笔检测基于matlab模板匹配+PCA笔检测含Matlab源码 1093期
Posted 紫极神光(Q1564658423)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了笔检测基于matlab模板匹配+PCA笔检测含Matlab源码 1093期相关的知识,希望对你有一定的参考价值。
一、简介
1 PCA
PCA(Principal Component Analysis)是常用的数据分析方法。PCA是通过线性变换,将原始数据变换为一组各维度线性无关的数据表示方法,可用于提取数据的主要特征分量,常用于高维数据的降维。
1.1 降维问题
数据挖掘和机器学习中,数据以向量表示。例如某个淘宝店2012年全年的流量及交易情况可以看成一组记录的集合,其中每一天的数据是一条记录,格式如下:
(日期, 浏览量, 访客数, 下单数, 成交数, 成交金额)
其中“日期”是一个记录标志而非度量值,而数据挖掘关心的大多是度量值,因此如果我们忽略日期这个字段后,我们得到一组记录,每条记录可以被表示为一个五维向量,其中一条样本如下所示:
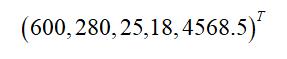
一般习惯上使用列向量表示一条记录,本文后面也会遵循这个准则。
机器学习的很多算法复杂度和数据的维数有着密切关系,甚至与维数呈指数级关联。这里区区5维的数据,也许无所谓,但是实际机器学习中处理成千上万甚至几十万维的数据也并不罕见,在这种情况下,机器学习的资源消耗是不可接受的,因此就会对数据采取降维的操作。降维就意味着信息的丢失,不过鉴于实际数据本身常常存在相关性,所以在降维时想办法降低信息的损失。
例如上面淘宝店铺的数据,从经验可知,“浏览量”和“访客数”往往具有较强的相关性,而“下单数”和“成交数”也具有较强的相关性。可以直观理解为“当某一天这个店铺的浏览量较高(或较低)时,我们应该很大程度上认为这天的访客数也较高(或较低)”。因此,如果删除浏览量或访客数,最终并不会丢失太多信息,从而降低数据的维度,也就是所谓的降维操作。如果把数据降维用数学来分析讨论,用专业名词表示就是PCA,这是一种具有严格数学基础并且已被广泛采用的降维方法。
1.2 向量与基变换
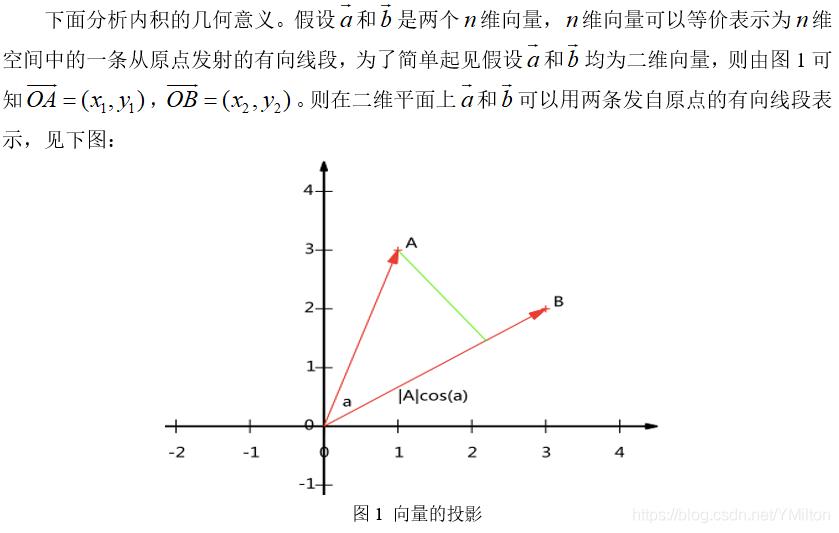
1.2.1 内积与投影
两个大小相同向量的内积被定义如下:


1.2.2 基
在代数中,经常用线段终点的点坐标表示向量。假设某个向量的坐标为(3,2),这里的3实际表示的是向量在x轴上的投影值是3,在y轴上的投影值是2。也就是说隐式引入了一个定义:以x轴和y轴上正方向长度为1的向量为标准。那么一个向量(3,2)实际是在x轴投影为3而y轴的投影为2。注意投影是一个矢量,可以为负。向量(x, y)实际上表示线性组合:
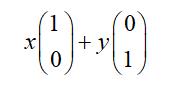
由上面的表示,可以得到所有二维向量都可以表示为这样的线性组合。此处(1,0)和(0,1)叫做二维空间中的一组基。
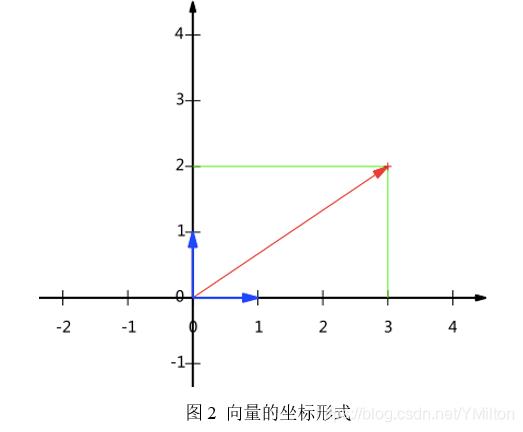
之所以默认选择(1,0)和(0,1)为基,当然是为了方便,因为它们分别是x和y轴正方向上的单位向量,因此就使得二维平面上点坐标和向量一一对应。但实际上任何两个线性无关的二维向量都可以成为一组基,所谓线性无关在二维平面内,从直观上就是两个不在一条直线的向量。
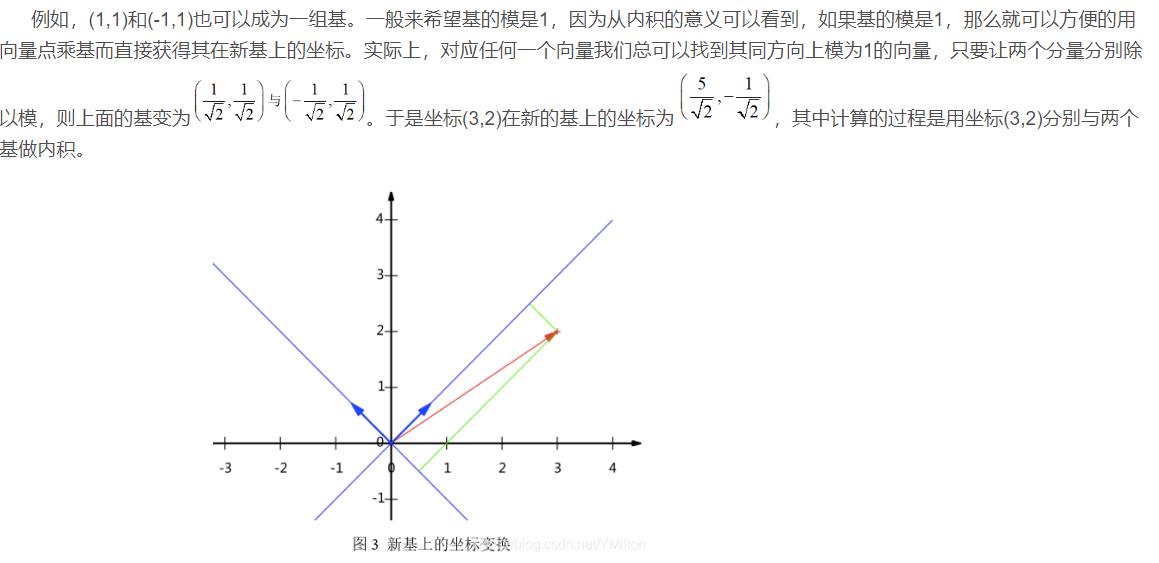
另外这里的基是正交的(即内积为0,或直观说相互垂直),可以成为一组基的唯一要求就是线性无关,非正交的基也是可以的。不过因为正交基有较好的性质,所以一般使用的基都是正交的。
1.2.3 基变换的矩阵
上述例子中的基变换,可以采用矩阵的乘法来表示,即
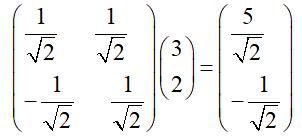
如果推广一下,假设有M个N维向量,想将其变换为由R个N维向量表示的新空间中,那么首先将R个基按行组成矩阵A,然后将向量按列组成矩阵B,那么两矩阵的乘积AB就是变换结果,其中AB的第m列为A中第m列变换后的结果,通过矩阵相乘表示为:
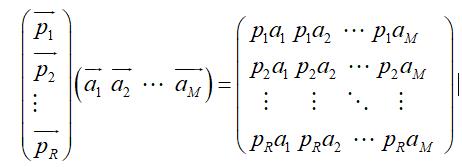

1.3 协方差矩阵及优化目标
在进行数据降维的时候,关键的问题是如何判定选择的基是最优。也就是选择最优基是最大程度的保证原始数据的特征。这里假设有5条数据为
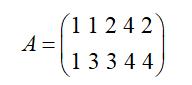
计算每一行的平均值,然后再让每一行减去得到的平均值,得到

通过坐标的形式表现矩阵,得到的图如下:
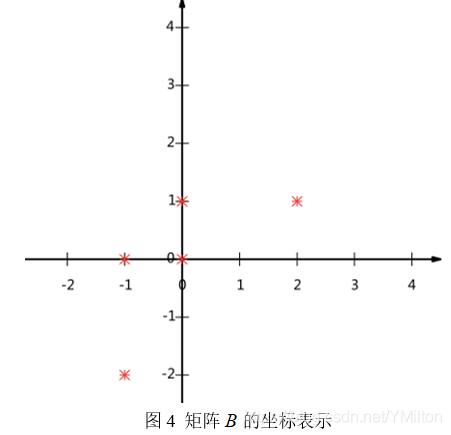
那么现在的问题是:用一维向量来表示这些数据,又希望尽量保留原有的信息,该如何选择呢?这个问题实际上是要在二维平面中选择一个方向的向量,将所有数据点都投影到这条直线上,用投影的值表示原始记录,即二维降到一维的问题。那么如何选择这个方向(或者说基)才能尽量保留最多的原始信息呢?一种直观的看法是:希望投影后的投影值尽可能分散。
1.3.1 方差
上述问题是希望投影后投影的值尽可能在一个方向上分散,而这种分散程度,可以采用数学上的方差来表述,即:
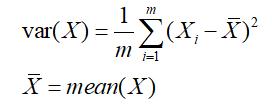
于是上面的问题被形式化表述为:寻找一个一维基,使得所有数据变换为这个基上的坐标后,方差值最大。
2.3.2 协方差
数学上可以用两个特征的协方差表示其相关性,即:
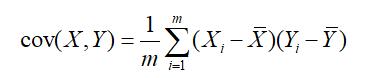
当协方差为0时,表示两个特征完全独立。为了让协方差为0,选择第二个基时只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。
至此获得降维问题的优化目标:将一组N维向量降为K维(K<N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0,而字段的方差则尽可能大(在正交的约束下,取最大的K个方差)。
2.3.3 协方差矩阵
假设只有x和y两个字段,将它们按行组成矩阵,其中是通过中心化的矩阵,也就是每条字段减去每条字段的平均值得到的矩阵:
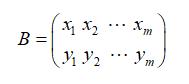

3.4 协方差矩阵对角化


1.4 算法与实例
1.4.1 PCA算法

1.4.2 实例


1.5. 讨论
根据上面对PCA的数学原理的解释,可以了解到一些PCA的能力和限制。PCA本质上是将方差最大的方向作为主要特征,并且在各个正交方向上将数据“离相关”,也就是让它们在不同正交方向上没有相关性。
因此,PCA也存在一些限制,例如它可以很好的解除线性相关,但是对于高阶相关性就没有办法了,对于存在高阶相关性的数据,可以考虑Kernel PCA,通过Kernel函数将非线性相关转为线性相关。另外,PCA假设数据各主特征是分布在正交方向上,如果在非正交方向上存在几个方差较大的方向,PCA的效果就大打折扣了。
最后需要说明的是,PCA是一种无参数技术,也就是说面对同样的数据,如果不考虑清洗,谁来做结果都一样,没有主观参数的介入,所以PCA便于通用实现,但是本身无法个性化的优化。
二、源代码
%笔的识别
global im;%使用全局变量
imgdata=[];%训练图像矩阵
for i=1:2
for j=1:4
a=imread(strcat('ORL\\pen',num2str(i),'_',num2str(j),'.bmp'));
b=a(1:176*132); % b是列矢量 1*M,其中M=23232
b=double(b);
imgdata=[imgdata; b]; % imgdata 是一个M * N 矩阵,imgdata中每一行数据一张图片,M=400
end;
end;
imgdata=imgdata'; %每一列为一张图片
imgmean=mean(imgdata,2); % 平均图片,N维列向量
for i=1:8
minus(:,i) = imgdata(:,i)-imgmean; % minus是一个N*M矩阵,是训练图和平均图之间的差值
end;
covx=minus'* minus; % M * M 阶协方差矩阵
[COEFF, latent,explained] = pcacov(covx'); %PCA,用协方差矩阵的转置来计算以减小计算量
% 选择构成95%的能量的特征值
i=1;
proportion=0;
while(proportion < 95)
proportion=proportion+explained(i);
i=i+1;
end;
p=i-1;
% 训练得到特征笔坐标系
i=1;
while (i<=p && latent(i)>0)
base(:,i) = latent(i)^(-1/2)*minus * COEFF(:,i); % base是N×p阶矩阵,用来进行投影,除以latent(i)^(1/2)是对笔图像的标准化
i = i + 1;
end
% 将训练样本对坐标系上进行投影,得到一个 p*M 阶矩阵为参考
reference = base'*minus;
% 测试过程——在测试图片文件夹中选择图片,进行查找测试
im=imread('待测笔\\待测笔.bmp');
a=im;
%b=a(1:38400);
b=double(b);
b=b';
object = base'*(b-imgmean);
% 绘出待测图片
subplot(2,3,1);
imshow(a);
title(['待测笔']);
distance=100000;
%最小距离法,寻找和待识别图片最为接近的训练图片
for k=1:8
temp= norm(object - reference(:,k));
if (distance > temp)
which = k;
distance = temp;
end;
end;
%找出距离最近的图片所在的位置
num1 = ceil(which/5);%第num1个文件夹
num2 = mod(which,5);%第num2个图片文件
if (num2 == 0)
num2 = 5;
end;
三、运行结果
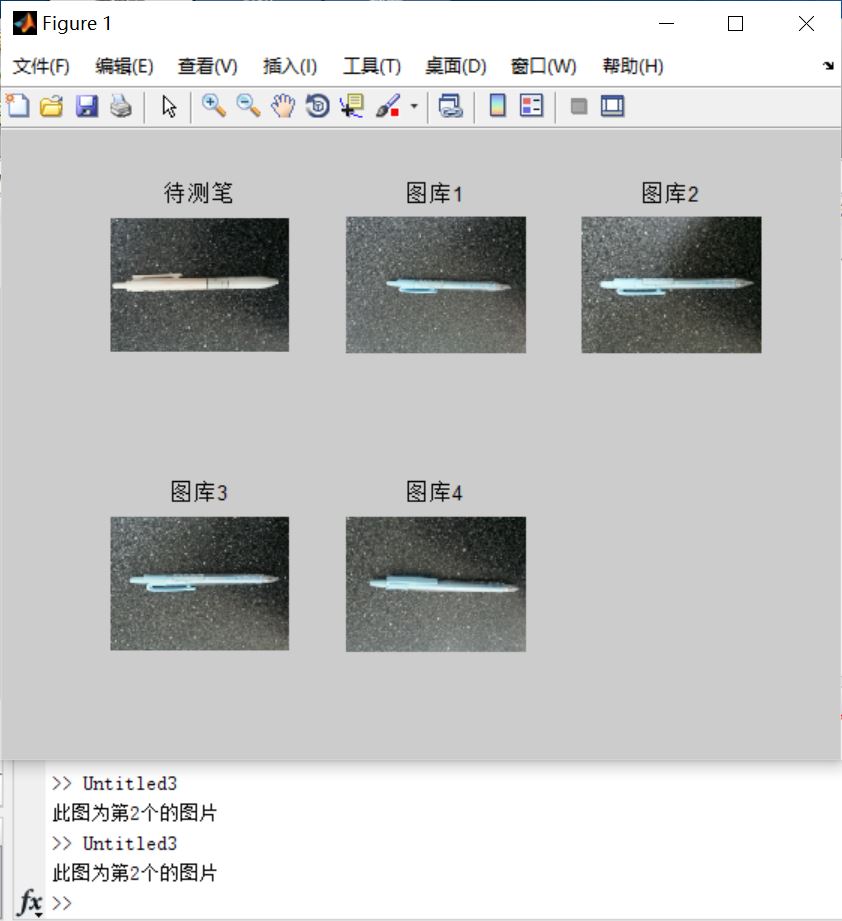
四、备注
版本:2014a
以上是关于笔检测基于matlab模板匹配+PCA笔检测含Matlab源码 1093期的主要内容,如果未能解决你的问题,请参考以下文章
手势识别基于matlab PCA+LDA手语检测识别含Matlab源码 1551期
图像检测基于形态学实现人脸检测定位matlab源码含 GUI
车牌识别基于matlab投影模板匹配车牌识别含Matlab源码 1359期