基于 Flink 的动态欺诈检测系统(下)
Posted zhisheng_blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于 Flink 的动态欺诈检测系统(下)相关的知识,希望对你有一定的参考价值。
介绍
在本系列的前两篇文章中,我们描述了如何基于动态更新配置(欺诈检测规则)来实现灵活的数据流分区,以及如何利用 Flink 的 Broadcast 机制在运行时在相关算子之间分配处理配置。
直接跟上我们上次讨论端到端解决方案的地方,在本篇文章中,我们将描述如何使用 Flink 的 "瑞士军刀" —— Process Function 来创建一个量身定制的实现,以满足你的流业务逻辑需求。我们的讨论将在欺诈检测引擎的背景下继续进行,我们还将演示如何在 DataStream API 提供的窗口不能满足你的要求的情况下,通过自定义窗口来实现你自己的需求。特别的是,我们将研究在设计需要对单个事件进行低延迟响应的解决方案时可以做出权衡。
本文将描述一些可以独立应用的高级概念,建议你先阅读本系列第一篇和第二篇文章,并阅读其代码实现,以便更容易理解本文。
ProcessFunction 当作 Window
低延迟
首先来看下我们将要支持的欺诈检测规则类型:
“每当同一付款人在 24 小时内支付给同一受益人的款项总额超过 20 万美元时,就会触发警报。”
换句话说,假设现在有一个按照付款人和受益人组成 key 分区的交易数据流,对于每条到来的交易数据流,我们都会统计两个特定参与者之间前 24 小时到现在的付款总额是否超过预定义的阈值。
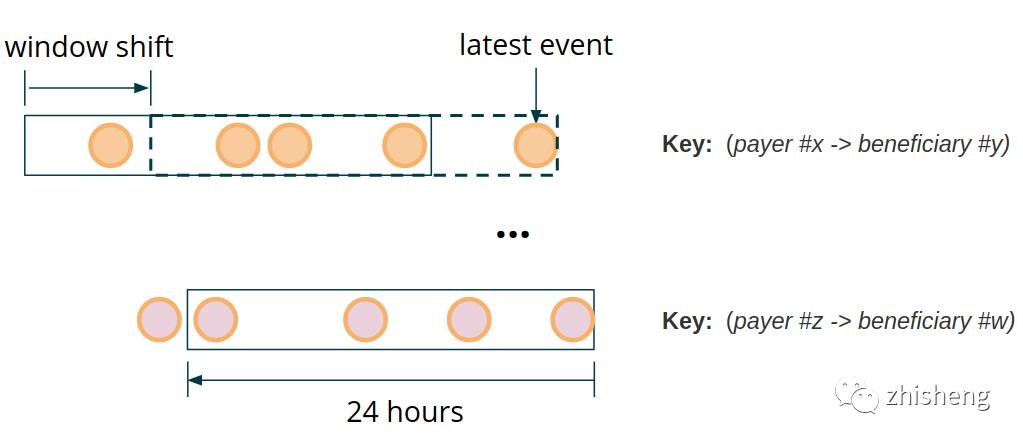
欺诈检测系统的常见关键要求之一是响应时间短。欺诈行为越早被检测到,阻止就会越及时,带来的负面影响就会越小。这一要求在金融领域尤为突出,因为用于评估欺诈检测系统的任何时间都是用户需要等待响应所花费的时间。处理的迅速性通常成为各种支付系统之间的竞争优势,产生告警的时间限制可能低至 300-500 毫秒。这是从欺诈检测系统接收到金融交易事件的那一刻起,直到下游系统发出告警为止的所有延迟时间限制。
你可能知道,Flink 已经提供了强大的 Window API,这些 API 可以适用于广泛的场景。但是你查看 Flink 所有支持的窗口类型,你会发现没有一个能完全符合我们这个场景的要求 —— 低延迟的计算每条交易数据。Flink 自带的窗口没有可以表达 "从当前事件返回 x 分钟/小时/天" 的语义。在 Window API 中,事件会落到由窗口分配器定义的窗口中,但是他们本身不能单独控制 Window 的创建和计算。如上所述,我们的欺诈检测引擎的目标是在收到新事件后立即对之前的相关数据进行计算。在这种场景下,利用 Flink 自带的 Window API 不清楚是否可行。Window API 提供了一些用于自定义的 Trigger、Evictor 和 Window Assigner,或许它们可能会帮助到我们获得所需的结果。但是,通常情况下很难做到这一点,此外,这种方法不提供对广播状态的访问,这是然后广播状态是实现业务规则动态配置所必须的。
除了会话窗口,它们仅限于基于会话间隙的分配
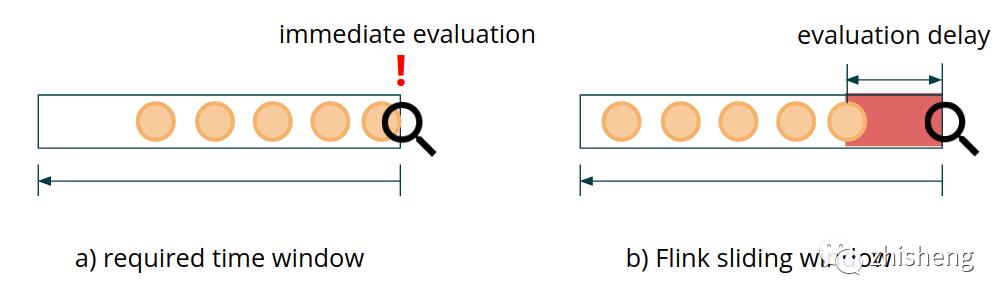
我们以使用 Flink 的 Window API 中的滑动窗口为例。使用滑动步长为 S 的滑动窗口转化为等于 S/2 的评估延迟的预期值。这意味着你需要定义 600~1000 毫秒的滑动窗口来满足 300~500 毫秒延迟的低延迟要求。Flink 要为每个滑动窗口存储单独的窗口状态,这会导致作业状态非常大,在任何中等高负载的情况下,这种方案都不可行。为了满足需求,我们需要创建自定的低延迟窗口实现,幸运的是,Flink 为我们提供了这样做所需的所有工具,ProcessFunction 是 Flink API 中一个低级但功能强大的类。它有一个简单的约定:
public class SomeProcessFunction extends KeyedProcessFunction<KeyType, InputType, OutputType> {
public void processElement(InputType event, Context ctx, Collector<OutputType> out){}
public void onTimer(long timestamp, OnTimerContext ctx, Collector<OutputType> out) {}
public void open(Configuration parameters){}
}
processElement():接收输入数据,你可以通过调用 out.collect() 为下一个算子生成一个或者多个输出事件来对每个输入作出反应,你可以将数据传递到侧输出或完全忽略特定的输入数据
onTimer():当之前注册的定时器触发时,Flink 会调用 onTimer(),支持事件时间和处理时间定时器
open():相当于一个构造函数,它在 TaskManager 的 JVM 内部调用,用于初始化,例如注册 Flink 管理内存,可以在该方法初始化那些没有序列化的字段或者无法从 JobManager JVM 中传递过来的字段。
最重要的是,ProcessFunction 还可以访问由 Flink 处理的容错状态。这种组合,再加上 Flink 的消息处理能力和低延迟的保证,使得构建具有几乎任意复杂业务逻辑的弹性事件驱动应用程序成为可能。这包括创建和处理带有状态的自定义窗口。
实现
状态的清除
为了能够处理时间窗口,我们需要在程序内部跟踪属于该窗口的数据。为了确保这些数据是容错的,并且能够在分布式系统中发生故障的情况下恢复,我们应该将其存储在 Flink 管理的状态中。随着时间的推移,我们不需要保留所有以前的交易数据。根据欺诈检测样例规则,所有早于 24 小时的交易数据都变得无关紧要。我们正在查看一个不断移动的数据窗口,其中过期的数据需要不断移出范围(换句话说,从状态中清除)。
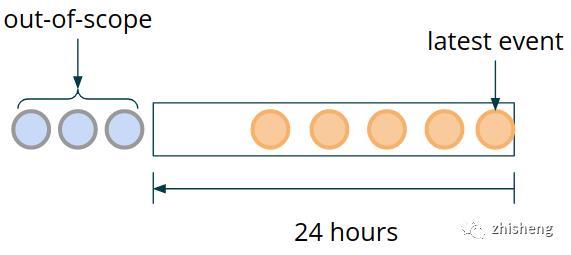
我们将使用 MapState 来存储窗口的各个事件。为了有效清理超出范围的事件,我们将使用事件时间戳作为 MapState 的 key。
在一般情况下,我们必须考虑这样一个事实,即可能存在具有完全相同时间戳的不同事件,因此我们将存储集合而不是每个键(时间戳)的单条数据。
MapState<Long, Set<Transaction>> windowState;
注意⚠️:
当在 KeyedProcessFunction 中使用任何 Flink 管理的状态时,state.value() 调用返回的数据会自动由当前处理的事件的 key 确定范围 - 参见下图。
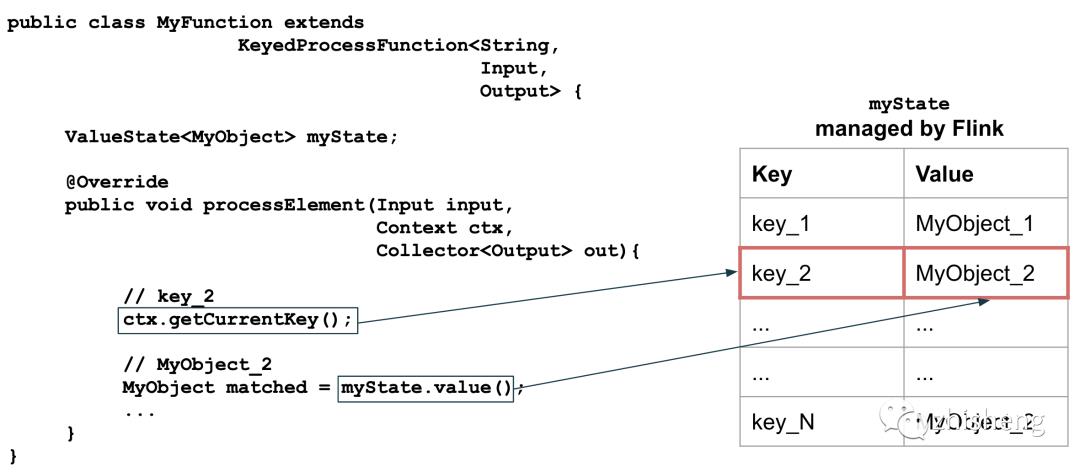
如果使用 MapState,则适用相同的原则,不同之处在于返回的是 Map 而不是 MyObject。如果你被迫执行类似 mapState.value().get(inputEvent.getKey()) 之类的操作,你可能应该使用 ValueState 而不是 MapState。因为我们想为每个事件 key 存储多个值,所以在我们的例子中,MapState 是正确的选择。
如本系列的第一篇博客所述,我们将根据主动欺诈检测规则中指定的 key 分配数据。多个不同的规则可以基于相同的分组 key。这意味着我们的警报功能可能会接收由相同 key(例如 {payerId=25;beneficiaryId=12})限定的交易,但注定要根据不同的规则进行计算,这意味着时间窗口的长度可能不同。这就提出了一个问题,即我们如何才能最好地在 KeyedProcessFunction 中存储容错窗口状态。一种方法是为每个规则创建和管理单独的 MapState。然而,这种方法会很浪费——我们会单独保存重叠时间窗口的状态,因此不必要地存储重复的数据。更好的方法是始终存储刚好足够的数据,以便能够估计由相同 key 限定的所有当前活动规则。为了实现这一点,每当添加新规则时,我们将确定其时间窗口是否具有最大跨度,并将其存储在特殊保留的 WIDEST_RULE_KEY 下的广播状态。
@Override
public void processBroadcastElement(Rule rule, Context ctx, Collector<Alert> out){
...
updateWidestWindowRule(rule, broadcastState);
}
private void updateWidestWindowRule(Rule rule, BroadcastState<Integer, Rule> broadcastState){
Rule widestWindowRule = broadcastState.get(WIDEST_RULE_KEY);
if (widestWindowRule == null) {
broadcastState.put(WIDEST_RULE_KEY, rule);
return;
}
if (widestWindowRule.getWindowMillis() < rule.getWindowMillis()) {
broadcastState.put(WIDEST_RULE_KEY, rule);
}
}
现在让我们更详细地看一下主要方法 processElement() 的实现。
在上一篇博文中,我们描述了 DynamicKeyFunction 如何允许我们根据规则定义中的 groupingKeyNames 参数执行动态数据分区。随后的描述主要围绕 DynamicAlertFunction,它利用了剩余的规则设置。

如博文系列的前几部分所述,我们的警报处理函数接收 Keyed<Transaction, String, Integer> 类型的事件,其中 Transaction 是主要的“包装”事件,String 是 key (payer #x - beneficiary #y),Integer 是导致调度此事件的规则的 ID。此规则之前存储在广播状态中,必须通过 ID 从该状态中检索。下面是实现代码:
public class DynamicAlertFunction
extends KeyedBroadcastProcessFunction<
String, Keyed<Transaction, String, Integer>, Rule, Alert> {
private transient MapState<Long, Set<Transaction>> windowState;
@Override
public void processElement(
Keyed<Transaction, String, Integer> value, ReadOnlyContext ctx, Collector<Alert> out){
// Add Transaction to state
long currentEventTime = value.getWrapped().getEventTime(); // <--- (1)
addToStateValuesSet(windowState, currentEventTime, value.getWrapped());
// Calculate the aggregate value
Rule rule = ctx.getBroadcastState(Descriptors.rulesDescriptor).get(value.getId()); // <--- (2)
Long windowStartTimestampForEvent = rule.getWindowStartTimestampFor(currentEventTime);// <--- (3)
SimpleAccumulator<BigDecimal> aggregator = RuleHelper.getAggregator(rule); // <--- (4)
for (Long stateEventTime : windowState.keys()) {
if (isStateValueInWindow(stateEventTime, windowStartForEvent, currentEventTime)) {
aggregateValuesInState(stateEventTime, aggregator, rule);
}
}
// Evaluate the rule and trigger an alert if violated
BigDecimal aggregateResult = aggregator.getLocalValue(); // <--- (5)
boolean isRuleViolated = rule.apply(aggregateResult);
if (isRuleViolated) {
long decisionTime = System.currentTimeMillis();
out.collect(new Alert<>(rule.getRuleId(),
rule,
value.getKey(),
decisionTime,
value.getWrapped(),
aggregateResult));
}
// Register timers to ensure state cleanup
long cleanupTime = (currentEventTime / 1000) * 1000; // <--- (6)
ctx.timerService().registerEventTimeTimer(cleanupTime);
}
以下是步骤的详细信息:
1)我们首先将每个新事件添加到我们的窗口状态:
static <K, V> Set<V> addToStateValuesSet(MapState<K, Set<V>> mapState, K key, V value)
throws Exception {
Set<V> valuesSet = mapState.get(key);
if (valuesSet != null) {
valuesSet.add(value);
} else {
valuesSet = new HashSet<>();
valuesSet.add(value);
}
mapState.put(key, valuesSet);
return valuesSet;
}
2)接下来,我们检索先前广播的规则,需要根据该规则计算传入的交易数据。
getWindowStartTimestampFor 确定,给定规则中定义的窗口跨度和当前事件时间戳,然后计算窗口应该跨度多久。
通过迭代所有窗口状态并应用聚合函数来计算聚合值。它可以是平均值、最大值、最小值,或者如本文开头的示例规则中的总和。
private boolean isStateValueInWindow(
Long stateEventTime, Long windowStartForEvent, long currentEventTime) {
return stateEventTime >= windowStartForEvent && stateEventTime <= currentEventTime;
}
private void aggregateValuesInState(
Long stateEventTime, SimpleAccumulator<BigDecimal> aggregator, Rule rule) throws Exception {
Set<Transaction> inWindow = windowState.get(stateEventTime);
for (Transaction event : inWindow) {
BigDecimal aggregatedValue =
FieldsExtractor.getBigDecimalByName(rule.getAggregateFieldName(), event);
aggregator.add(aggregatedValue);
}
}
有了聚合值,我们可以将其与规则定义中指定的阈值进行比较,并在必要时发出警报。
最后,我们使用
ctx.timerService().registerEventTimeTimer()注册一个清理计时器。当它要移出范围时,此计时器将负责删除当前数据。onTimer 方法会触发窗口状态的清理。
如前所述,我们总是在状态中保留尽可能多的事件,以计算具有最宽窗口跨度的活动规则。这意味着在清理过程中,我们只需要删除这个最宽窗口范围之外的状态。

这是清理程序的实现方式:
@Override
public void onTimer(final long timestamp, final OnTimerContext ctx, final Collector<Alert> out)
throws Exception {
Rule widestWindowRule = ctx.getBroadcastState(Descriptors.rulesDescriptor).get(WIDEST_RULE_KEY);
Optional<Long> cleanupEventTimeWindow =
Optional.ofNullable(widestWindowRule).map(Rule::getWindowMillis);
Optional<Long> cleanupEventTimeThreshold =
cleanupEventTimeWindow.map(window -> timestamp - window);
// Remove events that are older than (timestamp - widestWindowSpan)ms
cleanupEventTimeThreshold.ifPresent(this::evictOutOfScopeElementsFromWindow);
}
private void evictOutOfScopeElementsFromWindow(Long threshold) {
try {
Iterator<Long> keys = windowState.keys().iterator();
while (keys.hasNext()) {
Long stateEventTime = keys.next();
if (stateEventTime < threshold) {
keys.remove();
}
}
} catch (Exception ex) {
throw new RuntimeException(ex);
}
}
以上是实现细节的描述。我们的方法会在新交易数据到达时立即触发对时间窗口的计算。因此,它满足了我们的主要要求——发出警报的低延迟。完整的实现请看 github 上的项目代码 https://github.com/afedulov/fraud-detection-demo。
完善和优化
上面描述的方法的优缺点是什么?
优点:
低延迟能力
具有潜在用例特定优化的定制解决方案
高效的状态重用(具有相同 key 的规则共享状态)
缺点:
无法利用现有 Window API 中潜在的未来优化
无延迟事件处理,可在 Window API 中开箱即用
二次计算复杂度和潜在的大状态
现在让我们看看后两个缺点,看看我们是否可以解决它们。
延迟数据
处理延迟数据之前先提出了一个问题 - 在延迟数据到达的情况下重新评估窗口是否仍然有意义?如果需要这样做,你需要增加最宽的窗口大小,用来允许容忍最大的数据延迟。这样将避免因延迟数据问题导致触发了不完整的时间窗口数据。
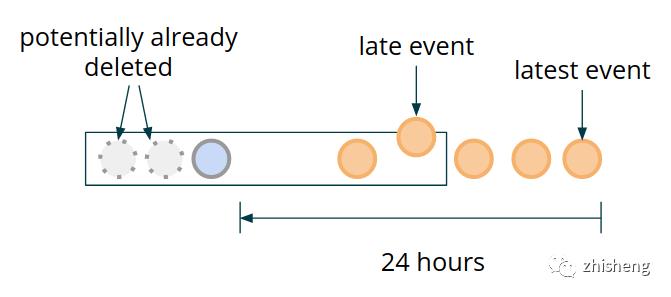
然而,可以说,对于强调低延迟处理的场景,这种延迟触发将毫无意义。在这种情况下,我们可以跟踪到目前为止我们观察到的最新时间戳,对于不会单调增加此值的事件,只需将它们添加到状态并跳过聚合计算和警报触发逻辑。
冗余重复计算和状态大小
在我们描述的实现中,我们保存每条数据处于状态中并在每个新数据来时遍历它们并一次又一次地计算聚合。这在重复计算上浪费计算资源方面显然不是最佳的。
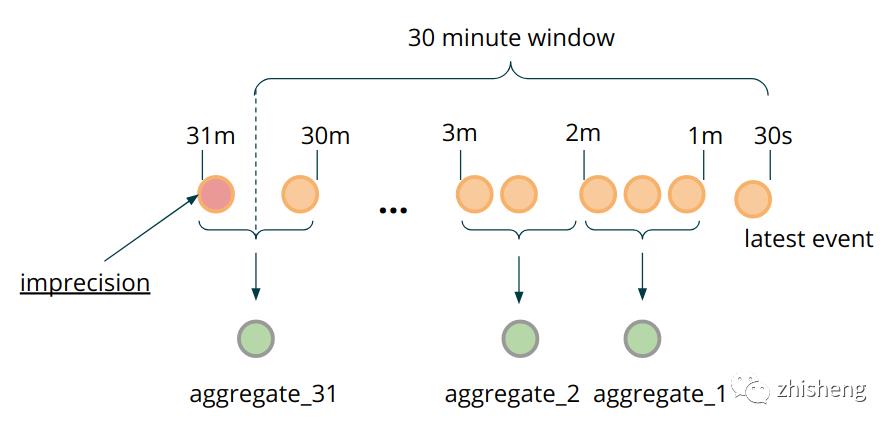
保存每个交易数据处于状态的主要原因是什么?存储事件的粒度直接对应于时间窗口计算的精度。因为我们是存储每条明细交易数据,所以一旦它们离开精确的 2592000000 毫秒时间窗口(以毫秒为单位的 30 天),我们就可以精确地移除它们。在这一点上,值得提出一个问题——在估计这么长的时间窗口时,我们真的需要这个毫秒级的精度,还是在特殊情况下可以接受潜在的误报?如果你的用例的答案是不需要这样的精度,那么你可以基于分桶和预聚合实施额外的优化。这种优化的思想可以分解如下:
不是存储每条明细交易数据,而是创建一个父类,该类可以包含单条数据的字段或是根据聚合函数计算处理一批数据后的聚合值。
不要使用以毫秒为单位的时间戳作为 MapState key,而是将它们四舍五入到你愿意接受的粒度级别(例如,一分钟),将数据分桶。
每当计算窗口时,将新的交易数据存储到聚合桶中,而不是为每个数据存储单独的数据点。
状态数据和序列化器
为了进一步优化实现,我们可以问自己的另一个问题是获得具有完全相同时间戳的不同事件的可能性有多大。在所描述的实现中,我们展示了通过在 MapState<Long, Set<Transaction>> 中存储每个时间戳的数据集来解决这个问题的一种方法。但是,这种选择对性能的影响可能比预期的要大。原因是 Flink 当前不提供原生 Set 序列化器,而是强制使用效率较低的 Kryo 序列化器(FLINK-16729)。一个有意义的替代策略是假设在正常情况下,没有两个有差异的事件可以具有完全相同的时间戳,并将窗口状态转换为 MapState<Long, Transaction> 类型。你可以使用辅助输出来收集和监控与你的假设相矛盾的任何意外事件。性能优化期间,我通常建议你禁用 Kryo,并通过确保使用更高效的序列化程序来验证你的应用程序可以进一步优化的位置。
你可以通过设置断点并验证返回的 TypeInformation 的类型来快速确定你的类将使用哪个序列化程序。
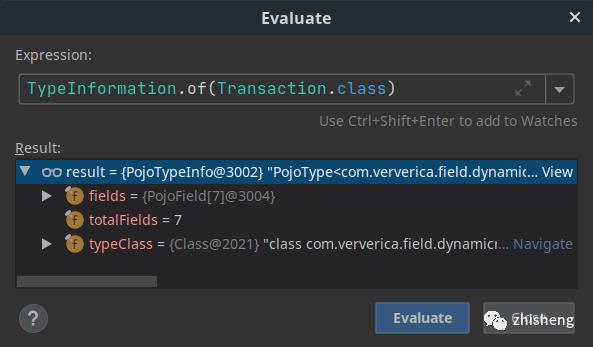
PojoTypeInfo 表示将使用高效的 Flink POJO 序列化器。
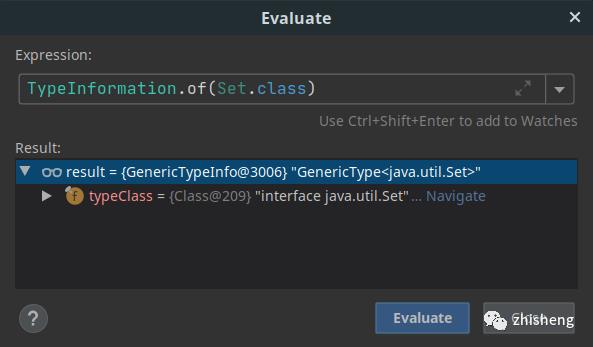
GenericTypeInfo 表示使用了 Kryo 序列化程序。
交易数据修剪:我们可以将单个事件数据减少到仅要用到的字段,而不是存储完整的事件数据,减少数据序列化与反序列化对机器施加额外的压力。这可能需要根据活动规则的配置将单个事件提取需要对字段出来,并将这些字段存储到通用 Map<String, Object> 数据结构中。
虽然这种调整可能会对大对象产生显著的改进,但它不应该是你的首选。
总结
本文总结了我们在第一部分中开始的欺诈检测引擎的实现描述。在这篇博文中,我们演示了如何利用 ProcessFunction 来“模拟”具有复杂自定义逻辑的窗口。我们已经讨论了这种方法的优缺点,并详细说明了如何应用自定义场景特定的优化 - 这是 Window API 无法直接实现的。
这篇博文的目的是说明 Apache Flink API 的强大功能和灵活性。它的核心是 Flink 的支柱,作为开发人员,它为你节省了大量的工作,并通过提供以下内容很好地推广到广泛的用例:
分布式集群中的高效数据交换
通过数据分区的水平可扩展性
具有快速本地访问的容错状态
方便处理状态数据,就像使用局部变量一样简单
多线程、并行执行引擎。ProcessFunction 代码在单线程中运行,无需同步。Flink 处理所有并行执行方面并正确访问共享状态,而你作为开发人员不必考虑(并发很难)。
所有这些方面都使得使用 Flink 构建应用程序成为可能,这些应用程序远远超出了普通的流 ETL 用例,并且可以实现任意复杂的分布式事件驱动应用程序。使用 Flink,你可以重新思考处理广泛用例的方法,这些用例通常依赖于使用无状态并行执行节点并将状态容错问题“推”到数据库,这种方法通常注定会遇到可扩展性问题面对不断增长的数据量。
本文作者:zhisheng
本文地址:http://www.54tianzhisheng.cn/2021/07/03/Flink-Fraud-Detection-engine-3/
原英文地址:https://flink.apache.org/news/2020/07/30/demo-fraud-detection-3.html
end
Flink 从入门到精通 系列文章
基于 Apache Flink 的实时监控告警系统关于数据中台的深度思考与总结(干干货)日志收集Agent,阴暗潮湿的地底世界

公众号(zhisheng)里回复 面经、ClickHouse、ES、Flink、 Spring、Java、Kafka、监控 等关键字可以查看更多关键字对应的文章。
点个赞+在看,少个 bug ????
以上是关于基于 Flink 的动态欺诈检测系统(下)的主要内容,如果未能解决你的问题,请参考以下文章