed/hive/tanzy.db/orders__0194bb05_7775_40ef_93f5_8c33fc9f564c/test__1ad30f50_4135_4011_802d_1d147c751c09 could only be written to 0 of the 1 minReplication nodes. There are 3 datanode(s) running and 3 node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:2125)
at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.chooseTargetForNewBlock(FSDirWriteFileOp.java:286)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2706)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:875)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:561)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:524)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1025)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:876)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:822)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2682)
at org.apache.hadoop.ipc.Client.call(Client.java:1476)
at org.apache.hadoop.ipc.Client.call(Client.java:1407)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy10.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:418)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy11.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.locateFollowingBlock(DFSOutputStream.java:1430)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1226)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:449)认真看了日志,研究了一下,我发现其实它没有走域名,还是走的内网ip 172.16.x.x

那问题就比较清晰了,为啥不走域名,首先肯定是怀疑配置有没下发并生效,因为我是使用Ambari操作hdfs服务的,先上对应的服务器,找到配置文件,是有对应的文件,说明配置下发成功了。
那现在摆在我的面前就只有一条路了,那就是为啥datax拿到的配置(dfs.client.use.datanode.hostname)是不对的。手动debug一下,果然发现了问题

在dfsclient.conf.properties中的dfs.client.use.datanode.hostname配置居然是false
这里就有两个怀疑的点了,1.Ambari配置下发成功了,但不生效;2.datax这里没有读取配置文件;
验证1的话,我需要找一个hdfs的clinet连接上hdfs namenode server验证,链路比较长。我选择了第二种(毕竟都已经debug datax源码到这里了),查询hdfs的writer config发现有一个
hadoopConfig 这里应该可以设置相关连接属性, "hadoopConfig": {
"dfs.client.use.datanode.hostname": true
},
重新运行datax:

舒服了。

以上是关于记一次datax hdfswriter的踩坑记(上传文件到hdfs的坑)的主要内容,如果未能解决你的问题,请参考以下文章